图文并茂解释内存池原理
Posted 昱唯网络
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图文并茂解释内存池原理相关的知识,希望对你有一定的参考价值。
在 C 语言的动态申请内存技术中,相比起 alloc/free 系统调用,内存池(memory pool)是与现在系统中请求一大片连续的内存空间,然后在运行时根据实际需要分配出去的技术。使用内存池的优点有:
速度远比
malloc/free快,因为减少了系统调用的次数,特别是频繁申请/释放内存块的情况避免了频繁申请/释放内存之后,系统的大量内存碎片
节省空间
分类
根据分配出去的内存大小,内存池可以分为两类:
Fixed-size Allocation
每次分配出去的内存单元(称为 unit 或者 cell)的大小为程序预先定义的值。释放内存块时,则只需要简单地挂回内存池链表中即可。又称为 “固定尺寸缓冲池”。
常规的做法是:将不同 unit size 的内存池整合在一起,以满足不同内存块大小的使用需求
Variable-size allocation
不分配固定长度,内存的分配只是在一大块空闲的内存上滑动。优点是分配效率很高,缺点是成批地回收内存,因为释放的内存无法直接重复利用。
使用这种需要合理规划每块内存的管理区域,所以又叫做 “基于区域的” 内存管理。使用这种做法的分配器,举例有 Apache Portable Runtime 中的 apr_pool 工具。本文不讨论这种内存池。
原理和结构
概念和数据结构
定长内存池有一些基本和必要的概念,需要定义在内存池的结构数据中。以下命名方式使用变体的匈牙利命名法,比如 nNext,n表示变量类型为整形。类似地,p表示指针。
Memory Unit
每次程序调用 MemPool_Alloc 获取一个内存区域后,会获得一块连续的内存区域。管理一个这样的内存区域的单元就成为内存单元 unit,有时也称作 chunk。每个 unit 需要包含以下数据:
nNext:整型数据,表示下一个可供分配的 unit 的标识号。功能请参见后问pData[]:实际的内存区域,其大小在创建时由调用方指定
Memory Block
一个内存块,内存块中保存着一系列的内存单元。
这个数据结构需要包含以下基本信息:
nSize:整型数据,表示该 block 在内存中的大小nFree:整型,表示剩下有几个 unit 未被分配nFirst:整型,表示下一个可供分配的 unit 的标识号pNext:指针,指向下一个 memory block
Memory Pool
一个内存池总的管理数据结构,换句话说,是一个内存池对象。
pBlock:指针,指向第一个 memory blocknUnitSize:整型,表示每个 unit 的尺寸nInitSize:整型,表示第一个 block 的 unit 个数nGrowSize:整型,表示在第一个 block 之外再继续增加的每个 block 的 unit 个数
函数接口
作为一个内存池,需要实现以下一些基本的函数接口,或者说可以是对象方法:
memPoolCreate()
创建一个 memory pool,必须的参数为 unit size,可选参数为上文 memory pool 的 nInitSize 和 nGrowSize。
memPoolDestroy()
销毁整个 memory pool 并交还给操作系统。
memPoolAlloc()
从 memory pool 中分配一个 unit,其尺寸是预先定义的 unit size。
memPoolFree()
释放一个指定的 unit。
工作过程
现在我们用一个 unit size 为 1024、init size 为 4(每一个 block 有 4 个 units)的 memory pool 为例,解释一下内存池的工作原理。下文假设整型的宽度为 4 个字节。
创建 memory pool
程序开始,调用并创建一个 memory pool。此时调用的函数为 memPoolCreate(),程序会创建一个数据结构,相应的结构体成员及其取值如下:
memory pool alloc
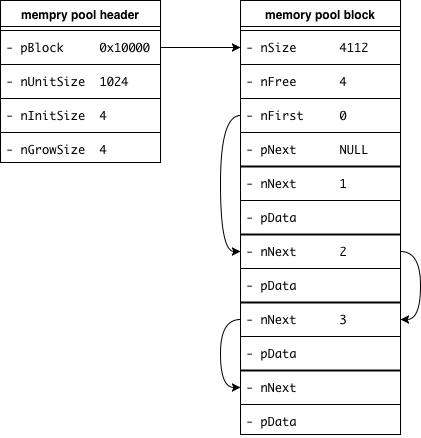
其中 nSize = 4112 = sizeof(memPool) + nInitSize * sizeof(memUnit)。每一个 nNext 依次加一,各指代着跟着自己的下一个 unit。最后一个 unit 的 nNext 值无意义,因此不说明其取值。
然后返回需要的 unit 中的内存。返回内存的逻辑如下:
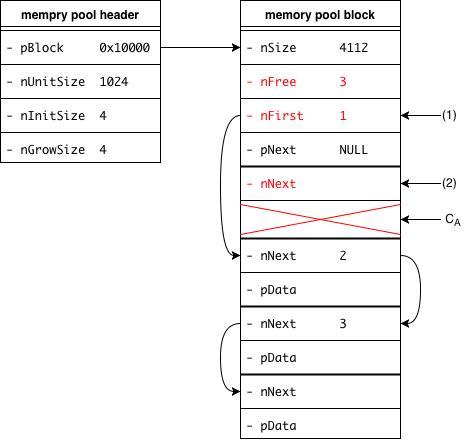
内存池在 block 中查询
nFree成员由于
nFree > 0,表示有未分配的 unit,因此继续在该 block 中查看nFirst成员nFree减一修改
nFirst的值,标记下一个可用的 unit。注意这里的nFirst切切不能简单地加一,而是取返回给调用方的 unit 所对应的nNext的值,也就是下图(2)处原来的值1
操作后各数据结构的状态如下:
第二次调用 alloc 的情况类似。调用后各数据结构的状态如下:
memory pool free
我们先看看结果:
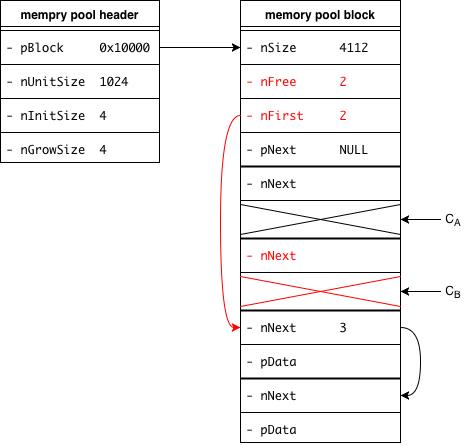
回收 unit,此时需要标记相应的成员值以标示 unit 的回收状态。首先查看
nFirst的值,参见上前幅图,nFirst的值为 3,表示位置(3)处的 unit 是可用的。因此我们首先把(2)处的nNext值设置为 3,将其加回到可用 unit 的链表中将
nFirst的值修改为0,也就是代表刚刚回收回来的 unit 的标号,而(2)处的值赋值为 2,表示b(3)的 unit
其实可以看到,上面就是一个简单的链表操作。根据上面的过程,如果 CB 也释放了的话,那么 memory pool 的状态则会变成这样:
到这个时候,由于整个 block 已经完全回收了(nFree == nInitSize),那么根据不同的策略,可以考虑将整个 block 从内存中释放掉。
block 满
我们回到 alloc 的逻辑中,可以看到内存池最开始会检查 block 的 nFree 成员。如果 nFree == 0 的时候,那么就会在该 block 的 pNext 中去找到下一个 block,再去检查 nFree。如果发现 block 链表已经结束了,那就意味着当前所有的 block 已满,必须创建新的 block。
在实际设计中,我们需要考虑选取合适的 init size 和 grow size 值。从上面的算法中可以看到,如果 alloc/free 调用非常频繁时,第一个 block 的使用效率是非常高的。
变体或改进
有些简化的版本中,可以不使用
pNext来维护链表,也就是只有一个 block,并且内存的使用有一个明确且受控的上限值。这经常用在没有malloc系统调用的 RTOS 或者是一些对内存非常敏感的嵌入式系统中。如果要用于多线程环境中,那么 memory pool 结构体需要加上锁
以上是关于图文并茂解释内存池原理的主要内容,如果未能解决你的问题,请参考以下文章
大数据技术Hadoop+SparkSpark架构原理优势生态系统等讲解(图文解释)
14.VisualVM使用详解15.VisualVM堆查看器使用的内存不足19.class文件--文件结构--魔数20.文件结构--常量池21.文件结构访问标志(2个字节)22.类加载机制概(代码片段