斗鱼基于 Golang 在高并发场景下的日志系统实践
Posted GoCN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了斗鱼基于 Golang 在高并发场景下的日志系统实践相关的知识,希望对你有一定的参考价值。
1 概述
日志是记录系统中各种问题信息的关键,也是一种常见的海量数据。做好日志可以有效的解决排查问题效率低、业务异常无法及时发现等等问题。
斗鱼的业务是经典的高并发场景:我们会由于某些业务场景,用户请求量会十倍秒级突增。为了针对这种场景,提高服务性能,我们不仅要优化业务逻辑,同时还要提升日志等基础组件的性能。以下是我们斗鱼go的日志类库架构图:
从架构图的日志组件中我们列举了三个重要组成部分。首先是日志的使用,我们提供了sugar、desugar、lazy-output的三种模式。根据使用场景,业务方可以选择不同的模式。例如在高并发场景情况下,可以使用编码稍微麻烦,但性能较好的desugar模式。在后台业务场景,可以使用性能差点,但编码友好的sugar模式;第二部分是日志的落盘,我们提供了配置项可以让业务方开启同步落盘,还是异步落盘,并且在异步落盘的时候,我们还针对落盘的时间和大小进行了测试,下文中会详细介绍;第三部分是日志的降级功能,我们也提供了配置项可以让业务方选择是否开启降级功能,我们的框架会将日志会拆分成info,err两种日志文件(参考ngx的日志)。这样的好处就是我们可以对info日志很好的降级,但err日志不会受任何影响,能够更好的去监控我们服务的错误问题。
2 日志库实践
直播流服务作为斗鱼的核心服务,记录的日志价值比较重要,我们能根据日志内容做报表分析、问题排查、流防刷等事情。但过多的日志又会影响服务性能。一方面我们需要日志帮我们解决业务上的问题,一方面又希望能日志不影响服务性能。
基于我们的业务场景,我们对日志库的需求如下:
高性能:我们的业务场景中有很多服务是会有突发流量的,因此日志的性能必须不能成为业务的瓶颈;
结构化:我们的很多业务会产生有价值的日志,因此日志必须结构化以便进行业务和服务的报表分析;
分级:在一定的场景下异步日志会退化成同步,为了保证业务的性能和可用性,不可避免的会需要对日志进行分级处理,即丢弃一部分非核心日志,保留核心日志;
标准化:日志标准化后可以方便做告警、报表等;
在golang日志库上我们没有必要完全重新造轮子,那么现有的开源组件中我们应该选择使用哪个呢?
2.1 日志库选型
基于以上我们对日志的需求,我们研究了部分golang主流开源日志库,最后我们选择了性能最好的zap。以下为各日志类库的性能对比表:
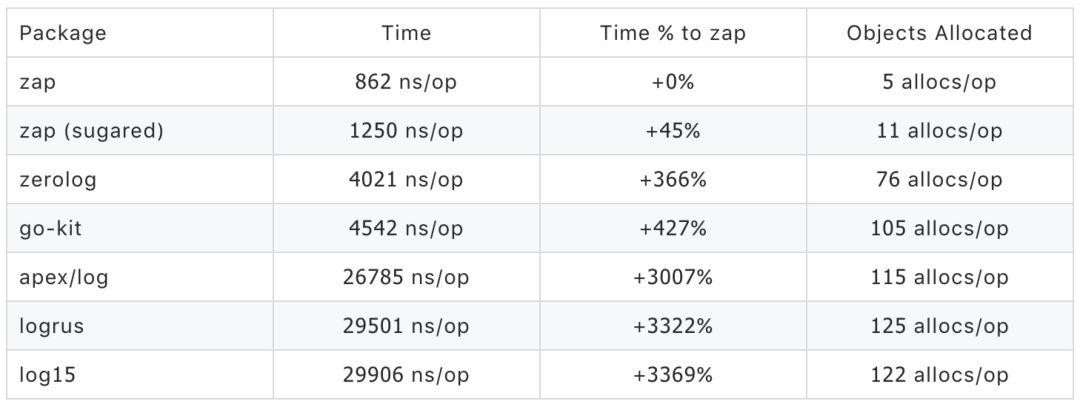
zap是一个比较优秀的日志组件。提供了sugar和desugar模式。方便业务方根据不同场景,选择不同的日志使用方式。并且提供了大量接口,方便业务方去改造日志类库。因此我们的日志是在zap的基础上进行了wrap,规范了日志用法、提供了日志插件。更好的适用于我们斗鱼的业务场景。
2.2 日志规范
斗鱼后端已经全面微服务化,线上运行上几百个各类业务服务。大量的服务每时每刻都在产生大量的日志。我们要基于这些日志数据进行业务的告警、分析运营数据、分析各类业务异常场景。如果没有统一的日志规范,服务的日志很难收敛,也很难去作分析。
2.2.1 日志分类分级
首先,我们将日志分为三种类型,access请求类型,worker任务类型,biz业务类型。基础框架处理access和worker类型日志,用户业务处理biz类型日志。
其次,我们的日志错误级别包含5中类型panic,error,warn,info,debug。panic、error日志均做了统一的告警处理。我们的debug日志结合配置中心的动态配置,可以很方便我们排查线上问题。并且日志会根据级别拆分成info,err两种日志文件(参考ngx的日志)。这样的好处就是我们可以对info日志很好的降级,但err日志不会受任何影响,能够更好的去监控我们服务的错误问题。
最后,我们将日志分层成框架日志和业务日志,主要是为了做日志的采集分流,同时框架集成统一的access、worker日志可以方便我们进行统一监控告警、统一业务报表。
2.2.2 access日志
那么我们的日志都包含哪些字段呢?这里我们以access日志为例:
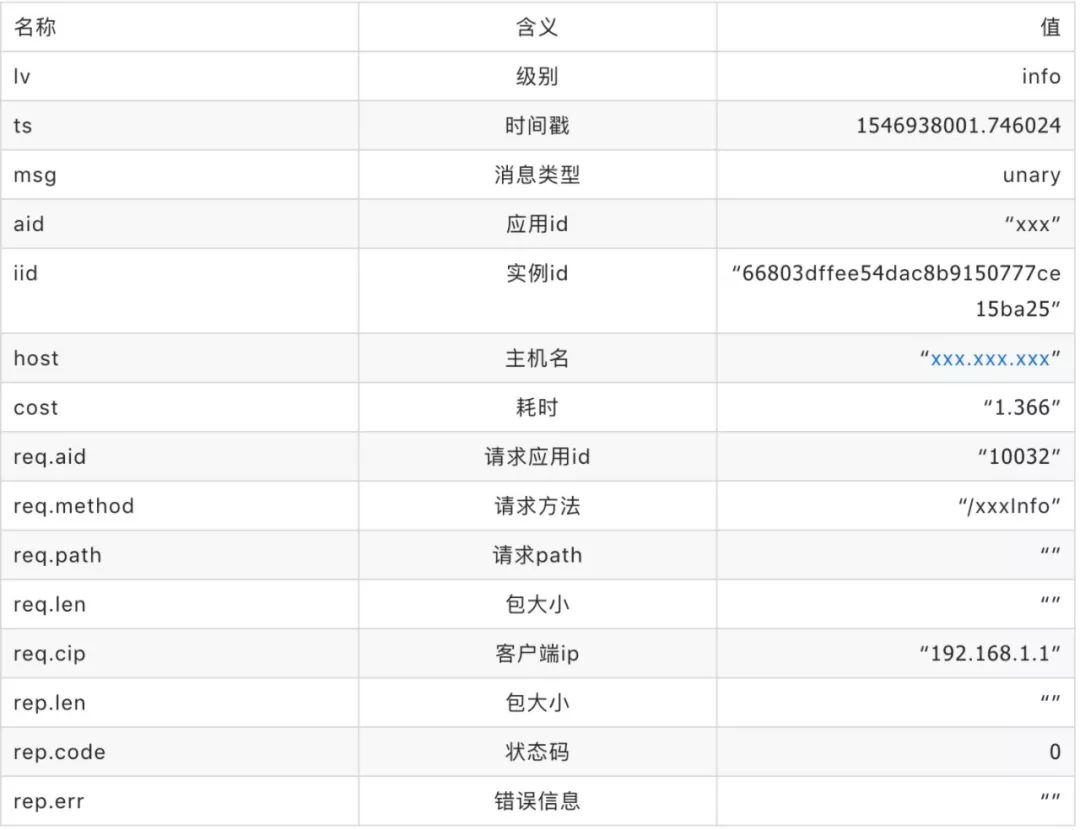

我们可以看到,在access日志里面记录了日志级别、时间戳、消息类型、应用ID、实例ID、主机名、耗时等关键信息。基于这些信息,我们可以快速的排查问题。
2.2.3 慢日志
我们针对服务和客户端等io操作都进行了调用耗时埋点。记录了超过阈值的调用耗时时间,方便业务方排查问题。
2.3 性能调优
下面在介绍下我们日志中遇到的坑,我们的业务在上云的过程中做性能压测,发现性能相比于物理机有较大差距。物理机的磁盘性能更好,云上使用的云盘性能相对较差。导致日志落盘性能很差。我们的日志落盘目前经过改造是异步化的。但是当磁盘性能达不到要求时,就会退化成同步写磁盘。同步写磁盘产生的耗时最终会反应到业务性能指标上。下面我们一起来看一下压测过程中发现的问题及排查优化过程。
2.3.1 问题:日志性能导致业务耗时急剧增加
在QPS达到4000+(10s采集一次数据,图中指标要除以10),通过我们的性能监控平台可以看到服务出现突发式性能剧降。如下图所示:
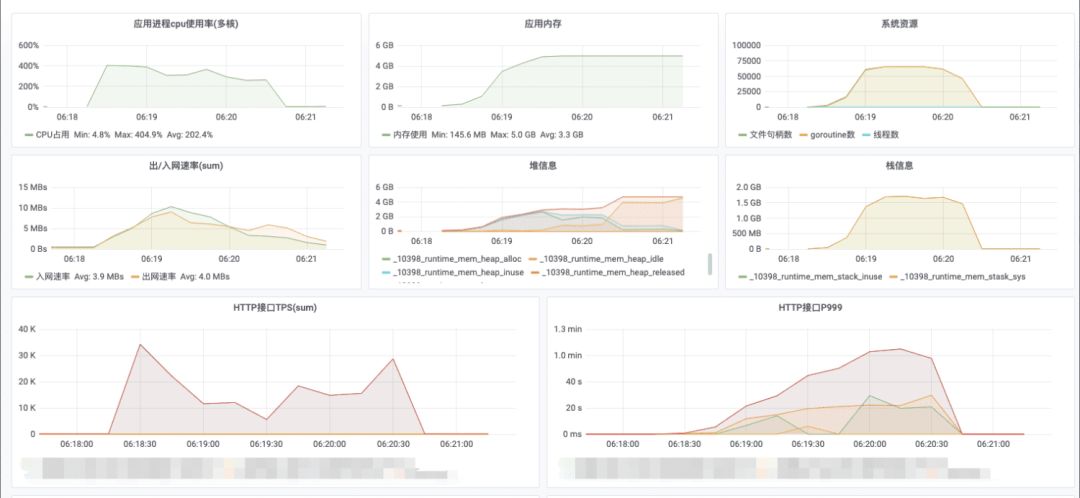
内存、Goroutine、响应耗时出现断层式增长,耗时达分钟级,CPU并未出现波动,但此时服务基本不可用。一般出现这种现象说明遇到了性能瓶颈,是坏事也是好事,坏事是因为这个瓶颈导致服务性能上不去,好事是这类明显的瓶颈一旦解决,服务量级可以数倍提升。
2.3.1 现象分析
可以看到cpu、内存增长算快但未达到真正瓶颈,最为诡异的是Goroutine的增长。通过我们的服务治理平台来看一下发生时的profile,如下图所示:

内存火焰图中,大头都是bufferWriterSync.Write 。而这个函数正是写日志操作。为什么写日志会导致性能下降呢?这里我们一起来分析一下代码。
2.3.2 分析代码
在写日志的时候,考虑到需要申请空间复制日志,在复制的时候采用了sync.Pool来进行对象的重复使用,避免GC对性能的影响。
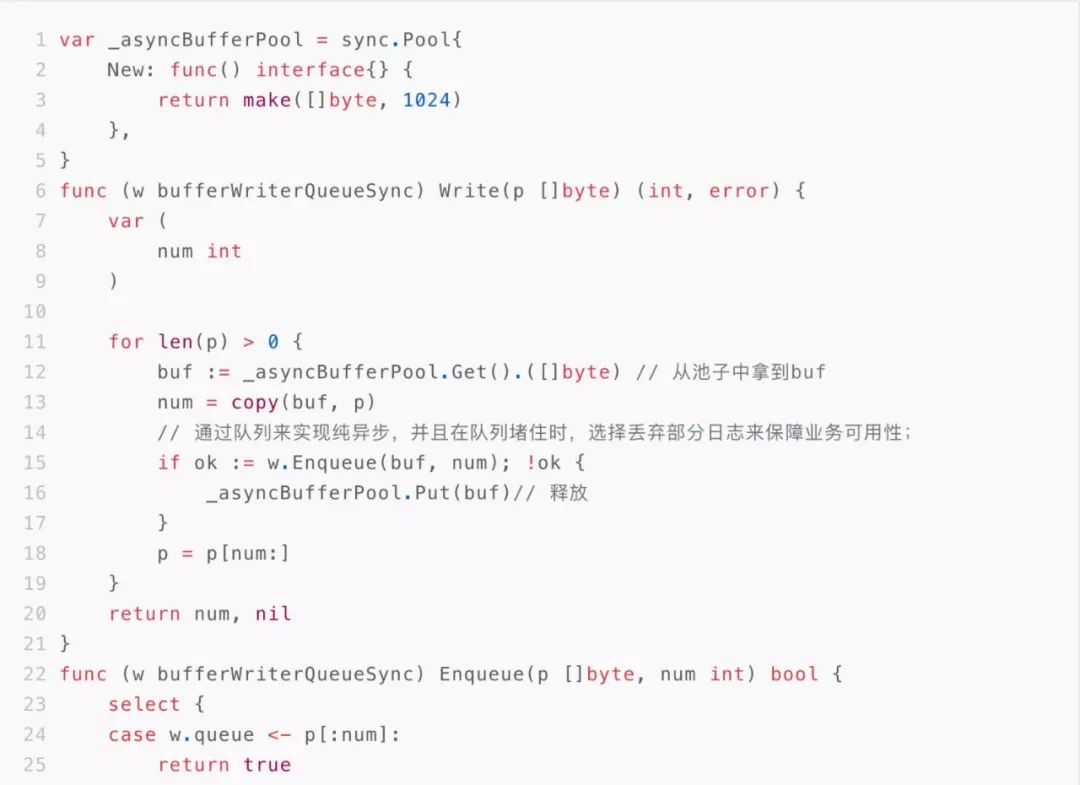

2.3.3 深入分析
上面的代码为什么会在并发数达到一定范围后性能急剧下降呢?导致性能急剧下降,而各类资源又未达到瓶颈,这样的情况很大概率是锁导致的。我们仔细分析这段代码,发现唯一有锁的地方就是这里使用sync.Pool。一起看看sync.Pool的源码。(此代码为go1.12版本的)
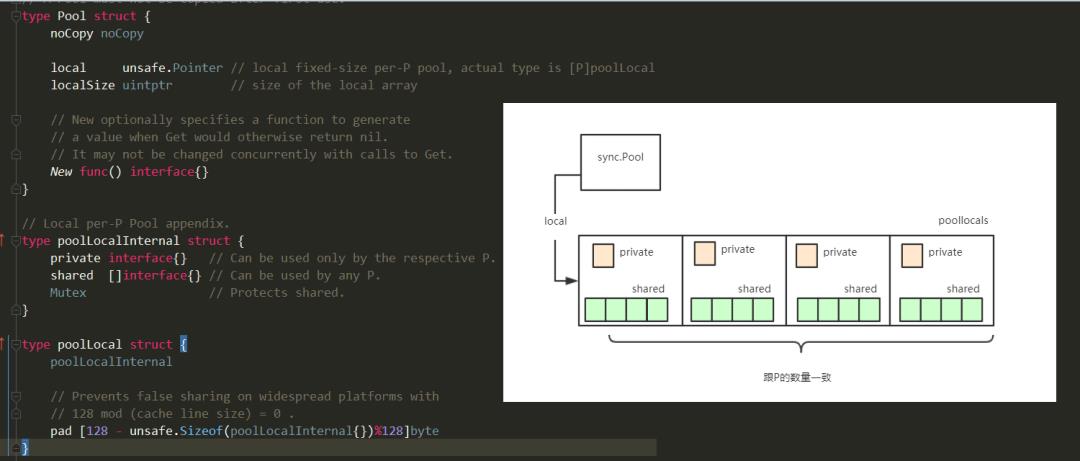
sync.Pool为每个P(对应cpu,不清楚的童鞋可以参见golang的GMP调度模型)分配一个poollocal子池,poollocal中有一个私有对象pricvate和一个共享对象列表shared。私有对象专属此P使用,因此不需要上锁,共享对象可以互相偷着用,因此共享对象的使用需要上锁 从池子中获取对象的过程如图:
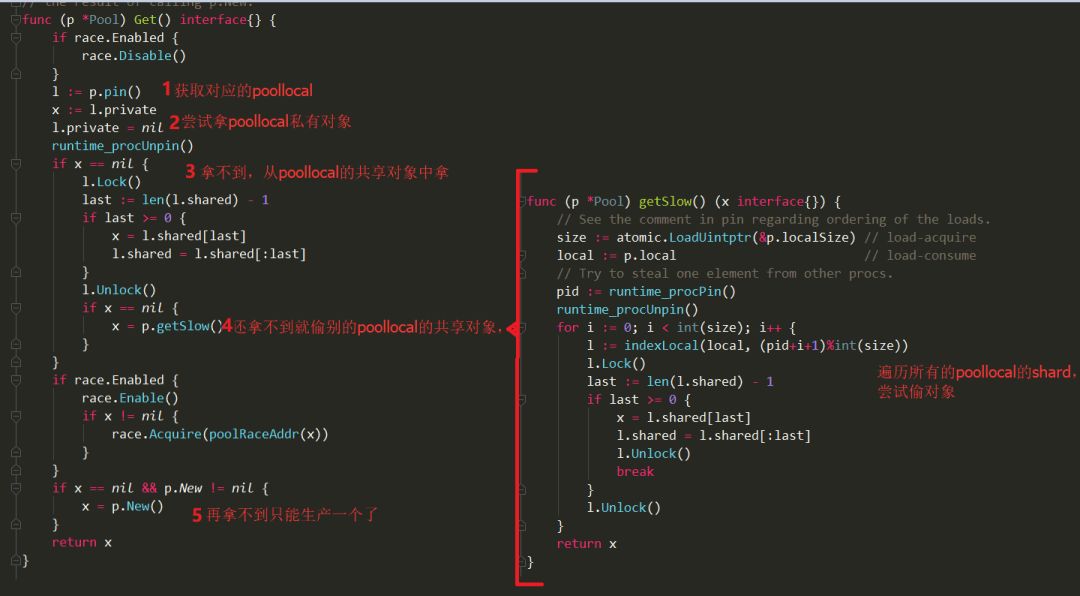
因此步骤3、4在高并发场景下,池子不够用时,每生产一个对象以为着需要把poollocal的锁遍历一遍即num(P)*num(shard),这个过程引发大量锁竞争行为,因此导致性能急剧下降。有童鞋可能会对1的过程比较感兴趣,发现里面也会有一个全局锁:
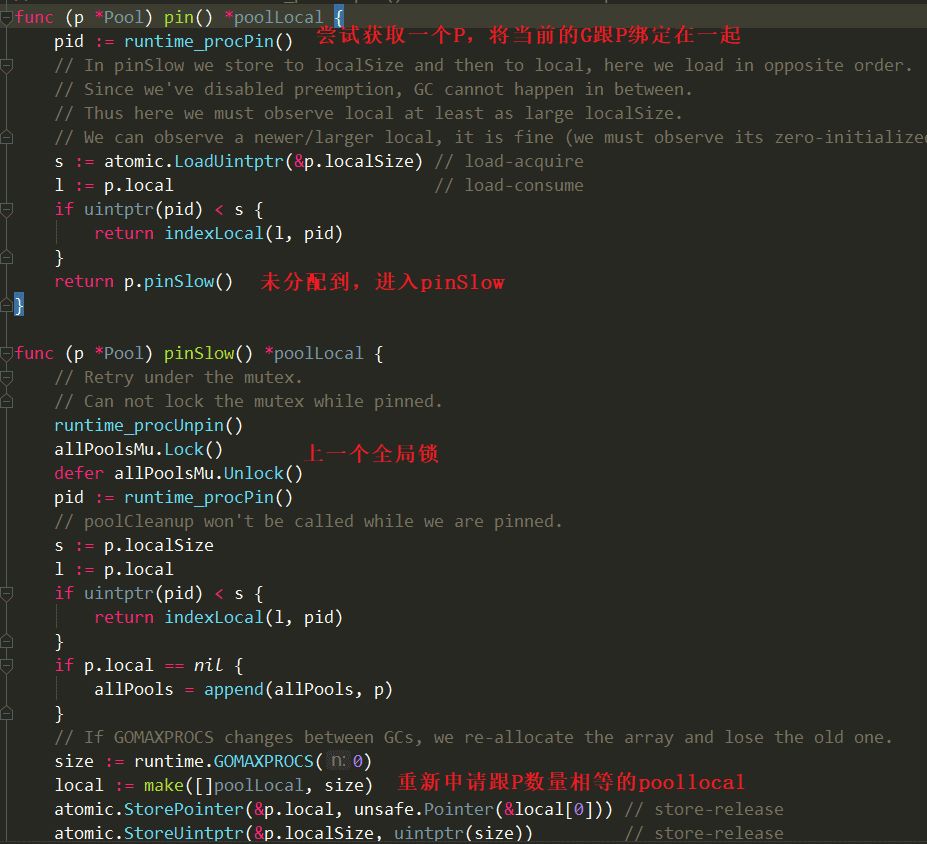
什么时候会进入pinSlow,在GC前会调用poolCleanup 将localpool全部置空,回收所有的sync.pool,因此只有在GC后才会进入pinSlow的调用。
通过上面的代码分析,仅在获取sync.Pool里存在锁的情况。写日志的过程主要是io操作,在实际压测过程中发现gc压力并不大,因此这里我们将之前使用sync.Pool的部分调整为直接分配内存。以减少sync.Pool锁问题带来的性能损耗。调整后的代码如下:
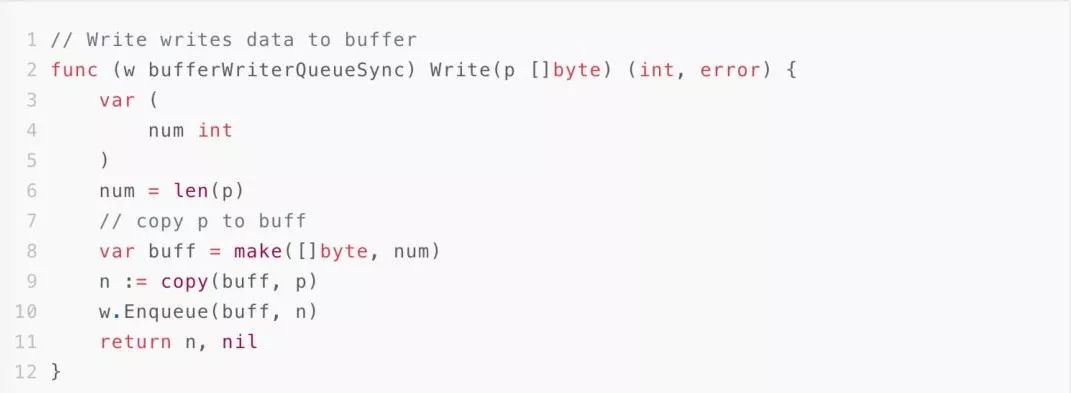
针对调整后的代码,我们又进行了压测,压测结果恢复正常。
2.3.5 结果对比
经调整后,请求量最大可压至1w5左右,此时Goroutine的量保持恒定,内存占用量小,主要是cpu压到1500%达到瓶颈。

3 总结
上面我们分析了日志性能调优的过程,在我们实际的业务使用过程中陆陆续续踩过了各种坑。得出在使用日志时,需要结合场景来做好日志分级。
日志尽量做好分级处理,在极限情况下哪些日志可以丢弃,哪些日志不可以丢弃;
日志字段尽量精简,单次请求建议合并一条日志;
使用desugar,避免大量反射;
经过性能优化后,为了验证优化结果在不同场景下的表现情况,我们后续又做了大量的压测对比。具体的压测数据见后面的附录。
4 优化压测数据
4.1 200G云盘测压结果
4.1.1 4K 小io顺序写
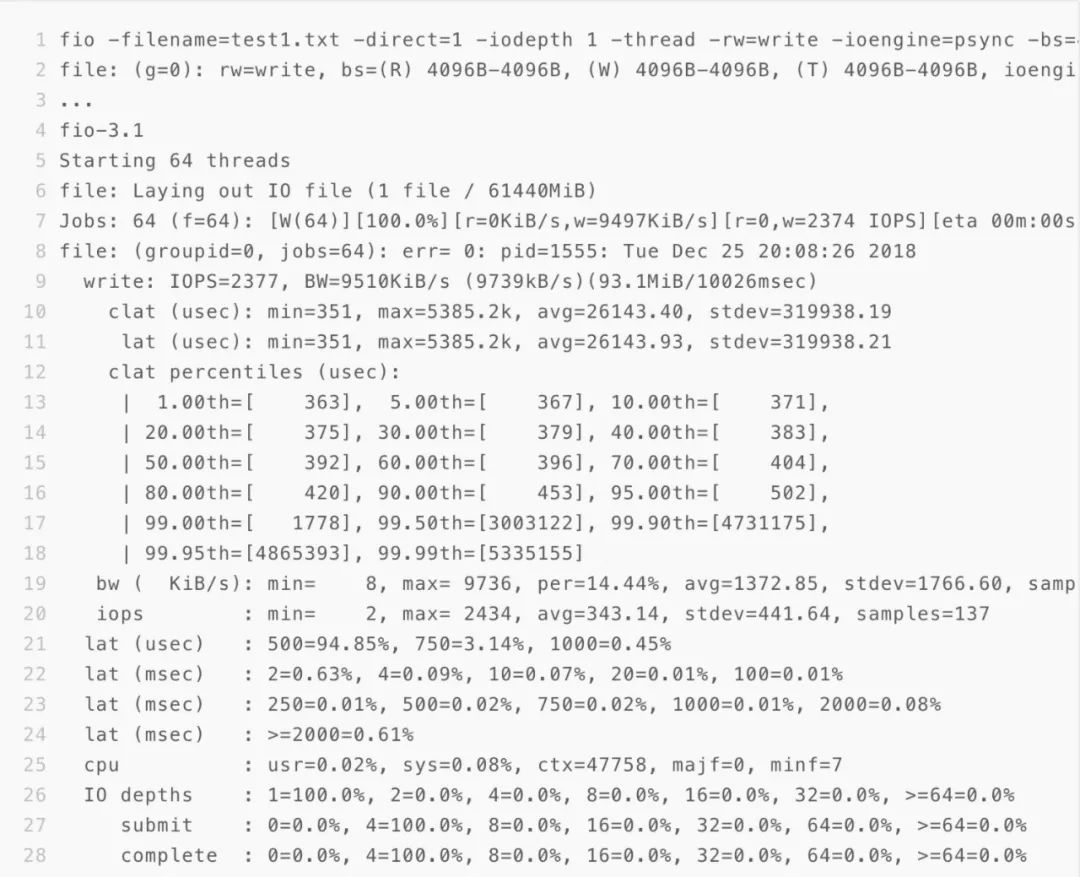

4.1.2 256K 大io顺序写


4.1.3 4096K 超大io顺序写
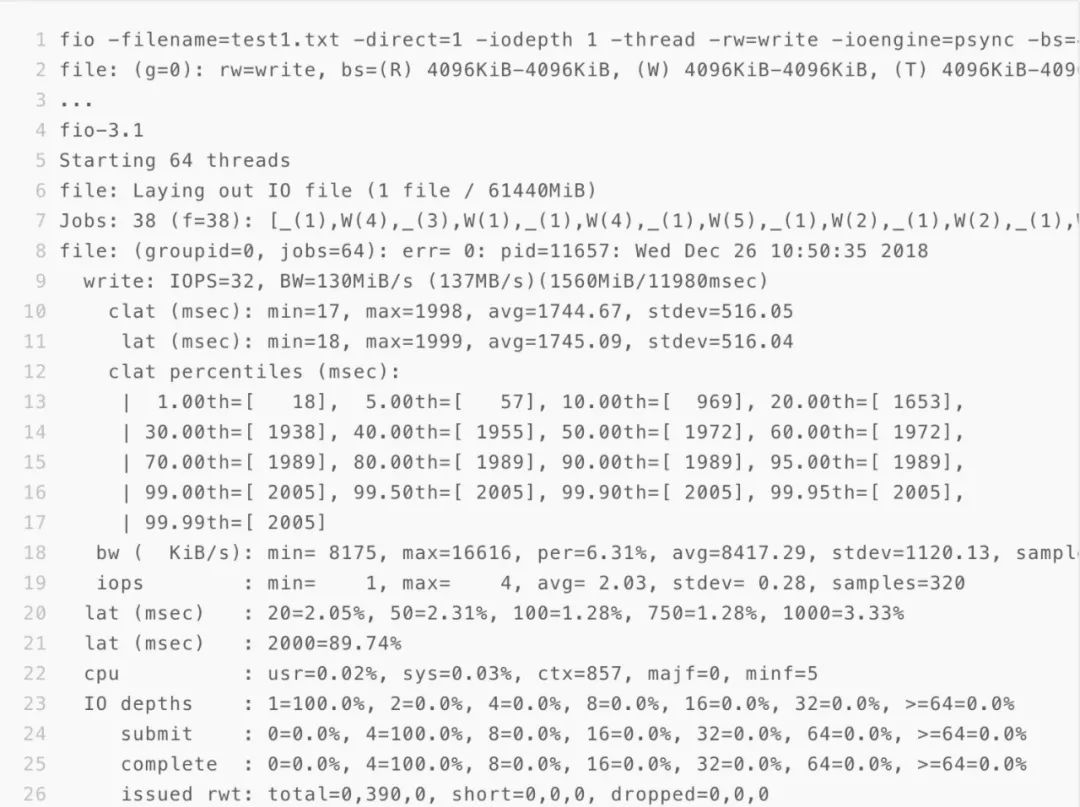

4. 2 log benchmark结果
4.2.1 windows: ssd
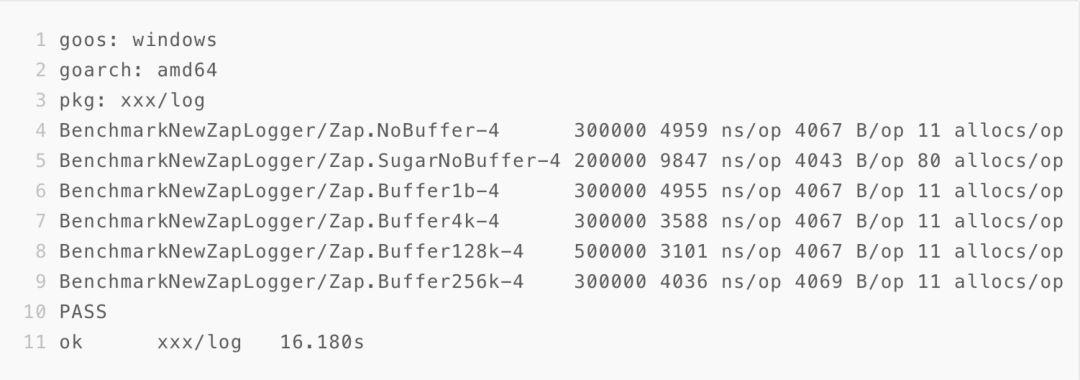
4.2.2 linux: virutalbox
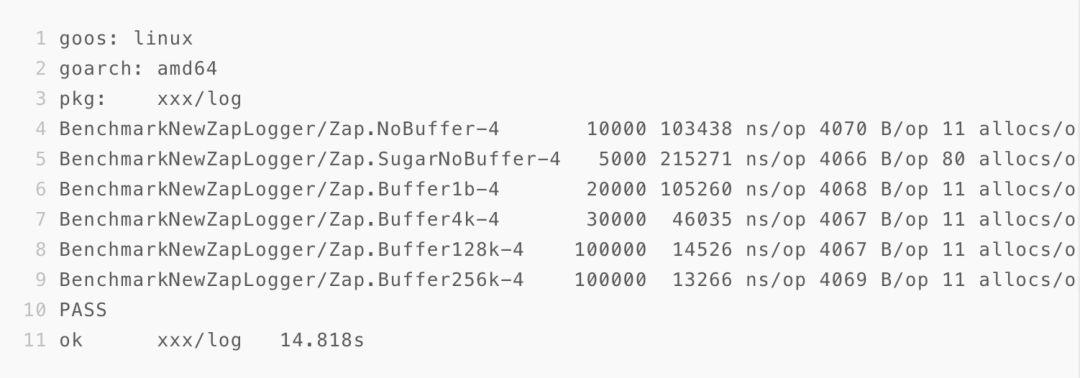
4.3 业务Access压测
压测Golang代码,处理逻辑统一sleep 10ms

4.3.1 调高日志等级,不写日志
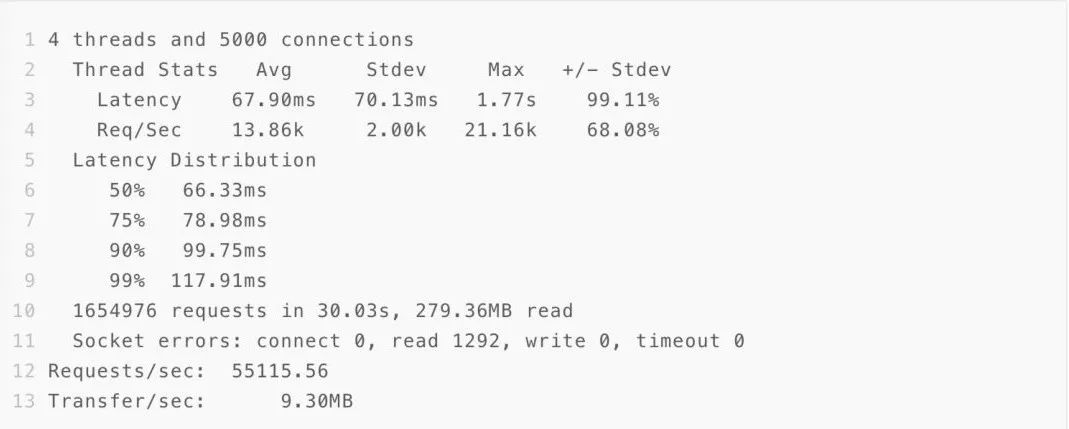
4.3.2 异步写日志

4.3.3 128K buffer+异步写日志
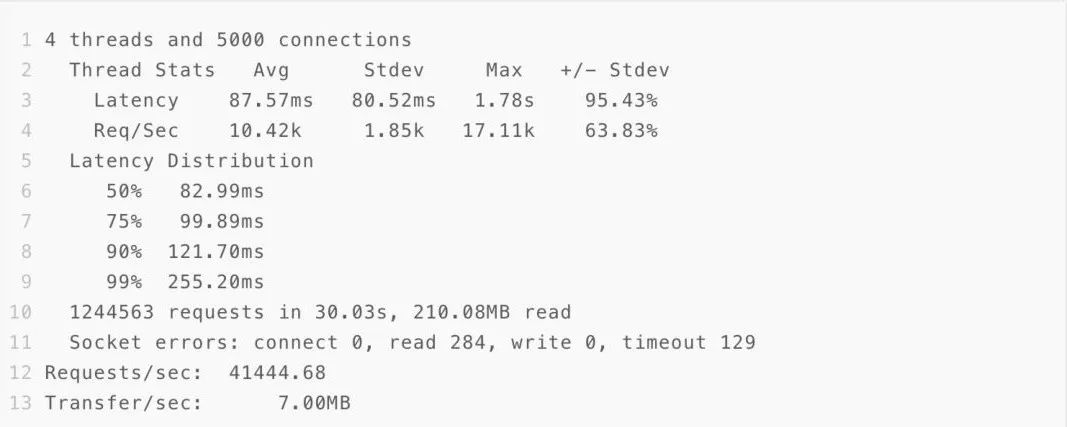
4.3.4 128K buffer+异步+优化access中间件
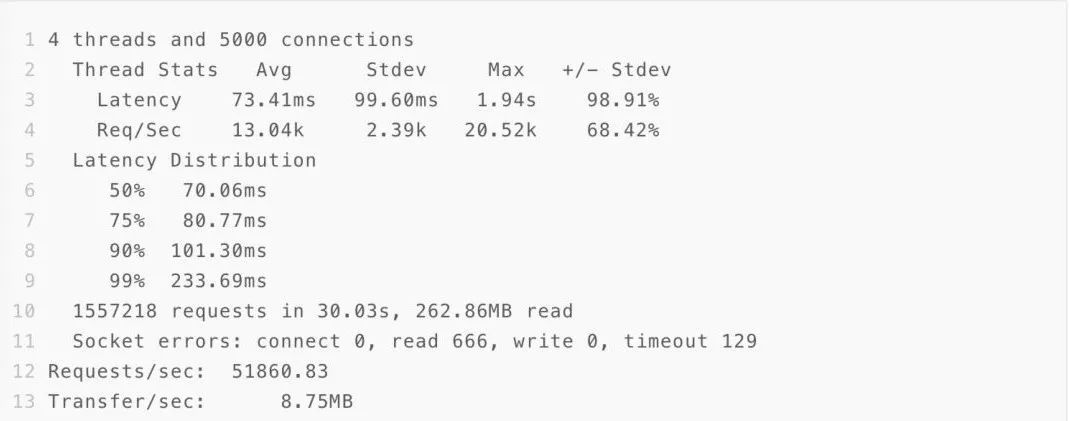
附 延伸阅读
sync.Pool通过对象复用确实可以减少gc的延迟,同时sync.Pool也引入了新的损耗,sync.Pool损耗主要体现在锁竞争上。go 1.13版在sync.Pool下了不少功夫来优化锁。具体信息可以参考下面的提交说明。
sync.Pool 变更 commit(扫二维码跳转)


以上是关于斗鱼基于 Golang 在高并发场景下的日志系统实践的主要内容,如果未能解决你的问题,请参考以下文章