鹰眼海量级分布式日志系统上云的架构和实践
Posted 21CTO
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了鹰眼海量级分布式日志系统上云的架构和实践相关的知识,希望对你有一定的参考价值。
导语 | 鹰眼是由腾讯PCG技术运营部负责的海量级分布式实时监控和日志分析系统,为响应公司战略要求,将原先的业务迁移上云,最终产生了可喜的变化。本文将介绍分布式日志系统(鹰眼)的整体上云方案,希望与大家一同交流。
鹰眼是由PCG技术运营部负责的海量级分布式实时监控和日志分析系统,支持多语言的上报,域名为:
http://log2.oa.com/
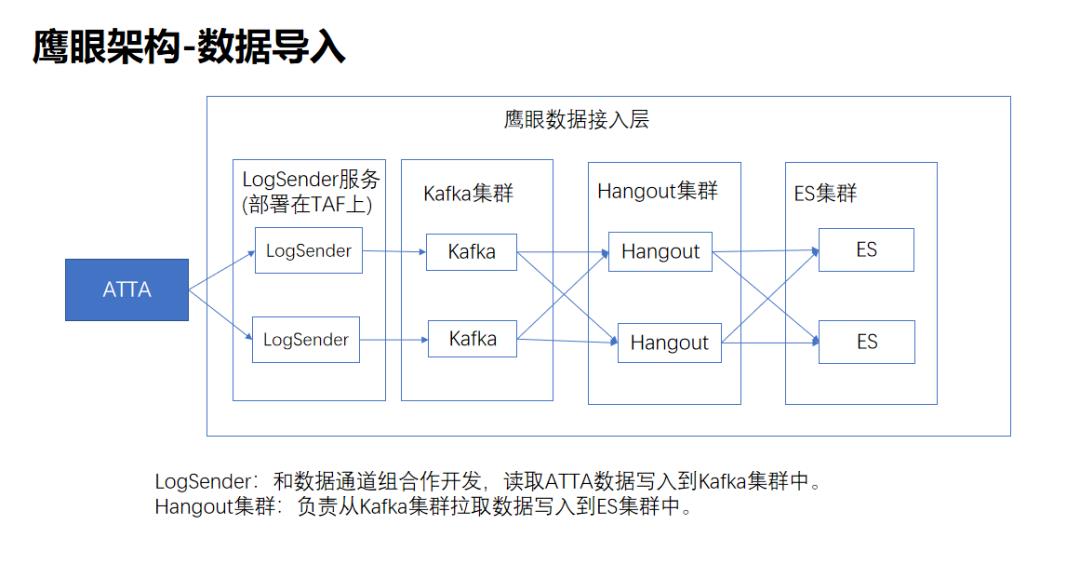
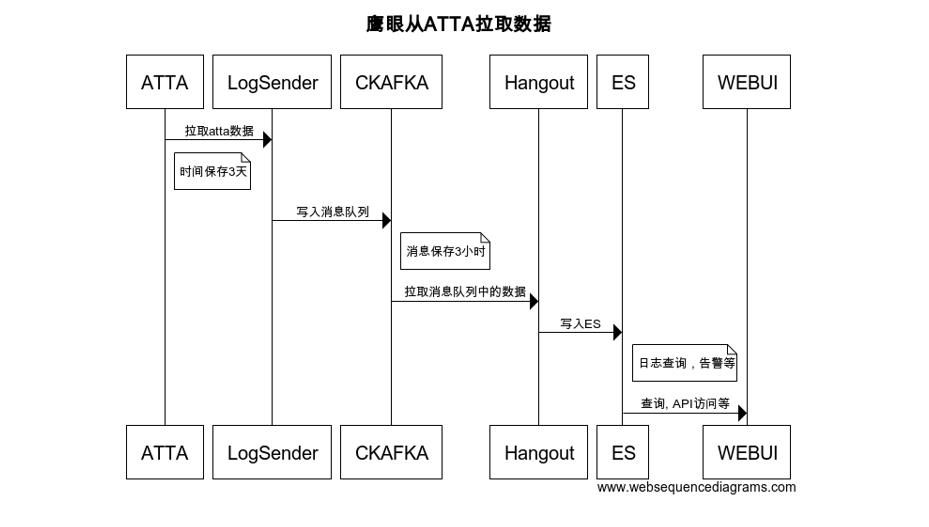
鹰眼的数据上报是通过ATTA提供的,ATTA支持多语言的上报(JAVA,Python,C++等),上报之后,鹰眼从ATTA系统拉取数据最终写入到ES,通过ES的倒排索引机制,快速查询功能,写入功能等。
使用ES的倒排索引机制,百亿数据秒级查询返回的能力,鹰眼提供了以下功能:
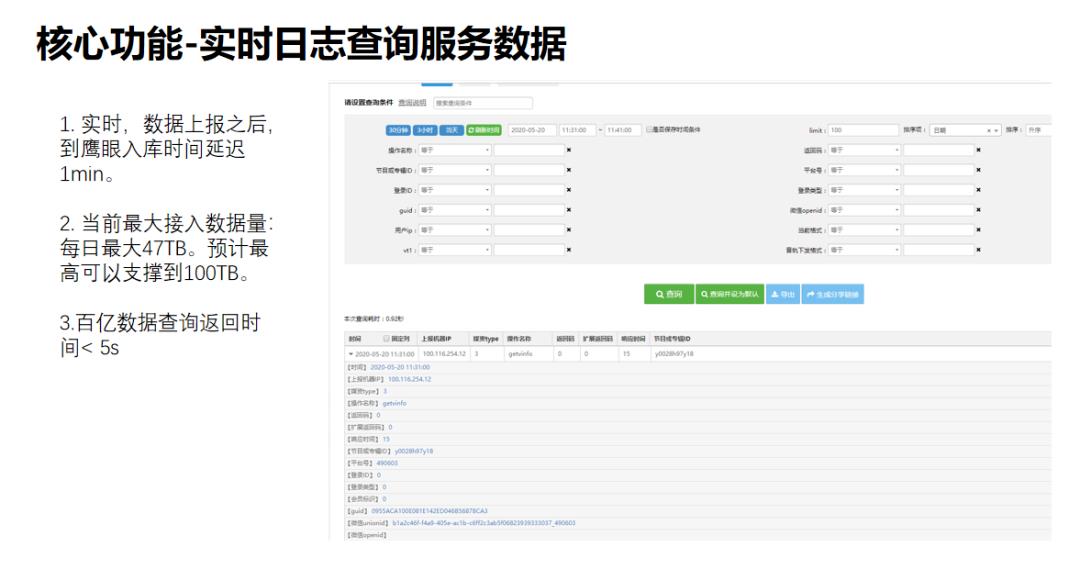
实时日志查询服务数据上报到ATTA之后,开发可以通过鹰眼及时查询到日志,定位问题,运维可以通过鹰眼提供的数据统计界面实时查询到业务的运行情况。
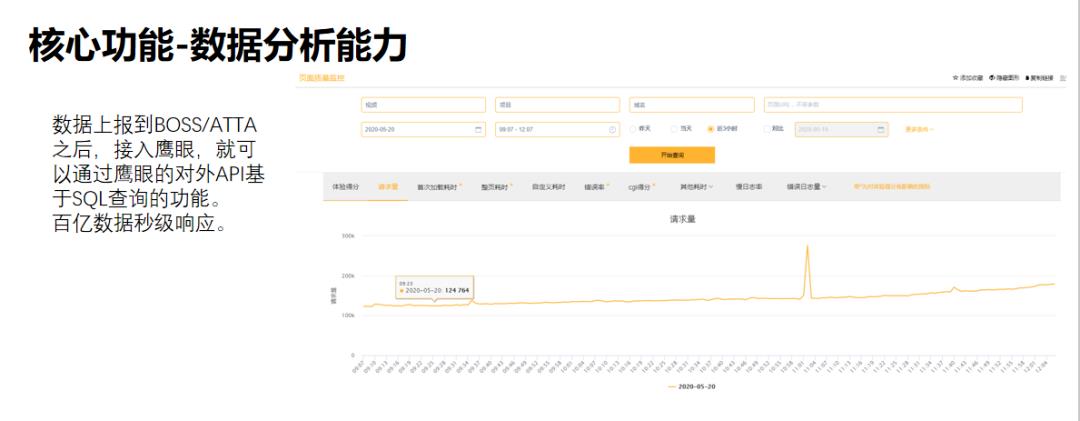
鹰眼数据入库后,用户可以通过API直接调用,进行OLAP分析。
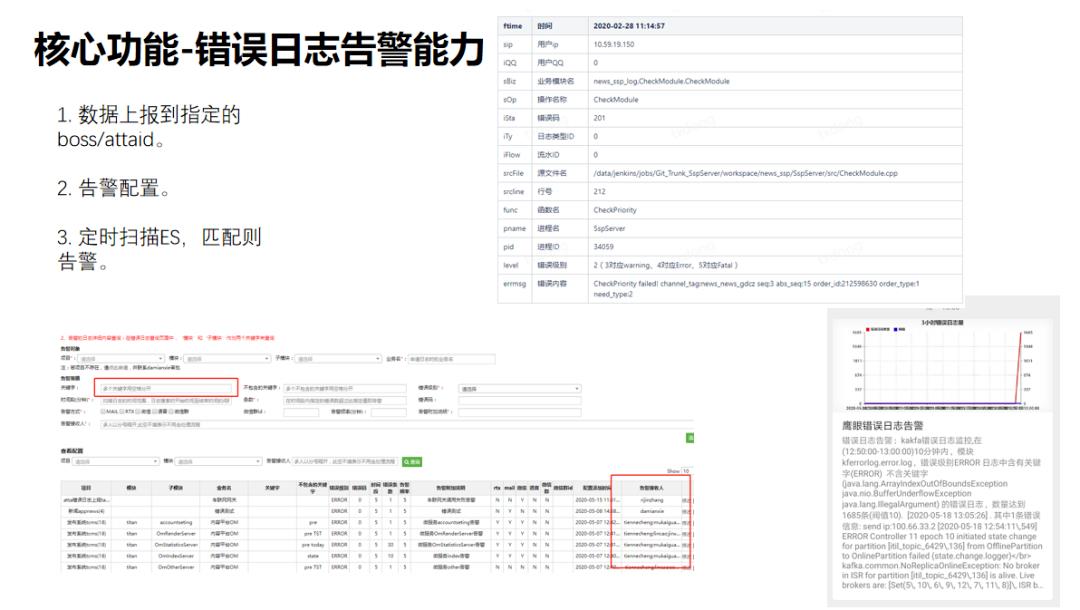
程序如果出现错误之后,可以按照鹰眼规范来上报错误日志,鹰眼进行分词,根据不同的错误码进行分钟级别的告警。
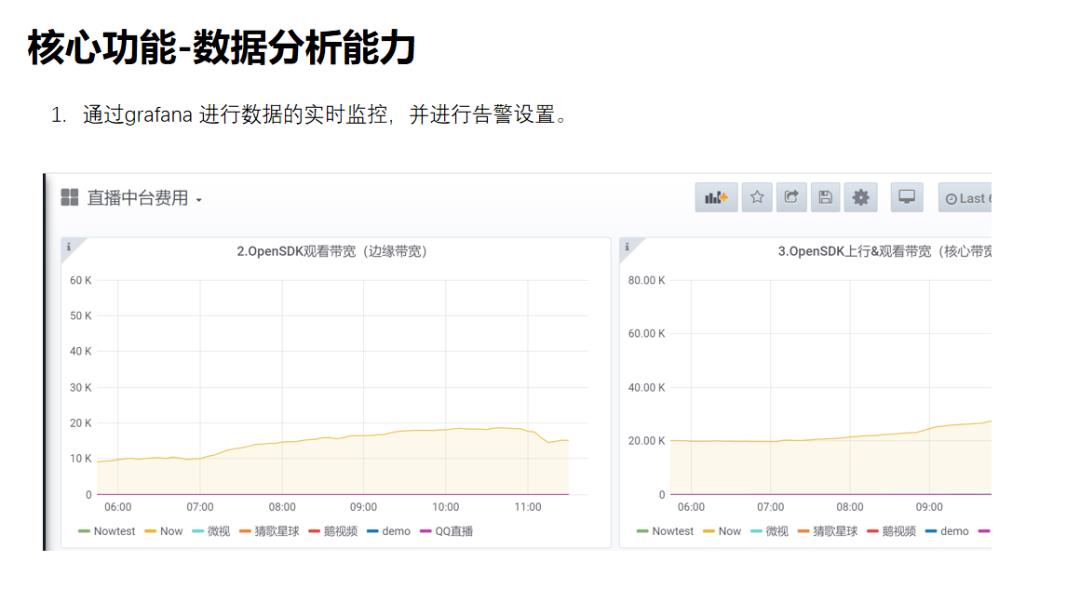
通过grafana对上报到鹰眼的数据进行实时的分析告警。
(由于ES不支持大并发查询,所以无法对超大数据进行实时分析)
公司战略调整,成立新的云事业群,内部成立“技术委员会”,启动“开源协同”和“业务上云”的两大战略方向。
在架构演进中,鹰眼团队上云能得到什么好处?上云的价值是什么?
为了保证业务的延续性和架构的演进,数据导入过程中的主体流程并没有太大改变,Kafka直接使用到云上的CKAFKA,ES直接使用到云上的ES。
ES和Kafka直接使用云上组件,其他组件需要进行重构。
生产者程序写入Kafka性能瓶颈特别大,高峰期丢数据特别严重。
生产者程序写数据流程:
读取BOSS订阅->IP解析->写入Kafka。
之前生产者程序是C++版本,经过打印日志,发现高峰期IP解析耗时特别严重。排查代码,发现IP解析加锁了。所以高峰期丢数据特别严重。
解决方法是:
将
IP解析改为二分查找算法来进行IP定位,然后取消锁,解决。
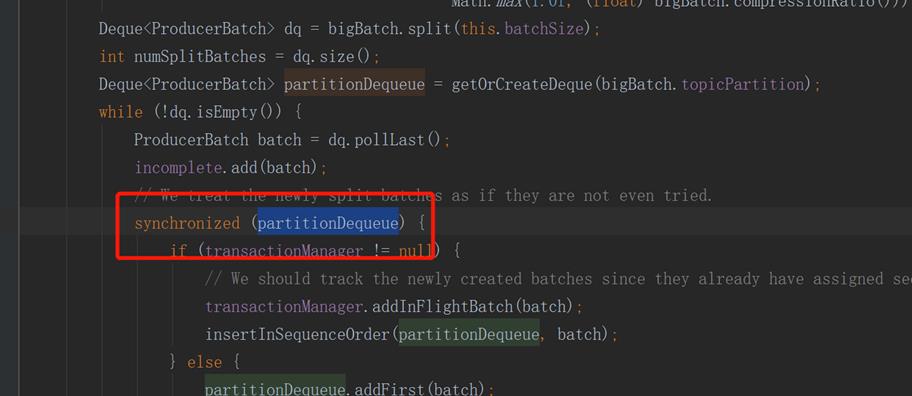
由于我们生产者程序,一个程序会读取很多很多个topic,然后写入到Kafka,我们尝试,使用一个producer和多个producer发送,性能都提升不起来。
经过源代码排查,发现Kafka发送时,会根据topic分区来锁队列,当这个队列满的时候,就会发送一批消息出去。所以解决方案为,每个BOSSID应该有独立的发送客户端。
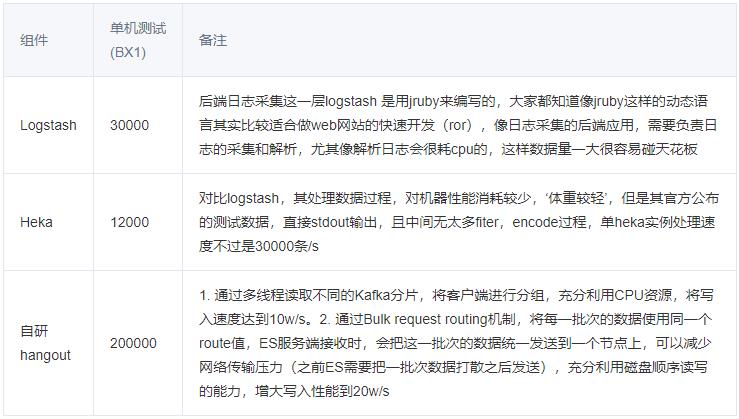
优化之后:在数据量非常大的时候,因为程序性能原因,会导致一分钟单节点最多只能处理13万条左右的数据。改进后, 单节点能处理55w条左右的数据。 性能提升4倍。
Kafka整体来说,高版本比低版本支持的功能更多,如事务,磁盘间的数据转移等,写入性能并不会下降。此处选型选的是最高版本。
当然CKAFKA并没有给我们选择版本的机会,客户端写入的时候还是得注意下和Kafka服务端版本一致,避免不必要的问题。
如低版本的客户端写入高版本的Kafka时,如果使用数据压缩,则服务端接受到数据后,会进行解压,然后再按照对应的格式压缩(如果版本一致,则不会有此动作),增加服务端的运行成本。
Kafka上云之后,单机性能能达到400MB/s,而我们自建的Kafka,单机性能最多达到100MB/s,性能提升4倍。
ES写入部分,业界有很多组件,最出名的是Logstach,由于性能不够,我们自己重新开发了一套读取Kafka写入ES的组件。
由于磁盘IO的大幅减少,能在极限优化下继续提升性能2倍以上。
整体来说,ES写入提升性能6倍左右。
ES低版本支持TCP写入和HTTP写入两种方式,高版本只支持一种HTTP写入方式。实测发现有如下区别:
TCP写入比HTTP更快;
-
HTTP写入更稳定一点,TCP写入是直接写到节点上面的,容易出现负载不均衡,HTTP更容易通过数据节点节点进行负载均衡。
ES/Kafka上云之后,统计有50多个ES集群,12个Kafka集群.
如果不上云的话,搭建这些集群平均一个ES集群需要20台机器,从申请机器,到机器初始化,磁盘RAID,安装ES,平均每个ES需要3-4人/天,则搭建成本就已经需要200多人(62*3-4)/天了,还没有谈到集群运维成本,远远超过鹰眼团队的人力。
上云之后,伴随着各个组件的优化,整体性能提升至少2-3倍,所需要的资源同比会减少2-3倍、每年节省成本至少2kw。
核心模块既要有日志,也要有监控,不同模块的监控维度对应起来,让核心的模块,日志和监控都有,当业务出现异常时,及时调出发生异常的基础数据(如CPU/Mem等),指标数据,日志数据等进行完整的监控体系的建设。
目前自研Hangout写入只能保证at least once,但是无法保证exactly once。尝试通过flink的checkpoint机制,保证数据链路的完整性。
以上是关于鹰眼海量级分布式日志系统上云的架构和实践的主要内容,如果未能解决你的问题,请参考以下文章
微服务运行时基础架构概述——微服务日志监控
百亿级日志系统架构设计及优化
实时海量日志分析系统的架构设计实现以及思考
斗鱼基于 Golang 在高并发场景下的日志系统实践
有赞百亿级日志系统架构设计
百亿级日志系统,如何架构实战 ? | 签到福利