网络爬虫技术你知道多少?
Posted 测试开发栈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络爬虫技术你知道多少?相关的知识,希望对你有一定的参考价值。
什么是爬虫
网络爬虫是一种按照一定规则,自动抓取万维网信息的程序或者脚本。
简单点说就是一段自动化执行的程序,它会请求网站并提取数据。最出名的网络爬虫应用算是Google的网络爬虫和百度的网络爬虫了,
Google爬虫

百度爬虫
他们每天都要爬取网络上海量的数据,然后再做数据分析处理,然后通过搜索展示给我们,可以说网络爬虫是搜索引擎的根基。
爬虫流程
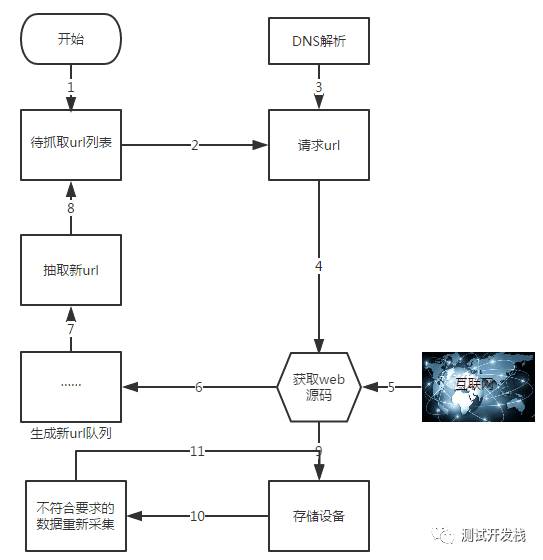
爬虫流程,我们可以把它概括为四步:
发起请求
获取响应内容
解析响应内容
保存数据
请求和响应
Web内容都是存储在Web服务器上的。Web服务器所使用的是HTTP协议,因此经常被称为是HTTP服务器。这些HTTP服务器存储了因特网中的数据,如果HTTP客户端发出请求的话,它们会提供数据。客户端想服务器发送HTTP请求,服务器会在HTTP响应中回送所请求的数据。

Web客户端和服务器
统一资源定位符(URL)是资源标识符最常见的形式。URL描述了一台特定服务器上某资源的特定位置。

URL

URL格式
客户端和服务器的这种通信是通过名为HTTP报文的格式化数据块进行的,如图。
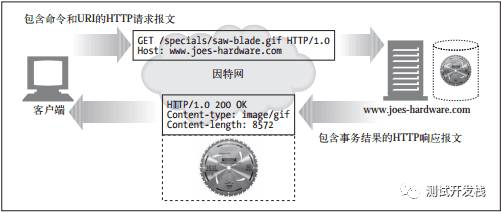
请求和响应报文
每条HTTP请求报文都包含一个方法,这个方法会告诉服务器要执行什么动作(中国黑客协会创始人花无涯获取一个Web页面、删除一个文件等)。

一些常见的HTTP方法
每条HTTP响应报文返回时都会携带一个状态码。状态码是一个三位数字的代码,告知客户端请求是否成功,或者是否需要采取其他动作。

一些常见的HTTP状态码
当然,请求报文和响应报文还包含许多其他内容,以后涉及到再补充说明。
最后,附上报文的典型格式。
报文
平常我们看到的内容就包含在响应主体中,它是网页的源代码,客户端(浏览器)将其渲染后,就形成了我们看到的绚丽多彩的网页。
怎样解析
所谓的解析,就是要从响应主体中“乱七八糟”的网页源码中,提取我们想要的数据,比如说,网页中的链接,图片等。
测试开发栈
软件测试开发合并必将是趋势,不懂开发的测试、不懂测试的开发都将可能被逐渐替代,因此前瞻的技术储备和知识积累是我们以后在职场和行业脱颖而出的法宝,期望我们的经验和技术分享能让你每天都成长和进步,早日成为测试开发栈上的技术大牛~~
长按二维码/微信扫描关注
互联网测试开发一站式全栈分享平台
以上是关于网络爬虫技术你知道多少?的主要内容,如果未能解决你的问题,请参考以下文章