爬虫技术,如何采撷这朵带刺玫瑰?| 同学汇
Posted 创新工场
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫技术,如何采撷这朵带刺玫瑰?| 同学汇相关的知识,希望对你有一定的参考价值。
「爬虫玩的溜,牢饭吃的久」
随着大数据执法风暴的开展,不少提供网络爬虫服务的公司被查,大家开始谈爬虫色变。
爬虫技术仿佛成了互联网的万恶之源。
2016 年,百度和大众点评曾因为爬虫技术引发了一起备受关注的诉讼,它们究竟谁在「搭便车」和「不劳而获」?
在这样的背景下,有些互联网公司甚至在考虑终止使用爬虫技术的可能性。完全终止是因噎废食,那么如何带着镣铐跳舞?爬虫技术的风险边界和合规红线到底如何界定?
本文来自创新工场2019年11月总第92期《法律宅急送》,作者为创新工场郭敬敬。
首先,我们先来了解下爬虫的定义以及robots协议(爬虫协议)的基本内涵。
网络爬虫
(又称为网页蜘蛛、网页机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本[]。爬虫技术有广泛的应用场景,在新闻信息搜索领域、互联网金融数据抓取、天气预报信息抓取、招投标信息抓取、视频图书类聚合平台、学术领域等都有现实应用案例。
Robots.txt
是一种存放于网站根目录下的ASCII编码的文本文件(“robots协议”),它通常告诉网络搜索引擎的漫游器/爬虫,网站的哪些内容是不应被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。robots协议不是命令,也不是防火墙,没办法防止恶意闯入者。
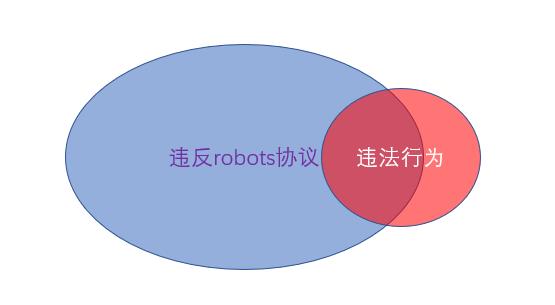
在爬虫合规界限和robots协议关系上,不少人有两个截然相反的误区。一种观点认为,robots协议不属于法律法规,只是君子协议,违反robots协议,不会产生任何法律责任。另一种观点则认为,只要爬虫过程遵守了robots协议,就满足了合规要求。
事实上,这两种观点都是片面的
。
《互联网搜索引擎服务自律公约》要求遵循国际通行的行业惯例与商业规则,遵守robots协议。
国内判决案例中,法院认为,robots协议已经成为一种国内外互联网普遍通行、普遍遵守的技术规范;《互联网搜索引擎服务自律公约》并非法院可以直接参照适用的法律法规或规章,但其反映和体现了行业内的公认商业道德和行为标准,法院对于《自律公约》所体现出的精神予以充分考虑。
遵守robots协议也是爬虫行为合规的必要非充分条件。
robots协议并不具有法律约束力,但是违反robots协议,可能会作为判断采用爬虫技术的一方是否存在主观恶意的重要标准。
在百度与大众点评网不正当纠纷上诉案中,尽管大众点评网的robots协议未禁止百度搜索引擎访问其网站点评信息,但法院认为,大众点评网的点评信息是其核心竞争资源之一,能带来竞争优势,具有商业价值。百度在百度地图和百度知道中大量使用了这些点评信息,其行为具有明显的搭便车、不劳而获的特点,违反了公认的商业道德和诚实信用原则,构成了不正当竞争。我们可以看到,网站的robots协议不禁止搜索引擎抓取信息,不构成网站允许使用这些信息的默示许可;不违反robots协议,仅说明爬取行为符合行业准则,但无法解决是否合法的问题;
不违反robots行为,在一定情形下,仍可能构成违法。
遵守robots协议,是爬虫技术的最基本行业规范要求;通常来说,遵守robots协议也是爬虫行为合规的必要非充分条件。
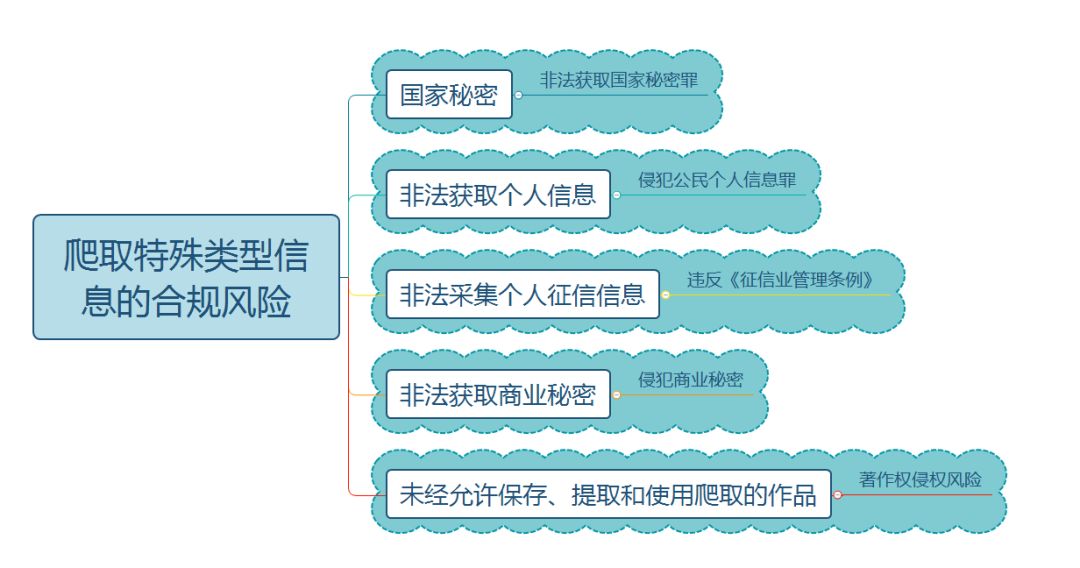
第一,国家秘密。
国家秘密系指关系国家安全和利益,依照法定程序确定,在一定时间内只限一定范围的人员知悉的事项。利用计算机爬虫技术,非法获取国家秘密的,涉嫌非法国家秘密罪。
第二,个人信息。
个人信息是以电子或其他方式记录的能单独或者与其他信息结合识别自然人个人身份的各种信息,包括但不限于自然人的姓名、出生日期、身份证件号码、个人生物识别信息、住址、电话号码等。个人信息收集前,应当遵循合法、正当、必要原则向被收集的个人信息主体公开收集、使用规则,明示收集、使用信息的目的、方式和范围等信息。未遵循前述要求,通过爬虫技术爬取个人信息,违反了网络安全法等法律法规关于个人信息保护的规定。
特别的,非法获取个人信息,情节严重的,涉嫌构成侵犯公民个人信息罪。
窃取或者以其他方法非法获取公民个人信息的,非法获取行踪轨迹信息、通信内容、征信信息、财产信息五十条以上的,非法获取住宿信息、通信信息、健康生理信息、交易信息等其他可能影响人身、财产安全的公民个人信息五百条以上的,或非法获取以上信息之外的公民个人信息五千条以上的,属于情节严重情形。
此外,未经被收集者同意,即使是将合法收集的公民个人信息向他人提供的,也属于“提供公民个人信息”,可能构成犯罪。
第三,个人征信。
征信业务,是指对企业、事业单位等组织的信用信息和个人的信用信息进行采集、整理、保存、加工,并向信息使用者提供的活动。根据《征信业管理条例》,擅自设立经营个人征信业务的征信机构或者从事个人征信业务活动的,由国务院征信业监督管理部门予以取缔。利用爬虫技术从事个人征信行为涉嫌违反《征信业管理条例》,从而面临罚款等处罚,甚至可能构成犯罪。
第四,商业秘密。
商业秘密是指不为公众所知悉,能为权利人带来经济利益,具有实用性并经权利人采取保密措施的技术信息和经营信息。根据《中华人民共和国反不正当竞争法》,通过电子侵入或者其他不正当竞争手段获取权利人的商业秘密的,构成侵犯商业秘密。
第五,著作权作品。
如果利用爬虫技术突破网站保障特定用户才能访问的部分文章、图片等作品的技术措施,可能涉嫌破坏技术措施的违法和侵权行为。如果在爬取该等文章、图片等作品之后公开传播前述作品,可能构成侵犯信息网络传播权。
爬虫技术本身虽然是中立的,但技术的背后是人。
爬虫技术使用者可能会出于自身目的,使用过于野蛮的爬虫,甚至导致网站无法正常运行。
根据国家互联网信息办公室2019年6月28日发布的《数据安全管理办法(征求意见稿)》,网络运营者采取自动化手段访问收集网站数据,不得妨碍网站正常运行;
此类行为严重影响网站运行,如自动化访问收集流量超过网站日均流量三分之一,网站要求停止自动化访问收集时,应当停止。
更甚者,如果使用网络爬虫技术过程中,破坏、突破或绕过其他计算机信息系统的安全保护措施,非法侵入他人的计算机信息系统,可能会触发法律风险,甚至构成犯罪。
-
违反国家规定,侵入国家事务、国防建设,尖端科学技术领域计算机信息系统的,构成非法侵入计算机信息系统罪。
-
违反国家规定,侵入国家事务、国防建设、尖端科学技术领域以外的计算机信息系统或者采取其他技术手段,获取该计算机信息系统中存储、处理或者传输的数据,情节严重的,构成非法获取计算机信息系统数据罪。
-
违反国家规定,如果通过网络爬虫技术侵入他人的计算机信息系统,或者对进入的计算机信息系统进行删除、修改、增加、干扰,造成计算机信息系统不能正常运行的,或对计算机系统中存储、处理或者传输的数据和应用程序进行删除、修改、增加,后果严重的,根据刑法第二百八十六条,构成破坏计算机信息系统罪。
数据是互联网时代的重要资源。
在数据的产生过程中,各式各样的互联网服务提供商在收集、整理、保存数据等方面做了很多工作。
爬虫技术可以有效的抓取现有数据,也就为「不劳而获」和「搭便车」提供了方便之门,进而可能违反商业道德和诚实信用原则,构成不正当竞争。
爬虫技术涉嫌不正当竞争行为的案件中,主要有几个核心因素需要考量,下面我们根据三个典型案例展开分析。
是否存在竞争关系,是判断构成不正当竞争行为的重要前提。
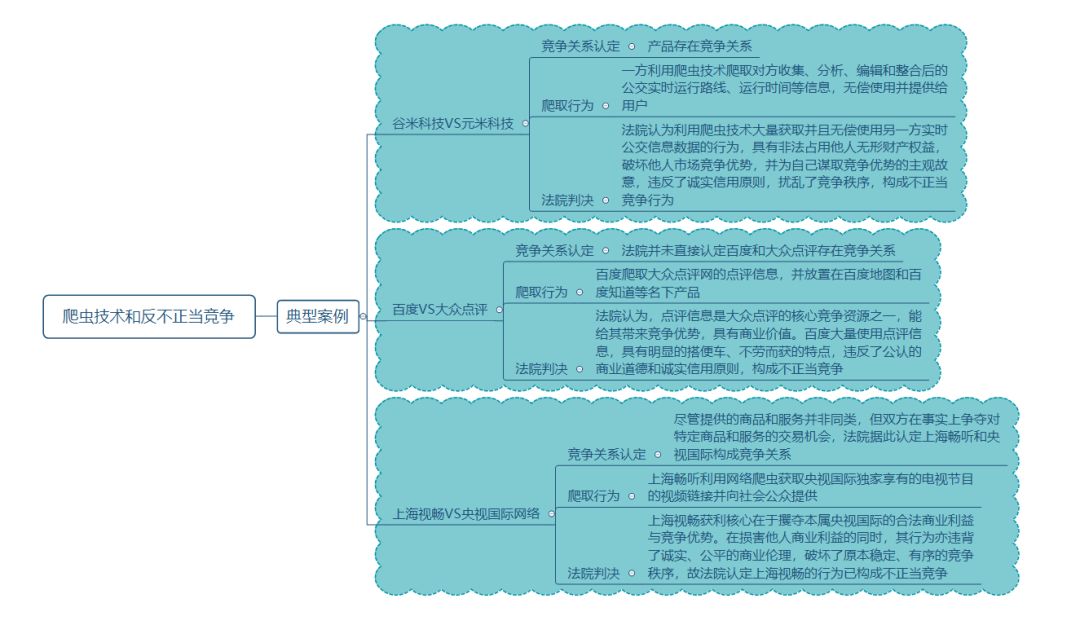
在百度VS大众点评案件中,百度爬取大众点评网上商户的点评信息,大众点评诉称百度构成不正当竞争;
百度主张,大众点评网为用户提供以餐饮为主的消费点评、消费优惠等业务,百度公司提供搜索服务,两者没有直接竞争关系。
公开的判决书中法院虽然没有就百度和大众点评网是否构成竞争关系做说明,但最终认定百度违反了公认的商业道德和诚实信用原则,构成了不正当竞争。
互联网时代的竞争是无边界的竞争,典型如BAT,其业务领域涵盖甚广且仍在扩张。
如果还是依照传统行业相同行业、相同领域或相同业态模式等固化的要素范围认定是否存在竞争关系,就会有失偏颇。
竞争关系是纵横交错的,很多经营者在提供的产品或服务的形式和内容方面虽然存在差异,但在争夺网络用户数量、信息、注意力等方面,目标是一致,具有实质性的竞争关系。
我们最大的竞争对手不是罗辑思维,也不是其他知识付费类产品;我们最大的竞争对手是王者荣耀。
判断竞争不应局限在产品或服务的「表象」,而要看业务的实质目标。
在认定被爬取信息的主体是否受到损失时,法院会权衡该等主题的流量是否被截取、用户群体是否会分流、原有商业广告利益是否减少、原有交易机会是否减少、软件下载量是否减少等因素。
例如,上海畅听VS央视国际案件中,上海畅听在未经授权以搜索链接方式传播开幕式节目的行为,必然会在一定程度上分流本属于央视国际公司的用户群体,增加自身的商业广告收益及客户端软件的下载数量;
上海视畅的行为已实质性地利用了央视国际享有权益的市场资源,打破原有的交易秩序,挤占他人的交易机会,并损害其竞争权益。
在判断爬取行为是否具有不正当性时,是否绕开robots协议是很重要的考量因素,但并非唯一的判断因素。
其余因素,比如涉案信息是否具有商业价值,是否给经营者带来竞争优势,信息获取的难易程度和成本付出、对信息的获取及利用是否违法、违背商业道德或损害社会公众利益、竞争对手使用信息的方式和范围等,都需要被综合考虑。
在谷米科技VS元米科技案件中,谷米公司对于公交车的实时运行路线、运行时间等信息进行收集、分析、编辑、整合并配合GPS精确定位,使得该等数据具有实用性并能够为权利人带来现实或将来的经济利益;
元米科技利用爬虫技术大量获取并且无偿使用谷米公司的实时公交数据的行为,具有非法占用他人无形财产权益、破坏他人市场竞争优势,并为自己谋取竞争优势的主观故意,违反了诚实信用原则,扰乱了竞争秩序,构成了不正当竞争。
如果经营者自身并非直接使用爬虫技术获取数据,而是从上游数据源公司获取数据,是不是就可以做到风险绝缘了呢?
以及,如果经营者爬取数据过程完全合法合规,或者其数据的收集方收集过程中合法合规,是否可以自由的进行数据整合和处理了?
最近的大数据行业整治活动,监管通过核查上游数据收集方的违规行为,顺藤摸瓜发现下游使用违规收集数据的企业。
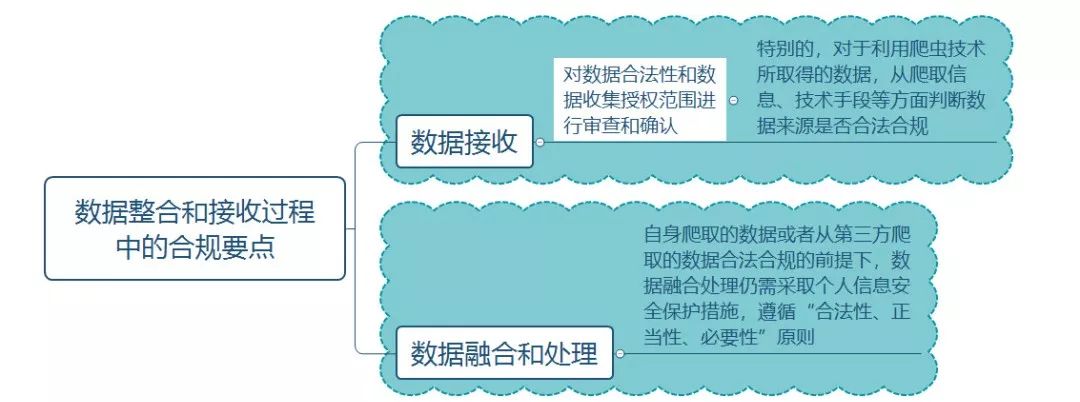
作为数据接收方,不能因为没有直接使用爬虫技术,就认为可以独善其身。
数据接收方应严格审核上游公司的数据来源
,特别是采用爬虫技术获取数据的数据提供方,是否遵守爬虫技术合规的要求。
为减少风险,数据接收方可以通过合同承诺等方式控制相关数据风险。
对于自身爬取或者从第三方获得的爬取数据,如果进行过数据融合和处理,融合和处理之后的信息包含个人信息,应遵守个人信息使用限制的要求,根据使用目的开展个人信息安全影响评估,并采取适当的个人信息保护措施。
爬虫技术虽属利器,使用不当,易遭反噬。
为尽可能的减少风险,使用爬虫技术时,应尽可能做到:
不绕开或规避robots协议;
爬取的信息如属于国家秘密、个人信息、商业秘密、著作权作品等,应及时停止并删除;
善意使用爬虫技术,不利用爬虫技术损失其他经营者的合法权益或攫取不正当的竞争利益;
作为数据接收方,应核查数据来源是否合法合规;数据融合和处理需要遵守个人信息保护等方面的合规要求。

以上是关于爬虫技术,如何采撷这朵带刺玫瑰?| 同学汇的主要内容,如果未能解决你的问题,请参考以下文章
Android学习之RecyclerView带刺的玫瑰
三分钟学会使用自动化的技术写爬虫
金牌讲师带你学爬虫——Python爬虫技术分享
数据即使不会爬虫技术,也能轻松获取的重要数据
电子书 | Python 爬虫技术升级必备
即使不会爬虫技术,也能轻松获取的重要数据