SQL为王:oracle标量子查询和表连接改写
Posted 数据和云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL为王:oracle标量子查询和表连接改写相关的知识,希望对你有一定的参考价值。
小鱼(邓秋爽)
云和恩墨专家,有超过5年超大型数据库专业服务经验,擅长oracle 数据库优化、SQL优化和troubleshooting
编辑手记:如何提高数据的查询效率是每个人都关注的问题,今天让我们来学习如何合理使用标量子查询和表连接方式来提高查询速度吧~
之前小鱼就听过了标量子查询,不过对于其中的细节理解还是远远不够,借助一部分资料和自己测试对标量子查询做一点简单的分析和介绍。
Oracle允许在select子句中包含单行子查询,这个也就是oracle的标量子查询,标量子查询有点类似于外连接,当使用到外连接时我们可以灵活的将其转化为标量子查询。我们来看下面的例子:
SQL> create table t1 as select * from all_users;
Table created.
SQL> create table t2 as select * from all_objects;
Table created.
SQL> select a.object_id,(select b.username from t1 b where a.owner=b.username) from t2 a;
49812 rows selected.
其执行计划和统计信息如下:
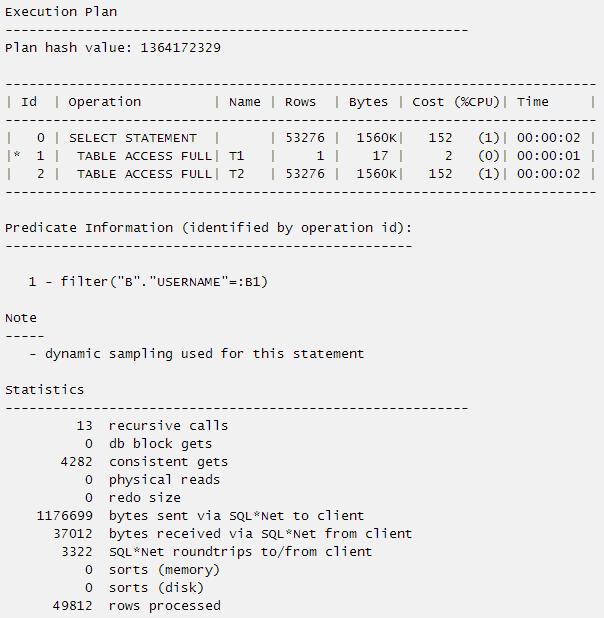
标量子查询其实还是一个子查询,那么它究竟是如何查询的:首先走的是外部的查询,比如上一个sql语句执行计划,先全表扫描的T2 a,然后取T2 a表的每一行数据就去和T1 b去过滤,过滤条件是a.owner=b.username,如果符合则返回子查询的值,如果不符合则用null补充。当然这个时候还有个类似的filter去重的运算,对于t2 a中重复的数据行不用再去和t1 b去过滤。
而上面这个标量子查询的sql语句其实是等价于下面外连接sql语句的:
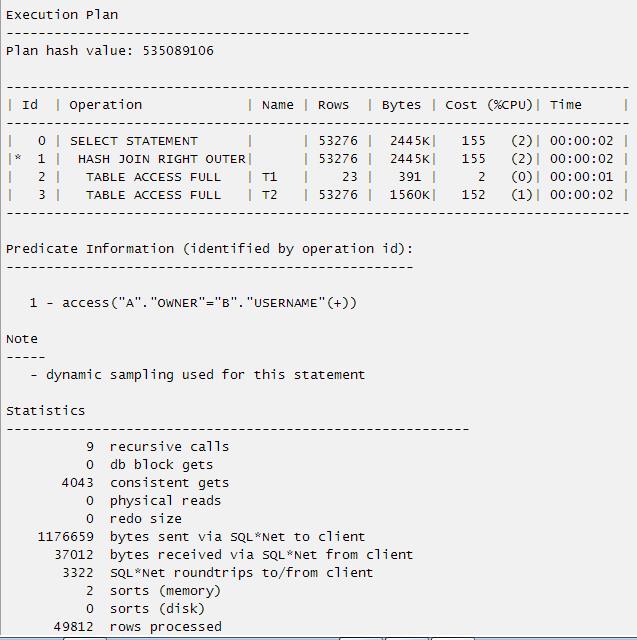
SQL> select a.object_id,b.username from t2 a,t1 b where a.owner=b.username(+) ;
49812 rows selected.
其执行计划和统计信息如下
而如果标量子查询中如果主查询的一行对应子查询返回有多个值,这个是不允许的,看下面的例子
SQL> select a.username,b.object_id from t1 a,t2 b where a.username=b.owner(+);
29742 rows selected.
我们来看执行计划和统计信息
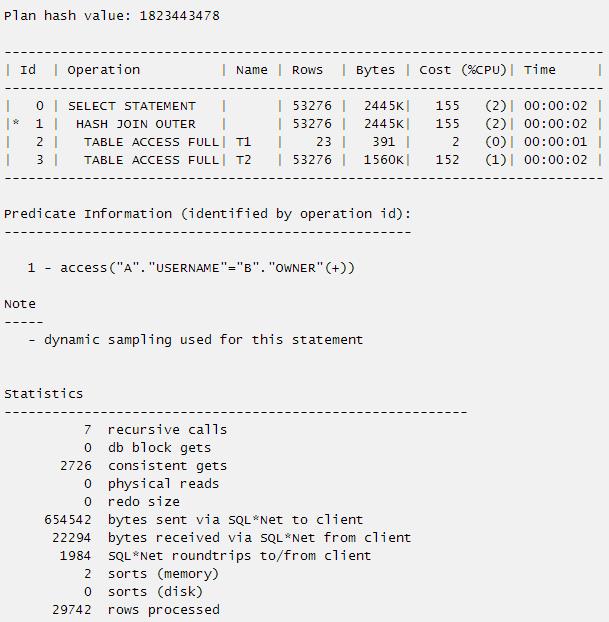
看下面的例子
SQL> select a.username,(select b.object_id from t2 b where a.username=b.owner) from t1 a;
select a.username,(select b.object_id from t2 b where a.username=b.owner) from t1 a
*
ERROR at line 1:
ORA-01427: single-row subquery returns more than one row
这里由于a.username=b.owner,其中b.owner有多个相同的值,所以这里返回的b.object_id可能有多个值,这里就出现上述的ora-01427错误。
标量子查询中也可以有聚合函数的出现:
SQL> select a.username,(select max(b.object_id) from t2 b where b.owner=a.username) from t1 a;
23 rows selected.
我们来看执行计划和统计信息:
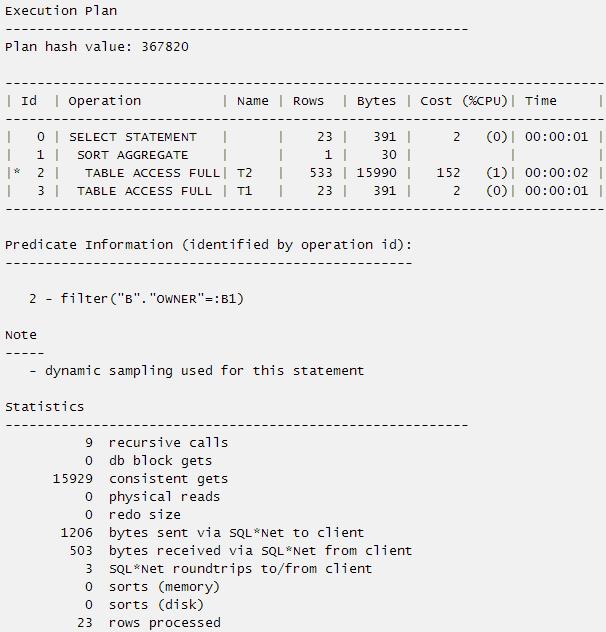
但是我们注意到上述标量子查询却存在一个问题,就是无法将子查询展开为表连接,换句话说无法采用灵活的hash join outer的关联方式。
关于标量子查询和表关联的性能简介:
如果主查询返回的数据较多,而子查询中又没有高效的索引,关联列对应的主查询表又没有较多的重复值,那么这个标量子查询的执行成本是很大的,如上面的标量子查询和外连接的sql语句中可以看出外连接IO成本要明显小于标量子查询。
但是标量子查询oracle内部确是有优化的,优化器cache了中间的结果,如果结果集不大,子查询中又有高效的索引,那么这个标量子查询可能会比常规的表关联更加高效。
小鱼列出几种常会涉及到的标量子查询和表连接的sql改写:
1. 最简单的标量子查询
table :a(a1,a2),b(a1,b2)
select a2,(select b2 from b where b.a1=a.a1) from a
表连接:
select a2,b2 from a,b where a.a1=b.a1(+);
2. 标量子查询带有聚合函数
table :a(a1,a2),b(a1,b2)
select a2,(select sum(b2) from b where b.a1 = a.a1) from a
表连接1:
SELECT a2, x.sum_value
FROM a,
( SELECT SUM (b2) sum_value, a1
FROM b
GROUP BY a1) x
WHERE a.a1 = x.a1(+);
3. 包含行转列的标量子查询改写
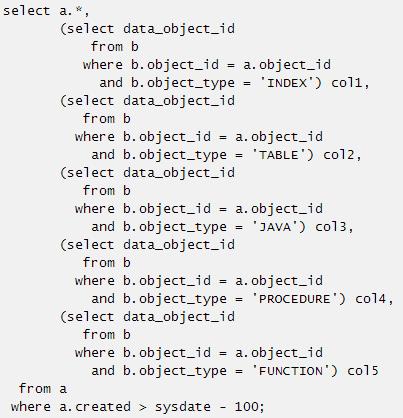
改写的SQL如下:
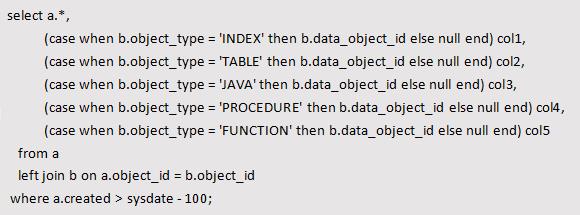
4. 标量子查询同时包含行转列和聚合函数
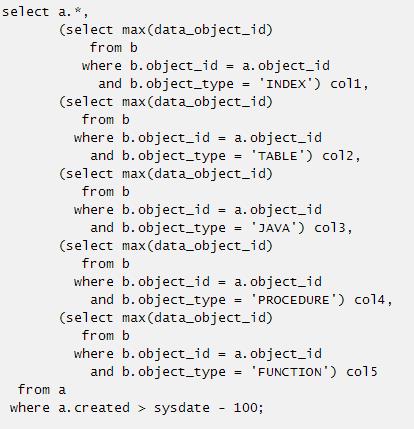
改写如下:

5. 标量子查询中出现rownum=1或者rownum<2
原则上标量子查询中出现rownum表示该SQL本来就是不严谨的,加上ROWNUM=1更多是为了防止标量子查询中返回多行而出现错误:
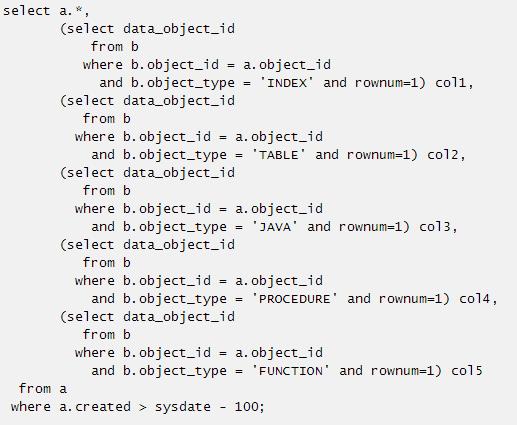
比如上面的SQL语句中对每个标量子查询都添加了rownum=1的限制,那么上述这个SQL语句如何改写为表的外连接了。这里首先取其中一个标量子查询来做分析:
select data_object_id
from b
where b.object_id = a.object_id
and b.object_type = 'INDEX' and rownum=1
比如b表中有两行数据都满足b.object_id = a.object_id and b.object_type = 'INDEX'条件,rownum=1后oracle会根据b表的执行计划取到第一条后就返回,这两行数据都有可能取到,具体取哪一行要决定B表的访问方式是索引扫描还是全表扫描等,而在这个SQL本意中无论取哪一条都是满足业务需求的。那么这个标量子查询则可以简化为:
select max(data_object_id)
from b
where b.object_id = a.object_id
and b.object_type = 'INDEX'
or
select min(data_object_id)
from b
where b.object_id = a.object_id
and b.object_type = 'INDEX'
那么原SQL的标量子查询可以简化为:
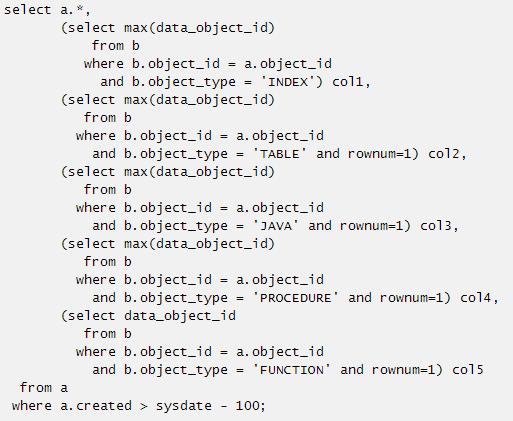
如何改写包含聚合函数的标量子查询之前已经介绍过,这里直接改写为如下SQL语句:

其实这个b.object_type in ('INDEX', 'TABLE', 'JAVA', 'PROCEDURE', 'FUNCTION')写不写也都符合业务逻辑
6. 关于标量子查询改写后逻辑校验:
select a.job,
a.deptno,
(select distinct dname from dept2 b where b.deptno=a.deptno) as dname
from emp a
有以下两个改写可供参考:
select distinct a.job,a.deptno,b.dname
from emp a
left join dept2 b on b.deptno=a.deptno;
select a.job,a.deptno,b.dname。
from emp a
left join (select dname,deptno from dept2 group by dname,deptno)b
on b.deptno=a.deptno
这里xiaoyu觉得第二种写法是完全复合业务逻辑的
简要分析下,对于原标量子查询中的(select distinct dname from dept2 b where b.deptno=a.deptno) as dname,由于标量子查询中只能返回单行,换句话说就是每个满足b.deptno=a.deptno条件的数据只能返回一行distinct dname,那么就是select dname,deptno from dept2 group by dname,deptno生成的数据不会有(dname=x deptno=a)和(dname=y deptno=a)的数据,因为这类数据在原SQL语句中如果存在是会报错的,那么可以确定的是对于dept2表只要deptno确定了,dname就确定了,所以这个改写不会改变原SQL的含义。
7. 不等连接的标量子查询改写:
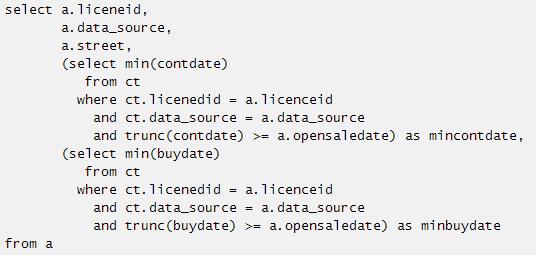
这个SQL主要是在标量子查询中用了聚合函数min和非等值关联trunc(contdate) >= a.opensaledate和trunc(buydate) >= a.opensaledate,聚合函数可以参考我们之前的写法用group by先行构造,但是非等值连接如何改写了。

由于有min聚合函数,必须要分组,但是上面这个SQL如果对a.liceneid,a.data_source,a.street三个字段分组,则不满足原SQL的含义,那么这个SQL究竟如何改写。
这里参考oracle 查询优化改写案例书籍,要改写这类不等连接的标量子查询,可以参考下面的写法

这个改写思路其实可以这么理解:首先构造x表,这个表存储了都是满足了
ct.licenedid = a.licenceid、
and ct.data_source = a.data_source、
trunc(ct.contdate)>=a.opensaledate
trunc(ct.buydate)>=a.opensaledate条件的a.rowid、min(contdate)和min(buydate)数据,同样有min函数如果需要将这些满足条件的数据输出需要再次关联一次a表,而比较容易的就是将满足条件的rowid去和a表重复做left join,满足a.rowid=x.rid就全部输出,不满足在的就补全null
其实还可以用分析函数更简单的改写为
------The end
如何加入"云和恩墨大讲堂"微信群
关注本微信(OraNews)回复关键字获取
2016DTCC, 2016数据库大会PPT;
DBALife,"DBA的一天"精品海报大图;
12cArch,“Oracle 12c体系结构”精品海报;
DBA01,《Oracle DBA手记》第一本下载;
YunHe,“云和恩墨大讲堂”案例文档下载;
以上是关于SQL为王:oracle标量子查询和表连接改写的主要内容,如果未能解决你的问题,请参考以下文章