一位前端专家构建GraphQL工程的心路历程
Posted IT大咖说
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一位前端专家构建GraphQL工程的心路历程相关的知识,希望对你有一定的参考价值。

内容来源:2018 年 6 月 9 日,国内某大型电商公司用户体验部门前端开发专家邓若奇在“杭州第一届 GraphQLParty—GraphQL与领域驱动带来的协同价值”进行《基于SPA架构的GraphQL工程实践》演讲分享。IT 大咖说(微信id:itdakashuo)作为独家视频合作方,经主办方和讲者审阅授权发布。
阅读字数:3838 | 10分钟阅读
摘要
主要演讲主要介绍基于SPA架构的GraphQL工程实践,从前端视角来分析GraphQL在整个链路中的协同效率问题。
获取嘉宾演讲视频及PPT,扫一扫下方二维码即可。

GraphQL的哲学
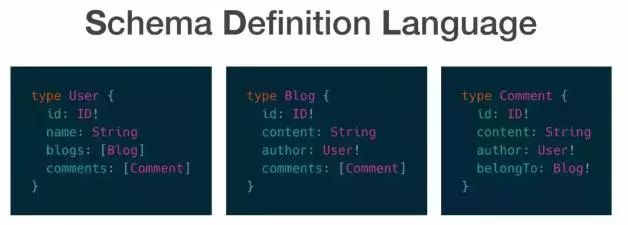
GraphQL是通过一套Schema来定义领域模型,官方称之为SDL。它引入了一套类型系统来对模型进行约束,如上图展示的3个类型。
在实际应用中客户端将要获取的字段通过Schema文本的方式发送给服务端,服务端接收处理后返回json格式的数据。
GraphQL提供了一套统一模型定义,拥有灵活的按需查询的能力。还有个容易被大家忽视的特性——通过类型系统提供了模型之间的关系描述,由此可以看出虽然数据以json格式返回,但是实际的应用数据呈现的应该是网状架构,这使得GraphQL成为描述应用数据的极佳选择,也是它名字的由来。
架构设计与技术选型
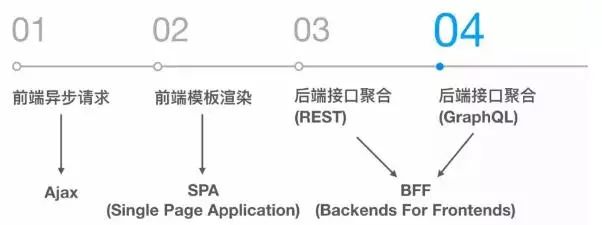
以我个人经历来看,前后端分离可以分为4个阶段。
第一阶段前端异步请求数据接口刷新局部UI。
第二阶段前端接管View层,这是很多基于MVC的框架采用的模式。
第三、四阶段随着nodeJS技术的兴起,前后端的协同效率问题开始受到关注,后续通过引入BFF这层让前端能够快速迭代,同时后端下沉为服务或微服务。
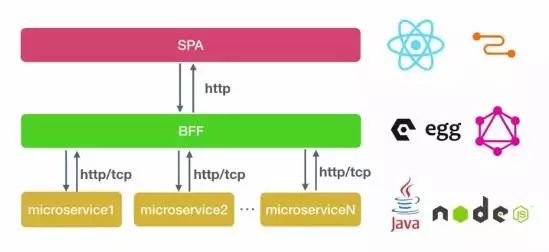
上图是我的技术选型方案。前端为React和relay,relay是基于GraphQL和React的数据整合方案。BFF这层引入的是Egg.js,它是阿里开源的面向企业级开发的web框架。
如何设计BFF
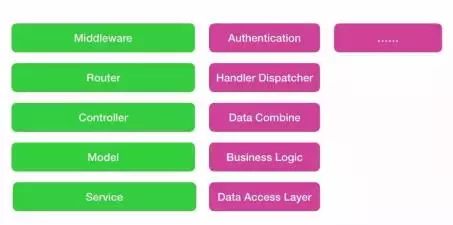
先来看下传统的基于MVC模式的web server受理REST请求过程。首先请求进入middleware(中间件),在此处理一些通用逻辑,比如用户登录态判断或API鉴权。接着进入Router将请求分布到不同的controller,controller这层调用model进行业务处理,然后model再调用service层取数据,最后数据在controller层完成封装并返回。
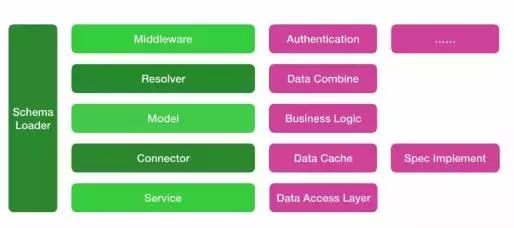
引入GraphQL之后Router和controller不再被需要,因为首先GraphQL并不基于endpoint,其次它自身的resolver可以完成数据封装。此架构中我们引入了两个模块connector和Schema Loader。connector模块一方面针对GraphQL的一些特点做了特殊缓存设计,另一方面制定了前后端协作的规范。
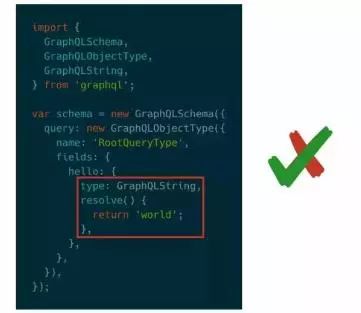
这是我最初写的GraphQL代码,借鉴与GraphQL-js的官方repo。现在看来这段代码存在2个问题,首先schema应与语言无关而只是模型的描述,其次开发的时候应该遵守设计先行的原则,先确定模型然后再写代码。

理想情况应该是这样的,先确定模型描述和关系,然后再编写resolver决定具体处理方案,最后在应用加载的时候使用schema Loader将他们绑定在一起。
鉴权和授权的区别在于,鉴权主要针对通用逻辑,是粗粒度的,授权则是定制逻辑,粒度较细。
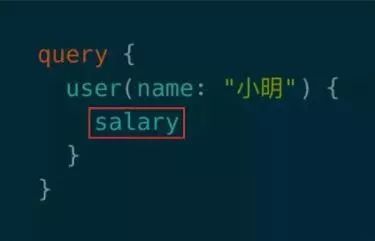
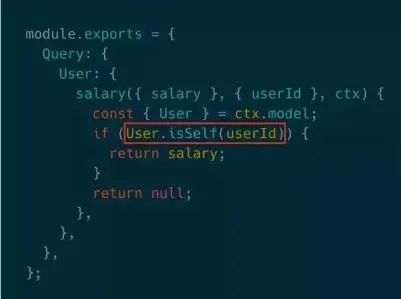
在GraphQL中授权可能针对的是某个字段,如图所示query查询的是小明的工资,由于工资只能自己查看,所以要在resolver中加入一段授权逻辑保证查询者为本人。这里的设计理念是将授权逻辑封装在model层,让它在不同的resolver中得以复用。
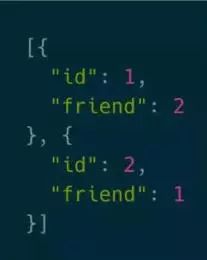
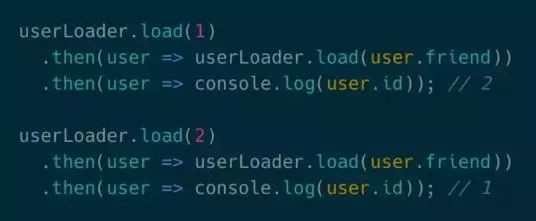
上图是数据库中的两条用户记录,他们互为friend,通过两段代码分别查询用户和他们的friend。
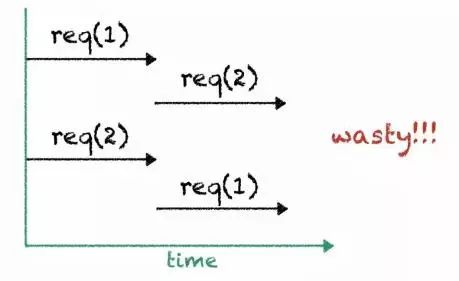
这是上面代码请求的时序图,可以看到一共发出了4次请求,但最终获取到的数据只有两条。
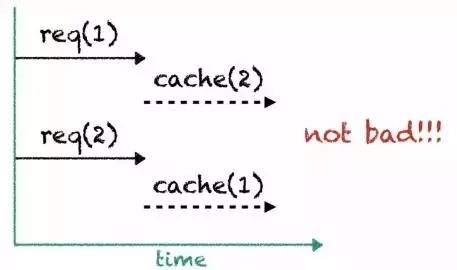
引入缓存之后,第二轮的请求就都可以在第一轮的查询缓存中找到。
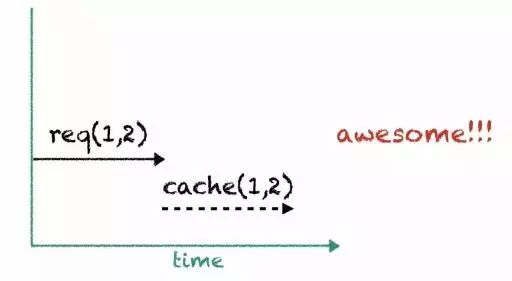
还可以再进行优化,将两段代码的第一轮请求合并在一起,这才是最优解。
为实现以上的效果,首先需要使用缓存。然后还要有请求队列,将同一个周期中的所有load或query全部缓存起来,然后在下一个周期中合并成一个请求放出。最后是批量处理的能力,用于处理附带批量key的请求。
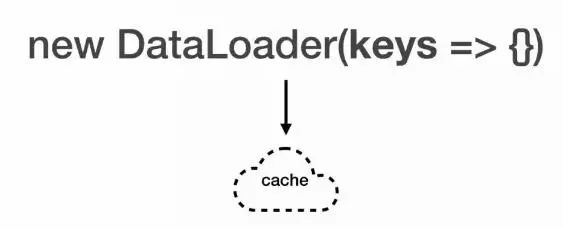
Facabook提供了一种批量处理的解决方案DataLoader,它接收一个用来处理批量key的方法,每个DataLoader的实例下方都有一个cache。最初的需求在引入DataLoader之后代码如下图所示。
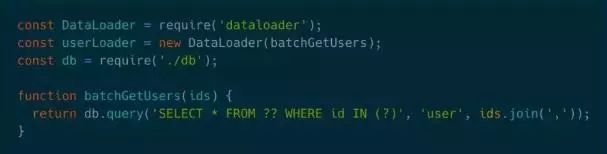
这段代码的最终效果是把三个请求合并成一个请求,在后端执行的是一条SQL语句。
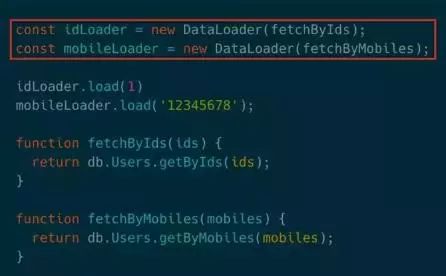
不过在实际结合关系型数据库使用的时候还是略微有些复杂。一般我们对关系型数据库进行查询的时候即会依据PK(primary key)也会依据UK(unique key)。如上代码关于用户的查询既可以通过ID也可以通过Mobiles,这就不得不实例化两个DataLoader实例。由于是不同DataLoader实例,所以用的是不同的缓存,导致缓存利用率不高。
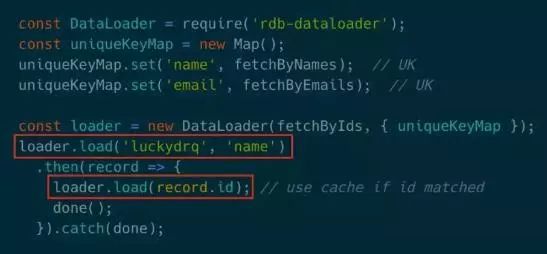
为此我编写了rdb-dataloader模块,让PK和UK的查询都在同一个实例中,达到复用缓存的目的。注意红框中的代码,这里先通过name查询出一条记录,然后对这条记录经由ID做第二次查询,显然第二次查询不会发出,而是会使用缓存。方案的核心在于缓存记录的全部字段,数据量的控制应该由分页逻辑来关心。
DataLoader是请求级别的缓存,请求进来的时候初始化DataLoader实例,请求结束后就销毁。
前后端如何协作
作为一名前端在使用GraphQL的时候首先要是思考的是对浏览器的性能有何影响,这也是接下来进一步挖掘relay的原因。
在使用React组件时,最普遍的诉求就是需要异步取数据,然后对数据进行渲染,常规的做法是在componentDidMount中添加异步取数的逻辑。因此实际应用中随着页面层级的深入,加载时间会随之变长,子组件必须等待父组件的数据加载完之后才能开始渲染。
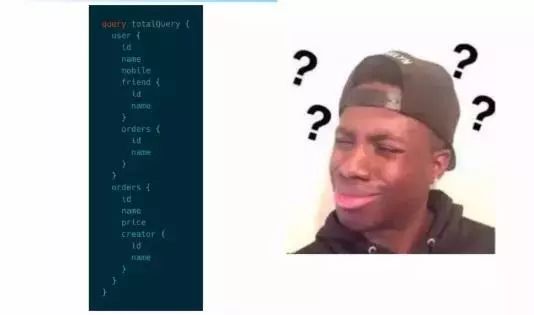
对此最简单的优化方案是将所有组件需要的数据全部放在第一次请求中,如上所示。可是在后续要新增需求的时候我却搞出了bug,因为此时已经分不清哪些字段对应哪些组件。
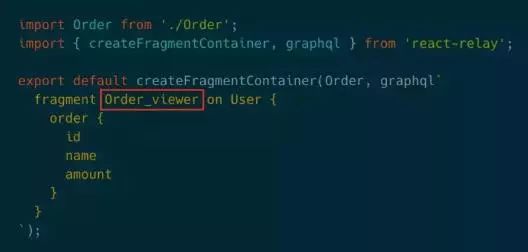
再来看下relay的实现方式,relay有一个creatFragmenContainer方法,可以向该方法传入React组件,然后通过GraphQL的scheam返回relay component。这种方式不仅实现了依赖注入也没有打破组件的数据封装性。
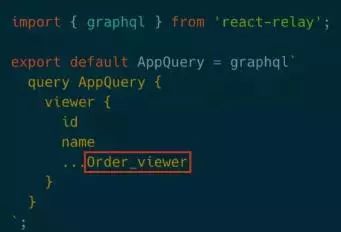
在最初的query中嵌入上面的fragment后,我们就知道了字段是由哪个组件发出的。
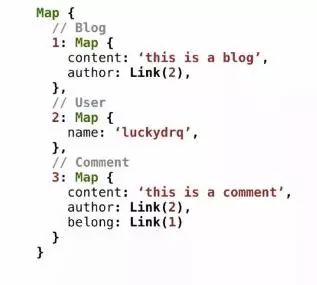
上图是一段伪代码,表示的是relay底层的协作方式。第一个对象是博客,有内容,也有作者,但是这个作者是一个 user 类型,博客不会直接存储 user 的全部数据,而是通过引用的方式引用到第二个对象。同理评论的作者和它属于哪个博客,同样是用引用的方式。这样的好处在于只要对象发生改动,所有引用该对象的地方都会同步更新。
请注意图中1、2、3这几个数字,他们是全局唯一的缓存key。由于所有的数据都在缓存中,所以不能再使用数据库中的ID,否则对于ID相同的博客和用户就无法处理了。唯一ID的实现有各种方案,可以使用base64(type+”:”+id)这种形式。
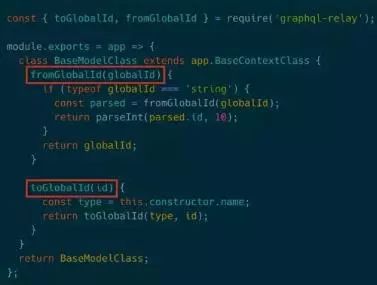
全局ID需要后端来配合,定义fromGlobalId和toGobalId这两个方法。fromGlobalId负责将relay发请求时带来的ID解包成数据库ID,toGobalId负责返回的时候对数据库ID装包。
客户端将schema文本发送到服务端,然后由服务端进行处理的这一过程中,文本量其实是相当大的,对于网络环境不好的用户体验会非常差。
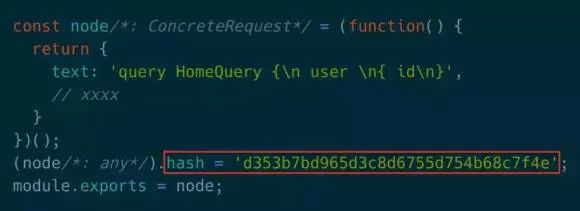
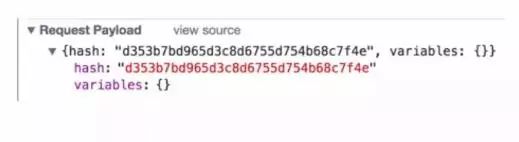
那么能不能直接发送query id,在服务端通过id解析出文本呢?所幸relay提供了这种方式,在构建relay脚本的时候会给模块注入hash标识当前schema,通过这个hash前后端就对应起来了。
需要解决的问题

首要解决的是DOS Attack,说白了就是上图这种嵌套攻击,请注意这并不是死循环,这只是一个攻击者故意通过你的 query 无限写的非常复杂的嵌套,让你的服务器消耗殆尽。显然设置query文本长度和query白名单无益于解决问题,正确的做法是控制query的深度。

对于rate limiting限流,由于GraphQL并非是基于Rest,所以不能通过限制路由每分钟的调用次数来解决。而应该是限制读写操作,上面的例子表示的就是每分钟最多只能添加20个评论,通过directive实现。
不过实际上限流的实现成本是比较大的,如果要专门实现限流功能,需要依赖第三方的一些服务。
以上为今天的分享内容,谢谢大家!
IT大咖说 | 关于版权
感谢您对IT大咖说的热心支持!
相关推荐
推荐文章
近期活动
点击【阅读原文】 打开干货通道
以上是关于一位前端专家构建GraphQL工程的心路历程的主要内容,如果未能解决你的问题,请参考以下文章