初识 Dotnetspider 网络爬虫
Posted DotNet开发跳槽
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了初识 Dotnetspider 网络爬虫相关的知识,希望对你有一定的参考价值。
本文连接:http://www.cnblogs.com/grom/p/8931650.html
最近在做爬虫,之前一直在使用 HttpWebRequest 和 WebClient ,很方便快捷,也很适合新手,但随着抓取任务的增多,多任务,多库等情况的出现,使用一个优秀的爬虫框架是十分必要的。于是开始接触dotnetspider。
借鉴一下框架的设计图,在引入dotnetspider的NuGet包后,我基本也是按照这个进行了分层
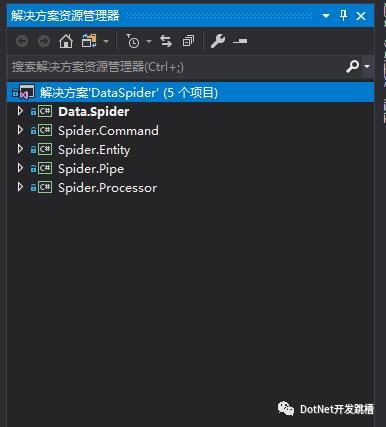
Data.Spider - 存放前台页面(Winform、控制台)和实体爬虫(EntitySpider)、Downloader等,相当于发起请求的起点。
Spider.Processor - 处理器,继承 IPageProcessor 实现对抓取内容的处理
Spider.Pipe - 管道,我将它理解为经过了 Processor 处理后的一个回调,将处理好的数据存储(文件、数据库等)
Spider.Entity - 数据实体类,继承 SpiderEntity
Spider.Command - 一些常用的公用命令,我这目前存放着转数据格式类,后台执行JS类,SqlHelper(因架构自带数据库管道,暂时没用)等
这样的分层也是参考了源码的示例
随着这几天的尝试,真的发现这个框架真的非常灵活,以凹凸租车的爬虫为例,上代码
实体类:
[EntityTable("CarWinsSpider", "AtzucheCar", EntityTable.Today)]
[EntitySelector(Expression = "$.data.content[*]", Type = SelectorType.JsonPath)]
public class AtzucheModel : SpiderEntity
{
}
起始:
/// <summary>
/// 应用程序的主入口点。
/// </summary>
[STAThread]
static void Main()
{
var site = new Site
{
CycleRetryTimes = 1,
SleepTime = 200,
Headers = new Dictionary<string, string>()
{
{"Accept","application/json, text/javascript, */*; q=0.01" },
{"Accept-Encoding","gzip, deflate" },
{"gzip, deflate","zh-CN,zh;q=0.9" },
{"X-Requested-With","XMLHttpRequest" },
{ "Referer", "http://www.atzuche.com/hz/car/search"},
{ "Connection","keep-alive" },
{ "Content-Type","application/json;charset=UTF-8" },
{ "Host","www.atzuche.com"},
{ "User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"}
}
};
List<Request> resList = new List<Request>();
Request res = new Request();
//res.PostBody = $"id=7&j=%7B%22createMan%22%3A%2218273159100%22%2C%22createTime%22%3A1518433690000%2C%22row%22%3A5%2C%22siteUserActivityListId%22%3A8553%2C%22siteUserPageRowModuleId%22%3A84959%2C%22topids%22%3A%22%22%2C%22wherePhase%22%3A%221%22%2C%22wherePreferential%22%3A%220%22%2C%22whereUsertype%22%3A%220%22%7D&page={i}&shopid=83106681";//据说是post请求需要
res.Url = "http://www.atzuche.com/car/searchListMap/2?cityCode=330100&sceneCode=U002&filterCondition%5Blon%5D=120.219294&filterCondition%5Blat%5D=30.259258&filterCondition%5Bseq%5D=4&pageNum=1&pageSize=0";
res.Method = System.Net.Http.HttpMethod.Get;
resList.Add(res);
var spider = DotnetSpider.Core.Spider.Create(site, new QueueDuplicateRemovedScheduler(), new AtzucheProcessor())
.AddStartRequests(resList.ToArray())//页面抓取整理
.AddPipeline(new AtzuchePipe());//数据回调
//----------------------------------
spider.Monitor = new DotnetSpider.Core.Monitor.NLogMonitor();
spider.Downloader = new DotnetSpider.Core.Downloader.HttpClientDownloader();
spider.ClearSchedulerAfterComplete = false;//爬虫结束后不取消调度器
//----------------------------------
spider.ThreadNum = 1;
spider.Run();
Console.WriteLine("Press any key to continue...");
Console.Read();
}
这里也可将整个抓取方法当做一个Spider实例单独放置 -> EntitySpider
/// <summary>
/// 应用程序的主入口点。
/// </summary>
[STAThread]
static void Main()
{
AtzucheEntitySpider dDengEntitySpider = new AtzucheEntitySpider();
dDengEntitySpider.AddPageProcessor(new AtzucheProcessor());//控制器
dDengEntitySpider.AddPipeline(new AtzuchePipe());//回调
dDengEntitySpider.ThreadNum = 1;
dDengEntitySpider.Run();
Console.WriteLine("Press any key to continue...");
Console.Read();
}
新建爬虫实体类
public class AtzucheEntitySpider : EntitySpider
{
protected override void MyInit(params string[] arguments)
{
AddPipeline(new SqlServerEntityPipeline("Server=.;Database=AuzucheSpider;uid=sa;pwd=123;MultipleActiveResultSets=true"));//注意连接字符串中数据库不能带 . 亲测报错。。。
AddStartUrl("http://www.atzuche.com/car/searchListMap/2?cityCode=330100&sceneCode=U002&filterCondition%5Blon%5D=120.219294&filterCondition%5Blat%5D=30.259258&filterCondition%5Bseq%5D=4&pageNum=1&pageSize=0");
AddEntityType<AtzucheModel>();//如添加此实体类,框架将会根据此实体类上面的特性选择进行匹配,匹配成功后插入数据库,固可以省略Processor和Pipe,或者不适用此句,通过控制器和回调自定义存储方法
}
public AtzucheEntitySpider() : base("AuzucheSpider", new Site
{
CycleRetryTimes = 1,
SleepTime = 200,
Headers = new Dictionary<string, string>()
{
{"Accept","application/json, text/javascript, */*; q=0.01" },
{"Accept-Encoding","gzip, deflate" },
{"gzip, deflate","zh-CN,zh;q=0.9" },
{"X-Requested-With","XMLHttpRequest" },
{ "Referer", "http://www.atzuche.com/hz/car/search"},
{ "Connection","keep-alive" },
{ "Content-Type","application/json;charset=UTF-8" },
{ "Host","www.atzuche.com"},
{ "User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36"}
}
})
{
}
}
接下来是处理器:
解析抓取的数据封装到"AtzucheList"内,可Pipe内通过此名称获取处理好的数据。
public class AtzucheProcessor : IPageProcessor
{
public void Process(Page page, ISpider spider)
{
List<AtzucheModel> list = new List<AtzucheModel>();
var html = page.Selectable.JsonPath("$.data.content").GetValue();
list = JsonConvert.DeserializeObject<List<AtzucheModel>>(html);
page.AddResultItem("AtzucheList", list);
}
}
最后是回调,可在此加入保存数据的代码,至此结束。
public class AtzuchePipe : BasePipeline
{
public override void Process(IEnumerable<ResultItems> resultItems, ISpider spider)
{
var result = new List<AtzucheModel>();
foreach (var resultItem in resultItems)
{
Console.WriteLine((resultItem.Results["AtzucheList"] as List<AtzucheModel>).Count);
foreach (var item in (resultItem.Results["AtzucheList"] as List<AtzucheModel>))
{
result.Add(new AtzucheModel()
{
carNo = item.carNo
});
Console.WriteLine($"{item.carNo}:{item.type} ");
}
}
}
}
结果图:
总体来说,此框架对新手还是很友好的,灵活写法可以让我们有较多的方式去实现爬虫,因为这个爬虫比较简单,就先写到这里,未来如果可能,会再尝试使用框架内的多线程、代理等功能,如有心得将继续分享,希望能对跟我一样的新手有所帮助,十分感谢。
以上是关于初识 Dotnetspider 网络爬虫的主要内容,如果未能解决你的问题,请参考以下文章