redis源码阅读-终于把内存占用算清楚了
Posted 5ycode
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis源码阅读-终于把内存占用算清楚了相关的知识,希望对你有一定的参考价值。
在我计算key个value的空间的时候,发现我使用命令获取的和自己算的总是对不上。比如
命令行执行
local:0>set 5ycode yxkong
"OK"
local:0>OBJECT ENCODING 5ycode
"embstr"
local:0>DEBUG OBJECT 5ycode
"Value at:0x7f9dc6a0e180 refcount:1 encoding:embstr serializedlength:7 lru:14046288 lru_seconds_idle:32"
local:0>memory usage 5ycode
"56"
local:0>Append 5ycode 1
"7"
local:0>OBJECT ENCODING 5ycode
"raw"
local:0>memory usage 5ycode
"66"
我开始手动计算,我的依据是以下的数据结构 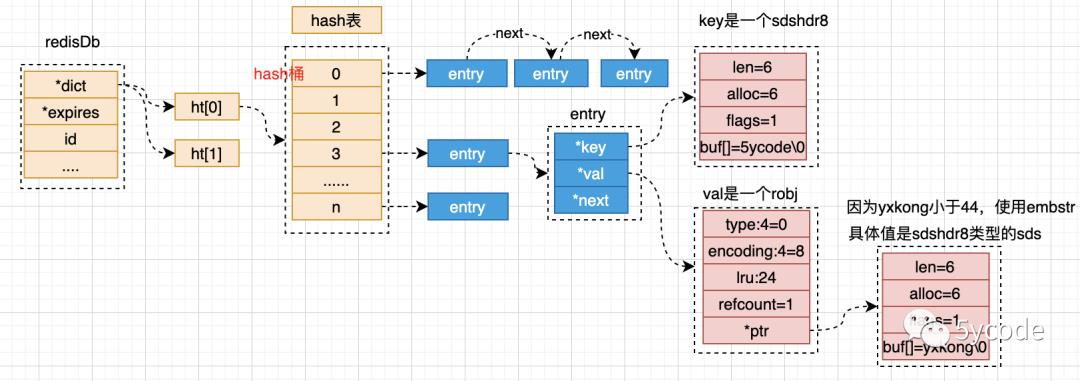
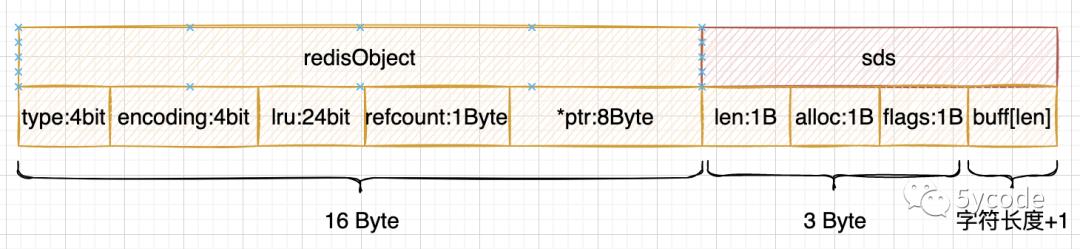
typedef struct redisObject
//robj存储的对象类型
unsigned type:4; //4位
// 编码
unsigned encoding:4; //4位
/**
* @brief 24位
* LRU的策略下:lru存储的是 秒级时间戳的低24位,约194天会溢出
* LFU的策略下:24位拆为两块,高16位(最大值65535)低8位(最大值255)
* 高16存储的是 存储的是分钟级&最大存储位的值,要溢出的话,需要65535%60%24 约 45天溢出
* 低8位存储的是近似统计位
* 在lookupKey进行更新
*/
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
//引用次数,当为0的时候可以释放就,c语言没有垃圾回收的机制,通过这个可以释放空间
int refcount; //4字节
/**
* 指针有两个属性
* 1,指向变量/对象的地址;
* 2,标识变量/地址的长度;
* void 因为没有类型,所以不能判断出指向对象的长度
*/
void *ptr; // 8字节
robj;//一个robj 占16字节
//因为在客户端解析的时候创建的是sdshdr8
struct __attribute__ ((__packed__)) sdshdr8
//1字节 max= 255 已用空间
uint8_t len; /* used */
//1字节 申请的buf的总空间,max255(不包含flags、len、alloc这些)
uint8_t alloc;
// 1字节 max= 255
unsigned char flags;
// 字节数组+1结尾\\0
char buf[];
;//4+n 长度
//key val关系
typedef struct dictEntry
void *key;//64位系统占8字节 32位系统占4字节
void *val;//64位系统占8字节 32位系统占4字节
struct dictEntry *next; //64位系统占8字节 32位系统占4字节
dictEntry; //占24字节
开始计算embstr编码的:
key 是一个sds字符串,共计:10字节:
len+alloc+flags=3字节
buf[] = 6(5ycode)+1(\\0)=7字节
entry:3*8= 24 字节
value 是一个robj+sdshdr8: 26字节
robj结构体:16字节
sds中: len+alloc+flags:3字节
buf[] 6(yxkong)+1(\\0)=7
共计:10+24+26=60
waht?
memory usage 5ycode 得出的结果是56字节,手动算出来是60字节?
不对啊,开始撸代码
db.c
/**
* @brief 将对应的key 和 redisObject对象塞入到全局hash表中
*
* @param db
* @param key
* @param val
*/
void dbAdd(redisDb *db, robj *key, robj *val)
//生成一个固定长度的sds字符串作为key(因为key没有动态扩容,所以不需要多申请空间)
sds copy = sdsdup(key->ptr);
//添加key,val 到全局hash表
int retval = dictAdd(db->dict, copy, val);
// 输出信息
serverAssertWithInfo(NULL,key,retval == DICT_OK);
if (val->type == OBJ_LIST ||
val->type == OBJ_ZSET)
//list和zset添加数据后会触发signalKeyAsReady(这里应该再加个stream,ps:stream已经单独处理了)
signalKeyAsReady(db, key);
if (server.cluster_enabled) slotToKeyAdd(key);
dict.c
/**
* @brief 添加一个key val到对应的hash表
* @param d 目标hash表
* @param key sds字符串 的指针
* @param val robj的指针
* @return int
*/
int dictAdd(dict *d, void *key, void *val)
dictEntry *entry = dictAddRaw(d,key,NULL);
if (!entry) return DICT_ERR;
//将val赋值给entry
dictSetVal(d, entry, val);
return DICT_OK;
object.c中
/**
* @brief 创建embstr字符串
* 好处是空间连续,只需创建一次
* @param ptr 字符串指针
* @param len 实际字符长度 小于44位
* @return robj* 在这里明确创建了一个SDS_TYPE_8类型的embstr
*/
robj *createEmbeddedStringObject(const char *ptr, size_t len)
// 申请一个robj+sdshrd8 的连续空间
//16+(3+1)+len 最大64字节,这里会做内存对齐
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1);
//字符串结构体开始位置,+1是因为o->type+o->encoding=1字节
/**
* 因为o是一个robj类型
* o+1等价于sizeof(o)+1 1表示o结构体的一个单位
* sizeof(o)就是robj类型的结构体大小
* 所以sh的指针就是在申请的内存空间里排除了robj对象的大小
*/
struct sdshdr8 *sh = (void*)(o+1);
o->type = OBJ_STRING;
o->encoding = OBJ_ENCODING_EMBSTR;
/**
* 这块刚开始还有点想不明白,为什么+1?
* 指针是可以在知道结构体类型的情况下,指针是可以自加操作,1个单位表示结构体的大小
* void 指针因为不知道结构体类型,所以无法自加,也可以防止误操作
*/
o->ptr = sh+1;
//占用4字节
o->refcount = 1;
//设置过期策略
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU)
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
else
o->lru = LRU_CLOCK();
//直接已用长度和申请长度打满,后续不让动了
sh->len = len;
sh->alloc = len;
sh->flags = SDS_TYPE_8;
if (ptr == SDS_NOINIT)
sh->buf[len] = '\\0';
else if (ptr)
//将原来的字符串拷贝过去
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\\0';
else
memset(sh->buf,0,len+1);
return o;
 没问题,我计算的没问题。
没问题,我计算的没问题。
既然这样,我看下memory usage是怎么算的?
在object.c中
void memoryCommand(client *c)
if (!strcasecmp(c->argv[1]->ptr,"usage") && c->argc >= 3)
dictEntry *de;
long long samples = OBJ_COMPUTE_SIZE_DEF_SAMPLES;
for (int j = 3; j < c->argc; j++)
if (!strcasecmp(c->argv[j]->ptr,"samples") &&
j+1 < c->argc)
if (getLongLongFromObjectOrReply(c,c->argv[j+1],&samples,NULL)
== C_ERR) return;
if (samples < 0)
addReply(c,shared.syntaxerr);
return;
if (samples == 0) samples = LLONG_MAX;;
j++; /* skip option argument. */
else
addReply(c,shared.syntaxerr);
return;
if ((de = dictFind(c->db->dict,c->argv[2]->ptr)) == NULL)
addReply(c, shared.nullbulk);
return;
//计算value的长度
size_t usage = objectComputeSize(dictGetVal(de),samples);
serverLog(LL_WARNING, "memoryCommand usage dictGetVal size:%d",usage);
//计算key的长度
usage += sdsAllocSize(dictGetKey(de));
serverLog(LL_WARNING, "memoryCommand usage dictGetVal+dictGetKey size:%d",usage);
//计算dictEntry的长度
usage += sizeof(dictEntry);
serverLog(LL_WARNING, "memoryCommand usage dictGetVal+dictGetKey+dictEntry size:%d",usage);
addReplyLongLong(c,usage);
/**
* @brief 计算robj的大小
*
* @param o
* @param sample_size
* @return size_t
*/
size_t objectComputeSize(robj *o, size_t sample_size)
sds ele, ele2;
dict *d;
dictIterator *di;
struct dictEntry *de;
size_t asize = 0, elesize = 0, samples = 0;
if (o->type == OBJ_STRING)
if(o->encoding == OBJ_ENCODING_INT)
//int类型,直接
asize = sizeof(*o);
else if(o->encoding == OBJ_ENCODING_RAW)
//raw编码申请空间的长度+结构体的长度
asize = sdsAllocSize(o->ptr)+sizeof(*o);
else if(o->encoding == OBJ_ENCODING_EMBSTR)
//embstr实际字符串的使用长度+2+16,这块有点想不明白了
asize = sdslen(o->ptr)+2+sizeof(*o);
else
serverPanic("Unknown string encoding");
加日志,编译启动
10284:M 08 Jan 2022 15:26:31.985 # memoryCommand usage dictGetVal size:24
10284:M 08 Jan 2022 15:26:31.985 # memoryCommand usage dictGetVal+dictGetKey size:32
10284:M 08 Jan 2022 15:26:31.985 # memoryCommand usage dictGetVal+dictGetKey+dictEntry size:56
从日志上看:
val : 计算出来的是24 从代码算出来是26
dictGetKey : 计算出来的是8 出代码算出来是10
dictEntry: 计算出来的是24 这个没问题
key和val 各差了两字节;
在计算embstr类型val的长度时计算公式为:sdslen(o->ptr)+2+sizeof(*o),计算key占用的空间时用的 sdsHdrSize(s[-1])+alloc+1。
val计算的逻辑有点不理解,但是key计算的逻辑没问题,怎么就少了2字节?
断点了下,有如下发现:
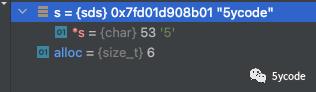
从内存中看key的前一位是0,也就是类型是sdshdr5

val 我就看不明白了
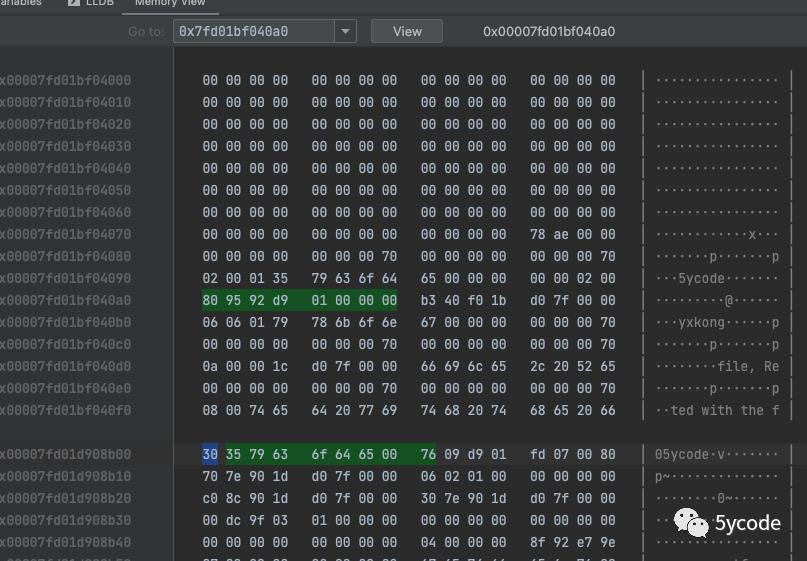
从上图可以看出key的结构体是一个sdshdr5的结构体。
然后我又撸了一遍代码
-
在接收的时候:createStringObject 通过createEmbeddedStringObject创建了sdshdr8类型的ebmstr字符串;
-
在setCommand 中通过tryObjectEncoding进行尝试压缩优化,但是val本身就是embstr类型了,这里什么都没做,日志输出也证明了;
-
在setGenericCommand中setKey->dbAdd 方法里sdsdup->sdsnewlen 在这里将key变成了sdshdr5
具体代码如下
/**
* @brief 初始化sds字符串
* 返回的是一个sds指针,这个指针是在对应的结构体开始指针+结构体大小
* @param init 初始化字符串
* @param initlen 初始化字符串的长度
* @return sds
*/
sds sdsnewlen(const void *init, size_t initlen)
void *sh;
sds s;
//获取结构体的类型,在这里根据长度将key转成了sdshdr5
char type = sdsReqType(initlen);
/* Empty strings are usually created in order to append. Use type 8
* since type 5 is not good at this. */
// SDS_TYPE_5并且字符串长度为0的情况下修复为SDS_TYPE_8
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
//计算对应sds类型结构体的size
int hdrlen = sdsHdrSize(type);
unsigned char *fp; /* flags pointer. */
assert(hdrlen+initlen+1 > initlen); /* Catch size_t overflow */
// 申请空间(结构体类型长度+字符串长度+1)
sh = s_malloc(hdrlen+initlen+1);
// printf("key: %s initlen:%d type:%d hdrlen:%d size %d \\n",init,initlen,type,hdrlen,(hdrlen+initlen+1));
if (init==SDS_NOINIT)
init = NULL;
else if (!init)
memset(sh, 0, hdrlen+initlen+1);
if (sh == NULL) return NULL;
//s是在申请的sh指针的地址上,加上了结构体大小
s = (char*)sh+hdrlen;
fp = ((unsigned char*)s)-1;
switch(type)
case SDS_TYPE_5:
*fp = type | (initlen << SDS_TYPE_BITS);
break;
if (initlen && init)
memcpy(s, init, initlen);
s[initlen] = '\\0';
return s;
顺带梳理了下set命令tryObjectEncoding的逻辑
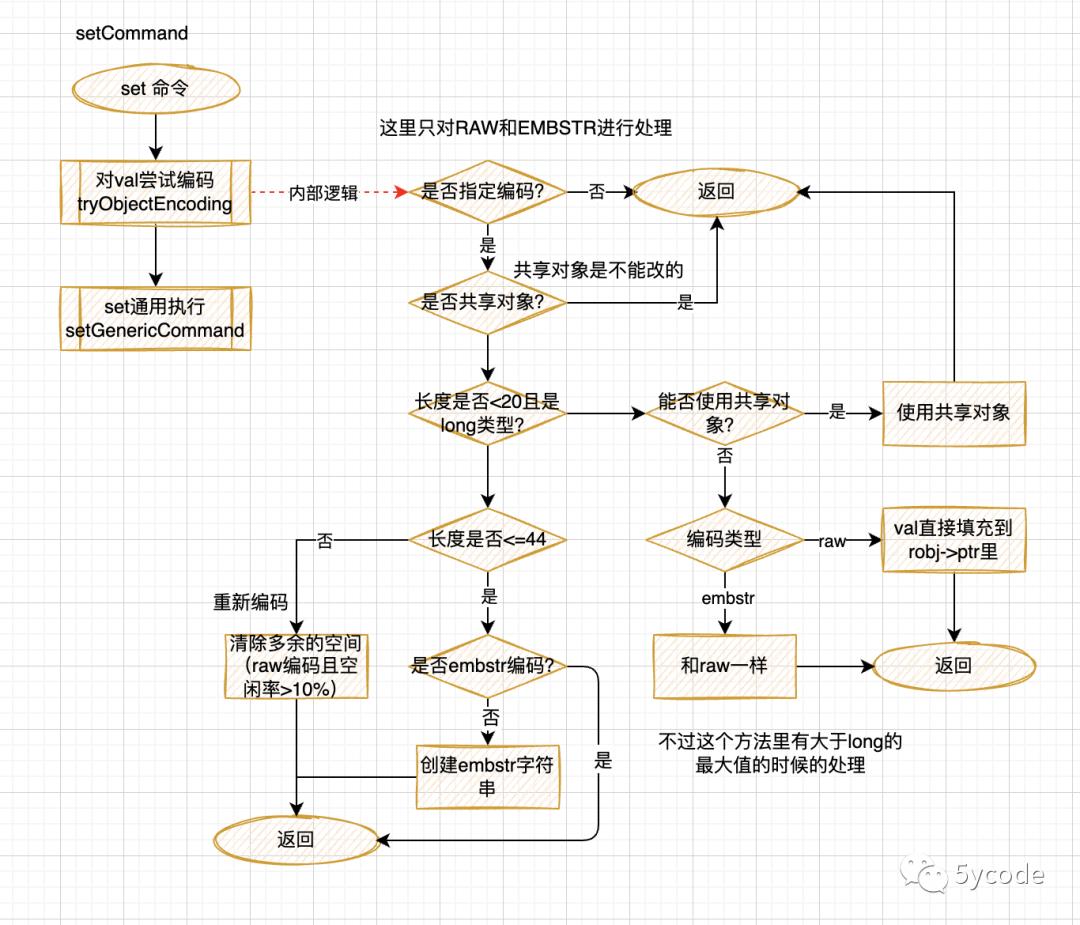
key的计算没问题了,就剩val了
然后我添加各种日志,从接收参数到执行命令对应的sds类型一直是1.
15299:M 08 Jan 2022 21:07:58.742 # processMultibulkBuffer param:set type:1
15299:M 08 Jan 2022 21:07:58.742 # processMultibulkBuffer param:5ycode type:1
15299:M 08 Jan 2022 21:07:58.742 # processMultibulkBuffer param:yxkong type:1
15299:M 08 Jan 2022 21:07:58.742 # processCommand call before param:yxkong type:1
15299:M 08 Jan 2022 21:07:58.742 # call before param:yxkong type:1
15299:M 08 Jan 2022 21:07:58.742 # setCommand tryObjectEncoding before param:yxkong type:1
15299:M 08 Jan 2022 21:07:58.742 # setCommand tryObjectEncoding after param:yxkong type:1
15299:M 08 Jan 2022 21:07:58.742 # setCommand setGenericCommand after param:yxkong type:1
想不明白,然后去github上查。
https://github.com/redis/redis/issues/6263
https://github.com/redis/redis/pull/6198
大意是在申请内存的时候,使用了内存对齐,然后将对齐内存后的大小,增加到了used_memory上(在zmalloc.c中),用于标记申请的总内存,这些对齐的内存叫内存碎片。这和jemalloc有关。
在objectComputeSize上,注释也说返回的结果是一个近似值,特别是在集合类型下,那我想string类型应该是准确的吧,单对embstr的结果计算是不准确的。
redis的作者基于什么样的考量这么设计?后续有空了再跟进下。
最后更新下从代码层面梳理的数据结构图 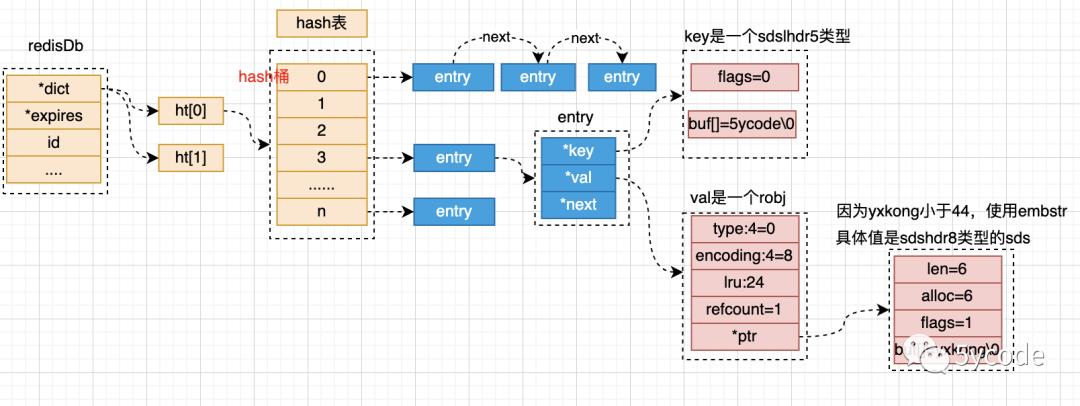
redis系列文章
redis源码阅读四-我把redis6里的io多线程执行流程梳理明白了
redis源码阅读五-为什么大量过期key会阻塞redis?
本文是Redis源码剖析系列博文,有想深入学习Redis的同学,欢迎star和关注;
Redis中文注解版:https://github.com/yxkong/redis/tree/5.0
如果觉得本文对你有用,欢迎一键三连;
同时可以关注微信公众号5ycode获取第一时间的更新哦;
以上是关于redis源码阅读-终于把内存占用算清楚了的主要内容,如果未能解决你的问题,请参考以下文章