谷歌亚马逊和百度的深度学习野心:TensorFlowMXNetPaddlePaddle 三大框架对比
Posted 新智元
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了谷歌亚马逊和百度的深度学习野心:TensorFlowMXNetPaddlePaddle 三大框架对比相关的知识,希望对你有一定的参考价值。
新智元推荐
来源:我爱计算机 授权转载
新智元启动新一轮大招聘:COO、执行总编、主编、高级编译、主笔、运营总监、客户经理、咨询总监、行政助理等 9 大岗位全面开放。
简历投递:jobs@aiera.com.cn HR 微信:13552313024
新智元为COO和执行总编提供最高超百万的年薪激励;为骨干员工提供最完整的培训体系、高于业界平均水平的工资和奖金。加盟新智元,与人工智能业界领袖携手改变世界
【新智元导读】本文作者陈汝丹从定位、框架使用、分布式构成三个方面比较了 TensorFlow、MXNet、PaddlePaddle三个常用开源框架。
本文转载自《TensorFlow、MXNet、PaddlePaddle 对比 | 我爱计算机》,特此感谢。
从深度学习开始流行,到深度学习框架的迭代,到各类实际应用的出现,不过短短几年时间。TensorFlow刚出的那段时间,简单对比过TensorFlow、MXNet、caffe三个框架,有些看法可能也不够准确,到了今天,TensorFlow、MXNet作为国内风头很盛的框架迭代了多个版本, caffe几乎没怎么更新了, 因此就不再讨论caffe了,而是看看百度推出的开源框架PaddlePaddle,本文主要对比一下TensorFlow、MXNet、PaddlePaddle在用户实现上的一些异同。先从三个框架的定位开始。
1.定位
其实发展到现在,各个框架对自己的定位都不相同,硬要说哪个框架最好没什么必要,结合自身需求找到合适的用就够了(实验室的服务器不太方便拿来折腾,本文就不比较运算速度了)。而框架的定位从它们的网站标题中就完全可以看出来。
TensorFlow想做的是人工智能的算法引擎,它不仅提供了深度学习的基本元件例如卷积、pooling、lstm等,提供很多基本计算操作,在这一年还围绕着算法开发推出了TensorFlow Serving用于将算法动态部署到线上、想取代scikit-learn的tf.contrib.learn、将不同尺寸的输入处理成相同规模用于批处理的TensorFlow Fold、在移动平台上跑算法、支持Java/Go语言的接口、分布式实例等等。这些都可以看出TensorFlow在不断扩张版图,它不只是一个框架提供一些API供用户调用,也同时在围绕着算法推出各种配套服务。也许由于TensorFlow的扩张,做优化的人不够多,导致现在运行效率就算是分布式版本都比其他框架都要慢[4],而且版本间有时候函数接口还老不兼容。最新的1.0的版本说Inception v3神经网络的训练速度提升了58倍,个人觉得tf底层实现不会大改,如果要提速可能需要针对各个网络单独设计优化版本。
MXNet对自己的定位是一个flexible和efficient的深度学习框架,它的重点放在了深度学习算法上面,而针对两个特性,前者是说它支持命令式和声明式两种编程方式,比如说做一道菜,TensorFlow就必须按照规定好的步骤热锅、放油、放菜、放盐等一步步执行,而MXNet则能在中间过程做点别的事情,假如味道淡了再放点调味料,假如又想加别的菜了也可以加进去,所以说它更灵活,其次还体现在支持多种语言,从最早的R/Julia到现在增加了对Go/Matlab/Scala/javascript的支持。高效性则是指MXNet的分布式并行计算性能好、程序节省内存,在多GPU上表现非常好,几乎能做到线性加速。内存方面比较能说明问题的是这个框架一推出的时候就支持在移动设备上运行神经网络。TensorFlow开始横向拓展服务时,MXNet仍旧继续优化技术,提供更多的operators、优化内存相关操作、提高并行效率等。并且去年十月份提出了NNVM,将代码实现和硬件执行两个部分隔离开,使得不同的框架不同语言实现的代码可以无差别执行在不同硬件之上。但这一年MXNet都没有产生一个大的社区,有同学说遇到问题还需要自己去查阅修改源码,导致使用门槛还是有一些高。但是16年11月份亚马逊将MXNet选为了官方框架,后续估计会提供非常简洁的云计算服务,用户只需要提交网络配置文件和数据就够了,使用会成为一件简便的事情。
PaddlePaddle是16年9月份开源的,它对自己的定位是easy to use,这点做的很好,它将一些算法封装的很好,如果仅仅只需要使用现成的算法(VGG、ResNet、LSTM、GRU等等),源码都不用读,按照官网的示例执行命令,替换掉数据、修改修改参数就能跑了,特别是NLP相关的一些问题,使用这个库比较合适,并且没有向用户暴露过多的python接口。它的中文文档相对友好,但是中英文文档数量都有点少,主程序是个c++程序,所以源码阅读还挺方便,但是由于像caffe一样按照功能来构造整个框架,二次开发要从c++底层写起,使用已有的算法没问题,但想做一些新功能会麻烦一些。做科研的话这个库可能不是很合适,它的文档比较注重怎么用它已经实现好的网络,而不是怎么写网络,比较适合需要成熟稳定的模型来处理新数据的情况。它的分布式部署做的很好,目前是唯一支持Kubernetes的深度学习库。
2.使用构成
这个部分简单谈谈从我们用户角度来看各个框架是怎么设计和使用的。
tensorflow出发点是将一个算法表示成一张有向计算图,并提供了TensorBoard这样一个工具用于可视化算法,如下图的节点和连线,包括了计算、数据以及控制关系。算法中涉及到的任何计算都抽象成符号operation,例如图中的conv、concat、add等椭圆形的计算节点,而算法涉及到的数据则是tensor,它在节点之间流动,连线上还展示了这个tensor的shape,有向图中还有一种数据节点variable,它表示的是某个变量(权重或者输入输出),可以通过它来控制tensor的读写,它能像tensor一样作为计算节点的输入。tensor的流动通过连接有向图的实线表示,控制依赖control dependencies通过虚线箭头表示,箭头的起始节点执行完毕才执行结束节点,session控制tensor流动到何处停止。因此使用TensorFlow需要先定义计算图,然后再把数据往里传得到输出。它没有一个严格的前向传输后向传输的概念,求解梯度通过optimizer来控制,如果数据flow到了optimizer的位置,会对前面需要求导的变量自动求导并更新。
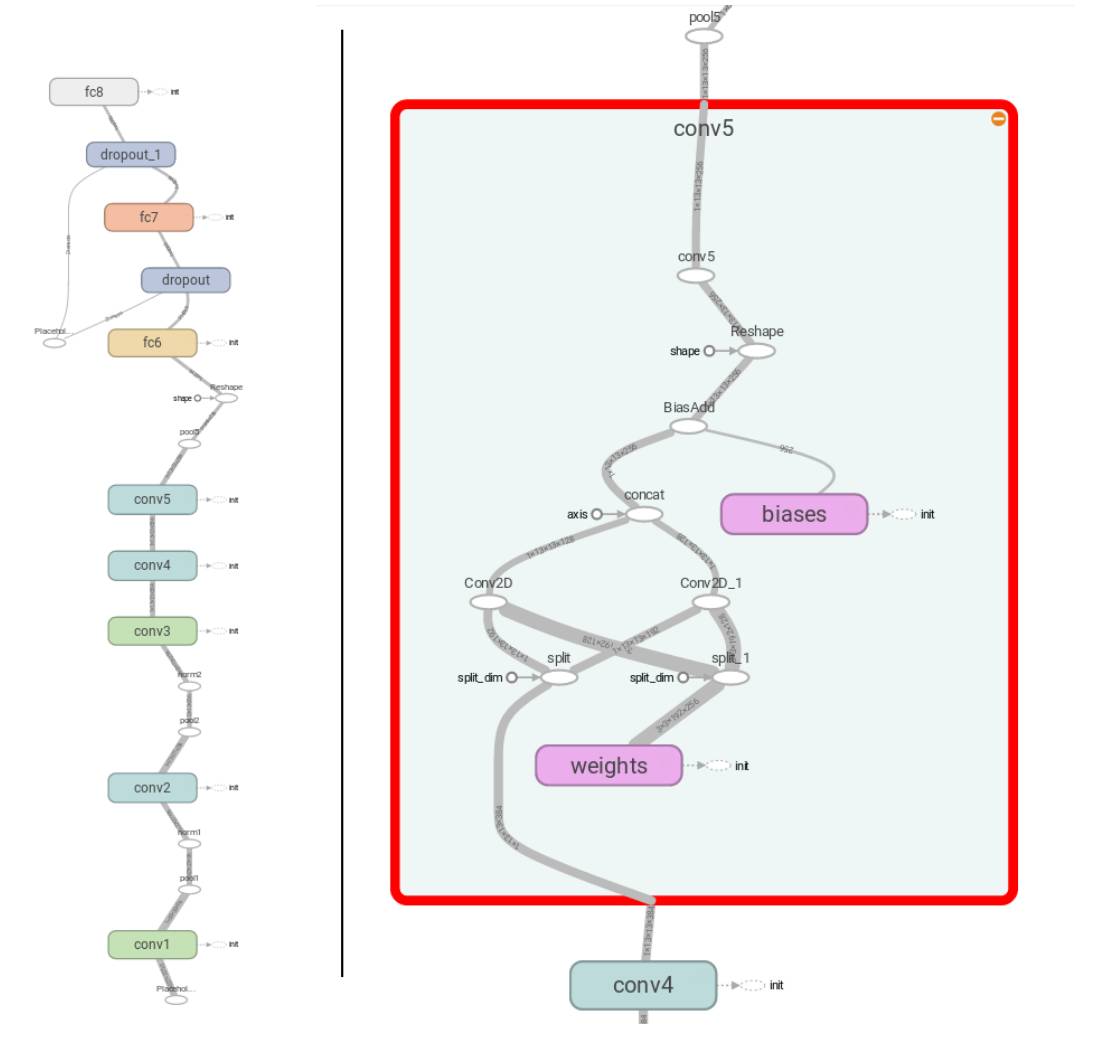
图1 TensorFlow计算图
MXNet也是将算法表达成了有向计算图,将数据和计算表达成有向图中的节点,与TensorFlow不同的是,MXNet将计算图中每一个节点,包括数据节点variable、基本计算floor、神经网络操作pooling都封装在symbol里面,而TensorFlow将数据节点、基本计算、神经网络操作封装成了不同的类,所以它们之间流通需要通过tensor,而MXNet计算图的节点输出类型统一是symbol,通过outputs访问symbol中的NDarray数据。当构建好计算图的节点、连接方式,就通过executor来启动计算,包括计算图的前向计算输出和反向计算导数。MXNet为训练深度学习实现了Model/Module两个类,Model在executor上又封装了一层,实现了feedforward功能,将forward和backward整合在了一起,用户直接调用feedforward.fit即可完成训练、更新参数。而Module的接口好像也差不多,官网说Model只是为了提供一个接口方便训练,Module是为了更高一层的封装。
Paddle的架构挺像caffe的,基于神经网络中的功能层来开发的,一个层包括了许多复杂的操作,例如图1中右边展开的所有操作合起来可以作为这里的一个卷积层。它将数据读取DataProvider、功能层Layers、优化方式Optimizer、训练Evaluators这几个分别实现成类,组合层构成整个网络,但是只能一层一层的累加还不够实用,为了提高灵活性,额外
设置了mixed_layer用来组合不同的输入,如下图2所示。但是这种比较粗粒度的划分就算能组合不同输入也不会像上面的灵活,比如add和conv这种操作在上面两种框架中是属于同一层面的,而在pd中则会是conv里面包含add。看得出paddle在尽可能简化构造神经网络的过程,它甚至帮用户封装好了networks类,里面是一些可能需要的组合,例如卷积+batchNorm+pooling。它希望提供更简便的使用方式,用户不需要更改什么主体文件,直接换数据用命令行跑。
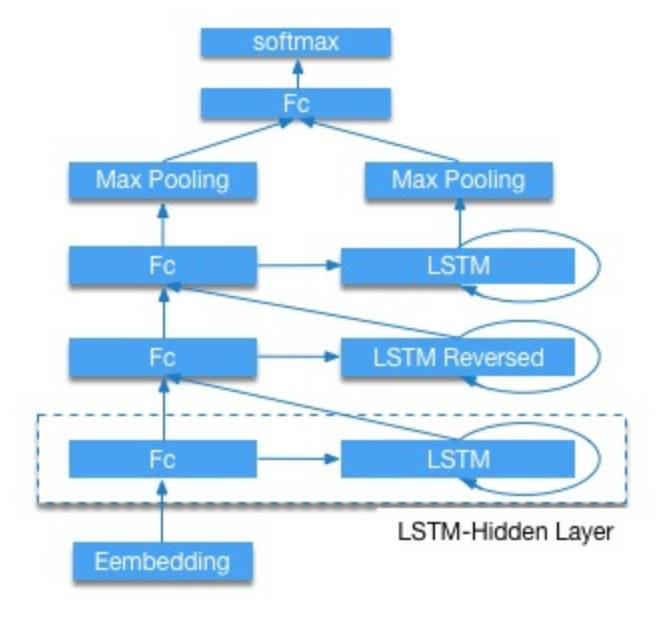
图2 PaddlePaddle功能层
3.分布式实现
首先说说深度学习算法实现分布式需要干什么,分布式就是将一个参数巨多、数据居多的神经网络分成一些小任务放在多个机器多个显卡上面执行,针对这两个特性有两种解决方案,参数多就把网络切分放在不同设备上,数据量大就多台机器同时执行相同代码处理不同数据,前者称为模型并行后者称为数据并行。神经网络相对其他分布式问题的特殊之处在于,不同机器上的网络参数在训练时都会独立的求导更新,然而这些参数在新的迭代开始之前要保证相对一致(由于可以异步更新,不同机器之间可以不完全一样,但肯定不能差别过大),因此就出现了Parameter Server,它保存了神经网络的权重等参数,决定了何时接收对这些数据的修改,决定了何时将修改后的数据发放到不同机器的计算节点上。假设需要训练图3中的神经网络,其中节点b和e是网络参数,machine 0和machine 1构成了模型并行,machine01和machine23构成了数据并行,中间的是参数服务器,用于收发参数。目前三个框架都说支持模型并行和数据并行,从用户实现上来看还是各有不同。
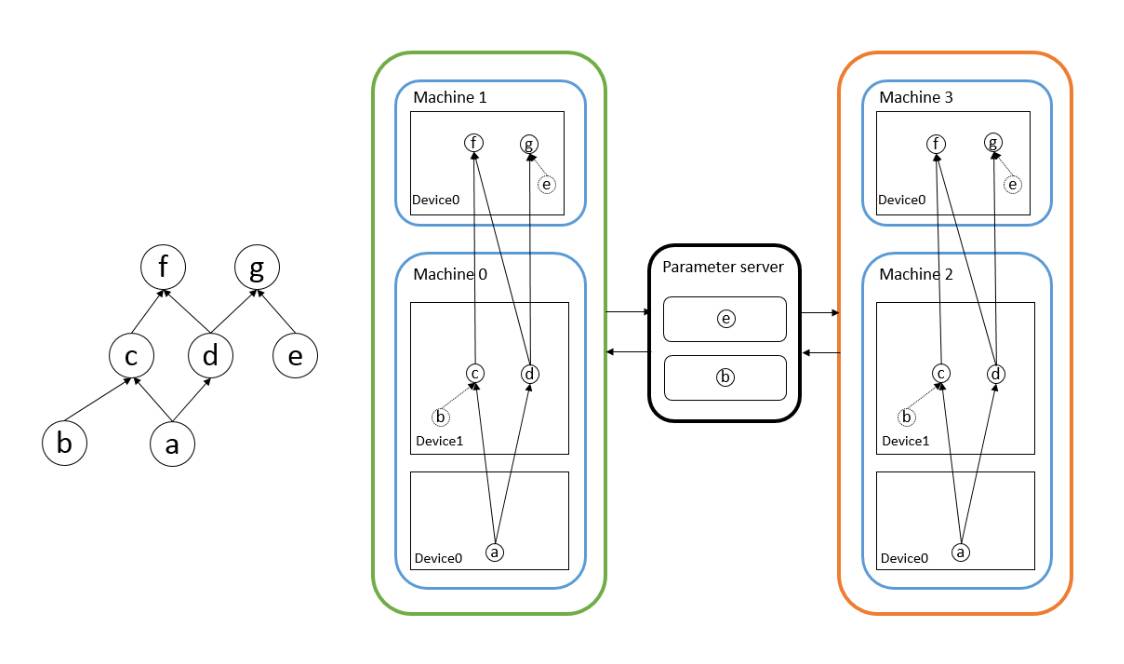
图3 分布式神经网络
tf不同的功能以job划分,例如运行整个computation graph是一个功能,作为parameter server存储更新交换参数是一个功能。job由一系列task组成,每个task是一个进程,它完成指定的工作,计算、传输、读写等等。在tf的分布式实现中,用户要实现的分布式程序主要是两个部分,分别是graph的配置和集群的配置,client需要定义computation graph的结构,节点放在哪个job/task上,并且创建session,通过session请求graph计算到什么地方,一个client对应一个computation graph,如果采用了数据并行,那么就会产生多个graph。集群配置确定了有多少台机器,哪台机器执行哪个task。
tf没有专门实现paramter server,而是实现了server,server对象负责交换数据,但不是只交换网络的参数,只要涉及到不同设备间要交换的数据都是由server管理,例如下图中machine0的device 0和device 1之间交换网络的输入输出,因此,在实现神经网络时一般需要将网络参数放在称为ps的job中,从而在网络运行时自动的更新参数。一个task会实例化一个server对象,不同机器之间交换数据的协议有多种,例如gRPC、RDMA等。然后手动在不同的机器上分别执行程序,如下图所示。
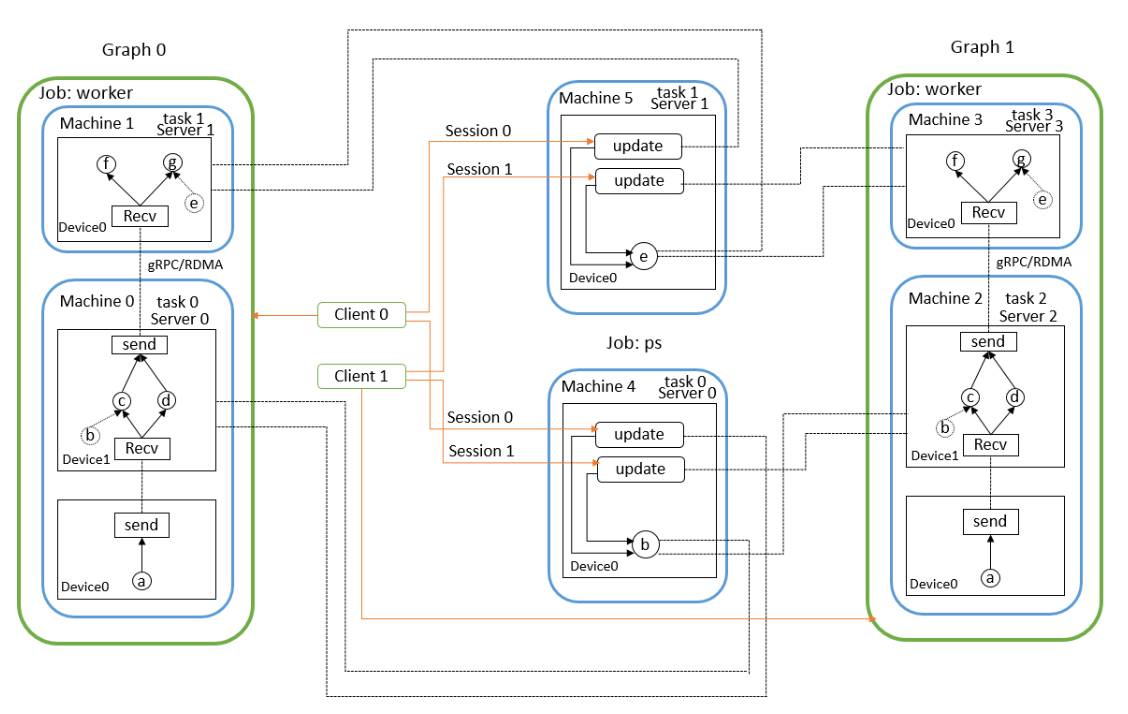
图4 TensorFlow各台机器涉及到的内容
MXNet通过kvstore实现parameter server从而实现多机运行程序,设备之间传输是通过确定数据所在的context后相互交换NDArray。从15年推出的时候就已经支持分布式了,它将网络分布式训练的过程已经封装好,用户只需要确定网络的配置,哪些操作放在哪个GPU之上,开放给用户的接口是Module类的fit函数,这个函数内部会自动创建kvstore对象,在训练的时候梯度和权重会自己push/pull。启动分布式程序也不需要自己手动在多台机器上执行命令,MXNet封装好了launch.py,传入机器个数、主机ip等就能在一台机器上启动多台机器运行程序。
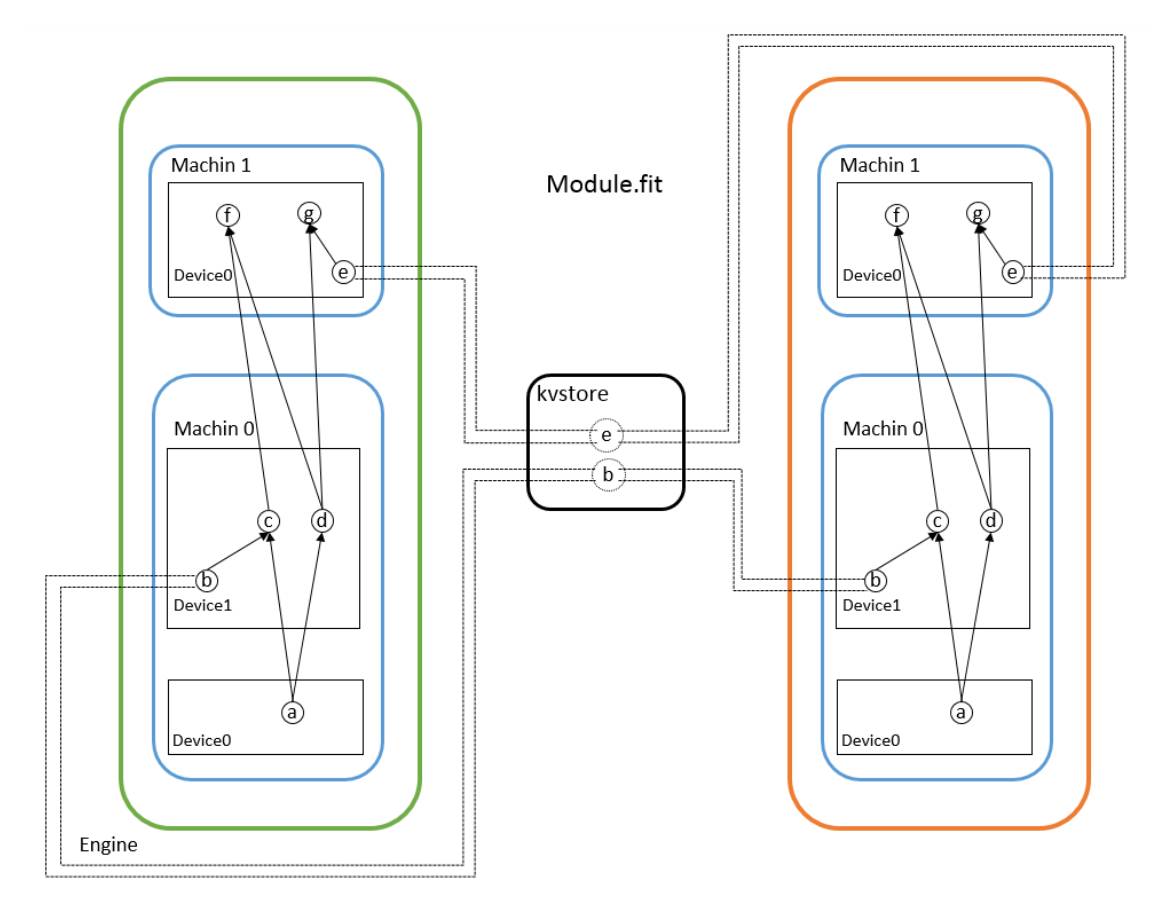
图5 MXNet各台机器涉及到的内容
PaddlePaddle的分布式结构主要有两个部分,trainer和parameter server。前者是配置网络,功能层、优化算法的python接口封装在了trainer_config_helpers类中,用户可以使用这些接口配置自己的网络,后者没有将接口放出来给用户使用,而是在c++程序中实现的,再通过python来调用c++程序。pd给的例子中通过fabric库来启动分布式程序,可以做到在一台机器上启动多台机器。在parameter server的使用上,pd针对一个网络可以拥有多个参数服务器ps,每个ps负责一部分的网络参数,与所有的trainers进行交换数据,如下图所示。
图6 PaddlePaddle分布式结构
4.小结
零零碎碎聊了一些各个框架中我比较关注的内容,作为Caffe的真爱粉,这三个框架我没有什么偏好,各有各的优点各有各的缺点,都有很多值得学习的地方。写之前对PaddlePaddle 的印象还挺不错的,没想到文档资料并不多,github上面的star虽然有4400+,但是感觉用的人好少,官方的文件对这个框架本身的东西介绍也少,重心放在了怎么使用上面。就使用上来看,周围的同学反而用Keras的比较多,有条件的话其实都下载试一试才能确定哪个更适合自己。
个人理解有限,如果文章有不对的地方,欢迎批评指正。
5. 参考文献
[1] TensorFlow
[2] MXNet
[3] PaddlePaddle
[4] Benchmarking State-of-the-Art Deep Learning Software Tools
[5] Comparative Study of Deep Learning Software Frameworks
[6] TensorFlow Serving
[7] Learn (contrib)
[8] 谷歌发布深度学习库TensorFlow Fold,支持动态计算图
[9] TensorFlow Mobile
[10] 宣布 TensorFlow 1.0
[11] MXNet设计和实现简介
[12] Deep Learning in a Single File for Smart Devices
[13] [RELEASE] Announcing v0.9 Release Candidate 1
[14] MXNet专栏 | 陈天奇:NNVM打造模块化深度学习系统
[15] 跑在Kubernetes上的开源深度学习,百度这次带来了哪些技术看点?
[16] TensorBoard: 图表可视化
[17] Finetuning AlexNet with TensorFlow
[18] Sentiment Analysis Tutorial
[19] Large Scale Distributed Deep Networks
[20] Scaling Distributed Machine Learning with the Parameter Server
[21] 理解和实现分布式TensorFlow集群完整教程
[22] Run Deep Learning with PaddlePaddle on Kubernetes
本文获我爱计算机授权转载发布,特此感谢。
新智元招聘
职位:COO
职位年薪:50万(工资+奖金)-100万元(含期权)
工作地点:北京-海淀区
所属部门:运营部
汇报对象:CEO
下属人数:10人
年龄要求:25 岁至 40 岁
语 言:英语六级以上或海外留学从业背景
职位背景:在IT领域有专业团队管理经验
学历要求:硕士及以上
职位描述:
1. 负责新智元总体市场运营,智库与人工智能百人会经营,政府关系统筹协调
2. 擅长开拓市场,并与客户建立长期多赢关系,有建构产业生态系统能力
3. 深度了解人工智能及机器人产业及相关市场状况,善于捕捉商业机会
4. 统筹管理公司各运营部门,兼管公司HR及财务部门
5. 带领运营团队完成营业额目标,并监控协调运营部与编辑部、研究部运作
6. 负责公司平台运营总体战略计划、合作计划的制定与实施
岗位要求
1、硕士以上学历,英语六级以上,较强的英语沟通能力或外企从业经验
2、 3年以上商务拓展经验,有团队管理经验,熟悉商务部门整体管理工作
3、 IT领域商务拓展经验、强大的团队统筹管理能力
4、 有广泛的TMT领域人脉资源、 有甲方市场部工作经验优先考虑
5、 知名IT媒体商务部门管理经验,广告、公关公司市场拓展部负责人优先
应聘邮箱:jobs@aiera.com.cn
HR微信:13552313024
新智元欢迎有志之士前来面试,更多招聘岗位请点击阅读原文查看。
新智元招聘信息请点击“阅读原文”
以上是关于谷歌亚马逊和百度的深度学习野心:TensorFlowMXNetPaddlePaddle 三大框架对比的主要内容,如果未能解决你的问题,请参考以下文章
我不再使用TensorFlow的5大原因谷歌最受欢迎深度学习框架日渐式微?
PyTorch成TensorFlow最大竞争对手,微软亚马逊Facebook 合作联盟对抗谷歌
马云:要是哭有用我就每天哭!微软和亚马逊联合推出深度学习库Gluon;谷歌推出AVA数据库;Ant Design 2.13.7