Netty广播场景压测内存泄漏破案全流程
Posted 掌门技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Netty广播场景压测内存泄漏破案全流程相关的知识,希望对你有一定的参考价值。
全文约8000字,预计阅读时间40分钟。
编者话:本次压测是场景压测中比较重要的环节,除此之外还有并发会话压测(同时在线人数),并发多组压测(同时在线群组数),推送点对点、群组发送、广播发送等场景,同时针对限流、发包大小限制、熔断标记等环节都有涉及,非常感谢@梁兵玉(大佬的原话:压测一时爽,一直压测一直爽)同学在压测环节提供的各种压测流程编排和数据提供,后续会陆续讲述这其中的精彩故事。
(一)背景
(二)分析
JVM破案
源码梳理
重现现场
现场分析
(三)定位
审问
指认现场
(四)整改
Buffer设置
水位设置
参数验证
(五)复盘
基础设定
水位设定重要性
Netty其他优化
举一反三
类似案情
其他
(六)反思
开源敬畏和怀疑之道
(一)背景
针对第一篇关于Socket长连接场景高性能事件驱动探索中,我们进行了部分核心场景的性能压测,高性能驱动凝聚了中台Socket团队很多生产经验的积累,我们希望通过一些场景压测来验证和发现那些已知和未知的问题,这次我们选择了广播场景,广播消息是Socket长连接业务常用的一种技术手段,推送系统的广播,IM系统的群聊都是针对一类特定人群的消息派发,在业务上的实现通过有状态的会话进行循环点对点式的主动消息上传。
压测1800人大群以10秒每人次的速度进行广播聊天消息,在压测大概10分钟左右,服务器流量会突然下降,并且内存耗尽,而10分钟的过程则显得非常平淡,内存正常,CPU正常,网络几乎无波动,没有异常日志,没有生成dump文件,压测机器流量正常,笔者怀疑每个人是不是都在正常开车,但是却没有证据。
硬件环境:4C8G
系统环境:
1CentOS Linux release 7.6.1810 (Core)
2uname:Linux 3.10.0-957.5.1.el7.x86_64 #1 SMP Fri Feb 1 14:54:57 UTC 2019 x86_64
3libc:glibc 2.17 NPTL 2.17
网络环境:模拟公网带宽100Mbps
压测数据:
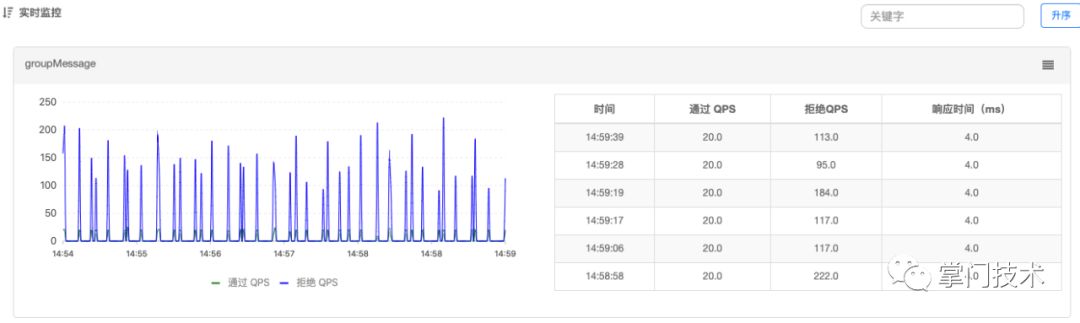
群人数:1800
QPS:20
上行QPS=20*1800=36,000/s
消息大小:78Byte
协议头大小:22Byte(粗估)+socketio二进制头40Byte
每秒包大小:36,000*(78+22+40) = 3,600,000Byte=4.8MB
窗口大小和吞吐量:按照RTT0.1s计算,1个连接的最大吞吐量为5.2Mbps,在一般网络压测中,使用多个TCP连接提高网络吞吐量,web浏览器中通常使用4个TCP连接。
(二)分析
对于服务器性能迷之自信的我肯定是无法接受这种没有证据的开车一说,临近下班,没有太清晰的思路去偌大车祸现场研究细节,于是对广播消息进行限流,数据对比如下:
| 序号 | 人数 | 限流次数 | 广播次数 | 上行网络带宽 | 持续时间 | GC |
|---|---|---|---|---|---|---|
| 1 | 1800 | 30 | 54,000 | ~80Mbps | 20m | G1 |
| 2 | 1800 | 20 | 36,000 | ~65Mbps | 30m | G1 |
| 3 | 1800 | 30 | 54,000 | ~80Mbps | 23m | G1 |
通过前2次分析和GC的内存走势上面分析,老年代突然加大,必定是内存中的QPS达到峰值无法销毁导致年轻代来不及回收,本该需要回收的对象,在CPU允许的情况下并没有GC掉,第三次试图通过G1的垃圾回收参数通过CPU换取QPS效率。
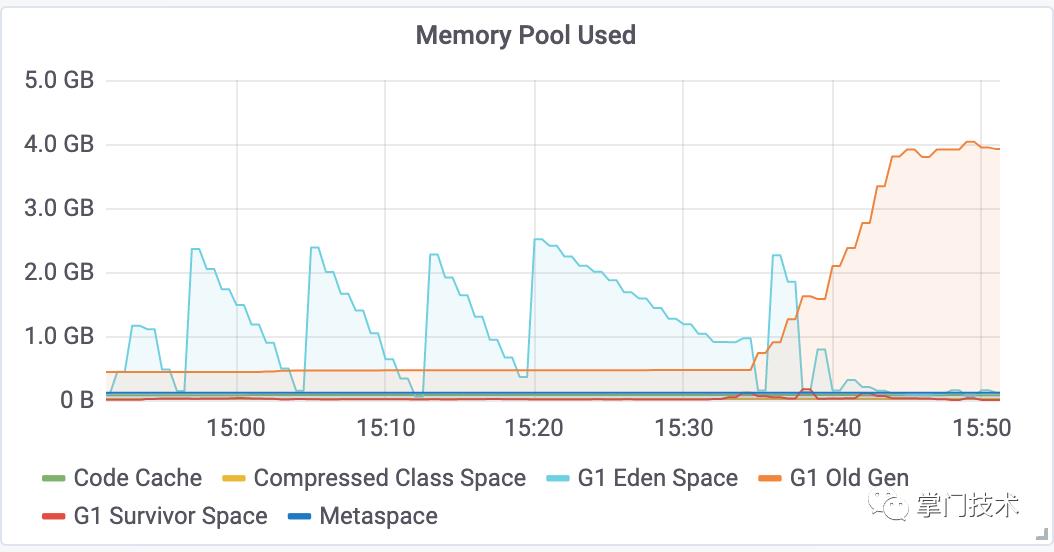
JVM破案
使用G1垃圾收集器时,该标志有一个默认值:200毫秒(这一点跟Throughput收集器有所不同)。如果G1收集器发生时空停顿(stoptheworld)的时长超过该值,G1收集器就会尝试各种方式进行弥补——譬如调整新生代与老年代的比例,调整堆的大小,更早地启动后台处理,改变晋升阈值,或者是在混合式垃圾收集周期中处理更多或更少的老年代分区(这是最重要的方式)。
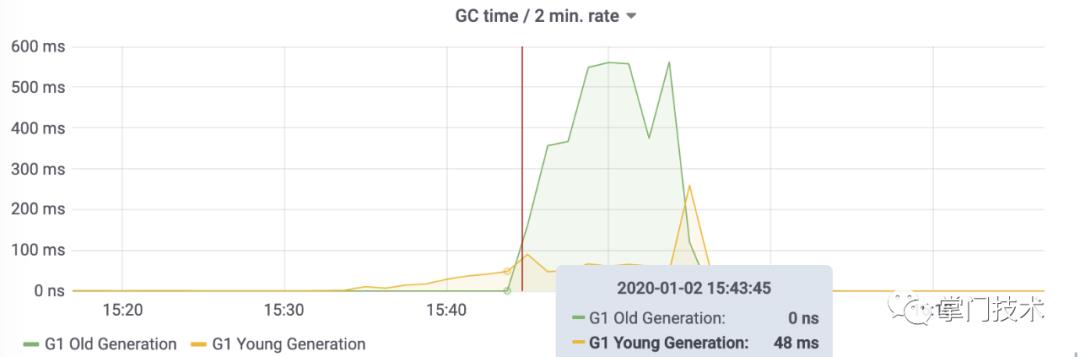
从整个前期gc过程看,整个YGC的效率都在处于低位,CPU同样处于低位,于是根据线上的G1参数,试图查看了一下线上的GC配置具体情况,再来定夺剩下的调整,参数调优道艰且阻。
理论:JVM在G1出现FGC的可能情况
1.并发收集有余,应用程序和GC线程交替工作,不能完全避免繁忙的场合会出现回收过程中出现内存不足的情况,这时G1会转入一个FullGC进行回收。
2.如果混合GC出现空间不足,或者新生代GC时,survivor区和老年代无法容纳幸存对象,会进行一次FullGC
1[admin@FAT-HZ-11123-2:~]16:55:57$ java -XX:+PrintFlagsFinal -version
2[Global flags]
3 uintx AdaptiveSizeDecrementScaleFactor = 4 {product}
4 ...省略
通过增加QPS思路且降低老年代消耗,简单调整了2个参数,并查看Native内存情况
1-XX:InitiatingHeapOccupancyPercent=45 改成40
2-XX:InitialTenuringThreshold=10 默认7 Max是15
3#为了帮助G1赢得这场垃圾收集的比赛,可以尝试增加后台标记线程的数目(假设机器有足够的空闲CPU可以支撑这些线程的运行)。
4-XX:ConcGCThreads=2
5-XX:NativeMemoryTracking=summary
GC日志:
12020-01-02T17:32:13.794+0800: 1229.446: [GC pause (G1 Evacuation Pause) (young), 0.0138628 secs]
2 [Parallel Time: 11.1 ms, GC Workers: 4]
3 [GC Worker Start (ms): Min: 1229446.6, Avg: 1229446.6, Max: 1229446.6, Diff: 0.1]
4 [Ext Root Scanning (ms): Min: 1.5, Avg: 1.8, Max: 2.4, Diff: 0.9, Sum: 7.3]
5 [Update RS (ms): Min: 4.7, Avg: 5.0, Max: 5.2, Diff: 0.5, Sum: 20.1]
6 [Processed Buffers: Min: 19, Avg: 29.0, Max: 43, Diff: 24, Sum: 116]
7 [Scan RS (ms): Min: 0.4, Avg: 0.4, Max: 0.4, Diff: 0.0, Sum: 1.6]
8 [Code Root Scanning (ms): Min: 0.0, Avg: 0.1, Max: 0.4, Diff: 0.3, Sum: 0.6]
9 [Object Copy (ms): Min: 3.1, Avg: 3.4, Max: 3.7, Diff: 0.6, Sum: 13.7]
10 [Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
11 [Termination Attempts: Min: 1, Avg: 1.2, Max: 2, Diff: 1, Sum: 5]
12 [GC Worker Other (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.1, Sum: 0.5]
13 [GC Worker Total (ms): Min: 10.8, Avg: 11.0, Max: 11.1, Diff: 0.2, Sum: 43.9]
14 [GC Worker End (ms): Min: 1229457.5, Avg: 1229457.6, Max: 1229457.6, Diff: 0.1]
15 [Code Root Fixup: 0.1 ms]
16 [Code Root Purge: 0.0 ms]
17 [Clear CT: 0.5 ms]
18 [Other: 2.1 ms]
19 [Choose CSet: 0.0 ms]
20 [Ref Proc: 0.2 ms]
21 [Ref Enq: 0.0 ms]
22 [Redirty Cards: 0.1 ms]
23 [Humongous Register: 0.1 ms]
24 [Humongous Reclaim: 0.0 ms]
25 [Free CSet: 1.3 ms]
26 [Eden: 2450.0M(2450.0M)->0.0B(2450.0M) Survivors: 6144.0K->6144.0K Heap: 2781.6M(4096.0M)->333.0M(4096.0M)]
27 [Times: user=0.04 sys=0.00, real=0.01 secs]
设置了-XX:ErrorFile=/var/log/hs_err_pid
1Heap:
2 garbage-first heap total 4194304K, used 4174480K [0x00000006c0000000, 0x00000006c0204000, 0x00000007c0000000)
3 region size 2048K, 0 young (0K), 0 survivors (0K)
4 Metaspace used 95930K, capacity 98918K, committed 101888K, reserved 1138688K
5 class space used 11721K, capacity 12272K, committed 12800K, reserved 1048576K
6
7Heap Regions: (Y=young(eden), SU=young(survivor), HS=humongous(starts), HC=humongous(continues), CS=collection set, F=free, TS=gc time stamp, PTAMS=previous top-at-mark-start, NTAMS=next top-at-mark-start)
8AC 0 HS TS 0 PTAMS 0x00000006c0000000 NTAMS 0x00000006c0000000 space 2048K, 50% used [0x00000006c0000000, 0x00000006c0200000)
9AC 0 HS TS 0 PTAMS 0x00000006c0200000 NTAMS 0x00000006c0200000 space 2048K, 50% used [0x00000006c0200000, 0x00000006c0400000)
10AC 0 HS TS 0 PTAMS 0x00000006c0400000 NTAMS 0x00000006c0400000 space 2048K, 50% used [0x00000006c0400000, 0x00000006c0600000)
11AC 0 O TS 0 PTAMS 0x00000006c0600000 NTAMS 0x00000006c0600000 space 2048K, 99% used [0x00000006c0600000, 0x00000006c0800000)
12AC 0 O TS 0 PTAMS 0x00000006c0800000 NTAMS 0x00000006c0800000 space 2048K, 99% used [0x00000006c0800000, 0x00000006c0a00000)
13AC 0 O TS 0 PTAMS 0x00000006c0a00000 NTAMS 0x00000006c0a00000 space 2048K, 97% used [0x00000006c0a00000, 0x00000006c0c00000)
14AC 0 O TS 0 PTAMS 0x00000006c0c00000 NTAMS 0x00000006c0c00000 space 2048K, 99% used [0x00000006c0c00000, 0x00000006c0e00000)
Native内存查看命令
1jcmd 15602 VM.native_memory baseline
2jcmd 15602 VM.native_memory summary
又进行了20分钟压测,这次时间从20分延迟了3分钟,23分钟,事实证明,通过简单JVM参数调优获得大改观的想法还是图样:
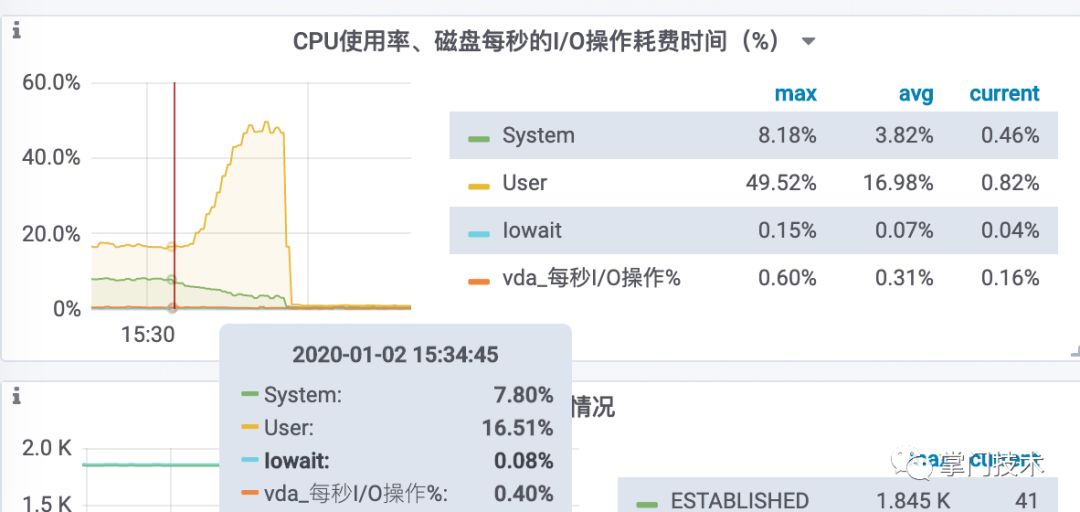
(图2-4) 使用更多CPU换取GC效率
调整G1垃圾收集线程的方法与调整CMS垃圾收集线程的方法类似:对于应用线程暂停运行的周期,可以使用ParallelGCThreads标志设置运行的线程数;对于并发运行阶段可以使用ConcGCThreads标志设置运行线程数。不过,ConcGCThreads标志的默认值在G1收集器中不同于CMS收集器。它的计算方法如下:ConcGCThreads=(ParallelGCThreads+2)/4
源码梳理
时间太晚,思路不顺,决定回家好好理理思路,还原整个车祸现场,并决定从代码逻辑层面入手,整个框架经历了很多大场合正常运行没有翻车,虽然不愿意,但是经验告诉我,代码中一定有没有考虑到的地方,于是从服务器车祸现场着手大致有这些因素需要一一排除:
1)广播功能事件API,每广播1次创建一个集合,将需要广播的对方放到集合中,第一感觉数组扩容性能以及回收,会造成YGC的延长,于是JMH根据现场逻辑还原一番。
1@OutputTimeUnit(TimeUnit.MILLISECONDS)
2 @BenchmarkMode(Mode.AverageTime)
3 @Benchmark
4 @SneakyThrows
5 public void collectAndDispatch() {
6 Iterable<Client> clients = getClients("test");
7 for (Client client : clients ) {
8 client.send(message);
9 writeAndFlush(client);
10 }
11 }
12
13 @OutputTimeUnit(TimeUnit.MILLISECONDS)
14 @BenchmarkMode(Mode.AverageTime)
15 @Benchmark
16 @SneakyThrows
17 public void directDispatch() {
18 Set<UUID> sessionIds = MAP.get("test");
19 for (UUID sessionId : sessionIds) {
20 Client client = CLIENTS.get(sessionId);
21 if(client != null) {
22 client.send(message);
23 writeAndFlush(client);
24 }
25 }
26 }
结局:打脸,Pass,JVM在处理朝生夕灭短生命对象时性能几乎可以忽略不计,对于超过一定次数的方法JIT会进行若干优化手段。
2)SocketIO广播底层代码怀疑,从发送事件到调用API逻辑排除,于是专心从这个角度去怀疑SocketIO,从代码到配置
a、同步消息
1public ChannelFuture send(Packet packet, Transport transport) {
2 TransportState state = channels.get(transport);
3 //将需要发送的packet添加进入每个用户会话待发送队列
4 state.getPacketsQueue().add(packet);
5
6 Channel channel = state.getChannel();
7 if (channel == null
8 || (transport == Transport.POLLING && channel.attr(EncoderHandler.WRITE_ONCE).get() != null)) {
9 return null;
10 }
11 //执行待发送队列的正式发送动作
12 return sendPackets(transport, channel);
13 }
b、异步处理
1private ChannelFuture sendPackets(Transport transport, Channel channel) {
2 return channel.writeAndFlush(new OutPacketMessage(this, transport));
3 }
c、handler中处理bytebuf问题,按空间复杂度N分配内存空间
1private void handleWebsocket(final OutPacketMessage msg, ChannelHandlerContext ctx, ChannelPromise promise) throws IOException {
2 ChannelFutureList writeFutureList = new ChannelFutureList();
3 //循环执行待发送队列packet的刷新,直到该队列为空
4 while (true) {
5 Queue<Packet> queue = msg.getClientHead().getPacketsQueue(msg.getTransport());
6 Packet packet = queue.poll();
7 if (packet == null) {
8 writeFutureList.setChannelPromise(promise);
9 break;
10 }
11 final ByteBuf out = encoder.allocateBuffer(ctx.alloc());
12 encoder.encodePacket(packet, out, ctx.alloc(), true);
13
14 WebSocketFrame res = new TextWebSocketFrame(out);
15 if (log.isTraceEnabled()) {
16 log.trace("Out message: {} sessionId: {}", out.toString(CharsetUtil.UTF_8), msg.getSessionId());
17 }
18
19 if (out.isReadable()) {
20 writeFutureList.add(ctx.channel().writeAndFlush(res));
21 } else {
22 out.release();
23 }
24 for (ByteBuf buf : packet.getAttachments()) {
25 ByteBuf outBuf = encoder.allocateBuffer(ctx.alloc());
26 outBuf.writeByte(4);
27 outBuf.writeBytes(buf);
28 if (log.isTraceEnabled()) {
29 log.trace("Out attachment: {} sessionId: {}", ByteBufUtil.hexDump(outBuf), msg.getSessionId());
30 }
31 writeFutureList.add(ctx.channel().writeAndFlush(new BinaryWebSocketFrame(outBuf)));
32 }
33 }
34 }
重现现场
深入还原车祸现场,从代码结构和功能看,这个过程中参与通信的对象在Netty Outbound pipline中结构比较简单,没有多余的对象耦合关联。
因为本地网络无法使用服务压测,dump在服务器上因为内存不足经常失败,于是再请上座上宾JMC(声明:本次验证仅学习使用,非生产环境),进入服务器配置好飞行记录器(行车记录仪)。
1-XX:NativeMemoryTracking=summary -Djava.rmi.server.hostname=x.x.x.x -XX:+UnlockCommercialFeatures -XX:+FlightRecorder
1)开始新一轮的模拟,使用堆分配20分钟压测,装了行车记录仪,大家都好好开车。
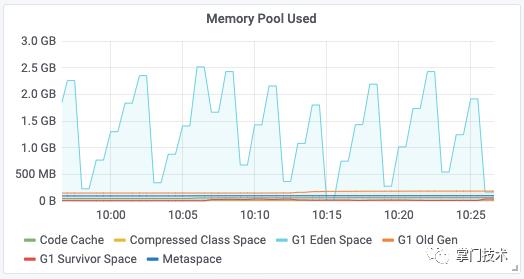
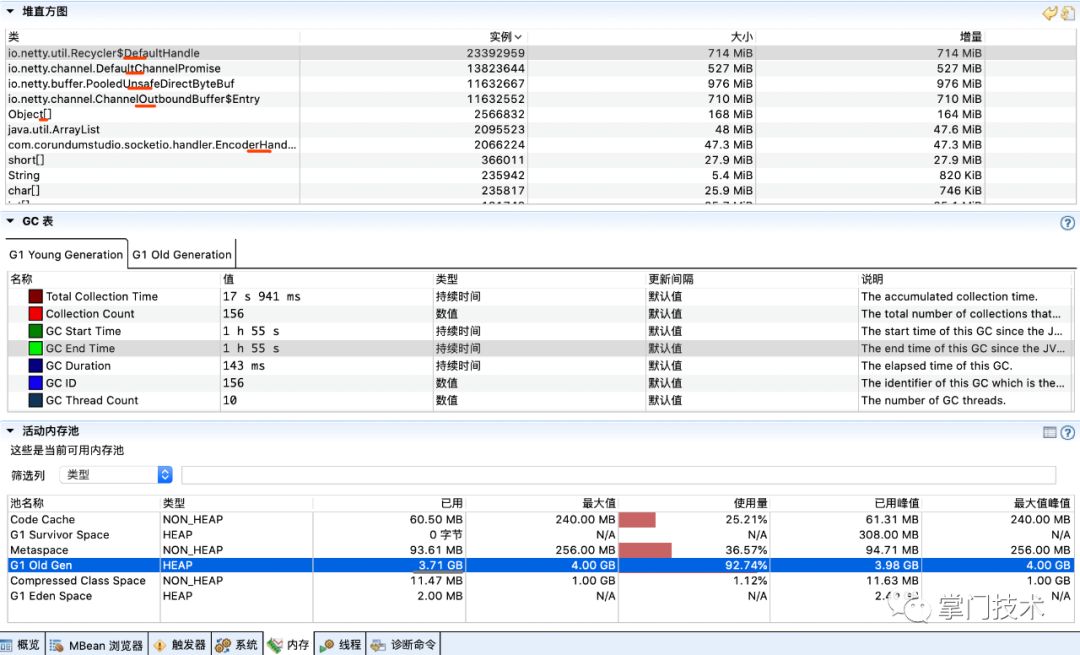
2)20分钟开始后,流量监控开始出现减少异样,第一时间刷新数据,进行堆直方图对比:
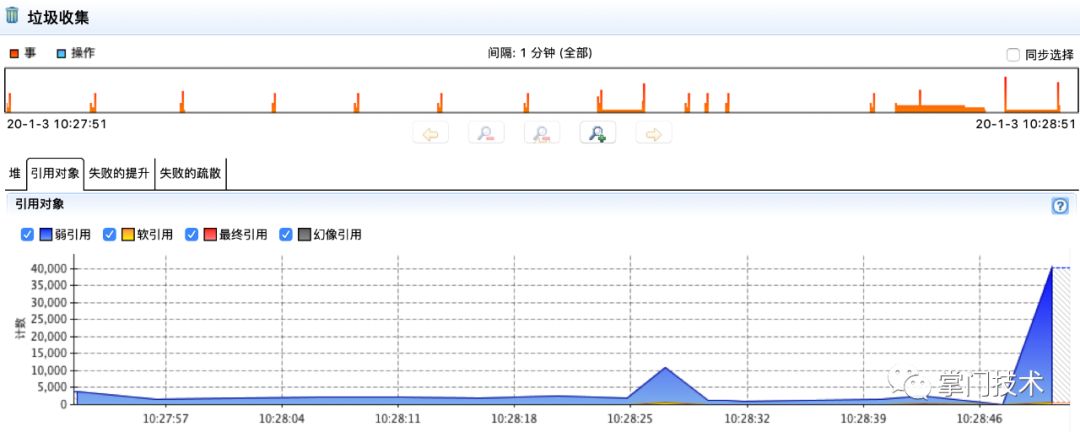
3)案发现场快速录制1分钟的飞行记录:
现场分析
理论知识支撑
1)对象分配
堆分配
TLAB分配
2)Netty内存分配
DirectPool
JdkPool
理论知识是内功修炼核心,此处不再重复,如果忘记,有很多资料可以查阅《Java性能优化权威指南》《Java虚拟机实战》《Netty权威指南》
数据分析
1)堆直方图:在压测开始后,所有数据趋于平稳情况下进行一次堆数据刷新,作为初始记录,在出现异常趋势开始时再进行一次数据刷新,作为对比数据,主要观察增量较大对象(平稳运行情况下的堆增量在10M正负区间以内)。
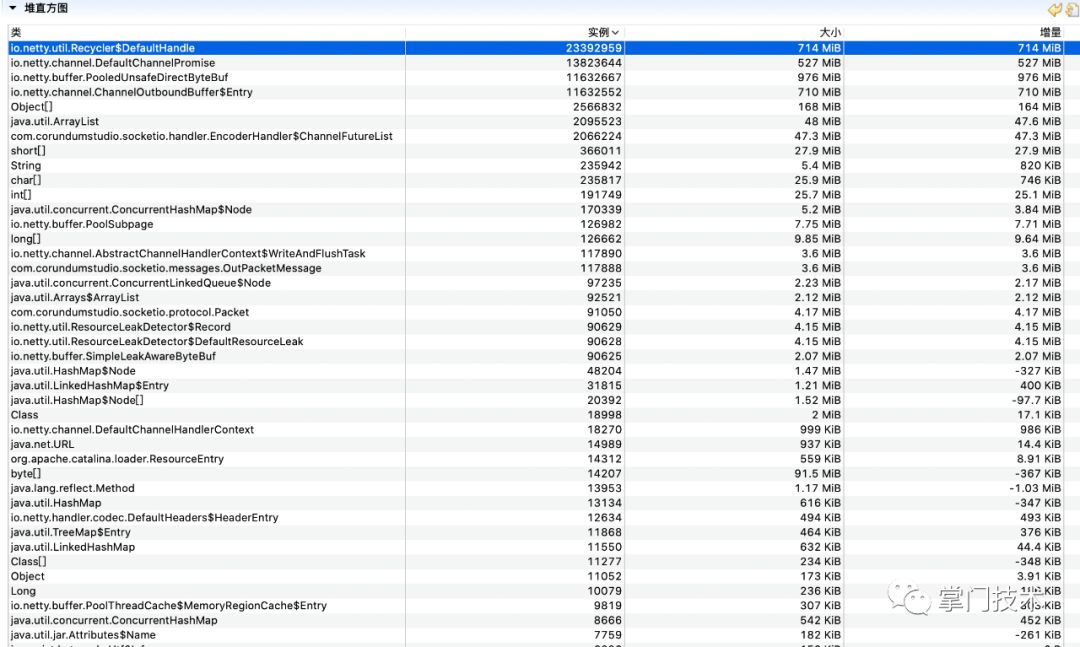
从上述的增量上看,可以看出有大量的Netty创建的发送包对象堆积,没有被销毁,而这里有个PooledUnsafeDirectByteBuf对象需要重点关注。
2)对象分配分析图:从理论支撑中可以知道,线程在分配对象时优先在TLAB中进行分配,堆直方图中增量的大量对象需要追踪出由哪个堆栈代码进行分配。
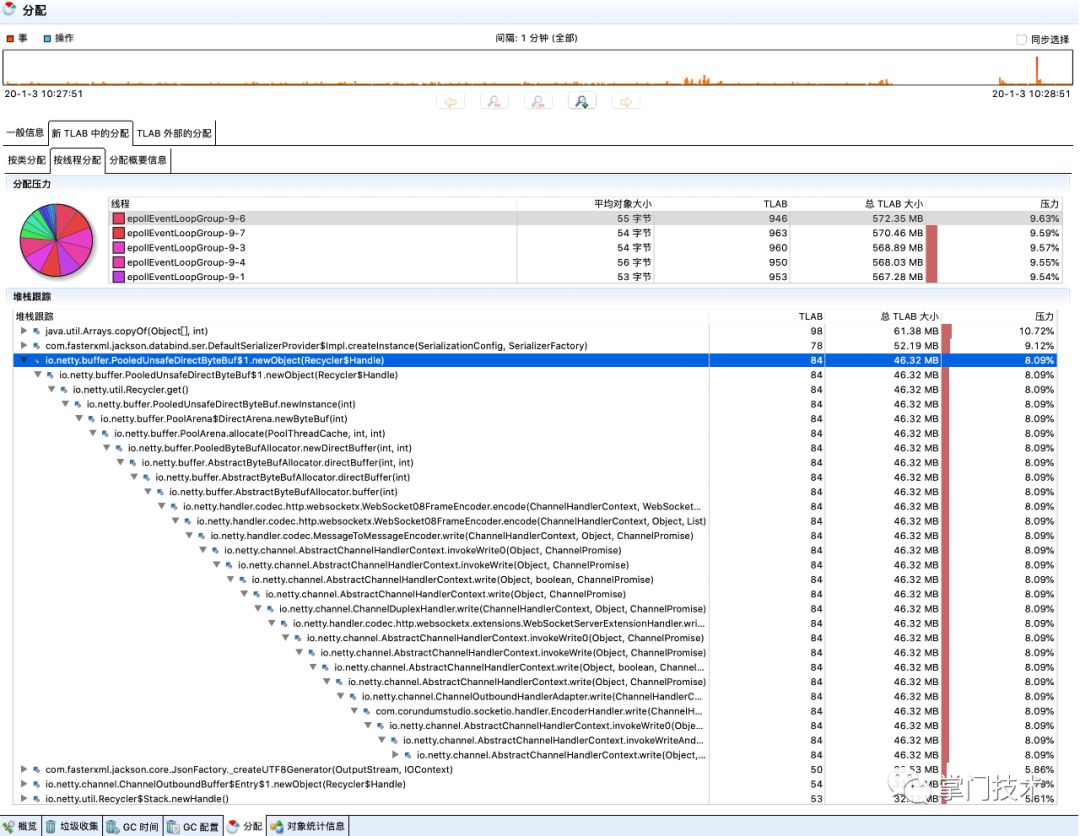
从图中经过破案分析,可以判断出由WebSocket08FrameEncoder分配了大量的ByteBuf对象,而从中可以看出,其中使用了直接内存,大量的对象和直接内存分配的结果是即耗尽了JVM分配的堆,也会逐渐耗尽系统剩余的物理内存,而为了规避直接内存问题,在SocketIO配置中,笔者特地将此处设置为堆分配,这也是一个重要疑点和未来可验证的重要依据。
3)从另外几个维度进行同样的数据追踪,标记红色区域都是需要关注的疑点:
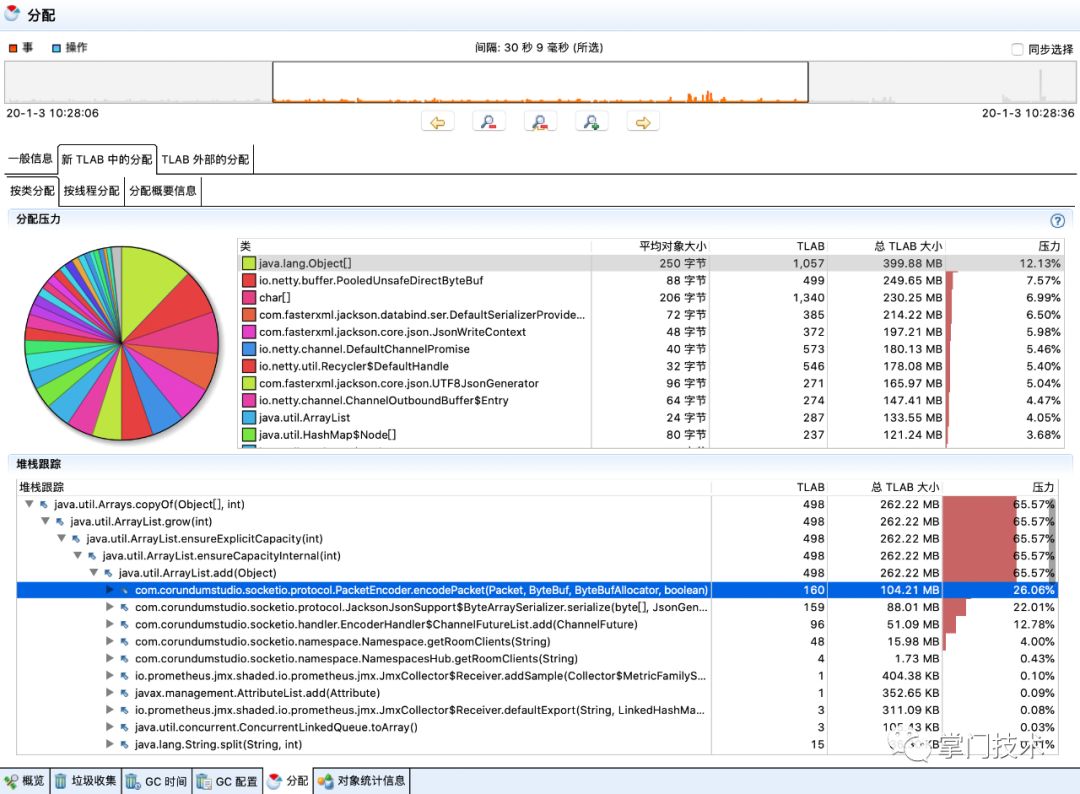
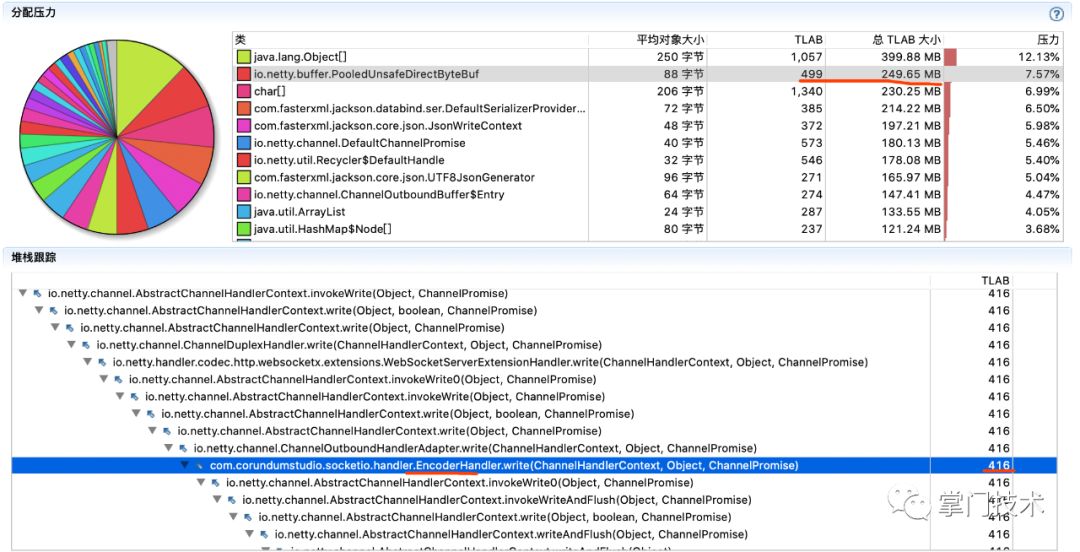
(三)定位
带着上述的疑点数据分析,几乎可以认为SocketIO内部存在嫌疑人,范围确定后,拿好抓捕令可以根据堆栈分析结果进入代码层面进行审问了。
审问
1)着重审问以下几个类中的对象
EncoderHandler
Line154. WebSocket08FrameEncoder
2)逐个破案
SocketIO使用配置进行JDK或者Direct分配空间,当进一步writeAndFlush时,Netty默认使用DirectByDefault进行堆外内存分配,此处疑惑解除。
NioSocketChannel.java
1public NiosocketChannel(Channel parent, java.nio.channels.SocketChannel socket) {
2 super(parent, socket);
3 this.config = new NioSocketChannel.NioSocketChannelConfig(this, socket.socket());
4}
DefaultSocketChannelConfig.java
1protected DefaultChannelConfig(Channel channel, RecvByteBufAllocator allocator) {
2 this.allocator = ByteBufAllocator.DEFAULT;
3 this.msgSizeEstimator = DEFAULT_MSG_SIZE_ESTIMATOR;
4 this.connectTimeoutMillis = 30000;
5 this.writeSpinCount = 16;
6 this.autoRead = 1;
7 this.autoClose = true;
8 this.writeBufferWaterMark = WriteBufferWaterMark.DEFAULT;
9 this.pinEventExecutor = true;
10 this.setRecvByteBufAllocator(allocator, channel.metadata());
11 this.channel = channel;
12}
指认现场
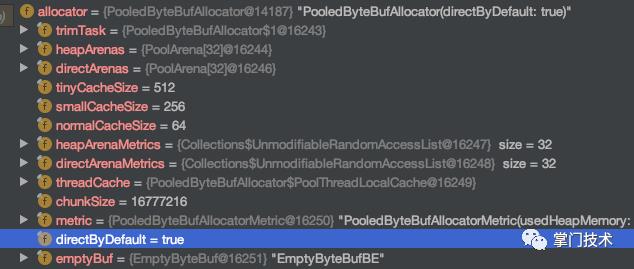
整个SocketIO在进行发送时,有2个地方使用了ButeBuf的内存申请工作,为了避免堆外的问题,在一开始使用了堆分配,然后在WebSocket层面,Netty使用了默认的堆外分配,而车祸现场中,巨大的对象数量是堆分配的,所以能得到,堆和堆外的占用在同时放大。
经过这一轮分析,基本上已经可以下结论,因为网络拥塞或者客户端消费速度达不到服务器的速度导致了服务器消息发送了堆积。
根据这个思路,进入了常规操作空间,服务器拥塞问题通常需要设置TcpBuffer和水位控制,于是破案这个环境中是否对这些配置进行设置或者生效,其次,更艰难的是该如何设定这些值。
默认的确没有配置:
1private SocketConfig socketConfig = new SocketConfig();
2public class SocketConfig {
3 private boolean tcpNoDelay = true;
4 private int tcpSendBufferSize = -1;
5 private int tcpReceiveBufferSize = -1;
(四)整改
防范上存在漏洞,自我的安全保护机制则需要进行深化整改,首先需要对SocketIO的Netty部分默认配置进行二次设置。
Buffer设置
1if (config.getTcpSendBufferSize() != -1) {
2 bootstrap.childOption(ChannelOption.SO_SNDBUF, config.getTcpSendBufferSize());
3}
4if (config.getTcpReceiveBufferSize() != -1) {
5 bootstrap.childOption(ChannelOption.SO_RCVBUF, config.getTcpReceiveBufferSize());
6 bootstrap.childOption(ChannelOption.RCVBUF_ALLOCATOR, new FixedRecvByteBufAllocator(config.getTcpReceiveBufferSize()));
7}
水位设置
SocketIO没有针对Netty水位直接配置选项,需要开发者重写SocketIOServer类并添加配置项。
对Options方法仅从复写,加入高低水位控制参数。
对发送API接口进行改进,针对发送的接口进行优先水位判断,并将结果加入到监控体系(此处非常重要)。
后续复盘复现过程中,此处需要通过arthas进行证据提取。
1ClientHead head = ((NamespaceClient)client).getBaseClient();
2TransportState state = head.getCurrentTransportState();
3Channel channel = state.getChannel();
4if (channel == null) {
5 return;
6}
7//fallback
8if (!channel.isWritable()) {
9 //TODO 输出到监控,此处Log消息过大,Log仅为验证输出用, 还可以打印出当前channel对应的未发送的queue的byteSize
10 //int size = state.getPacketsQueue().size();
11 //log.warn("channel is not writable, current sessionId: {}, queue-size: {}", client.getSessionId(), size);
12 return;
13}
14
15//--------------
16netty.socketio.tcpSendBufferSize = 32k
17netty.socketio.serverBufferLow = 32k
18netty.socketio.serverBufferHigh = 64k
参数验证
加上配置之后,在此模拟车祸现场情况下,预估会产生几种结果:
配置过大,没有发挥总用
发挥作用,按照经验依然还会被linux kill掉
发挥作用,设定一个刚好的值,服务器保命最大,接下来才能去谈人生、上监控
继续压测,得到一个满足期望相对较优的具体参数值,进过多轮压测,逐个命中上述的3个预期结果,参数设置逐渐趋于明朗。
结果1:内存暴增,无法保持正常的连接心跳,连接断开
1syscall:read(..) failed: Connection reset by peer
结果2:物理内存逐渐减少,服务被Linux Kill
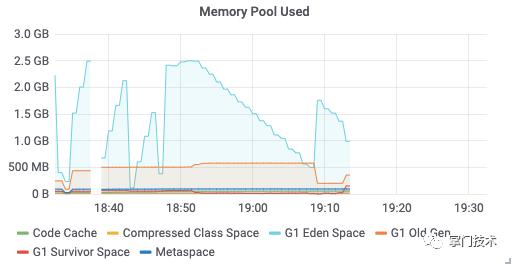
结果3:设置一些相对较优的参数(根据多次压测得出),以下是得出的过程介绍。
1)以一个较大的限流QPS,期望快速进入缓冲池打满。
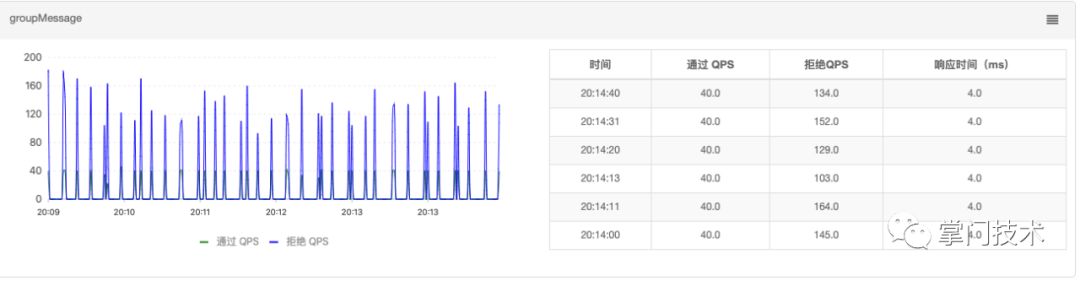
2)得出两个截然不同的结果,在第二个压测周期内,在预期Buffer进入警戒后,整改发挥了效果。
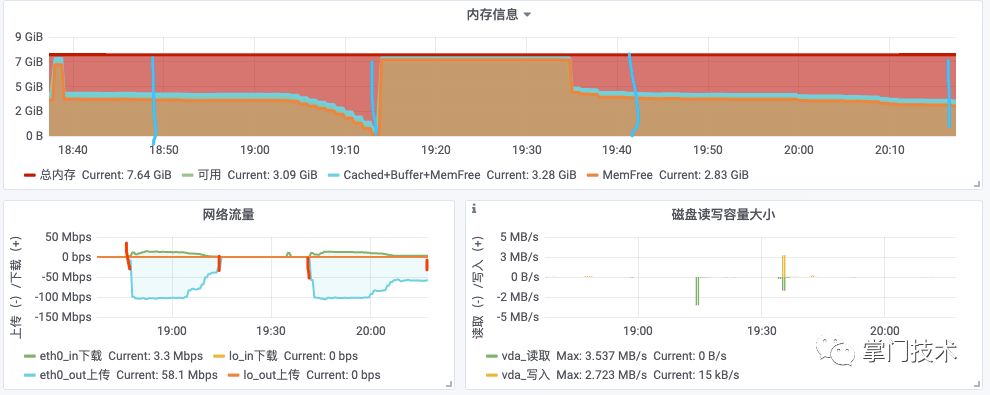
上图包含了内存和网络2个维度的2次压测结果对比,第一次命中预测2,第二次命中预测3。
预测2:参数发挥了作用,延长了流量减少到最终被Linux kill中间的时间,且从内存可以看出对外分配几乎耗尽了整个剩余的物理内存。
预测3:当发生网络拥塞后,服务器自我保护机制启动,对高于水位情况下的消息不发送,待水位趋于正常后继续发送,保证稳定的输出,并且对丢弃消息包进行监控、预警。
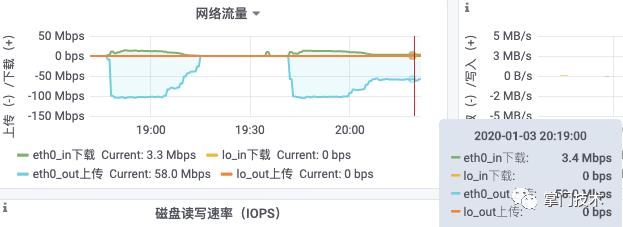
3)查看具体的流量数据,流程趋于平稳且数据在预期中。
4)通过命令验证TCP缓冲区情况:
1[root@xxx]20:18:49# cat /proc/net/sockstat
2sockets: used 2080
3TCP: inuse 9 orphan 0 tw 75 alloc 1855 mem 23811
4UDP: inuse 1 mem 6
5UDPLITE: inuse 0
6RAW: inuse 0
7FRAG: inuse 0 memory 0
验证缓冲区不断变大的动态过程:
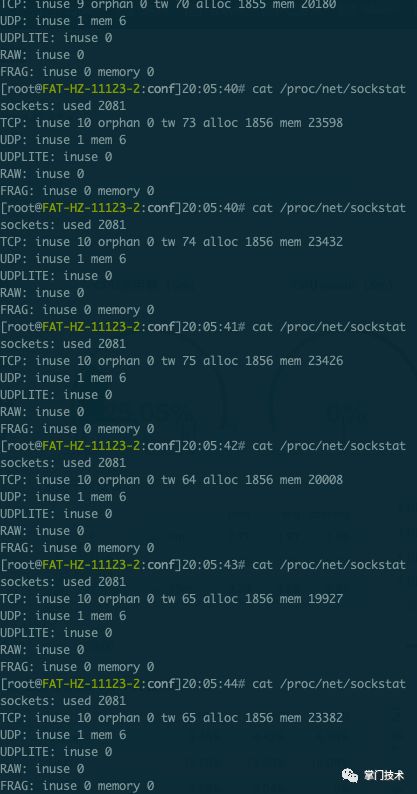
5)最终在进行一次30分钟直方图增量分析,基本上可以确定为区域不变,目标基本达成,问题基本解决。
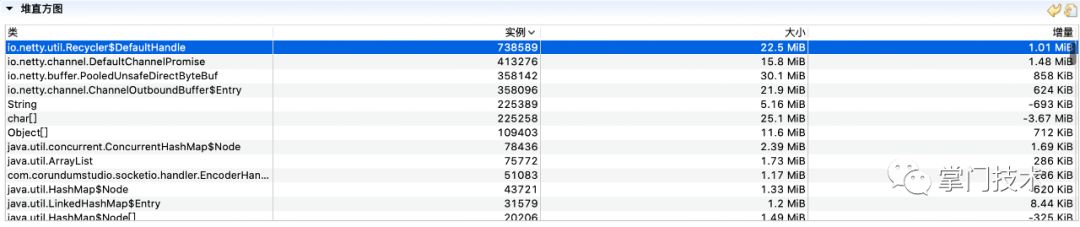
6)抓虫虫
使用arthas定位到发生泄漏的疏忽点进行监控,压测机器部署在测服或者生产服务,arthas可以通过简单的配置和命令在对的时间对的地点可以完整展现整个泄漏现场的对象和参数。
a)确定java进程启动用户和当前用户是否一致,如果不一致需要切换到统一用户启动和监控
b)定位到java进程pid
c)启动arthas定位到具体方法全路径,针对入参、出参、通过ognl表达式实现更细颗粒度的现场查看
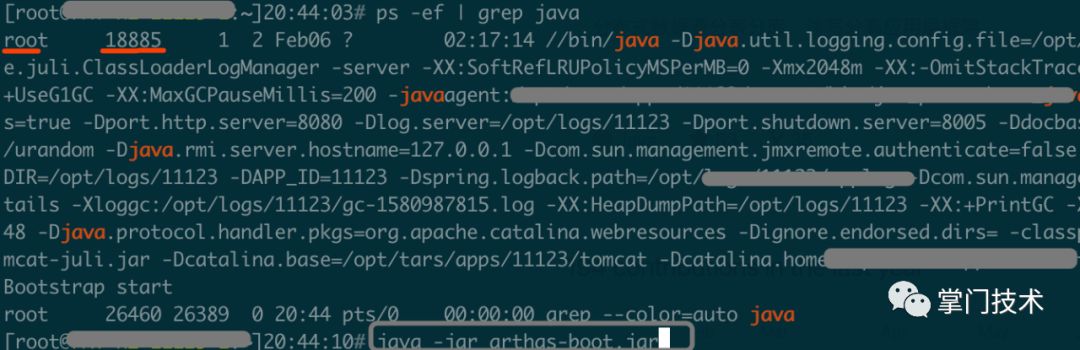
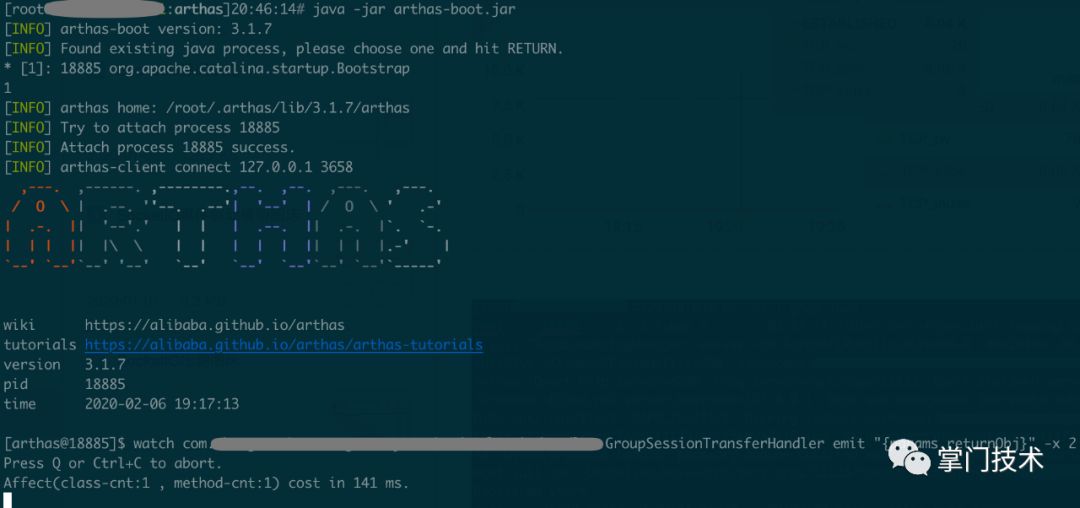
篇幅原因,验证过程环节、工具选型介绍、参数介绍、底层原理不再详细说明。
(五)复盘
复盘是对整个故障一个全面的事后总结,期以避免问题再现,更甚举一三反,做到系列问题的规避和容错。
基础设定
水位设定重要性
1cat /proc/sysctl.conf
2# TCP读buffer
3net.ipv4.tcp_rmem = 4096 87380 4194304
4# TCP写buffer
5net.ipv4.tcp_wmem = 4096 16384 4194304
6# 默认的发送窗口大小
7net.core.wmem_default = 8388608
8# 默认的接收窗口大小
9net.core.rmem_default = 8388608
10# 最大socket接收缓冲
11net.core.rmem_max = 16777216
12# 最大socket发送缓冲
13net.core.wmem_max = 16777216
原理分析
详细介绍水位在其中的作用:异步化是提高吞吐量的一个很好的手段。但是,与异步相比,同步有天然的负反馈机制,也就是如果后端慢了,前面也会跟着慢起来,可以自动的调节。但是异步就不同了,异步就像决堤的大坝一样,洪水是畅通无阻。如果这个时候没有进行有效的限流措施就很容易把后端冲垮。如果一下子把后端冲垮倒也不是最坏的情况,就怕把后端冲的要死不活。这个时候,后端就会变得特别缓慢,如果这个时候前面的应用使用了一些无界的资源等,就有可能把自己弄死。那么现在要介绍的这个坑就是关于Netty里的ChannelOutboundBuffer这个东西的。这个buffer是用在netty向channel write数据的时候,有个buffer缓冲,这样可以提高网络的吞吐量(每个channel有一个这样的buffer)。初始大小是32(32个元素,不是指字节),但是如果超过32就会翻倍,一直增长。大部分时候是没有什么问题的,但是在碰到对端非常慢(对端慢指的是对端处理TCP包的速度变慢,比如对端负载特别高的时候就有可能是这个情况)的时候就有问题了,这个时候如果还是不断地写数据,这个buffer就会不断地增长,最后就有可能出问题了(我们的情况是开始吃swap,最后进程被linux killer干掉了)。为什么说这个地方是坑呢,因为大部分时候我们往一个channel写数据会判断channel是否active,但是往往忽略了这种慢的情况。
那这个问题怎么解决呢?其实ChannelOutboundBuffer虽然无界,但是可以给它配置一个高水位线和低水位线,
当buffer的大小超过高水位线的时候对应channel的isWritable就会变成false,
当buffer的大小低于低水位线的时候,isWritable就会变成true。所以应用应该判断isWritable,如果是false就不要再写数据了。
高水位线和低水位线是字节数,默认高水位是64K,低水位是32K,我们可以根据我们的应用需要支持多少连接数和系统资源进行合理规划。
1b.childOption(ChannelOption.WRITE_BUFFER_WATER_MARK, new WriteBufferWaterMark(
2 connect_server_low, connect_server_high
3));
为了把这件事情说清楚,笔者画了2张图来描述当程序通过API把数据发送到内核之后的过程处理流程。
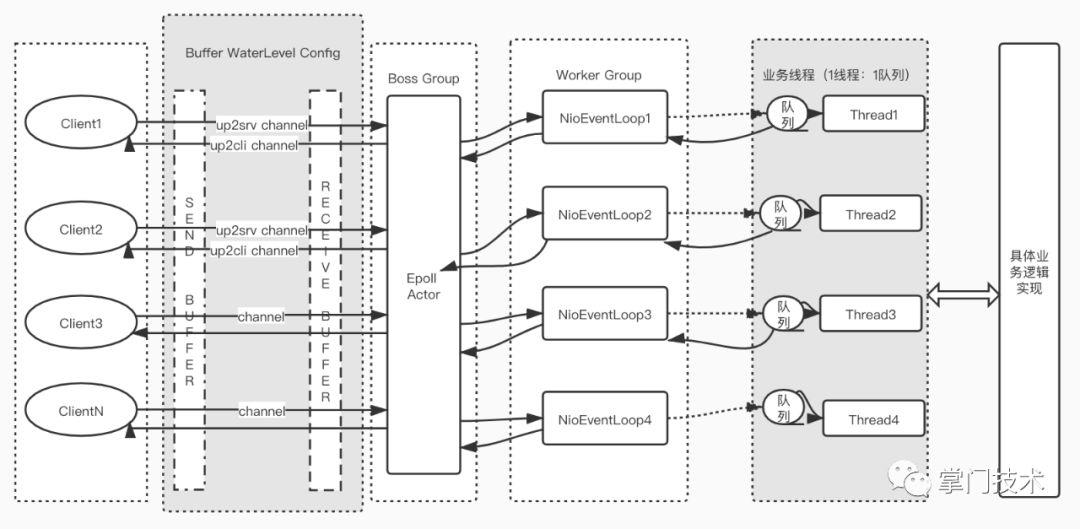
抗疲劳检验
从后续多次多个小时的压测结果下,上述问题没有再次发生,从下面的监控中体现出缓冲区和水位限流已经生效,在接收端拥塞的情况下,保证了服务端系统的可靠性。
将本次问题解决方案量化到业务系统监控:
Netty其他优化
Nagel算法禁用建议
socketio默认关闭TCP_NODELAY=true,通常根据报文大小和报文数量来设置。
soLinger:socketio默认-1,禁用该功能,表示socket.close时,操作系统OS底层依然将缓冲区发送全部到对端
开启并使用NativeMemory
建议:
从Java8开始,借助XX:NativeMemoryTracking=off|summary|detail这个选项,JVM支持我们一窥它是如何分配原生内存的。原生内存跟踪(NativeMemoryTracking,NMT)默认是关闭的(off模式)。如果开启了概要模式(summary)或详情模式(detail),可以随时通过jcmd命令获得原生内存的信息:
1jcmd process_id VM.native_memorysummary
Epoll动态支持
之前事件驱动一篇已经介绍,此处不再重复。
1/**
2 * 在Netty 4中实现了一个新的ByteBuf内存池,它是一个纯Java版本的 jemalloc (Facebook也在用)。
3 * 现在,Netty不会再因为用零填充缓冲区而浪费内存带宽了。不过,由于它不依赖于GC,开发人员需要小心内存泄漏。
4 * 如果忘记在处理程序中释放缓冲区,那么内存使用率会无限地增长。
5 * Netty默认不使用内存池,需要在创建客户端或者服务端的时候进行指定
6 */
7b.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
8b.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
Backlog设定:
ChannelOption.SO_BACKLOG, 1024
在netty实现中,backlog默认通过NetUtil.SOMAXCONN指定。
这个都是socket的标准参数,并不是netty自己的。
具体为:
BACKLOG用于构造服务端套接字ServerSocket对象,标识当服务器请求处理线程全满时,用于临时存放已完成三次握手的请求的队列的最大长度。如果未设置或所设置的值小于1,Java将使用默认值50。
1b.option(ChannelOption.SO_BACKLOG, 65535);
缓冲区:
1/**
2 * TCP层面的接收和发送缓冲区大小设置,
3 * 在Netty中分别对应ChannelOption的SO_SNDBUF和SO_RCVBUF,
4 * 需要根据推送消息的大小,合理设置,对于海量长连接,通常32K是个不错的选择。
5 */
6if (snd_buf.connect_server > 0) b.childOption(ChannelOption.SO_SNDBUF, snd_buf.connect_server);
7if (rcv_buf.connect_server > 0) b.childOption(ChannelOption.SO_RCVBUF, rcv_buf.connect_server);
水位设定:
默认情况:
ChannelConfig默认的水位配置为低水位32K,高水位64K,如果用户没有配置就会使用默认配置。
1private volatile WriteBufferWaterMark writeBufferWaterMark = WriteBufferWaterMark.DEFAULT; //设置默认配置
1/**
2 * 当buffer的大小超过高水位线的时候对应channel的isWritable就会变成false,
3 * 当buffer的大小低于低水位线的时候,isWritable就会变成true。所以应用应该判断isWritable,如果是false就不要再写数据了。
4 * 高水位线和低水位线是字节数,默认高水位是64K,低水位是32K,我们可以根据我们的应用需要支持多少连接数和系统资源进行合理规划。
5 */
6b.childOption(ChannelOption.WRITE_BUFFER_WATER_MARK, new WriteBufferWaterMark(
7 connect_server_low, connect_server_high
8));
流量整形
流量整形在SocketIO 中并不被包含在pipline编排内,可根据场景进行流量整形实践 GlobalChannelTrafficShapingHandler
1if (enabled) {
2 trafficShapingExecutor = Executors.newSingleThreadScheduledExecutor(new NamedPoolThreadFactory(TRAFFIC_SHAPING));
3 trafficShapingHandler = new GlobalChannelTrafficShapingHandler(
4 trafficShapingExecutor,
5 write_global_limit, read_global_limit,
6 write_channel_limit, read_channel_limit,
7 check_interval);
8 }
本次排障用到的工具
掌门完善的基础服务(Linux基础监控、JVM监控、可定制的发布系统、Sentinel)
JMC
SocketIO业务监控【自研监控体系】
Linux参数命令
arthas@alibaba:monitor/trace/watch(观察send方法泄漏证据)
1[net]
2getconf PAGESIZE
3cat /proc/net/sockstat
4sysctl -a
5[jvm]
6java -XX:+PrintFlagsFinal -version
7jstat -gcnew/-gccapacity/-gcutil pid
8jinfo pid
9jcmd pid VM.native_memory baseline
10jcmd pid VM.native_memory summary
疏忽点
整个压测故障分析中都没有考虑到压测机的监控现场数据,而是凭借经验从泄漏点直接判断出压测机的自身发生了消息消费能力不足(结果的监控也验证了这点),对整个现场数据覆盖范围的局限导致了第一次使用JVM调优作为手段应对,对整个故障现场的回顾做到监控的最大覆盖时刻体现监控的重要性,科学的监控可以最大化减少人为、直觉、口头上的不准确描述,对计算机来说,数据是最大证据,对开发者,第一手资料最准确。
举一反三
类似案情
超大消息
超大广播基数
弱网
应用无限重试
限流无上限
其他
整个问题破案都是基于TCP协议作为传输协议的前提,当前服务器使用的TCP的特性决定了在网络发生拥塞情况下,TCP的可靠保证和拥塞算法会加剧整个阻塞程度,从这个角度出发,未来可能会从以下2维度进行关注:
基于TCP-BBR算法的协议
QUIC/UDP
(六)反思
问题破案几乎是所有技术人员都会面对并且需要着手解决的事情,根据难易程度、影响范围、紧急程度对问题破案设立优先级,诸葛亮不常有,但细致的观察、丰富的经验、工具、给力的团队能将大事化小,快速解决,剥丝抽茧,刨根问底对技巧和熟练度有着很高的要求,运气时有时无,在问题破案时通常还是会有一些常规流程可遵循(时间范围、版本变化、案发现场第一首资料掌握程度),做到镇定果断,多因子偶发性问题,无法简单重现,规律不可寻,做好案发现场的保护可能会是最后的证据。
开源敬畏和怀疑之道
netty-socketio作为接入框架在整个项目中仅仅覆盖的是连接层面的实现和基础模型的抽象,更多的业务和生产监控需求还需要业务方更加深入的投入,一个成熟的平台不仅仅是一个框架的玩法,更是一个生态的健全和迭代,在构建上,无论是基础服务还是业务实现,尽量避免重复造轮子,专业的事情交给专业的工具,但需要对轮子的好坏了如指掌,需要时刻关注轮子的性能范围还需给轮子加上轮胎监测。
对于开源领域的高级功能,高级带来的高收益也意味着难以掌控的高风险,在满足扩展性的前提下,做到容量内的实现和容量外的规划,过渡设计的背后都会给团队带来难以偿还的技术债务,大多数情况下,功能在大而全面前,稳定往往是权重最大的。高QPS/高响应/低内存,三者只能取其二。
在这次压测的故障中,因为压测机的处理性能低于服务器发送的数据,导致压测机故障,本身并不归属服务器问题,但是反应出服务器在自我保护措施上做的不够完善,对于类似可能的情况的破案会进一步提升服务内功。在最新的压测中,单台7K用户,以20帧/S的速度进行IM消息的广播,网卡上行250+Mbps的流量冲刷下完成一期抗疲劳压测,未来我们期望通过更多深度优化来持续提升Socket吞吐量任重道远。
最后,祝福武汉,武汉加油!
个人邮箱:xumin.wlt@gmail.com
Github:https://github.com/xuminwlt/
作者介绍:徐敏,开源爱好者,10年+互联网开发经验,现任掌门课堂云架构师,主要负责课堂云实时交互中台和4层网关架构设计开发工作。
以上是关于Netty广播场景压测内存泄漏破案全流程的主要内容,如果未能解决你的问题,请参考以下文章
破案现场:记一次压测异常排查--Redisson锁失效的场景