《爬虫100例专栏》复盘更新,再捋一遍这100篇文章,更新1,2,3,4 篇(收藏再看)
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《爬虫100例专栏》复盘更新,再捋一遍这100篇文章,更新1,2,3,4 篇(收藏再看)相关的知识,希望对你有一定的参考价值。
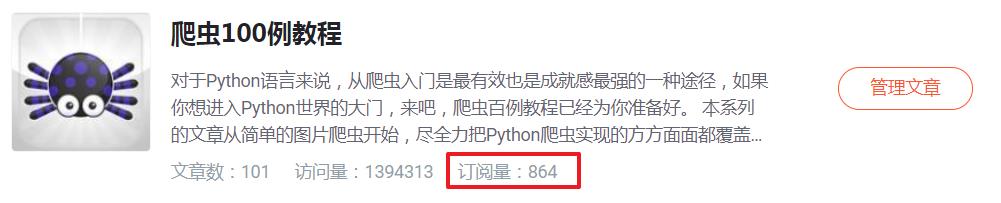
Python 爬虫 100 例专栏,即将售卖出 900 份啦,作为一个良心博主,我们把这 100 例在复盘一下吧。
爬虫技术,是一个时效性极强的技术体系,也是技术体系中非常有名的一门杂学,因为它需要:
- 你比前端工程师略懂一点点前端知识;
- 你比后端工程师略懂一点点数据库知识;
- 你比网络工程师略懂一点点网络协议;
- 最好你会安卓和 ios 开发;
- 数据分析与数据挖掘要了解;
- 加密解密要懂一点点吧;
- 调度算法要懂一点点吧;
- 为了识别验证码,要求会一点点机器学习不过分吧;
- 上面都会了,分布式的架构和使用,网络底层协议,网络安全攻防是不是也应该掌握呢?
- ……
如你所愿,这是爬虫的体系。Python 爬虫 100 例专栏,只是给你打开爬虫世界的一扇门,给你发了一个邀请函,能进到这个世界,才能知道这个世界的美丽。
复盘爬虫 100 例
在 100 例中采集的目标站点,随着时间的推移,有的网站消失了,有的更新了,有的增加了反爬,有的给橡皮擦发了律师函,是时候整体复盘一下啦。
我们将通过 15~20 篇博客,将《爬虫 100 例》整体梳理一遍,确定每一篇文章的可行性,如果网站消失,也会给大家补充一个替代网站,同时将梳理所有代码到 CSDN 的代码托管平台中。
补更博客之后,《爬虫 100 例》专栏将进行最后一次调价,即到达本专栏的终点价格 49.9 元,抓紧订阅喽。
更新过程中,我会将大家的评论全部都回复一遍,如果有特殊性问题,将一一进行补充。
案例一:在 CentOS 中安装 Python 环境
这个没啥好说的了,毕竟如果给我一次重写的机会,我一定在 windows 中安装,不过大家可以忽略,就当知识扩展了,毕竟后文都是在 Windows 上进行的代码编写。
案例二:命运多喘的一个案例了
这个案例被下架了不下 10 次,因为涉及的网站被和谐掉了,导致现在案例 2 的名称是 爬取 X 图网,更难的是其它平台也把这个 X 图网给屏蔽了,不知道这个网站闯了多大的祸。
这个不得不更新一下啦,在原案例中,咱使用的是 CentOS 系统,更新案例就不用了,直接切换到 Windows 即可。
原案例其实是一个与漂亮女生有关的网站,那我们在保留核心技术不变的情况下,就把它换成装修效果图爬取吧。
目标网站切换为如下网站:https://home.fang.com/album/s24/,这美丽的装修图指定不会被和谐掉。

由于是复盘类文章,技术的线性学习还是要依据原文,复盘文只做对比更新(有可能会全部更新)
本网站的页面规则如下,与原网站基本一致。
https://home.fang.com/album/s24/1/
https://home.fang.com/album/s24/2/
https://home.fang.com/album/s24/3/
第一步用生成了待抓取地址,重点逻辑查看注释即可。
import requests
all_urls = [] # 我们拼接好的图片集和列表路径
class Spider():
# 构造函数,初始化数据使用
def __init__(self, target_url, headers):
self.target_url = target_url
self.headers = headers
# 获取所有的想要抓取的 URL
def getUrls(self, start_page, page_num):
global all_urls
# 循环得到URL
for i in range(start_page, page_num+1):
url = self.target_url % i
all_urls.append(url)
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0',
'HOST': 'home.fang.com'
}
target_url = 'https://home.fang.com/album/s24/%d/' # 图片集和列表规则
spider = Spider(target_url, headers)
# 先测试 10 页数据
spider.getUrls(1, 10)
print(all_urls)
第二步进行数据提取,在原案例中使用了多线程,还使用了生产者和观察者模式,现在想想,好像调调一上来就起的太高了,不知道有多少同学在这里上来就翻车了。
新案例的目标网站,禁止鼠标右键查看源码,你可以通过直接点击 F12 唤醒开发者工具即可。
由于页面已经修改,顾正则表达式提取逻辑需要调整。
修改 Producer 类中的正则表达式
all_pic_link = re.findall('<a href="(.*?)" title=".*?" target="_blank">',response.text,re.S)
再次修改之后的如下所示,果然有一定的学习量,重点逻辑都在注释中进行了体现。
import requests
import threading # 多线程模块
import re # 正则表达式模块
import time # 时间模块
# 图片列表页面的数组
all_img_urls = []
# 初始化一个锁
g_lock = threading.Lock()
# 我们拼接好的图片集和列表路径
all_urls = []
class Spider():
# 构造函数,初始化数据使用
def __init__(self, target_url, headers):
self.target_url = target_url
self.headers = headers
# 获取所有的想要抓取的 URL
def getUrls(self, start_page, page_num):
global all_urls
# 循环得到URL
for i in range(start_page, page_num+1):
url = self.target_url % i
all_urls.append(url)
# 生产者,负责从每个页面提取图片列表链接
class Producer(threading.Thread):
def run(self):
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0',
'HOST': 'home.fang.com'
}
global all_urls
while len(all_urls) > 0:
# 在访问all_urls的时候,需要使用锁机制
g_lock.acquire()
# 通过pop方法移除最后一个元素,并且返回该值
page_url = all_urls.pop()
# 使用完成之后及时把锁给释放,方便其他线程使用
g_lock.release()
try:
print("分析"+page_url)
response = requests.get(page_url, headers=headers, timeout=3)
# 提取详情页地址的正则表达式,需要重新编写
all_pic_link = re.findall(
'<a href="(.*?)" title=".*?" target="_blank">', response.text)
global all_img_urls
# 这里还有一个锁
g_lock.acquire()
# 这个地方注意数组的拼接,没有用 append 直接用的+=也算是 python 的一个新语法
all_img_urls += all_pic_link
print(all_img_urls)
# 释放锁
g_lock.release()
time.sleep(0.5)
except:
pass
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0',
'HOST': 'home.fang.com'
}
target_url = 'https://home.fang.com/album/s24/%d/' # 图片集和列表规则
spider = Spider(target_url, headers)
# 先测试 10 页数据
spider.getUrls(1, 10)
# print(all_urls)
for x in range(2):
t = Producer()
t.start()
接下来就是补充消费者逻辑了,这部分代码重点也是修改了正则表达式部分。
import requests
import threading # 多线程模块
import re # 正则表达式模块
import time # 时间模块
import os # 目录操作模块
# 图片列表页面的数组
all_img_urls = []
# 初始化一个锁
g_lock = threading.Lock()
# 我们拼接好的图片集和列表路径
all_urls = []
# 图片地址列表
pic_links = []
class Spider():
# 构造函数,初始化数据使用
def __init__(self, target_url, headers):
self.target_url = target_url
self.headers = headers
# 获取所有的想要抓取的 URL
def getUrls(self, start_page, page_num):
global all_urls
# 循环得到URL
for i in range(start_page, page_num+1):
url = self.target_url % i
all_urls.append(url)
# 生产者,负责从每个页面提取图片列表链接
class Producer(threading.Thread):
def run(self):
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0',
'HOST': 'home.fang.com'
}
global all_urls
while len(all_urls) > 0:
# 在访问all_urls的时候,需要使用锁机制
g_lock.acquire()
# 通过pop方法移除最后一个元素,并且返回该值
page_url = all_urls.pop()
# 使用完成之后及时把锁给释放,方便其他线程使用
g_lock.release()
try:
print("分析"+page_url)
response = requests.get(page_url, headers=headers, timeout=3)
# 提取详情页地址的正则表达式,需要重新编写
all_pic_link = re.findall(
'<a href="(.*?)" title=".*?" target="_blank">', response.text)
global all_img_urls
# 这里还有一个锁
g_lock.acquire()
# 这个地方注意数组的拼接,没有用 append 直接用的+=也算是 python 的一个新语法
# 这里还需要将图片地址拼接完整
all_img_urls += [
f"https://home.fang.com{link}" for link in all_pic_link]
# print(all_img_urls)
# 释放锁
g_lock.release()
time.sleep(0.5)
except:
pass
# 消费者
class Consumer(threading.Thread):
def run(self):
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0',
'HOST': 'home.fang.com'
}
global all_img_urls # 调用全局的图片详情页面的数组
print("%s is running " % threading.current_thread)
# print(len(all_img_urls))
while len(all_img_urls) > 0:
g_lock.acquire()
img_url = all_img_urls.pop()
g_lock.release()
try:
response = requests.get(img_url, headers=headers)
# 设置案例编码
response.encoding = 'utf-8'
title = re.search('<title>(.*?)-房天下家居装修网</title>', response.text).group(1)
all_pic_src = re.findall('<img src[2]?="(.*?)" οnerrοr=".*?"/>', response.text)
pic_dict = {title: all_pic_src} # python字典
global pic_links
g_lock.acquire()
pic_links.append(pic_dict) # 字典数组
print(title+" 获取成功")
g_lock.release()
except Exception as e:
print(e)
time.sleep(0.5)
if __name__ == "__main__":
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0',
'HOST': 'home.fang.com'
}
# 图片集和列表规则
target_url = 'https://home.fang.com/album/s24/%d/'
spider = Spider(target_url, headers)
# 先测试 5 页数据
spider.getUrls(1, 5)
# print(all_urls)
threads = []
# 开启两个线程去访问
for x in range(2):
t = Producer()
t.start()
threads.append(t)
for tt in threads:
tt.join()
print("进行到我这里了")
# 开启10个线程去获取链接
for x in range(10):
ta = Consumer()
ta.start()
除了正则表达式修改以外,在 main 中代码涉及了多线程的执行顺序问题,可重点学习一下。
接下来补齐图片下载部分逻辑,案例 2 复盘完成,核心代码未进行任何变更,篇幅原因,完整代码提交到 https://codechina.csdn.net/hihell/scrapy,clone 案例 2 即可,最终得到大量装修美图。
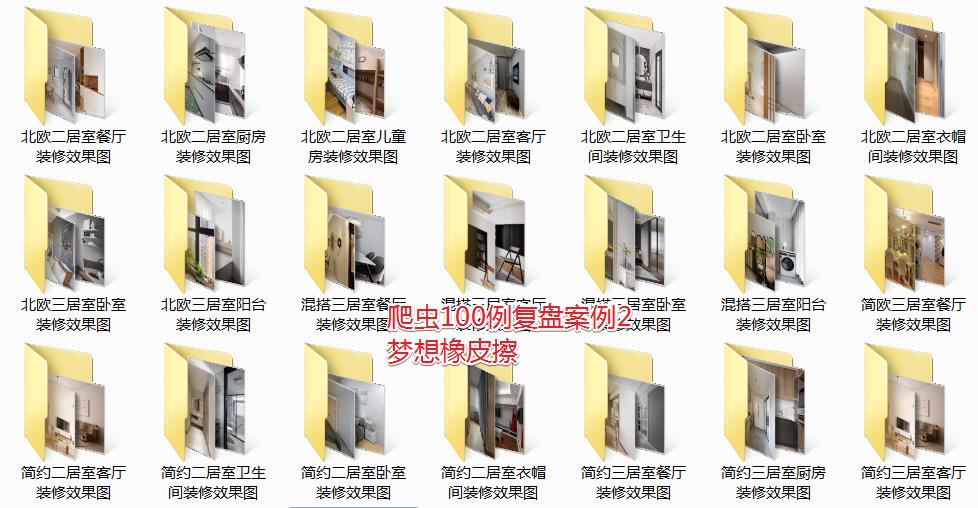
好吧,我道歉,这个案例作为起手项目,有点难了。
案例三:美空网数据抓取
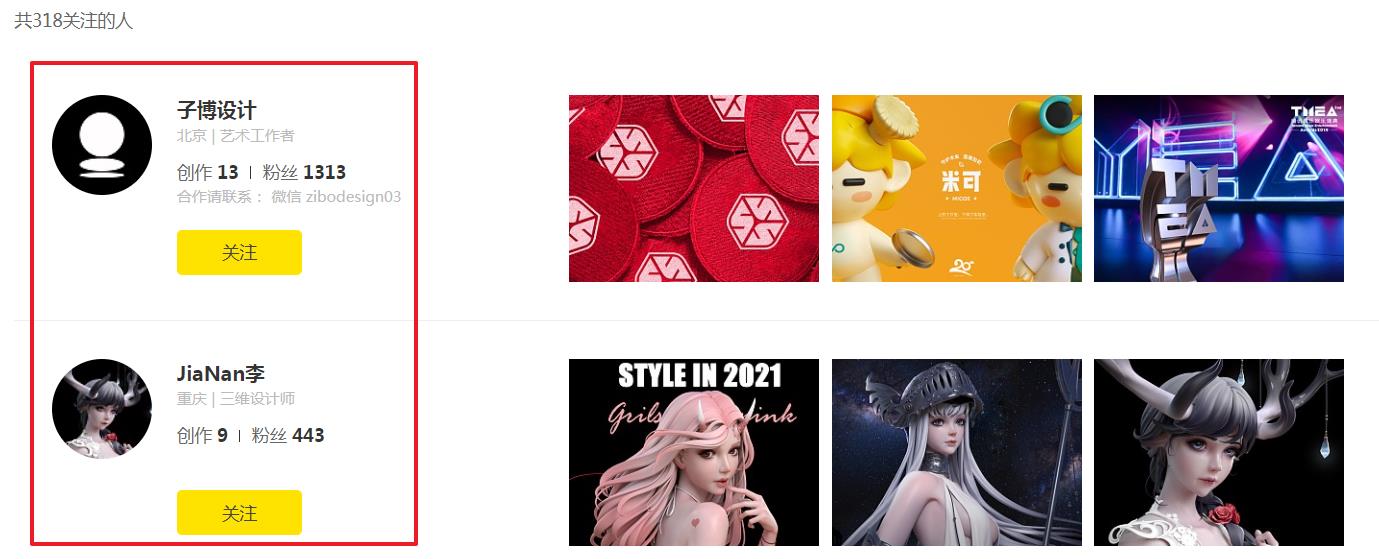
时隔三年,美空网竟然已经不能通过 PC 浏览模特数据了。是时候升级这个案例了,我们将其替换为站酷网 zcool,只做爬取展示,数据保存到 mongo 中,不再进行编写。
本案例核心是为了抓取用户关系链,起始选择任意一个用户进行爬取都可。
https://douge2013.zcool.com.cn/follow?condition=0&p=1
安装 mongodb 服务的时候出现了一点小问题,即 mangodb 服务无法启动。
解决方案如下:
在 MongoDB 安装目录中找到 bin 文件夹,同级目录创建 data 文件夹,在 data 中创建 db 与 logs 文件夹,然后在控制台输入如下命令。
mongod --dbpath="C:\\Program Files\\MongoDB\\Server\\3.6\\data\\db" --logpath="C:\\Program Files\\MongoDB\\Server\\3.6\\data\\logs\\MongoDB.log" --install --serviceName "MongoDB"
后面启动 mongo 留给你自己完成,mongo --port 27017。
第一步链接生产者的代码修改如下:
# -*- coding: UTF-8 -*-
import requests # 网络请求模块
import random # 随机模块
import re # 正则表达式模块
import time # 时间模块
import threading # 线程模块
import pymongo as pm #mongodb模块
class Config():
def getHeaders(self):
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (Khtml, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"其它 UserAgent "
]
UserAgent = random.choice(user_agent_list)
headers = {'User-Agent': UserAgent}
return headers
# 起始种子地址
urls = ["https://douge2013.zcool.com.cn/follow?condition=0&p=1"]
index = 0 # 索引
g_lock = threading.Lock() # 初始化一个锁
# 获取连接
client = pm.MongoClient('127.0.0.1', 27017) # 端口号是数值型
# 连接目标数据库
db = client.zcool
# 数据库用户验证
db.authenticate("zcool", "zcool")
# 生产者
class Producer(threading.Thread):
def run(self):
print("线程启动...")
headers = Config().getHeaders()
print(headers)
global urls
global index
while True:
g_lock.acquire()
if len(urls) == 0:
g_lock.release()
continue
page_url = urls.pop()
g_lock.release() # 使用完成之后及时把锁给释放,方便其他线程使用
response = ""
try:
response = requests.get(page_url, headers=headers, timeout=5)
except Exception as http:
print("生产者异常")
print(http)
continue
content = response.text
rc = re.compile(
r'<a href="(.*?)" title=".*?" class="avatar" target="_blank" z-st="member_content_card_1_user_face">')
follows = rc.findall(content)
# print(follows)
fo_url = []
threading_links_2 = []
for u in follows:
# 生成关注列表地址
this_url = "%s/follow?condition=0&p=1" % u
g_lock.acquire()
index += 1
g_lock.release()
fo_url.append({"index": index, "link": this_url})
threading_links_2.append(this_url)
g_lock.acquire()
urls += threading_links_2
g_lock.release()
print(fo_url)
try:
db.text.insert_many(fo_url,ordered=False )
except:
continue
if __name__ == "__main__":
p = Producer()
p.start()
最终经过我的一番修改,爬虫 100 例案例三重获新生,再次可用。重点修改的依旧是正则表达式解析逻辑。
修改后的代码下载地址:https://codechina.csdn.net/hihell/scrapy 案例 3。
案例四:基于案例三抓取到的用户地址,进行图片抓取
通过案例三,获取了大量的用户地址。图片抓取就不在进行案例更新了,使用案例三与案例四的思路,直接进行修改即可。
恰巧更新的站酷网也有图片,正好可以练手。
今日复盘结论
在复盘过程中,要记住爬虫的思路是不会发生变化的。实践过程也看到,只需要进行目标网站地址变更,正则表达式变更,就可以编写一个全新的爬虫。
良心博主,竟然 3 年不掉线。
收藏时间
做个不可能实现的任务吧,收藏过400,橡皮擦将回复评论区所有人,发一个神秘码
今天是持续写作的第 185 / 200 天。
可以关注我,点赞我、评论我、收藏我啦。
更多精彩
以上是关于《爬虫100例专栏》复盘更新,再捋一遍这100篇文章,更新1,2,3,4 篇(收藏再看)的主要内容,如果未能解决你的问题,请参考以下文章
时隔3年,摄影网站依旧可用,果然靠谱,Python爬虫100例,第2篇复盘文章
《爬虫100例》博客,2022-4-19最新案例复盘清单,已更新56/100例
时隔3年,摄影网站依旧可用,果然靠谱,Python爬虫100例,第2篇复盘文章
值!一篇博客,容纳11个Python爬虫案例总结,《爬虫100例》专栏第6篇复盘文章