动静分离的数据并发加载策略
Posted SegmentFault
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了动静分离的数据并发加载策略相关的知识,希望对你有一定的参考价值。
前言
当今许多大型网页应用尤其是SPA均采用了动静分离的策略。关于动静分离的描述,这里推荐一篇不错的博文 。
本人是做前端的,之前有幸与一位对性能追求极致的后端同学一起开发这种动静分离的web项目,以下将从传统顺序模式、单路数据并发模式(以下简称单并发模式)、多路数据并发模式(以下简称多路并发模式)来谈谈自己对这类应用关于前端加载方面的心得。本文中的例子均来自该项目中。
1. 传统顺序模式
一般情况下,浏览器首先会接收到一张静态的页面,这张页面会包含样式文件和脚本文件引用的标签(图片什么的不在这里讨论)。至于数据哪里来,下面介绍两种方式:
脚本请求获取
通常,在脚本加载完毕后,脚本会执行一段向服务端发送请求数据的代码,然后通过回调函数取出数据并做初始化工作。这一个过程为:请求页面=>渲染页面=>加载脚本=>请求数据=>数据与脚本一起初始化=>初始化完毕,也就是从加载应用到启动应用是以顺序任务的形式执行。直接填充于隐藏标签中
服务端也可以直接将数据填充到网页中的一个隐藏标签中再传回给客户端,也就是上面顺序中把获取数据放在页面请求之前。之后在脚本中直接去获取相应的DOM中的内容也就是数据,来进行初始化工作。
这两种方法各有优劣,因为不是本文重点,在此就直接带过。不过笔者更倾向于前者。
1.1 工作流图
如果用工作流的思想去理解,大概可以为下图(第一种方式):
1.2 结果分析
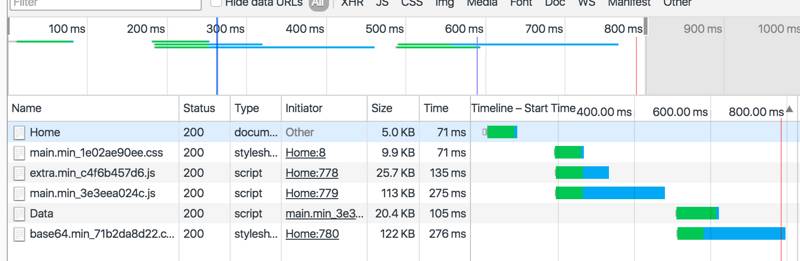
在这里我们只研究数据以及main.js的加载情况。
base64.css是用来存储一些小图片的base64字符串并且是允许延后加载,可以将其归为图片资源一类。
总体情况还是可以接受的,毕竟后端同学对缓存这一块下了很大的功夫,用户会在500ms左右看到页面的内容,到了600ms之后程序就可以正式启动。
这种模式的优点是显而易见的,这种顺序加载启动模式易用性、可维护性都比较好,也能很好地发挥动静分离的特长。
然而,我们认为,如果将上图中数据的请求放在前面和脚本一起并发请求,也许会减少整个页面的加载和启动所需时间,而且后端同学还觉得这样的加载效果会更加直观、整齐……
于是便有了下面的研究。
2. 单并发模式
要实现数据与脚本并发加载,最核心的就是要让数据不依赖于脚本进行加载,笔者所能想到的有两种:
在头部添加一个
script,插入一段发送ajax请求的代码,向服务端发送数据请求。同样是添加一个
script,将其src设为数据请求的url来引用外部数据资源。
单从执行效率来说,1比2还多了一步,故本文中选择2进行讨论。
2.1难点与解决方案
如何保证script标签进行外部下载时不阻塞其他资源的下载?
把script在head标签内。在下载script引入的外部脚本时,浏览器处于阻塞状态,网络不好或者script文件过大时,页面处于空白停顿状态,这样的体验是很不好的。
我们一般会将脚本文件放在页面底部来降低脚本下载与运行所带来的阻塞影响,而且这样可以保证脚本中所引用的页面元素已经渲染完毕。
而数据请求是与页面元素无关,在这里我们希望它能放在头部确保可以尽早地开始加载来达到与其它资源一起请求,但又不阻塞其他资源的下载。
浏览器对标记有async属性的scripts会立即加载并解析,该script相对于页面的其余部分异步地执行(当页面继续进行解析时,脚本将被执行)。
这里的解决办法则是采用html5的async属性,将其应用于数据请求相关的script上,就可以达到脚本与数据并发加载的效果。如下代码:
script(src="/Table/Data" type="text/javascript" async="async")在数据与脚本加载的顺序未知的情况下,如何保证正确的页面启动?
javascript是一门解析性语言,当它加载完毕之后就会执行。
此时的数据请求变成了一个script标签,也就是说,它可以变成一段与赋值相关的javascript代码,直接把得到的结果放在公共环境中。如果不把它变成赋值代码,基于上面的引言,可能得到的数据就会变成环境中的一个匿名对象而在之后无法再次被访问。这样一来,在脚本记载完毕就可以直接去引用这个结果进行启动页面。那么问题来了……
基于上面
async中阐述的方案,在实际中更多时候我们可能无法100%保证数据与脚本加载的先后顺序。资源大小的确一定程度决定了加载时间,但是网络传输也有着许多不稳定的因素。我们也不可能直接在任何一个
script中直接引用对方的资源(如果未加载完毕,会返回undefined的错误)。不到万不得已,不应该使用轮询检查的方法去解决并发问题,这样的应用性能太低,和我们的初衷相违背。
既然它们是相互依赖的关系,而且我们只需要其中一方引用另一方的资源即可完成我们所需要的启动。在这里,我们只需要让先加载完成前的把资源暴露到公共环境window中,让后加载的那一方察觉到之后直接引用进行启动即可。
对于数据与脚本,我们把它们的资源分别定为:
| 名称 | 资源 | 描述 |
|---|---|---|
| 数据 | allData(Object) | 存储所有的动态数据 |
| 脚本 | mainInitByData(Function) | 主引导函数 |
在数据请求里,代码为:
var allData = window.allData = '{"name":"data"}';
//检查脚本的资源是否存在
if (typeof window.mainInitByData !== 'undefined') {
mainInitByData(JSON.parse(allData));
};脚本里相关的片段则为:
var mainInitByData = window.mainInitByData = function(data) {
//TODO...
}
if (typeof window.allData !== 'undefined') {
mainInitByData(JSON.parse(allData));
}2.2 工作流图

2.3 结果分析
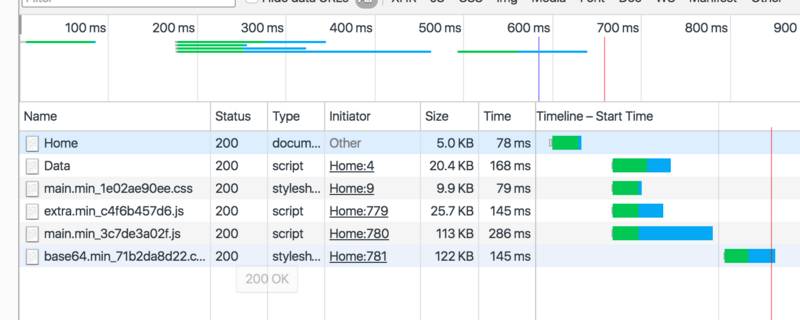
不难发现,经过并行化处理之后,加载页面的效率相比于之前的顺序模式大大增加了。且页面程序也能顺利启动(这里大家可以自行尝试)。
不料后端同学在一两个月后,又提出了希望作多路数据并发请求,因为动态数据中也有部分数据相对一段时间内为静态的,这部分数据可以用缓存处理,其他数据则直接从其它服务器中获取,可以进一步提高并发效率。事情变得越来越有趣,也有了下面的研究。
3. 多路并发模式
3.1 “继承”单并发
此时,假设我们所需请求的数据共有三条A、B、C,其中A为相对静态数据,可以做出以下定义:
| 名称 | 资源 | 描述 |
|---|---|---|
| 子数据A | AData(Object) | 存储A的相对静态数据 |
| 子数据B | BData(Object) | 存储B的动态数据 |
| 子数据C | CData(Object) | 存储C的动态数据 |
| 脚本 | mainInitByData(Function) | 主引导函数 |
如果继续沿用单并发中的策略,脚本的相关片段代码则为:
var mainInitByData = window.mainInitByData = function(dataA, dataB, dataC) {
//TODO...
}
if (typeof window.dataA !== 'undefined' && window.dataB !== 'undefined' && window.dataC !== 'undefined') {
var dataA = JSON.parse(dataA),
dataB = JSON.parse(dataB),
dataC = JSON.parse(dataC);
mainInitByData(dataA, dataB, dataC);
}以上数据只是一个例子,并不代表这样就可以解决这类的问题。假如有一天后端突然要求一次并发加载10条数据,代码就会变得十分冗余。
既然要处理并发,那么单并发的思想是可以沿用的,只是这里的方向不对。
不妨我们换个角度思考,脚本仍然和数据进行互相检查,但是这个数据包含了所有子数据,在这里我直接将其称为父数据。那子数据之间怎么办?
3.2 以信号量的思想处理数据整合
之所以说是信号量的思想而不是信号量,因为信号量本身是多线程多任务同步,而对于带有async标签里的javascript是单线程异步,但不代表javascript不能利用信号量的思想,信号量的思想就是在解决处理并发问题。具体的信号量定义,请读者自行查阅。
为了更好的描述这个借用思想的过程,先做以下定义:
父数据与子数据之间共用一种信号量,子数据运用这种信号量进行数据的整合,而父数据应用这种信号量进行与脚本初始化启动。
每次子数据加载完毕后,释放信号量,并把自己的数据整合到父数据中。
假设子数据之间申请信号量的顺序未知,但必定在父数据之前。
整合的数据以及信号量都放在一个js对象
integrateData中,分别命名为data、sem(其值为1-子数据数量),即integrateData = {data: {}, sem: -2}
这里可能需要对子数据的格式做一定的调整。变成以下类型,方便做整合
{"message":"success", "data": {....}}那么对于所有子数据的处理代码为:
var result = 'JSON';
var integrateData = window.integrateData || (window.integrateData = { data: {}, sem: 1 - 3 });
var onDataCallback = window.onDataCallback || (window.onDataCallback = function(result_, integrateData) {
function dataIsReady(integrateData) {
return integrateData.sem > 0;
}
function dataReadyCallback(integrateData) {
integrateData.sem--;
//父数据与脚本启动
var mainInitBydata = window.mainInitBydata;
if (typeof mainInitBydata === "function") {
mainInitBydata(integrateData);
}
integrateData.sem++;
}
if (dataIsReady(integrateData)) {
alert("非法请求");
return;
}
var result = result_;
if (typeof result_ === "string") {
result = JSON.parse(result_);
}
//数据整合
if (result.message === "success") {
var data = result.data;
for (var key in data) {
integrateData.data[key] = data[key];
}
}
//释放信号量
integrateData.sem++;
//检查信号量
if (dataIsReady(integrateData)) {
dataReadyCallback(integrateData);
}
});
onDataCallback(result, integrateData);此时,脚本里的相关代码则为:
var mainInitByData = window.mainInitByData = function(integrateData) {
//TODO...
}
var integrateData = window.integrateData;
//这里无需担心冲突问题,因为js是单线程执行,子数据整合完毕后会直接执行父数据检查脚本资源的行为,所以sem>0时,父数据处于就绪状态。
if (integrateData && integrateData.sem > 0) {
mainInitBydata(integrateData)
}3.3 工作流图
3.4 结果分析
其实效率相比单并发提高不多,主要是涉及的动态数据规模不大,而且每次发送的请求报文和响应报文都会有一定大小的报头,造成不必要的开销。但假如动态数据足够大的话,这种策略是可以起到很大的作用。同时,单并发模式中的双向检查也可以用信号量的思想实现。
总结
总结以上的模式,我们可以得出以下的结论:
| 模式 | 效率 | 易用性 | 性能主要影响因素 | 适用场景 |
|---|---|---|---|---|
| 顺序 | 普通 | 容易 | 数据与程序的大小总和 | 一般的小项目 |
| 单并发 | 比顺序模式高 | 普通 | 数据与程序大小比例 | 大多数动静分离的网站应用 |
| 多路并发 | 一般比单并发高,当数据太小时效率会比单并发低 | 复杂 | 划分数据的比例 | 数据比较庞大的网站应用,尤其是数据之间按相对均匀的比例归类 |
除此以外,上述中,单并发与多路并发的一大缺陷就是代码的耦合性会相对地提高,对于多路并发而言,如果子数据请求之间有依赖关系,可能还要定义多种不同的信号量,不利于管理。
利用现有的工具比如EventProxy,可以很好管理这些并发请求,包括任务之间的依赖关系。通过事件订阅与触发的形式可以让程序更好地知道当前所完成的任务以触发相应的回调函数进行处理。
希望本文可以给读者带来一定的帮助。
欢迎关注作者, follow 其 github :
以上是关于动静分离的数据并发加载策略的主要内容,如果未能解决你的问题,请参考以下文章
网站优化:缓存策略优化(CDN/动静分离/Cache-control)