花了 1000G,我终于弄清楚了 Serverless 是什么(上)?
Posted phodal
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了花了 1000G,我终于弄清楚了 Serverless 是什么(上)?相关的知识,希望对你有一定的参考价值。
在过去的 24 小时,我通过微信公号的『电子书』一事,大概处理了 8000 个请求:
大部分的请求都是在 200ms 内完成的,而在最开始的请求潮里(刚发推送的时候,十分钟里近 1500 个请求),平均的响应时间都在 50ms 内。
 Serverless 请求时间
Serverless 请求时间
这也表明了,Serverless 相当的可靠。显然,当请求越多的时候,响应时间越快,这简直有违常理——一般来说,随着请求的增加,响应时间会越来越慢。
毫无疑问,在最近的几年里,微服务渐渐成为了一个相当流行的架构风格。微服务大致从 2014 年起,开始流行开来,如下图所示:
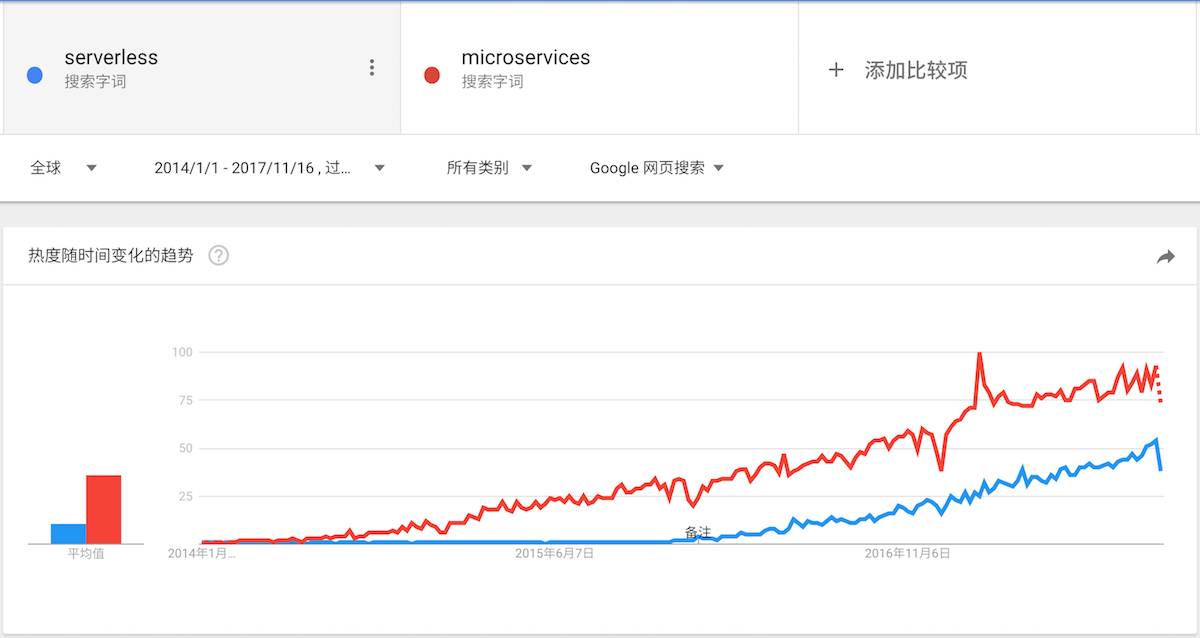 microservices vs serverless
microservices vs serverless
而微服务是从 2016 年起,开始受到开发者的关注。并且从其发展趋势来看,它大有可能在两年后,拥有今天微服务一样的地位。可见,它是一个相当具有潜力的架构。
什么是 Serverless 架构??
为了弄清 Serverless 究竟是什么东西?Serverless 到底是个什么?我使用 Serverless 尝试了一个又一个示例,我自己也做了四五个应用,总算是对 Serverelss 有了一个大致上的认识。
虚拟化与隔离
开发人员为了保证开发环境的正确(即,这个 Bug 不是环境因素造成的),想出了一系列的隔离方式:虚拟机、容器虚拟化、语言虚拟机、应用容器(如 Java 的 Tomcat)、虚拟环境(如 Python 中的 virtualenv),甚至是独立于语言的 DSL。
从最早的物理服务器开始,我们都在不断地抽象或者虚拟化服务器。
我们使用 XEN、KVM等虚拟化技术,隔离了硬件以及运行在这之上的操作系统。
我们使用云计算进一步地自动管理这些虚拟化的资源。
我们使用 Docker 等容器技术,隔离了应用的操作系统与服务器的操作。
现在,我们有了 Serverless,我们可以隔离操作系统,乃至更底层的技术细节。
为什么是花了 1000G ?
现在,让我简单地解释『花了 1000G,我终于弄清楚了 Serverless 是什么?』这句话,来说说 Serverless 到底是什么鬼?
在实践的过程中,我采用的是 AWS Lambda 作为 Serverless 服务背后的计算引擎。AWS Lambda 是一种函数即服务(Function-as-a-Servcie,FaaS)的计算服务,简单的来说就是:开发人员直接编写运行在云上的函数、功能、服务。由云服务产商提供操作系统、运行环境、网关等一系列的基础环境,我们只需要关注于编写我们的业务代码即可。
是的,你没听错,我们只需要考虑怎么用代码提供价值即可。我们甚至连可扩展、蓝绿部署等一系列的问题都不用考虑,Amazon 优秀的运营工程师已经帮助我们打造了这一系列的基础设施。并且与传统的 AWS 服务一样,如 Elastic Compute Cloud(EC2),它们都是按流量算钱的。
那么问题又来了,它到底是怎么对一个函数收钱的。我在 Lambda 函数上运行一个 Hello, world 它会怎么收我的钱呢?
如果要对一个运行的函数收费,那么想必只有运行时间、CPU、内存占用、硬盘这几个条件。可针对于不同的需求,提供不同的 CPU 是一件很麻烦的事。对于代码来说,一个应用占用的硬盘空间几乎可以忽略不计。当然,这些应用会在你的 S3 上有一个备份。于是,诸如 AWS 采用的是运行时间 + 内存的计算方式。
| 内存 (MB) | 每个月的免费套餐秒数 | 每 100ms 的价格 (USD) |
|---|---|---|
| 128 | 3,200,000 | 0.000000208 |
| 192 | 2,133,333 | 0.000000313 |
| 256 | 1,600,000 | 0.000000417 |
| ... | ... | ... |
| 1024 | 400,000 | 0.000001667 |
| ... | ... | ... |
在运行程序的时候,AWS 会统计出一个时间和内存,如下所示:
REPORT RequestId: 041138f9-bc81-11e7-aa63-0dbab83f773d Duration: 2.49 ms Billed Duration: 100 ms Memory Size: 1024 MB Max Memory Used: 20 MB
其中的 Memory Size 即是我们选用的套餐类型,Duration 即是运行的时间,Max Memory Used 是我们应用运行时占用的内存。根据我们的 Max Memory Used 数值及应用的计算量,我们可以很轻松地计算出我们所需要的套餐。
因此,如果我们选用 1024M 的套餐,然后运行了 320 次,一共算是使用了 320G 的计算量。而其运行时间会被舍入到最近的 100ms,就算我们运行了 2.49ms,那么也是按 100ms 算的。那么假设,我们的 320 次计算都花了 1s,也就是 10100ms,那么我们要支付的费用是:10320*0.000001667=0.0053344刀,即使转成人民币也就是不到 4 毛钱的 0.03627392。
如果我们先用的是 128M 的套餐,那么运行了 2000 次,就是 200G 的计算量了。
如果我们先用的是 128M 的套餐,那么运行了 8000 次,就是 1000G 的计算量了。
不过如上表所示,AWS 为 Lambda 提供了一个免费套餐(无期限地提供给新老用户)包含每月 1M 免费请求以及每月 400 000 GB 秒的计算时间。这就意味着,在很长的时间里,我们一分钟都不用花。
Serverless 是什么?
而从上节的内容中,我们可以知道这么几点:
在 Serverless 应用中,开发者只需要专注于业务,剩下的运维等工作都不需要操心
Serverless 是真正的按需使用,请求到来时才开始运行
Serverless 是按运行时间和内存来算钱的
Serverless 应用严重依赖于特定的云平台、第三方服务
当然这些都是一些虚无缥缈地东西。
按 AWS 官方对于 Serverless 的介绍是这样的:
服务器架构是基于互联网的系统,其中应用开发不使用常规的服务进程。相反,它们仅依赖于第三方服务(例如AWS Lambda服务),客户端逻辑和服务托管远程过程调用的组合。”[^aws_serverless]
在一个基于 AWS 的 Serverless 应用里,应用的组成是:
网关 API Gateway 来接受和处理成千上万个并发 API 调用,包括流量管理、授权和访问控制、监控等
计算服务 Lambda 来进行代码相关的一切计算工作,诸如授权验证、请求、输出等等
基础设施管理 CloudFormation 来创建和配置 AWS 基础设施部署,诸如所使用的 S3 存储桶的名称等
静态存储 S3 作为前端代码和静态资源存放的地方
数据库 DynamoDB 来存储应用的数据
等等
以博客系统为例,当我们访问一篇博客的时候,只是一个 GET 请求,可以由 S3 为我们提供前端的静态资源和响应的 html。
Serverless SPA 架构
而当我们创建一个博客的时候:
我们的请求先来到了 API Gateway,API Gateway 计费器 + 1
接着请求来到了 Lambda,进行数据处理,如生成 ID、创建时间等等,Lambda 计费器 + 1
Lambda 在计算完后,将数据存储到 DynamoDB 上,DynamoDB 计费器 + 1
最后,我们会生成静态的博客到 S3 上,而 S3 只在使用的时候按存储收费。
在这个过程中,我们使用了一系列稳定存在的云服务,并且只在使用时才计费。由于这些服务可以自然、方便地进行调用,我们实际上只需要关注在我们的 Lambda 函数上,以及如何使用这些服务完成整个开发流程。
因此,Serverless 并不意味着没有服务器,只是服务器以特定功能的第三方服务的形式存在。
当然并不一定使用这些云服务(如 AWS),才能称为 Serverless。诸如我的同事在 《Serverless 实战:打造个人阅读追踪系统》,采用的是:IFTTT + WebTask + GitHub Webhook 的技术栈。它只是意味着,你所有的应用中的一部分服务直接使用的是第三方服务。
在这种情况下,系统间的分层可能会变成一个又一个的服务。原本,在今天主流的微服务设计里,每一个领域或者子域都是一个服务。而在 Serverless 应用中,这些领域及子域因为他们的功能,又可能会进一步切分成一个又一个 Serverless 函数。
更小的函数
只是这些服务、函数比以往的粒度更加细致。
更多精彩内容,请期待下一篇
以上是关于花了 1000G,我终于弄清楚了 Serverless 是什么(上)?的主要内容,如果未能解决你的问题,请参考以下文章
终于有人把tomcat讲清楚了!阿里大牛推荐的tomcat架构解析文档
终于有人把tomcat讲清楚了!阿里大牛推荐的tomcat架构解析文档