网络爬虫以及反爬虫技术介绍
Posted 光说产品
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络爬虫以及反爬虫技术介绍相关的知识,希望对你有一定的参考价值。
托了搜索引擎的福,我们现在大多数的信息和数据,可以通过搜索引擎高效的检索到,那么搜索引擎又是怎么知道这些数据在哪里的呢?答案就是网络爬虫。
网络爬虫
网络爬虫,就是程序模拟的网络机器人,他可以模拟人的行为,在网络上按照你的设定规则进行访问或者数据交互。
网络爬虫(Web crawler),就是通过网址获得网络中的数据、然后根据目标解析数据、存储目标信息。这个过程可以自动化程序实现,行为类似一个蜘蛛。蜘蛛在互联网上爬行,一个一个网页就是蜘蛛网。这样蜘蛛可以通过一个网页爬行到另外一个网页。
搜索引擎是最早诞生的爬虫,它爬取互联网上的所有信息,帮助用户进行快速的信息检索,为用户提升效率的同时也为网站带来流量。
网络爬虫在干哪些事?
1,信息搜集
2,刷量
3,秒杀资源
爬虫最初是为搜索业务服务的。早期的搜索引擎,就是一个自动化程序,可以抓取网上的所有网页,然后将所有页面上的内容复制到数据库中制作索引,然后对外提供数据检索业务。
让爬虫去检索全部互联网的数据,这个就是搜索引擎。
让爬虫去检索某企业相关的网络信息,这个就是舆情监控。
让爬虫去搜集某一类特定的信息,这个就是现在的大数据。
让爬虫去检索购物网站商品的价格信息,这个就是现在的币价软件。
互联网一个重要经济来源就是广告,既然广告是按照点击来计费的,那么是否可以用爬虫模拟一次点击,来骗取广告费呢?从技术的角度来说,这个当然可以。
于是网络上各种刷就出现了,从一开始简单的刷广告流量,到刷点击量,刷好评,毫不夸张的说,任何网络上人可以通过重复操作来进行的事情,都可以通过爬虫模拟的方式进行刷量。各种刷好评现在大家已经是心知肚明,各种点击量粉丝量各方也是各打折扣,现在连亚马逊的好评也开始大规模刷了。刷量,已经是司空见惯的一种运营操作了。
既然能刷量,那么能不能顺手再做一步,比如抢红包呢?答案是当然能!
于是各种社交平台抢红包,网络抢票,阿里抢月饼,等等通过爬虫来进行互联网秒杀资源的产品就出现了。知乎史中介绍了一个刷机票的案例:
亚洲航空。这是一家马来西亚的廉价航空公司,航线基本都是从中国各地飞往东南亚的旅游胜地,飞机上连矿泉水都得自费买,是屌丝穷X度假之首选。为什么爬虫这么青睐亚航呢?因为它便宜。确切地说,因为它经常放出便宜的票。本来,亚航的初衷只是随机放出一些便宜的票来吸引游客,但这里面黄牛党是有利可图的。据我所知,他们是这样玩的:技术宅黄牛党们利用爬虫,不断刷新亚航的票务接口,一旦出现便宜的票,不管三七二十一先拍下来再说。亚航有规定,你拍下来半小时(具体时间记不清了)不付款票就自动回到票池,继续卖。但是黄牛党们在爬虫脚本里写好了精确的时间,到了半小时,一毫秒都不多,他又把票拍下来,如此循环。直到有人从黄牛党这里定了这个票,黄牛党就接着利用程序,在亚航系统里放弃这张票,然后0.00001秒之后,就帮你用你的名字预定了这张票。“我是中间商,我就要赚差价!”这波骚操作,堪称完美。
你说既然网络上这么多爬虫在干各种各样的活,那么爬虫在互联网的流量得占一半吧?
不,你的想法一点都不大胆!
35个不同类型的爬虫程序(优质爬虫程序)构成了绝大多数的爬虫流量。它们可以分为四大类:搜索引擎爬虫,商业爬虫,内容获取者爬虫和监控爬虫。这些爬虫覆盖了超过互联网84%的爬虫流量。
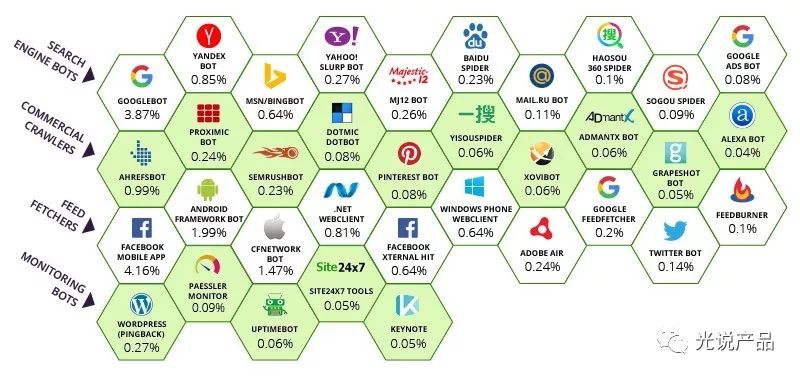
据国际知名金融广告服务平台提供商Dianomi的报告《2018 Robot traffic report》的数据,在互联网上人类流量仅仅占了48.2%,也就是说,一个页面的10000个点击里面,大约5100个来自机器人。在航旅票务等行业,热门数据接口中甚至有超过95% 的流量是来自机器人。
想象一下,你所购买的服务器和带宽,其实,大多数的资源是为了另外一些机器来服务的。流量的现状如此。下图是知乎史中提供的一个数据,现在春节抢票期间,你大概能够理解为什么你抢不到的火车票,黄牛手里为什么有了吧。人的手速,怎么可能硬刚的过机器呢。
反爬虫
反爬虫,就是识别和过滤和阻止爬虫。
如果你希望你的信息迅速传播,没有什么壁垒,那么可以让所有的爬虫来你这里尽情玩耍。但是如果你只希望真正的人来访问你,那你就需要进行反爬虫了。
爬虫就是机器模拟人的访问,反爬虫就是在这些访问里边识别机器。随着爬虫技术的进步,反爬虫的技术也随着在需要不断更新进步。这里我们也简单介绍几种常用的方式。
1,君子协定:Robots协议
搜索引擎的爬虫都遵守着一个协议:robots.txt,它是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的爬虫,此网站中的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。robots.txt放置于网站的根目录下。robots.txt协议并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私。
使用Robots协议可以过滤掉遵守君子协定的爬虫的访问。
2,各类验证码类型的人机识别技术
你在访问网站的时候总会遇到各种各样的验证码,例如图片数字,滑动,图片识别,等等,这些验证码的步奏,就是为了区别你的这个访问是真人,还是机器,毕竟真人做这个操作很简单,但是对于机器操作就比较难了。
12306有段时间采用的选择图片的方式,就是一种人机识别的策略:
随着人工智能技术的出现,机器识别图片的能力已经超出了人类,上图中,机器识别白百合的成功率比大多数人还要高。所以,现在大家都较少的采用图片的方式进行反爬虫了,因为这个防护还是太弱了。
4,访问请求识别类技术
访问请求过来的HAED头,其中包含了大量的用户标记数据,爬虫如果粗糙一点的话,这些字段设置通常都是默认值或者是一个机器值,通过过滤这些值可以滤掉一部分无效请求。
5,访问行为识别类技术
人的访问过程会有一个比较清晰的逻辑路径,机器的访问路径是按照遍历或者递归的方式来的,通过对这个用户的访问行为进行分析,也能够识别和判断一部分的爬虫访问。
6,前端页面技术
通过JS等一些前端页面技术,让爬虫无法直接识别到页面的有效信息。
反爬技术也在不断的进步和成长,爬虫技术也在反爬技术的成长过程中不断的更新迭代。有一篇反爬的文章不错:论爬虫持久战:https://www.freebuf.com/articles/database/221679.html,可以看一下。
所谓道高一尺魔高一丈,爬虫与反爬虫,在相互竞争中互相成长,创造了大量的互联网劳动岗位,也拖死了不少创业公司。
冤冤相报不好了,互联网的丛林社会,进攻之前一定要先扎好篱笆。
参考链接
以上是关于网络爬虫以及反爬虫技术介绍的主要内容,如果未能解决你的问题,请参考以下文章