加米谷学院带你了解Flume的高可靠,高性能和高扩展性
Posted 加米谷学院
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了加米谷学院带你了解Flume的高可靠,高性能和高扩展性相关的知识,希望对你有一定的参考价值。
官网:https://flume.apache.org/
Flume 是Apache旗下的一款开源、高可靠、高扩展、容易管理、支持客户扩展的数据采集系统。 Flume使用JRuby来构建,所以依赖Java运行环境。
Flume最初是由Cloudera的工程师设计用于合并日志数据的系统,后来逐渐发展用于处理流数据事件。
Flume设计成一个分布式的管道架构,可以看作在数据源和目的地之间有一个Agent的网络,支持数据路由。
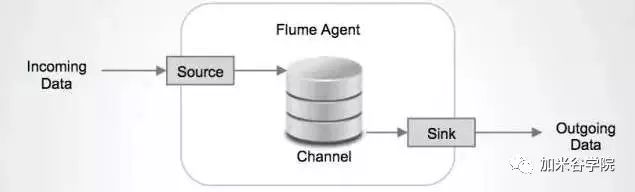
每一个agent都由Source,Channel和Sink组成。
Source负责接收输入数据,并将数据写入管道。Flume的Source支持HTTP,JMS,RPC,NetCat,Exec,Spooling Directory。其中Spooling支持监视一个目录或者文件,解析其中新生成的事件。
Channel 存储,缓存从source到Sink的中间数据。可使用不同的配置来做Channel,例如内存,文件,JDBC等。使用内存性能高但不持久,有可能丢数据。使用文件更可靠,但性能不如内存。
Sink负责从管道中读出数据并发给下一个Agent或者最终的目的地。Sink支持的不同目的地种类包括:HDFS,HBASE,Solr,ElasticSearch,File,Logger或者其它的Flume Agent。
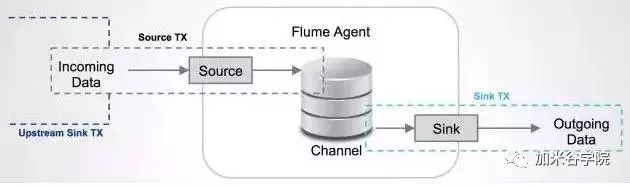
Flume在source和sink端都使用了transaction机制保证在数据传输中没有数据丢失。
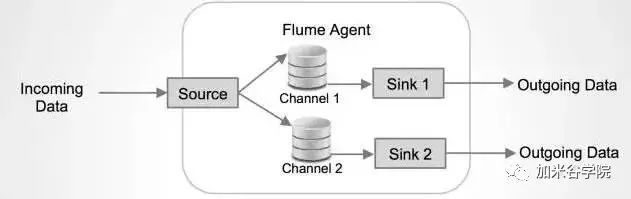
Source上的数据可以复制到不同的通道上。每一个Channel也可以连接不同数量的Sink。这样连接不同配置的Agent就可以组成一个复杂的数据收集网络。通过对agent的配置,可以组成一个路由复杂的数据传输网络。
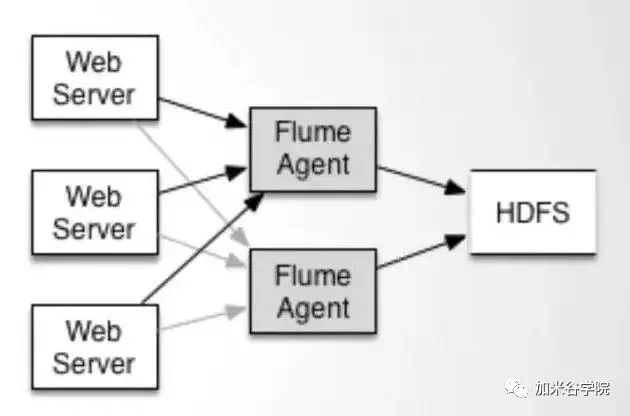
配置如上图所示的agent结构,Flume支持设置sink的Failover和Load Balance,这样就可以保证即使有一个agent失效的情况下,整个系统仍能正常收集数据。
Flume中传输的内容定义为事件(Event),事件由Headers(包含元数据,Meta Data)和Payload组成。
Flume提供SDK,可以支持用户定制开发:
Flume客户端负责在事件产生的源头把事件发送给Flume的Agent。客户端通常和产生数据源的应用在同一个进程空间。常见的Flume客户端有Avro,log4J,syslog和HTTP Post。另外ExecSource支持指定一个本地进程的输出作为Flume的输入。当然很有可能,以上的这些客户端都不能满足需求,用户可以定制的客户端,和已有的FLume的Source进行通信,或者定制实现一种新的Source类型。
同时,用户可以使用Flume的SDK定制Source和Sink。似乎不支持定制的Channel。
成都加米谷大数据科技有限公司是一家专注于大数据人才培养的机构。由来自阿里、华为、京东、星环等国内知名企业的多位技术大牛联合创办,技术底蕴丰厚,勤奋创新,精通主流前沿大数据及人工智能相关技术。
以国家规划大数据产业发展战略为指引,以全国大数据技术和大数据分析人才的培养为使命,以提升就业能力、强化职业技术为目标。面向社会提供大数据、人工智能等前沿技术的培训业务。
以上是关于加米谷学院带你了解Flume的高可靠,高性能和高扩展性的主要内容,如果未能解决你的问题,请参考以下文章