静默错误:Oracle 数据库是如何应对和处理的 ?
Posted 数据和云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了静默错误:Oracle 数据库是如何应对和处理的 ?相关的知识,希望对你有一定的参考价值。
这两天,关于腾讯云『因为静默错误,把创业公司的数据彻底搞丢了』的事件已经传遍了整个互联网,引发了广泛的热议和讨论。
腾讯云已经于8月7日公布了最近这次事故的根本原因:
故障过程复盘 当天上午11:57,运维人员收到仓库Ⅰ空间使用率过高告警,准备发起搬迁扩容;在14:05时,从仓库Ⅰ选择了一批云盘搬迁至新仓库Ⅱ,为了加速搬迁,手动关闭了迁移过程中的数据校验;在20:27 搬迁完成之后,将客户的云盘访问切至仓库Ⅱ,同时为了释放空间,对仓库Ⅰ中的源数据发起了回收操作;到20:30 监控发现仓库Ⅱ部分云盘出现IO异常。
故障原因复盘 本次事故起源自因磁盘静默错误导致的单副本数据错误,再由于数据迁移过程中的不规范操作,导致异常数据扩散至三副本,进而导致客户数据完整性受损。
数据搬迁过程中的违规操作主要如下两点:
o第一是正常数据搬迁流程默认开启数据校验,开启之后可以有效发现并规避源端数据异常,保障搬迁数据正确性,但是运维人员为了加速完成搬迁任务,违规关闭了数据校验;
o第二是正常数据搬迁完成之后,源仓库数据应保留24小时,用于搬迁异常情况下的数据恢复,但是运维人员为了尽快降低仓库使用率,违规对源仓库进行了数据回收。
改进措施:经过技术复盘,腾讯云技术团队深入到每个环节,通过责任到人与流程闭环的双管齐下,相应作出如下的加强和改进措施:
o首先,我们将全面审视所有的数据流程,涉及数据安全的流程自动化闭环,进一步提升我们常规运维自动化和流程化,降低人工干预。同时把全流程的数据安全校验作为系统的常开功能,不允许被关闭。
o其次,针对物理硬盘静默数据错误,在当前用户访问路径数据校验自愈的基础上,我们优化现有巡检机制,通过优先巡检主副本数据块、跳过近期用户访问过的正确数据块等方法,加速发现该类错误,进行数据修复。
总结一下,故障的原因是:操作人员手工关闭数据校验,并且删除了源库,当发现『静默错误』导致的损坏时悔之晚矣。
无论如何,现在的事故已经发生,我想整个实践给行业以警示,我们的客户已经在设置方案将云上的数据库同步备份回本地。
而腾讯的一条改进建议是:提升自动化运维,降低人工干预。这一方面说明了自动化运维的重要性,另一方面仍然要警惕自动化中的故障传播。
既然有这样一个机会让我们了解了『静默错误』,那么我们可以进一步来看一看,在Oracle数据库中的静默错误是如何处理的。
首先还是回顾一下在我上一篇文章中描述的:。
静默错误在英文中被称为:Silent Data Corruption,我们知道硬盘最核心的使命是正确的存入数据、正确的读出数据,在出错时及时抛出异常告警。磁盘出现异常的情形可能包括硬件错误、固件 BUG 或者软件 BUG、供电问题、介质损坏等,常规的这些问题都能够正常被捕获抛出异常,而最可怕的事情是,数据处理都是正常的,直到你使用的时候才发现数据是错误的、损坏的。这就是静默错误。
网上的一篇论文:Silent data corruption in SATA arrays: A solution - Josh Eddy August 2008 对静默错误进行了解释。这篇文章提到:
有些类型的存储错误在一些存储系统中完全未报告和未检测到。 它们会导致向应用程序提供损坏的数据,而不会发出警告,记录,错误消息或任何类型的通知。 虽然问题经常被识别为静默读取失败,但根本原因可能是写入失败,因此我们将此类错误称为“静默数据损坏”。这些错误很难检测和诊断,更糟糕的是 它们实际上在没有扩展数据完整性检测功能的系统中相当普遍。
在某些情况下,当写入硬盘时,应该写入一个位置的数据实际上最终写入另一个位置。 因为某些故障,磁盘不会将此识别为错误,并将返回成功代码。 结果,RAID系统未检测到“错误写入”,因为它仅在硬盘发出错误信号时才采取措施。
因此,不仅发生了未检测到的错误,而且还存在数据丢失。 在图2中,数据块C应该覆盖数据块A,而是覆盖数据块B.因此数据块B丢失,数据块A仍然包含错误的数据!
结果,数据被写入错误的位置; 一个区域有旧的,错误的数据; 另一个区域丢失了数据,RAID系统和HDD都未检测到此错误。 检索B或C的访问将导致返回不正确的数据而不发出任何警告。
撕裂写入
在其他情况下,只有一些应该一起写入的扇区最终会出现在磁盘上。 这称为“撕裂写入”,其导致包含部分原始数据和部分新数据的数据块。 一些新数据已丢失,一些读取将返回旧数据。 同样,硬盘不知道此错误并返回成功代码,因此RAID无法检测到它。访问检索B将返回部分不正确的数据,这是完全不可接受的。
上文提到的“撕裂写入”,如果在 Oracle 数据库中发生,那么就是分裂块,当然 Oracle 数据库会自动检测这种情况。
那么“静默损坏”发生的概率有多少呢?该文提供了一组数据:
...一项针对NetApp数据库中150万个硬盘驱动器的学术研究在32个月内发现,8.5%的SATA磁盘会产生静默损坏。 某些磁盘阵列运行后台进程,以验证数据和RAID奇偶校验是否匹配,并且可以捕获这些类型的错误。 然而,该研究还发现,后台验证过程中错过了13%的错误。
那些未被发现的错误,就会成为企业的灾难。
即便没有任何错误,数据也需要定期进行读取,以确保数据无误,在几年前,我遇到过一起案例,Oracle 数据库莫名的发生了一定批量的数据损坏,存储上没有任何错误,但是数据库端大量的分裂块,存储没有检测到错误,并且复制到灾备站点,最后导致了数据丢失。
如果存储上出现了静默错误,在Oracle数据库中会是什么样的表现?

毫无疑问,在Oracle中经常出现的『坏块』就是静默错误的受害者之一。几乎所有的资深DBA都经历过坏块问题,当坏块出现在索引时,通过重建往往就修复了,而一旦坏块出现在数据或者元数据上,修复过程可能就比较复杂,甚至需要通过备份介质恢复,影响业务运行,更有甚者,会出现数据丢失,无法恢复的情况。
而坏块出现的原因,很少能够被明确定位,除了极少数的存储介质物理故障,其他多数都是说不清楚原因的逻辑损坏,通常我们都期望这是一次偶然意外,期望以后不会发生,当然,的确这是一个小概率事件。
在 Google 上,能够找到一些与『静默错误』相关的文献,由于这里不能链接,我统一放在下载中,大家可以自行下载学习:
Carnegie Mellon University – Disk failures in the real world: What does an MTTF of 1,000,000 hours mean to you? (2007)
CERN – Data integrity study (2007)
University of Wisconsin-Madison & Network Appliance – An Analysis of Data Corruption in the Storage Stack(2008)
Google – Failure Trends in a Large Disk Drive Population (2007)
经过很多研究表明,『静默错误』真实存在,并且不仅仅是磁盘驱动器的原因,在某些情况下,电源电缆、HBA卡、有BUG的驱动程序或微码也会导致静默损坏。
在 Oracle 官网上有一篇 2013 年的文章:How to Prevent Silent Data Corruption,这篇文章的两位作者一个是 Oracle Enterprise Linux 的内核开发者,另外一位来自 Emulex - 光纤卡厂商。
文章这样描述静默损坏:
静默损坏是在没有警告的情况下发生,可以定义为由于组件故障或无意的管理操作而导致的非恶意数据丢失。读取或写入无效数据时并不提示I/O问题,最终导致数据损坏。 这种类型的损坏是迄今为止最具灾难性的,并且没有有效的方法来检测。
通常情况下,保证数据一致性的 ECC 和 CRC 技术可用于大多数服务器,存储阵列和HBA。 但是这些检查仅在单个组件内临时保护数据,无法确保写入的数据在从应用程序传输到HBA,交换机,存储阵列和物理磁盘驱动器的数据路径中不会损坏。 发生数据损坏时,大多数应用程序都不知道存储在磁盘上的数据不是要存储的数据。
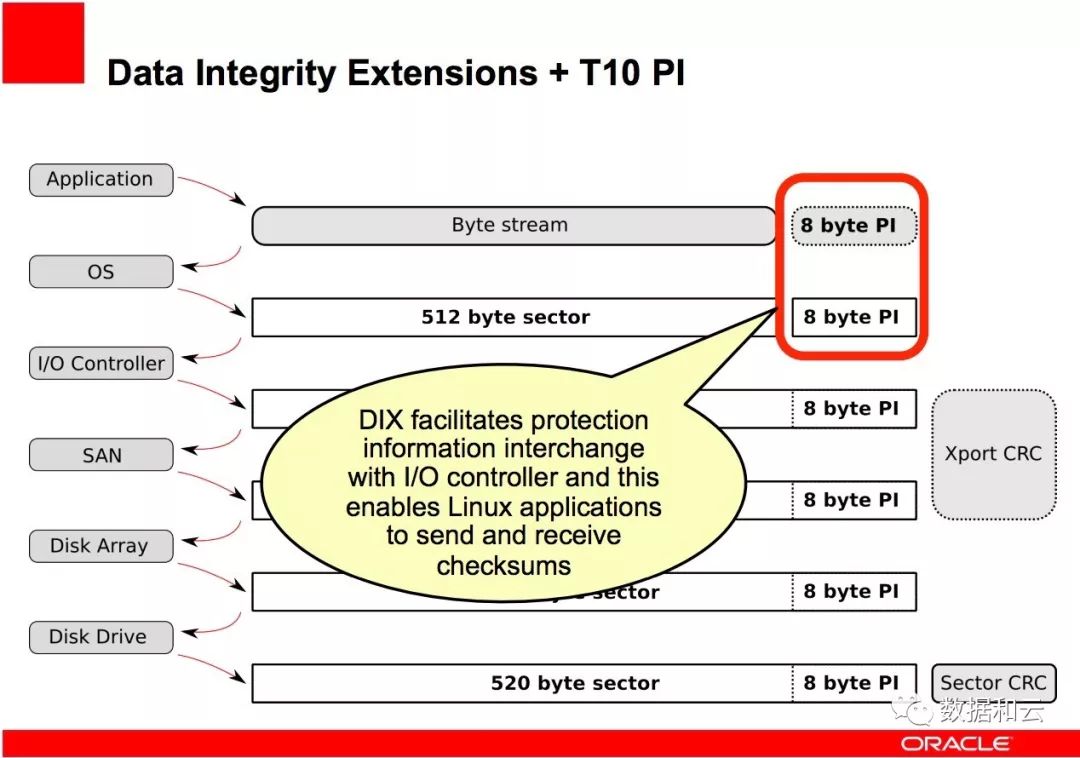
在过去几年中,EMC,Emulex和Oracle共同合作推动并实施了T10 SBC标准的附件信息保护功能,该功能可以在数据通过数据路径时对数据进行验证,以确保数据阻止静默损坏的发生。
最终目标是通过创建完整性元数据(也称为保护信息,与数据同时创建),然后在整个数据路径中验证元数据,并将错误回馈给应用程序进行修复,从而提供针对从应用程序到磁盘的静默数据损坏的保护。下图就是这个链路的保护过程:

写入数据时会发生以下步骤:
第一:Oracle自动存储管理库在写入内存时为每个512字节扇区添加保护信息。
第二:保护信息附加到 I / O请求,并通过Oracle Linux操作系统内核中的层传递给Emulex驱动程序。
第三:Emulex LightPulse Lpe16000B光纤通道HBA从内存缓冲区收集信息,验证数据完整性,合并数据和保护信息,然后根据T10 PI模型发送520字节扇区。
第四:EMC VMAX阵列固件验证保护信息并将数据写入磁盘。
第五:磁盘驱动器固件在将数据提交到物理介质之前验证保护信息。
读取数据时,步骤反向完成。
在2013年这篇文章提到,在基于 OEL 和 Emulex 的配置下,增强可以被启用以防范数据损失:
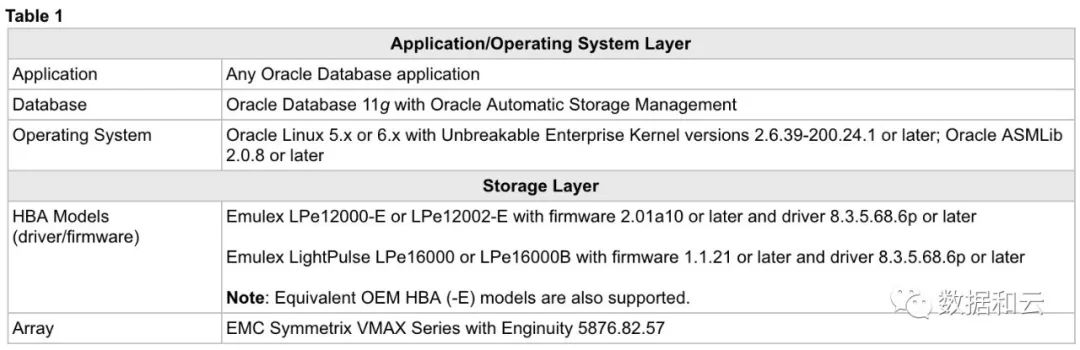
这是多方努力的结果,在 oracleasm-discover 中可以观察到相关信息:
# oracleasm-discover
Using ASMLib from /opt/oracle/extapi/64/asm/orcl/1/libasm.so
[ASM Library - Generic Linux, version 2.0.8 (KABI_V2)] Discovered
disk: ORCL:P00 [20971520 blocks (10737418240 bytes), maxio 512, integrity DIX1-512/512-IP] Discovered disk: ORCL:P01 [20971520 blocks
(10737418240 bytes),
maxio 512, integrity DIX1-512/512-IP] [...]
进一步的展开一下,看看Oracle的增强一致性检查实现。在复杂的数据流转过程中,每一个步骤都可能产生数据分歧:
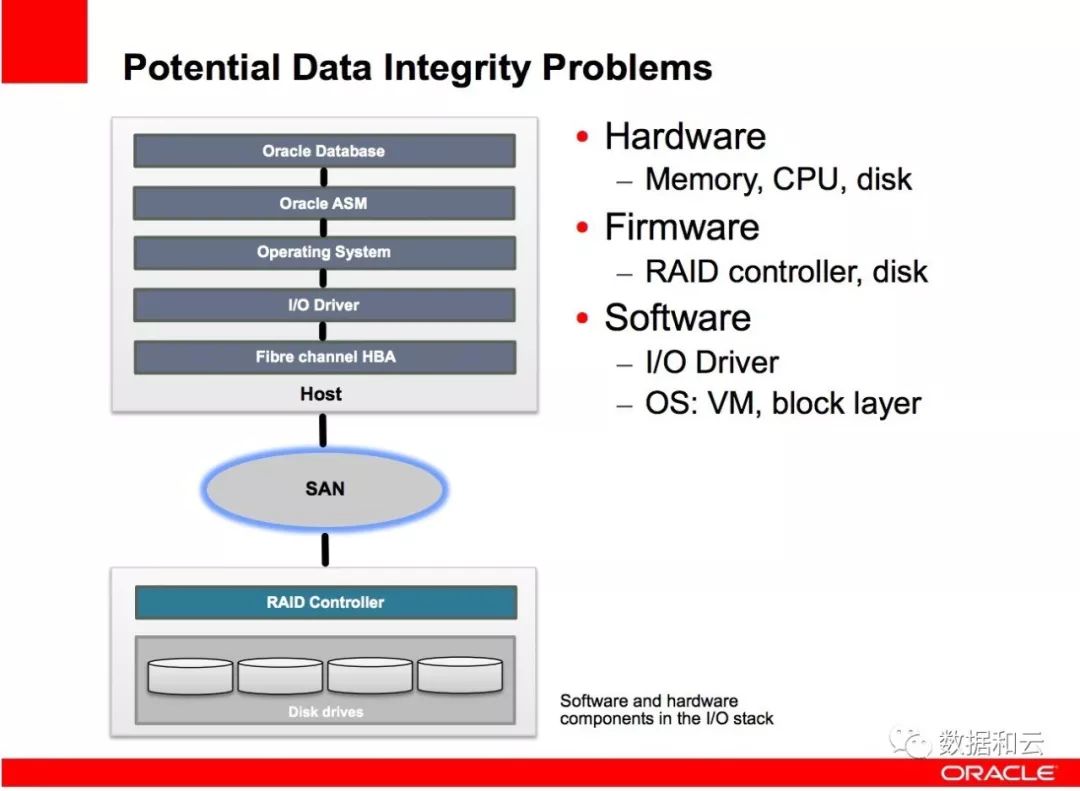
在典型的 I/O 处理栈中,最后在存储和驱动器层, 8 Byte 的 PI 校验位才被增加进去,而存储出现静默错误问题时,顶层是无法感知的。
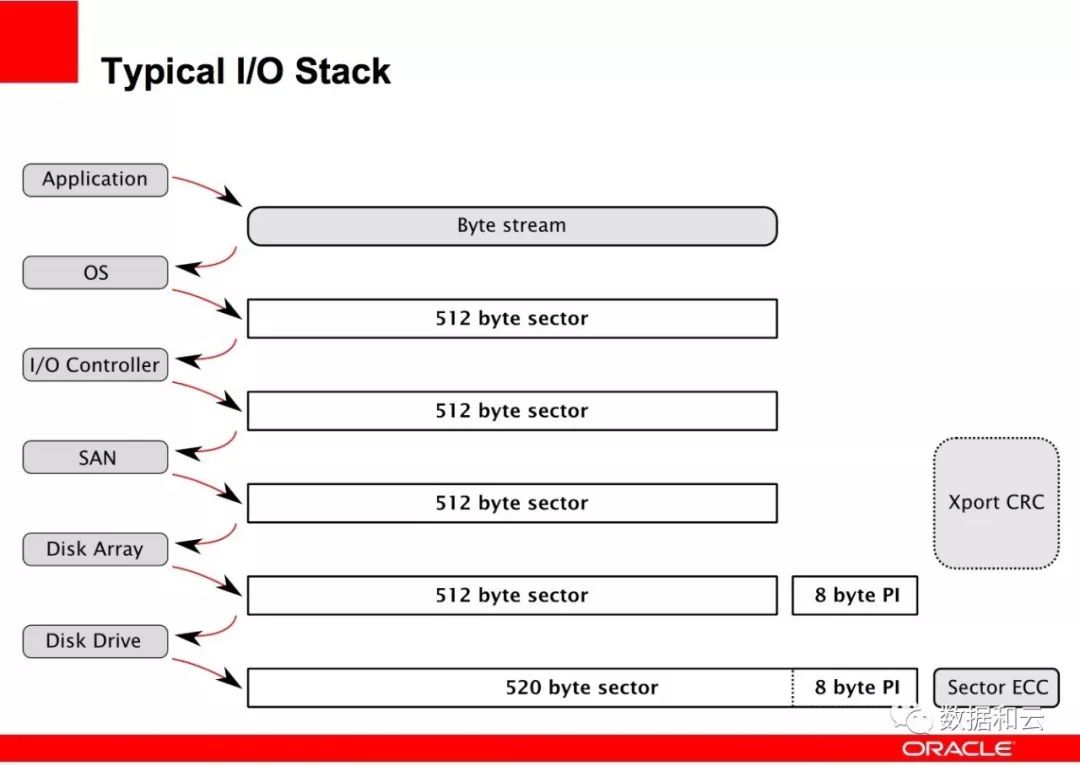
T10 的保护信息模型,就是增加额外 8 字节的校验位,从应用到HBA再到底层存储,层层校验保护:

在最高的 T10 PI 保护级别上,校验位从应用层就开始被添加,实现了端到端的校验:
在 Oracle 10g年代,Oracle 曾经推出 H.A.R.D. 计划,全程是 - Hardware Assisted Resilient Data ,被翻译为 硬件辅助弹性数据(HARD)计划,用于防止数据损坏。
在HARD 倡议下,Oracle与选定的系统和存储供应商合作,构建可以及早发现损坏并防止损坏的数据写入磁盘的操作系统和存储组件,并且此功能的实施对最终用户或DBA都是透明的。
要使用HARD验证,所有数据文件和日志文件都放在符合HARD标准的存储上,同时启用HARD验证功能。当Oracle将数据写入存储时,存储系统会验证数据。如果它看起来已损坏,则写入将被拒绝并显示错误。
HARD 的设计就是用于防范那些可能的静默错误,以下这些描述就是典型的问题:
写入损坏的块
数据由Oracle写入,并在到达磁盘之前被操作系统或硬件组件干预破坏。这些组件可能包括操作系统,文件系统,卷管理器,设备驱动程序,主机总线适配器和SAN交换结构。虽然Oracle可以在读取数据时检测到损坏,但Oracle可能会在几天或几个月后才读取数据。到那时,用于恢复数据的良好备份可能不再可用。
将块写入不正确的位置
Oracle向磁盘上的特定位置发出写入。不知何故,操作系统或存储系统将块写入错误的位置。这可能导致两个损坏:破坏磁盘上的有效数据并丢失已提交事务中的数据。
Oracle以外的程序对Oracle数据的错误写入
Oracle数据文件可能被非Oracle应用程序覆盖。非Oracle进程或程序可能会意外覆盖Oracle数据文件的内容。这可能是由于应用程序软件,操作系统中的错误或人为错误(例如,意外地将正常操作系统文件复制到Oracle数据文件上)。
损坏的第三方备份
将备份复制到磁带时可能会发生数据损坏。这种类型的损坏特别有害,因为备份用于修复数据损坏。因此,如果备份也已损坏,则无法恢复任何丢失的数据。对于第三方备份尤其如此(其中磁盘存储单元直接将数据复制到备份设备而不通过Oracle。)
可能的HARD检查
在实现Oracle HARD功能的存储系统中,Oracle服务器可以通过大量检查来验证Oracle块结构,块完整性和块位置。如果块在写入时未通过验证,则存储器拒绝写入,从而保护数据的完整性。在系统管理操作期间也可以选择性地禁用HARD验证检查,这可能会暂时使数据处于不一致状态。
关于这里描述的一种情形,让我想到在2010年我帮助用户进行恢复的一个案例,当时记录在博客上,原文:
http://www.eygle.com/archives/2010/11/recover_archivelog_corruption.html
引用一下,用现在的定义就应该属于『静默错误』的范畴:
最近在紧急故障处理时,帮助用户恢复数据库遇到了一则罕见的归档日志损坏案例,在这里和大家分享一下,看看是否有人遇到过类似的问题。
***
在进行归档recover时,数据库报错,提示归档日志损坏:
Corrupt block seq: 37288 blocknum=1.
Bad header found during deleting archived log
Data in bad block - seq:810559520. bno:170473264. time:707406346
beg:21280 cks:21061
calculated check value: 9226
Reread of seq=37288, blocknum=1, file=/ARCH/arch_1_37288_632509987.dbf, found same corrupt data
Reread of seq=37288, blocknum=1, file=/ARCH/arch_1_37288_632509987.dbf, found same corrupt data
Reread of seq=37288, blocknum=1, file=/ARCH/arch_1_37288_632509987.dbf, found same corrupt data
Reread of seq=37288, blocknum=1, file=/ARCH/arch_1_37288_632509987.dbf, found same corrupt data
Reread of seq=37288, blocknum=1, file=/ARCH/arch_1_37288_632509987.dbf, found same corrupt data
***
Dump file /ADMIN/bdump/erp_p007_19216.trc
信息比较详细,说37288号归档日志Header损坏,无法读取数据。
提一个小问题:如果你遇到了这样的错误?会怎样思考?
如果这个归档日志损坏了,其实我们仍然有办法跳过去,继续尝试恢复其他日志,但是客户数据重要,不能容忍不一致性,这时候就只能放弃部分数据,由前台重新提交数据了。这在业务上可以实现,也就不是大问题了。
好了,问题是为什么日志会损坏?是如何损坏的?
我首先要做的就是,看看日志文件的内容,通过最简单的命令将日志文件中的内容输出出来:
strings arch_1_37288_632509987.dbf > log.txt
然后检查生成的这个日志文件,我们就发现了问题。
在这个归档日志文件中,被写入了大量的跟踪文件内容,其中开头部分就是一个跟踪文件的全部信息。
这是一种我从来没有遇到过的现象,也就是说,当操作系统在写出跟踪文件时,错误的覆盖掉了已经存在的归档文件,最后导致归档日志损坏,非常奇妙,从所未见。
最后我的判断是,这个故障应当是操作系统在写出时出现了问题,存在文件的空间仍然被认为是可写的,这样就导致了写冲突,出现这类问题,应当立即检查硬件,看看是否是硬件问题导致了如此严重的异常(日志做了掩码脱敏)。
Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 - Production
With the Partitioning, OLAP and Data Mining options
ORACLE_HOME = /DBMS/erp/erpdb/10g
Linux
eygle.com
2.6.9-34.ELhugemem
#1 SMP Fri Feb 24 17:04:34 EST 2006
i686
Instance name: erp
Redo thread mounted by this instance: 1
Oracle process number: 22
Unix process pid: 19216, image: oracle@eygle.com (P007)
*** SERVICE NAME:() 2010-11-10 10:37:26.247
*** SESSION ID:(2184.1) 2010-11-10 10:37:26.247
*** 2010-11-10 10:37:26.247
KCRP: blocks claimed = 61, eliminated = 0
----- Recovery Hash Table Statistics ---------
Hash table buckets = 32768
Longest hash chain = 1
Average hash chain = 61/61 = 1.0
Max compares per lookup = 0
Avg compares per lookup = 0/61 = 0.0
----------------------------------------------
----- Recovery Hash Table Statistics ---------
Hash table buckets = 32768
Longest hash chain = 1
Average hash chain = 61/61 = 1.0
Max compares per lookup = 1
Avg compares per lookup = 1426/1426 = 1.0
----------------------------------------------
\GPAYMENTdxn
AP_CHECKS
Q(xn
.1=N
\Gxn
.1=N
^0e
^0e!
^0e"
^0e#
^0e$
^0e%
^0e&
^0e'
^0e(
^0e)
^0e*
^0e+
^0e+
^0e&
^ij1
R0:b
Q(xn
PaymentsN
a'VND
Userxn
AP_INVOICE_PAYMENTS
105273
5406105305-20101020-003
3001CASH CLEARING
CREATED
Dump file /ADMIN/bdump/erp_p002_19206.trc
Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 - Production
With the Partitioning, OLAP and Data Mining options
ORACLE_HOME = /DBMS/erp/erpdb/10g
Linux
eygle.com
2.6.9-34.ELhugemem
#1 SMP Fri Feb 24 17:04:34 EST 2006
i686
Instance name: erp
Redo thread mounted by this instance: 1
Oracle process number: 17
Unix process pid: 19206, image: oracle@eygle.com (P002)
*** SERVICE NAME:() 2010-11-10 10:37:26.263
*** SESSION ID:(2187.1) 2010-11-10 10:37:26.263
*** 2010-11-10 10:37:26.263
KCRP: blocks claimed = 84, eliminated = 0
----- Recovery Hash Table Statistics ---------
Hash table buckets = 32768
Longest hash chain = 1
Average hash chain = 84/84 = 1.0
Max compares per lookup = 0
Avg compares per lookup = 0/84 = 0.0
----------------------------------------------
----- Recovery Hash Table Statistics ---------
Hash table buckets = 32768
Longest hash chain = 1
Average hash chain = 84/84 = 1.0
Max compares per lookup = 1
Avg compares per lookup = 880/880 = 1.0
----------------------------------------------
^A&A
^1b#
^1b!
^1b"
^0e'
^Mj8
^;&3
2010PS_Legal Entity
^6&L
Eoi_VND
Quick Payment: ID=47708
如此少见的案例,在此与大家分享。
那么关于『静默错误』近年的进展有哪些呢?其实已经很少能够看到 Oracle 和存储厂商的进一步合作了,因为 Oracle 通过 ASM 技术的革新,通过针对 Linux 的增强,Oracle 逐步去强化和解决这些问题,尤其是在其自主的 Exadata 一体机中。
对于以上谈到的 『Oracle以外的程序对Oracle数据的错误写入』情形,在 Oracle 12c中,通过 ASM 实现的 ASM FD特性,Oracle 可以将外部写错完全隔绝。参考文章: 。
参考文献:
http://www.oracle.com/technetwork/articles/servers-storage-dev/silent-data-corruption-1911480.html
https://docs.oracle.com/cd/B12037_01/server.101/b10726/apphard.htm
https://bartsjerps.wordpress.com/2011/12/14/oracle-data-integrity/
招聘专栏
Oracle 售前工程师(广州、深圳、上海、武汉、北京、石家庄)
Oracle 高级工程师(上海、深圳、北京、成都、昆明、贵州、西宁)
mysql 技术经理(上海、南京、成都)
超高待遇:丰厚的年终奖,五险一金,高额学习基金,团建旅游,法定节假日,福利假期等。
推荐他人成功入职有好礼(iPhone X)相送 。
投递简历至邮箱:hr@enmotech.com
资源下载
2018DTCC , 数据库大会PPT
2017DTC,2017 DTC 大会 PPT
DBALIFE ,“DBA 的一天”海报
DBA04 ,DBA 手记4 电子书
122ARCH ,Oracle 12.2体系结构图
2017OOW ,Oracle OpenWorld 资料
PRELECTION ,大讲堂讲师课程资料
以上是关于静默错误:Oracle 数据库是如何应对和处理的 ?的主要内容,如果未能解决你的问题,请参考以下文章
oracle11g-R2静默安装报错[INS-32013]解决方案
静默“未知模块中发生‘System.ExecutionEngineException’类型的未处理异常”错误