三分钟学会使用自动化的技术写爬虫
Posted 测试萌萌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了三分钟学会使用自动化的技术写爬虫相关的知识,希望对你有一定的参考价值。
很多同学对爬虫比较感兴趣,很想知道什么是爬虫到底是什么,爬虫学起来难不难?从哪里入手开始学习?
这里我想跟大家说,其实你们学完自动化之后,要想学习爬虫,其实非常简单,爬虫里面用到的技术,我们在学习自动化的时候基本上都学过了。
只不过不知道如何使用自动化的技术来实现爬虫,那么接下来我们就来聊聊如何使用自动化的项目技能来实现爬虫。
01
什么是爬虫
学习爬虫之前我们来先了解一下爬虫的概念,什么是爬虫?
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫
——百度百科解释

爬虫和实现自动化实现流程对比:

02
爬虫和实现使用技术分析
发请求,访问页面
▲ requests(接口自动化必备技能)
▲ selenium(web自动化必备技能)
提取页面数据
▲ Xpath(web自动化元素定位的技能)
可以看得出,上述所需要的技能
03
环境安装
首先第一步就是关于环境的安装,环境安装前提:安装好python。然后在这边,我们还需要安装两个第三方库,第一个是requests,是用来发送网络请求的,第二个库是lxml是用来解析页面数据的。
1、requests模块安装

2、lxml模块安装

04
数据爬取实战
目标:获取北京地区自动化测试的所有热门岗位!
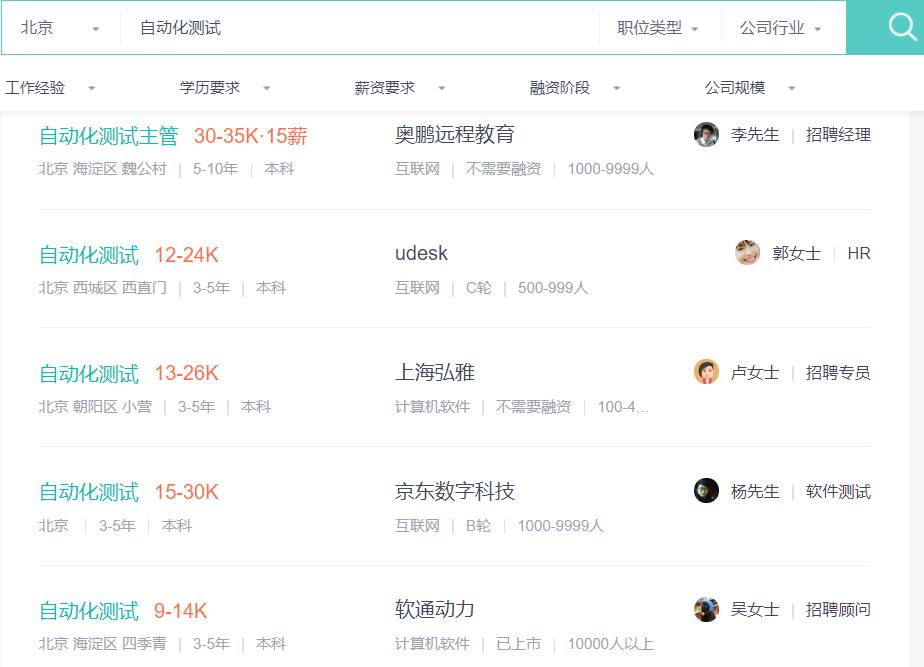
目标地址:
https://www.zhipin.com/c101010100/?query=%E8%87%AA%E5%8A%A8%E5%8C%96%E6%B5%8B%E8%AF%95&ka=sel-city-101010100
待获取的目标数据
▲ 职位名称
▲ 薪资范围
▲ 所属公司
爬虫实现的步骤:
1、构造请求数据
在发送请求时,注意请求头要写加上cookie和user-agent,否则无法获取到正确的页面数据(关于cookie和user-agent可以去浏览器上复制过来)
# 定义请求头
header =
"cookie":"_uab_collina=156013238928273573152563; lastCity=101010100; __c=1576727614; __g=-; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1576727614; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1576727614; __l=l=%2Fwww.zhipin.com%2F%3Fka%3Dheader-home-logo%26city%3D101010100&r=https%3A%2F%2Fwww.zhipin.com%2F%3Fka%3Dheader-home-logo&friend_source=0&friend_source=0; __a=12875726.1576727614..1576727614.2.1.2.2; __zp_stoken__=d78eVjuAQ37e1fHI1t6xEr7uLmzoPWCALMYtdQ%2Fk59lWJaxYFJnngZe64gxX529QtBuD3y4nmrjnnAYCmBn98W3jznBL%2BPb02LVrGXjyqcKWtU7k%2BxcdENjUJKQiEEjEiL2R",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/75.0.3770.80 Safari/537.36",
# 目标网站的地址
url = "https://www.zhipin.com/c101010100/?query=%E8%87%AA%E5%8A%A8%E5%8C%96%E6%B5%8B%E8%AF%95&ka=sel-city-101010100"2、发送网络请求

3、提取页面数据

综合整理代码如下:
"""
============================
author:MuSen
time:2019/6/10
E-mail:3247119728@qq.com
============================
"""
import requests
from lxml import etree
s = requests.session()
header =
"cookie":"_uab_collina=156013238928273573152563; lastCity=101010100; __c=1576727614; __g=-; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1576727614; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1576727614; __l=l=%2Fwww.zhipin.com%2F%3Fka%3Dheader-home-logo%26city%3D101010100&r=https%3A%2F%2Fwww.zhipin.com%2F%3Fka%3Dheader-home-logo&friend_source=0&friend_source=0; __a=12875726.1576727614..1576727614.2.1.2.2; __zp_stoken__=d78eVjuAQ37e1fHI1t6xEr7uLmzoPWCALMYtdQ%2Fk59lWJaxYFJnngZe64gxX529QtBuD3y4nmrjnnAYCmBn98W3jznBL%2BPb02LVrGXjyqcKWtU7k%2BxcdENjUJKQiEEjEiL2R",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.80 Safari/537.36",
# 目标网站的地址
url = "https://www.zhipin.com/c101010100/?query=%E8%87%AA%E5%8A%A8%E5%8C%96%E6%B5%8B%E8%AF%95&ka=sel-city-101010100"
# 发送请求,获取页面内容
response = s.get(url=url, headers=header)
# 获取页面内容(代码)
html_str = response.content.decode('utf8')
print(html_str)
# 转换
html = etree.HTML(html_str)
# 提取目标数据(招聘岗位)
# job_list = html.xpath('//*[@id="main"]/div/div[3]/ul/li')
# 提取所有的岗位节点
job_list = html.xpath('//div[@class="job-list"]/ul/li')
print(job_list)
for job in job_list:
# 获取岗位名称
job_name = job.xpath('.//div[@class="job-title"]/text()')
# 获取薪资待遇
price = job.xpath('.//span[@class="red"]/text()')
# 获取公司名称
job_company = job.xpath('.//div[@class="company-text"]/h3/a/text()')
# 格式化一下数据
job_data = '岗位名称: 薪资: 公司:'.format(job_name[0], price[0], job_company[0])
print(job_data)
运行以上代码就能爬取到我们所需要的数据了。
最后: 下方这份完整的软件测试视频学习教程已经整理上传完成,朋友们如果需要可以自行免费领取【保证100%免费】
这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!

以上是关于三分钟学会使用自动化的技术写爬虫的主要内容,如果未能解决你的问题,请参考以下文章