收藏爬虫技术,由浅入深,周末了解一下~
Posted JAVA和人工智能
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了收藏爬虫技术,由浅入深,周末了解一下~相关的知识,希望对你有一定的参考价值。
爬虫技术,剖你一下^^


有人说,女程序员再淑女,一旦编程就会暴露自己的身份,习惯性的把前额的头发往上捋,露出大大的额头。因为……CPU高速运作时需要散热!散热!散热!!!
——小竹笋《JAVA和人工智能》
现在的互联网来说,包含着各种海量的信息,无孔不入,包罗万象。出于数据分析或产品需求,我们需要从某些网站,提取出我们感兴趣、有价值的内容,我们需要一种能自动获取网页内容并可以按照指定规则提取相应内容的程序,这就是爬虫。
让我们说的稍微好听一点,网络爬虫就是按照一定的规则,自动地抓取万维网信息的程序或者脚本,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。
URI(Universal Resource Identifier):Web当中的每个可用资源,如html文档,图像视频,程序等,都有一个唯一的统一标识符进行定位。
URI组成:
访问资源的命名机制
存放资源的主机名
资源自身名称,通常由路由表示
URL组成:
协议(服务方式)
在网络爬虫的系统框架中,主过程由控制器、解析器、资源库三部分组成。控制器的主要工作负责给多线程中的各个爬虫线程分配工作任务。解析器的主要工作是下载网页,进行网页处理,主要将一些Js脚本标签、css代码内容、空格字符,HTML标签等内容处理掉,爬虫的基本工作是由解析器完成。资源库,是用来存放下载到的文件资源,一般都用大型的数据库存储。如:ORACLE数据库,对其建立索引。
Web网络爬虫系统一般会选择一些比较重要的、出度较大的网站的URL作为种子URL集合。网络爬虫系统以这种 种子集合作为初始URL,开始数据的抓取。因为网页中含有链接信息,通过已有的网页URL会得到一些新的URL,可以把网页之间的指向结构试做为一个森林,每个种子URL对应的网页是森林中的一棵树的根节点。这样Web网络爬虫系统就可以根据广度优先算法或者深度优先算法遍历所有的网页。由于深度优先算法可能会使爬虫系统陷入一个网站内部,不利于搜索比较靠近网站首页的网页信息,因此,一般采用广度优先搜索算法采集网页。
Web网络爬虫系统首先将种子URL放入下载队列,然后简单地从队首取出一个URL下载其对应的网页。得到网页的内容将其存储后,再经过解析网页中的链接信息可以得到一些新的URL,将这些URL加入下载队列。然后再取出一个URL,对其对应的网页进行下载,然后再解析,如此反复进行,直到遍历了整个网络或者满足某种条件后才会停止下来。
工作流程
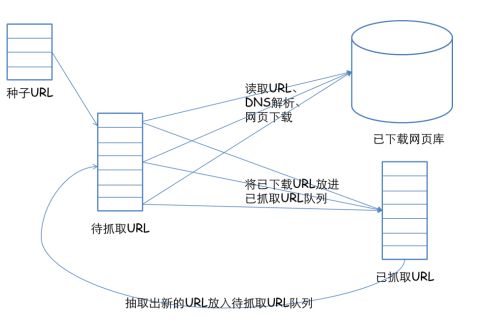
5.1 选取一部分精心挑选的种子。
5.2 将这些URL放入待抓取URL队列。
5.3 从待抓取URL中选出待抓取URL,解析DNS,并得到主机的IP,并将URL对应的网页下载下来,存取进已下载的网页库中,此外,将这些URL放进已抓取URL队列。
5.4 分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
遍历策略
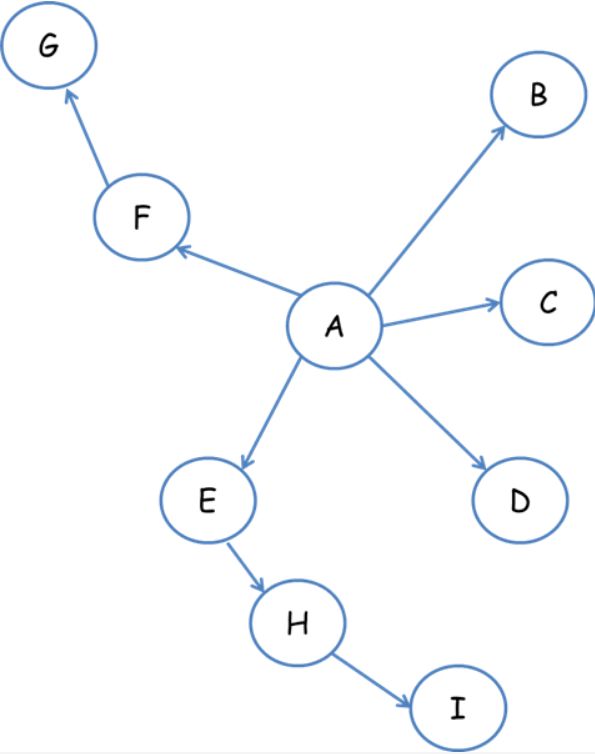
6.1 深度优先遍历策略
网络爬虫会从起始叶开始,一个链接一个链接跟踪下去,处理完这条路线之后,再转入下一个起始页。继续~
遍历顺序 A-F-G E-H-I B C D
6.2 宽度优先遍历
将新下载网页中发现的链接直接插入待抓取的URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取此网页中链接的所有网页。
遍历顺序 A-B-C-D-E-F G H I
当然在这里除了这两种还有一些其他的遍历方式,比如反向链接数策略、Partial PageRank策略、OPIC策略策略、大站优先策略等等。
7.1 Apache Nutch分布式爬虫
7.2 Java爬虫:Crawler4j、WebMagic、WebController
7.3 python爬虫:scrapy
Apache Nutch分布式爬虫
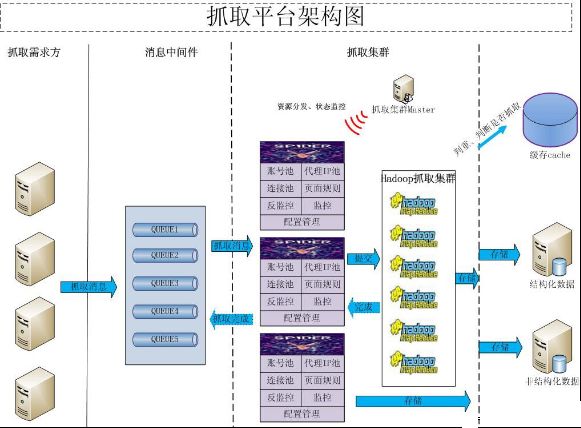
(1)大多数用户是需要一个做精准数据爬取(精抽取)的爬虫,Nutch运行的一套流程里,有三分之二是为了搜索引擎而设计的。说实在的,利用Nutch进行爬虫会浪费许多时间在不必要的计算上。
(2)Nutch 以来Hadoop运行,Hadoop本身需要很多时间。
(3)Nutch 有一套插件机制,提供精抽取功能。但是利用反射机制来加载和调用插件,使得程序的编写和调试都变的异常困难。
(4)Nutch2的版本目前并不适合开发。
总结:1,如果你不是要做搜索引擎,尽量不要选择Nutch作为爬虫,
2,如果你是要做搜索引擎,Nutch1.x是一个非常好的选择。Nutch1.x和solr或者es配合,就可以构成一套非常强大的搜索引擎了。
Java爬虫
Java单独拿出来是因为在Java中网络爬虫的生态圈是非常完善的。相关的资料也是比较完备。
开源网络爬虫(框架)难问题和复杂的问题已经得到了解决,比如DOM树解析和定位、字符集检测、海量URL去重。
爬js生成的信息:使用这些爬虫来遍历网站,遇到需要解析的页面,就将网页的相关信息提交给模拟浏览器,来完成JS生成信息的抽取。
爬取ajax信息:将生成的ajax请求作为种子,放入爬虫。用爬虫对这些种子,进行深度为1的广度遍历(默认就是广度遍历)。
爬取要登陆的网站:开源爬虫都支持在爬取时指定cookies,模拟登陆主要是靠cookies
抽取网页的信息:CSS SELECTOR和XPATH
保存网页的信息:有一些爬虫,自带一个模块负责持久化。比如webmagic,有一个模块叫pipeline。通过简单地配置,可以将爬虫抽取到的信息,持久化到文件、数据库等。还有一些爬虫,并没有直接给用户提供数据持久化的模块。比如crawler4j和webcollector。让用户自己在网页处理模块中添加提交数据库的操作。至于使用pipeline这种模块好不好,就和操作数据库使用ORM好不好这个问题类似,取决于你的业务。
python爬虫
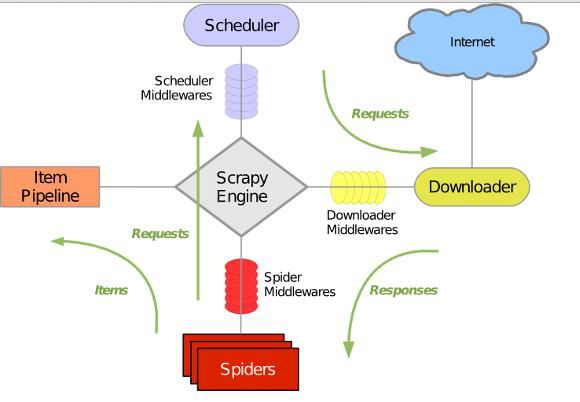
python爬虫,python可以用30行代码,完成JAVA 50行代码干的任务。让我们来看看它的框架流程图。
Scrapy的架构图,绿线是数据流向。
(1)从初始的URL,Scheduler 会将其交给 Downloader 进行下载
(2)下载之后会交给 Spider 进行分析。
(3)需要保存的数据则会被送到Item Pipeline,对数据进行后期处理
数据流动通道内需要安装各种中间件,进行必要处理。在进行爬虫的时候,首先先处理好模块,就比如:下载模块,爬行模块,调度模块,数据存储模块等等。
一般网站从三个方面进行反爬虫。用户请求的Headers,用户行为,网站目录和数据加载方式。第三种一些应用ajax的网站会采用,这样增大了爬取的难度。
8.1 用户请求的Headers
很多网站都会对Headers的User-Agent进行检测,还有一部分网站会对Referer进行检测。
解决反爬虫:
其解决反爬虫的解决方式,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或者添加Headers就能很好的绕过。
8.2 ,用户行为
(1)检测 同一IP短时间内多次访问同一页面。
(2)检测 同一账户短时间内多次进行相同操作。
解决反爬虫:
(1)前一种情况,对于这种情况,使用IP代理就可以解决。可以专门写一个爬虫,爬取网上公开的代理ip,检测后全部保存起来。这样的代理ip爬虫经常会用到,最好自己准备一个。有了大量代理ip后可以每请求几次更换一个ip,这在requests或者urllib2中很容易做到,这样就能很容易的绕过第一种反爬虫。
(2)可以在每次请求后随机间隔几秒再进行下一次请求。有些有逻辑漏洞的网站,可以通过请求几次,退出登录,重新登录,继续请求来绕过同一账号短时间内不能多次进行相同请求的限制
8.3 动态页面的反爬虫
用这套框架几乎能绕过大多数的反爬虫,因为它不是在伪装成浏览器来获取数据。除了加密ajax参数,它还把一些基本的功能都封装了,全部都是在调用自己的接口,而接口参数都是加密的。
解决反爬虫:
对于未加密的网站,接利用requests或者urllib2模拟ajax请求,对响应的json进行分析得到需要的数据,直接模拟ajax请求获取数据。
对于加密网站 可以用selenium+phantomJS框架,调用浏览器内核,并利用phantomJS执行js来模拟人为操作以及触发页面中的js脚本。从填写表单到点击按钮再到滚动页面,全部都可以模拟,不考虑具体的请求和响应过程,只是完完整整的把人浏览页面获取数据的过程模拟一遍。
超级链接回顾:
以上是关于收藏爬虫技术,由浅入深,周末了解一下~的主要内容,如果未能解决你的问题,请参考以下文章
K哥爬虫普法你很会写爬虫吗?10秒抢票10秒入狱,了解一下?
《爬虫100例专栏》复盘更新,再捋一遍这100篇文章,更新1,2,3,4 篇(收藏再看)