SPSS二元logistics回归结果分析
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SPSS二元logistics回归结果分析相关的知识,希望对你有一定的参考价值。
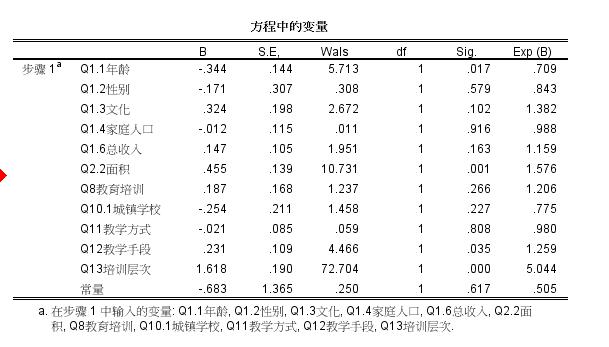
数据有问题吗?怎么小于0.05的这么少?要怎么分析啊!!
Logistic回归:主要用于因变量为分类变量(如疾病的缓解、不缓解,评比中的好、中、差等)的回归分析,自变量可以为分类变量,也可以为连续变量。
变量为二分类的称为二项logistic回归,因变量为多分类的称为多元logistic回归。Odds:称为比值、比数,是指某事件发生的可能性(概率)与不发生的可能性(概率)之比。OR(OddsRatio):比值比,优势比。
SPSS功能:
一、集数据录入、资料编辑、数据管理、统计分析、报表制作、图形绘制为一体。从理论上说,只要计算机硬盘和内存足够大,SPSS可以处理任意大小的数据文件,无论文件中包含多少个变量,也不论数据中包含多少个案例。
二、统计功能囊括了《教育统计学》中所有的项目,包括常规的集中量数和差异量数、相关分析、回归分析、方差分析、卡方检验、t检验和非参数检验。
参考技术A 1. Logistic回归简介Logistic回归:主要用于因变量为分类变量(如疾病的缓解、不缓解,评比中的好、中、差等)的回归分析,自变量可以为分类变量,也可以为连续变量。因变量为二分类的称为二项logistic回归,因变量为多分类的称为多元logistic回归。
Odds:称为比值、比数,是指某事件发生的可能性(概率)与不发生的可能性(概率)之比。
OR(Odds Ratio):比值比,优势比。
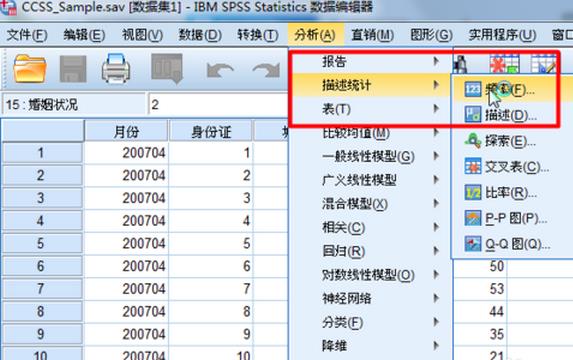
2.SPSS中做Logistic回归的操作步骤
分析>回归>二元Logistic回归
选择因变量和自变量(协变量)
3.结果怎么看
一些指标和数据怎么看
“EXP(B)”即为相应变量的OR值(又叫优势比,比值比),为在其他条件不变的情况下,自变量每改变1个单位,事件的发生比“Odds”的变化率。
伪决定系数cox & Snell R2和Nagelkerke R2,这两个指标从不同角度反映了当前模型中自变量解释了因变量的变异占因变量总变异的比例。但对于Logistic回归而言,通常看到的伪决定系数的大小不像线性回归模型中的决定系数那么大。
预测结果列联表解释,看”分类表“中的数据,提供了2类样本的预测正确率和总的正确率。
建立Logistic回归方程
logit(P)=β0+β1*X1+β2*X2+……+βm*Xm
4.自变量的筛选方法和逐步回归
与线性回归类似,在Logistic回归中应尽量纳入对因变量有影响作用的变量,而将对因变量没有影响或影响较小的变量排除在模型之外。
①.Wald检验:Wals是一个统计量,用检验自变量对因变量是否有影响的。它越大,或者说它对应的sig越小,则影响越显著。
②.似然比检验(Likelihood Ratio
Test):Logistic模型的估计一般是使用极大似然法,即使得模型的似然函数L达到最大值。-2lnL被称为Diviance,记为D。L越大,则D越大,模型预测效果越好。似然比检验是通过比较是否包含某个或几个参数β的多个模型的D值。
③.比分检验(Score Test)
以上三种假设检验中,似然比检验是基于整个模型的拟合情况进行的,结果最为可靠;比分检验结果一般与似然比检验结果一致。最差的就是Wald检验,它考虑各因素的综合作用,当因素间存在共线性的时候,结果不可靠。故在筛选变量时,用Wald法应慎重。
SPSS中提供了六种自变量的筛选方法,向前法(Forward)和向后法(Backward)分别有三种。基于条件参数估计和偏最大似然估计的筛选方法都比较可靠,尤以后者为佳。但基于Wald统计量的检验则不然,它实际上未考虑各因素的综合作用,当因素间存在共线性时,结果不可靠,故应当慎用。
5.模型效果的判断指标
①.对数似然值与伪决定系数
Logistic模型是通过极大似然法求解的,极大似然值实际上也是一个概率,取值在0~1之间。取值为1,代表模型达到完美,此时其对数值为0;似然值越小,则其对数值越负,因此-2倍的对数似然值就可以用来表示模型的拟合效果,其值越小,越接近于0,说明模型拟合效果越好。
②.模型预测正确率
对因变量结局预测的准确程度也可以反映模型的效果,SPSS在Logistic回归过程中会输出包含预测分类结果与原始数据分类结果的列联表,默认是按照概率是否大于0.5进行分割。
③.ROC曲线
ROC曲线即受试者工作特征曲线(Receiver
Operating Characteristic Curve),或译作接受者操作特征曲线。它是一种广泛应用的数据统计方法,1950年应用于雷达信号检测的分析,用于区别“噪声”与“信号”。在对Logistic回归模型拟合效果进行判断时,通过ROC曲线可直接使用模型预测概率进行。应用ROC曲线可帮助研究者确定合理的预测概率分类点,即将预测概率大于(或小于)多少的研究对象判断为阳性结果(或阴性结果)。ROC曲线,预测效果最佳时,曲线应该是从左下角垂直上升至顶,然后水平方向向右延伸到右上角。如果ROC曲线沿着主对角线方向分布,表示分类是机遇造成的,正确分类和错分的概率各为50%,此时该诊断方法完全无效。 参考技术B 你做的什么,怎么这么多变量,自变量要筛选的,p为0.808都在里面,无语了。追问
哦哦 那怎么筛选啊?
追答下面不是有个method(方法),这个就是变量筛选方法。
本回答被提问者和网友采纳 参考技术C 你在瞎做啊,不是这么做的做二元logistic回归遗漏项很多怎么办
参考技术A 可以多尝试不同的变量选择方法,比如glmnet,偏最小二乘,向前向后逐步变量选择,或者先做一步PCA,再用主成分进行logistic回归。最终看下哪个模型的效果好,就选用哪一个模型。1.可以用变量选取,如向前或向后法,然后利用Cross-Validatin或者AIC/BIC,Mallow Cp(若数据服从假设)方法挑出最好的。2.用Lasso或者Ridge Regression这样的Regularization方法调整参数选择模型。最后,可以用PCA先降维,然后再做回归。
以上是关于SPSS二元logistics回归结果分析的主要内容,如果未能解决你的问题,请参考以下文章