基于.NET的爬虫应用-DotnetSpider
Posted DotNet
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于.NET的爬虫应用-DotnetSpider相关的知识,希望对你有一定的参考价值。
来源:ITIBB-Shrek
cnblogs.com/sall/p/9031868.html
开源的爬虫框架比较多,之前我研究过java的nutch,同时它还兼备基于Lucene全文检索的功能,还有Python爬虫等等。
为什么我会选择用DotnetSpider呢,我之前有使用.net开发过一套分布式框架,框架的实现机制和DotnetSpider有相似之处,所以上手之后,甚是喜欢。
先看下解决方案的整体分层情况:
InternetSpider:控制台程序,后续可以服务的方式部署在windows环境中
ISee.Shaun.Spiders.Business:爬虫程序的中心调度层,负责爬虫的配置,启动,执行等
ISee.Shaun.Spiders.Common:通用类,包括反射代码、大众点评的数据字典、回调委托的定义等
ISee.Shaun.Spiders.Pipeline:BasePipeline的实现层,主要实现了数据保存
ISee.Shaun.Spiders.Processor:BasePageProcessor的实现层,主要实现了通过xpath的数据提取
ISee.Shaun.Spiders.SpiderModel:数据模型层,负责实体定义和EF数据操作
以爬取大众点评湘菜数据为例,程序的执行过程如下:
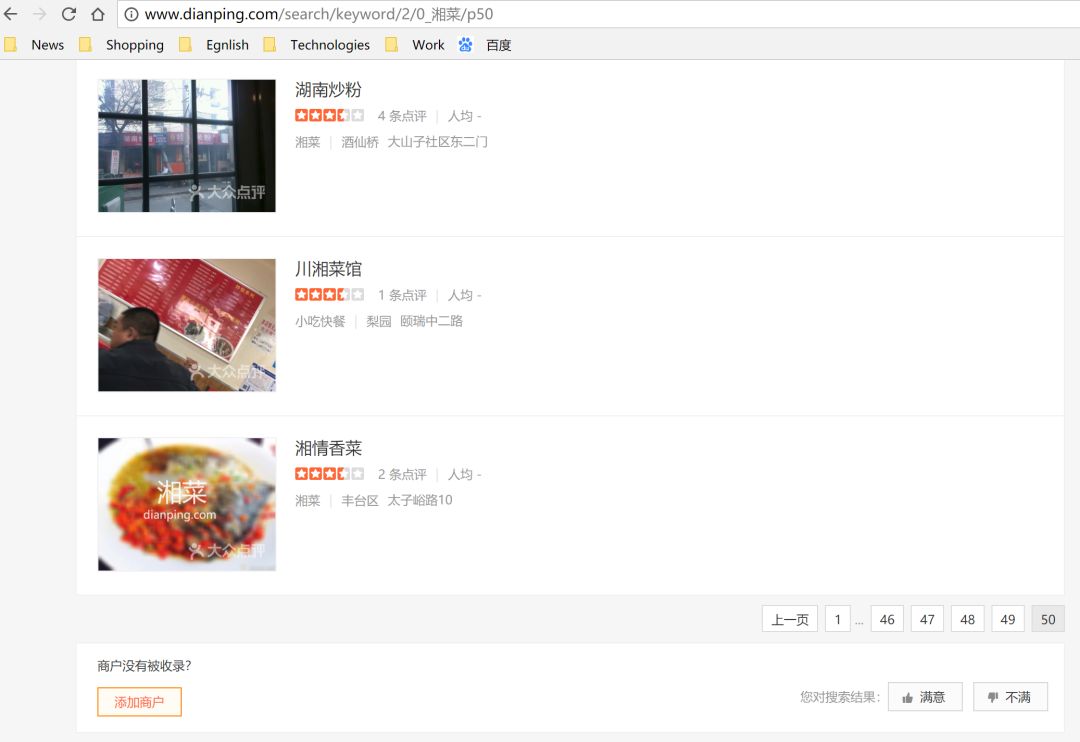
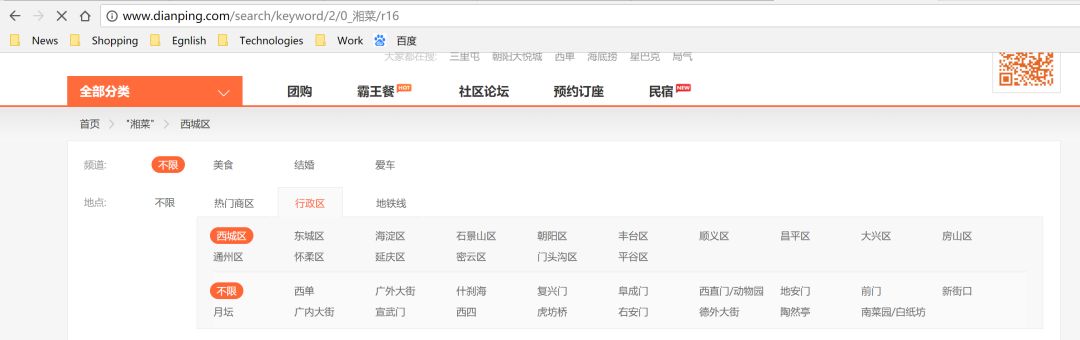
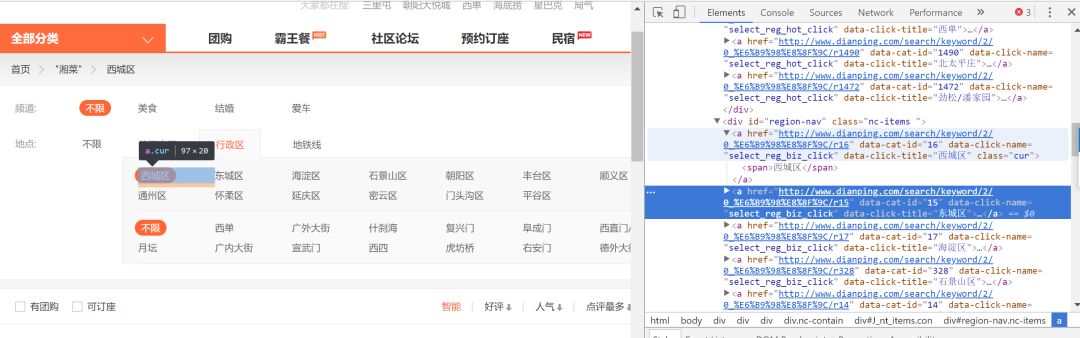
字典直接附上:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace ISee.Shaun.Spiders.Common
{
public static class DazhongdianpingArea
{
private static Dictionary<string, string> areaDic = null;
public static Dictionary<string, string> GetAreaDic()
{
if (areaDic == null)
{
areaDic = new Dictionary<string, string>();
areaDic.Add("r16", "西城区");
areaDic.Add("r15", "东城区");
areaDic.Add("r17", "海淀区");
areaDic.Add("r328", "石景山区");
areaDic.Add("r14", "朝阳区");
areaDic.Add("r20", "丰台区");
areaDic.Add("r9158", "顺义区");
areaDic.Add("r5950", "昌平区");
areaDic.Add("r5952", "大兴区");
areaDic.Add("r9157", "房山区");
areaDic.Add("r5951", "通州区");
areaDic.Add("c4453", "怀柔区");
areaDic.Add("c435", "延庆区");
areaDic.Add("c434", "密云区");
areaDic.Add("c4454", "门头沟区");
areaDic.Add("c4455", "平谷区");
}
return areaDic;
}
}
}
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<configSections>
<!-- For more information on Entity Framework configuration, visit http://go.microsoft.com/fwlink/?LinkID=237468 -->
<section name="entityFramework" type="System.Data.Entity.Internal.ConfigFile.EntityFrameworkSection, EntityFramework, Version=6.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089" requirePermission="false" />
</configSections>
<appSettings>
<add key="WebUrls" value="http://www.dianping.com/search/keyword/2/10_湖南菜/p{0}" />
<add key="WebAreaUrls" value="http://www.dianping.com/search/keyword/2/10_湖南菜/{0}p{1}" />
</appSettings>
<startup>
<supportedRuntime version="v4.0" sku=".NETFramework,Version=v4.6.1" />
</startup>
<connectionStrings>
<!-- 数据库连接字符串 -->
<add name="ConnectionStr" connectionString="data source=.;initial catalog=Membership_Spider;integrated security=True;user id=sa;password=123asd!@#;multipleactiveresultsets=True;" providerName="System.Data.SqlClient" />
</connectionStrings>
<entityFramework>
<defaultConnectionFactory type="System.Data.Entity.Infrastructure.LocalDbConnectionFactory, EntityFramework">
<parameters>
<parameter value="mssqllocaldb" />
</parameters>
</defaultConnectionFactory>
<providers>
<provider invariantName="System.Data.SqlClient" type="System.Data.Entity.SqlServer.SqlProviderServices, EntityFramework.SqlServer" />
</providers>
</entityFramework>
</configuration>
直接调用run方法,开始执行。
using ISee.Shaun.Spiders.Business;
using ISee.Shaun.Spiders.Common;
using System;
using System.Collections.Generic;
using System.Configuration;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace InternetSpider
{
class Program
{
private static string urlInfo = ConfigurationManager.AppSettings["WebUrls"];
private static string urlAreaInfo = ConfigurationManager.AppSettings["WebAreaUrls"];
static void Main(string[] args)
{
Run();
}
/// <summary>
/// Begin spider
/// </summary>
private static void Run()
{
//Add other areaInfo
Dictionary<string, string> areaDic = DazhongdianpingArea.GetAreaDic();
List<string> urls = new List<string>();
foreach (var key in areaDic.Keys)
{
for (int i = 1; i <= 50; i++)
{
urls.Add(string.Format(urlAreaInfo, key, i));
}
}
RunSpider runSpiders = new RunSpider("DazhongdianpingProcessor", "DazhongdianpingPipeline", "UTF-8", true);
runSpiders.Run(urls);
//RunSpider runSpider = new RunSpider("DazhongdianpingProcessor", "DazhongdianpingPipeline", "UTF-8", true);
//runSpider.Run(urlInfo, 50);
}
}
}
关于RunSpider,我不在重复说明,请看代码注释(RunSpider类的主要功能就是方便新任务的开启,或者不通域名下站点的调用,或者说我这里的委托中开启的子页面调用等;反射的使用,便于在后续扩展时,创建批量任务配置文件,自动执行任务才加入的):
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using DotnetSpider.Core;
using DotnetSpider.Core.Downloader;
using DotnetSpider.Core.Pipeline;
using DotnetSpider.Core.Processor;
using DotnetSpider.Core.Scheduler;
using ISee.Shaun.Spiders.Common;
using ISee.Shaun.Spiders.Pipeline;
using ISee.Shaun.Spiders.Processor;
namespace ISee.Shaun.Spiders.Business
{
public class RunSpider
{
private const string ASSEMBLY_PROCESSOR_NAME = "ISee.Shaun.Spiders.Processor";
private const string ASSEMBLY_PIPELINE_NAME = "ISee.Shaun.Spiders.Pipeline";
private BaseProcessor processor = null;
private BasePipeline pipeline = null;
private Site site = null;
private string encoding = string.Empty;
private bool removeOutBound = false;
private int spiderThreadNums = 1;
public int SpiderThreadNums { get => spiderThreadNums; set => spiderThreadNums = value; }
/// <summary>
/// Constructor
/// </summary>
/// <param name="processorName"></param>
/// <param name="pipeLineName"></param>
public RunSpider(string processorName, string pipeLineName, string encoding, bool removeOutBound)
{
//通过反射,获取当前处理类
processor = ReflectionInvoke.GetInstance(ASSEMBLY_PROCESSOR_NAME, processorName, null) as BaseProcessor;
//如果需要回写信息,使用当前委托,如这里,继续子页面的抓取调用
processor.InvokeFoodUrls = this.InvokeNext;
pipeline = ReflectionInvoke.GetInstance(ASSEMBLY_PIPELINE_NAME, pipeLineName, null) as BasePipeline;
this.encoding = encoding;
this.removeOutBound = removeOutBound;
}
/// <summary>
/// 执行,按照页号
/// </summary>
/// <param name="urlInfo"></param>
/// <param name="times"></param>
public void Run(string urlInfo, int times)
{
SetSite(encoding, removeOutBound, urlInfo, times);
Run();
}
/// <summary>
/// </summary>
/// <param name="urlList"></param>
public void Run(List<string> urlList)
{
SetSite(encoding, removeOutBound, urlList);
Run();
}
/// <summary>
/// Begin spider
/// </summary>
private void Run()
{
Spider spider = Spider.Create(site, new QueueDuplicateRemovedScheduler(), processor);
spider.AddPipeline(pipeline);
spider.Downloader = new HttpClientDownloader();
spider.ThreadNum = this.spiderThreadNums;
spider.EmptySleepTime = 3000;
spider.Deep = 3;
spider.Run();
}
private void InvokeNext(string processorName, string pipeLineName, List<string> foodUrls)
{
RunSpider runSpider = new RunSpider(processorName, pipeLineName, this.encoding, true);
runSpider.Run(foodUrls);
}
/// <summary>
/// 通过可变页号,设定站点URL
/// </summary>
/// <param name="encoding"></param>
/// <param name="removeOutBound"></param>
/// <param name="urlInfo"></param>
/// <param name="times"></param>
private void SetSite(string encoding, bool removeOutBound, string urlInfo, int times)
{
this.site = new Site { EncodingName = encoding, RemoveOutboundLinks = false };
if (times == 0)
{
this.site.AddStartUrl(urlInfo);
}
else
{
List<string> urls = new List<string>();
for (int i = 1; i <= times; ++i)
{
urls.Add(string.Format(urlInfo, i));
}
this.site.AddStartUrls(urls);
}
}
/// <summary>
/// 通过URL集合设置站点URL
/// </summary>
/// <param name="encoding"></param>
/// <param name="removeOutBound"></param>
/// <param name="urlList"></param>
private void SetSite(string encoding, bool removeOutBound, List<string> urlList)
{
this.site = new Site { EncodingName = encoding, RemoveOutboundLinks = false };
this.site.AddStartUrls(urlList);
}
}
}
关于Processor,我后续会扩展出不通的网站实现类,那么涉及到通用属性等需要进行抽象处理,代码如下:
using DotnetSpider.Core;
using DotnetSpider.Core.Processor;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using static ISee.Shaun.Spiders.Common.DelegeteDefine;
namespace ISee.Shaun.Spiders.Processor
{
public class BaseProcessor : BasePageProcessor
{
protected List<string> foodUrls = null;
public CallbackEventHandler InvokeFoodUrls { get; set; }
protected string SourceWebsite { get; set; }
public BaseProcessor() { foodUrls = new List<string>(); }
protected override void Handle(Page page)
{
throw new NotImplementedException();
}
protected virtual void InvokeCallback(string processorName, string pipeLineName)
{
if (InvokeFoodUrls != null && this.foodUrls.Count > 0)
{
InvokeFoodUrls(processorName, pipeLineName, this.foodUrls);
}
}
}
}
接下来看具体的实现类(关于xpath不在多加说明,网上资料很多,如果结构不清楚,可以使用谷歌的开发者工具,或者在调试中,拿到html结构,自行分析,本文不再增加次类演示截图):
using DotnetSpider.Core;
using DotnetSpider.Core.Processor;
using DotnetSpider.Core.Selector;
using ISee.Shaun.Spiders.Common;
using ISee.Shaun.Spiders.SpiderModel.Model;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using static ISee.Shaun.Spiders.Common.DelegeteDefine;
namespace ISee.Shaun.Spiders.Processor
{
public class DazhongdianpingProcessor : BaseProcessor
{
public DazhongdianpingProcessor() : base()
{
//标记当前数据来源
SourceWebsite = "大众点评";
}
/// <summary>
/// 重新父类方法,开始执行数据获取操作
/// </summary>
/// <param name="page"></param>
protected override void Handle(Page page)
{
// 利用 Selectable 查询并构造自己想要的数据对象
var totalVideoElements = page.Selectable.SelectList(Selectors.XPath(".//div[@class='shop-list J_shop-list shop-all-list']/ul/li")).Nodes();
if (totalVideoElements == null)
{
return;
}
//定义需处理数据集合
List<Restaurant> restaurantList = new List<Restaurant>();
foreach (var restElement in totalVideoElements)
{
var restaurant = new Restaurant() { SourceWebsite = SourceWebsite };
//下面通过xpath开始获取餐厅信息
restaurant.Name = restElement.Select(Selectors.XPath(".//h4")).GetValue();
var price= restElement.Select(Selectors.XPath(".//div[@class='txt']/div/a[@class='mean-price']/b")).GetValue();
restaurant.AveragePrice = string.IsNullOrEmpty(price) ? "0" : price.Replace("¥","");
restaurant.Type = restElement.Select(Selectors.XPath(".//div[@class='txt']/div[@class='tag-addr']/a/span[@class='tag']")).GetValue();
restaurant.Star = restElement.Select(Selectors.XPath(".//div[@class='txt']/div[@class='comment']/span/@title")).GetValue();
restaurant.ImageUrl = restElement.Select(Selectors.XPath(".//div[@class='pic']/a/img/@src")).GetValue();
var areaCode = page.Url.Substring(page.Url.LastIndexOf('/')+1);
if (!string.IsNullOrEmpty(areaCode) && (areaCode.Contains("r")|| areaCode.Contains("c")))
{
Dictionary<string, string> areaDic = DazhongdianpingArea.GetAreaDic();
string result= areaCode.Substring(0, areaCode.IndexOf('p'));
if (areaDic.ContainsKey(result))
{
restaurant.Area = areaDic[result];
}
}
List<ISelectable> infoList = restElement.SelectList(Selectors.XPath("./div[@class='txt']/span[@class='comment-list']/span/b")).Nodes() as List<ISelectable>;
if (infoList != null && infoList.Count > 0)
{
var result = infoList[0].GetValue();
restaurant.Taste = string.IsNullOrEmpty(result) ? string.Empty : result;
result = infoList[1].GetValue();
restaurant.Environment = string.IsNullOrEmpty(result) ? string.Empty : result;
result = infoList[2].GetValue();
restaurant.ServiceScore = string.IsNullOrEmpty(result) ? string.Empty : result;
}
var recommetList = restElement.SelectList(Selectors.XPath(".//div[@class='txt']/div[@class='recommend']/a")).Nodes();
restaurant.Recommendation = string.Join(",", recommetList.Select(o => o.GetValue()));
restaurant.Address = restElement.Select(Selectors.XPath(".//div[@class='txt']/div[@class='tag-addr']/span")).GetValue();
restaurant.Position= restElement.Select(Selectors.XPath(".//div[@class='txt']/div[@class='tag-addr']/a[@data-click-name='shop_tag_region_click']/span[@class='tag']")).GetValue();
var shopUrl = restElement.Select(Selectors.XPath(".//div[@class='txt']/div/a/@href")).GetValue();
restaurant.Code = shopUrl.Substring(shopUrl.LastIndexOf('/') + 1);
restaurantList.Add(restaurant);
//add next links
if (!string.IsNullOrEmpty(shopUrl))
{
this.foodUrls.Add(shopUrl);
}
}
// 如果进行二级爬虫,取消注释,并且实现对应的两个类
//InvokeCallback("DazhongdianpingFoodProcessor", "DazhongdianpingFoodPipeline");
// Save data object by key. 以自定义KEY存入page对象中供Pipeline调用
page.AddResultItem("RestaurantList", restaurantList);
}
}
}
数据实体的定义:
using System;
using System.Collections.Generic;
using System.ComponentModel.DataAnnotations;
using System.ComponentModel.DataAnnotations.Schema;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace ISee.Shaun.Spiders.SpiderModel.Model
{
public class FoodInfo
{
[Key]
public int Id { get; set; }
public int RestaurantId { get; set; }
public string Code { get; set; }
public string RestaurantCode { get; set; }
public string Name { get; set; }
public string Price { get; set; }
public string FoodImageUrl { get; set; }
[ForeignKey("RestaurantId")]
public Restaurant restaurant { get; set; }
}
}
数据获取下来之后,爬虫会自动将任务分配给pipeline来处理收集到的数据信息,直接上代码:
using DotnetSpider.Core;
using DotnetSpider.Core.Pipeline;
using ISee.Shaun.Spiders.SpiderModel.Model;
using ISee.Shaun.Spiders.SpiderModel;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace ISee.Shaun.Spiders.Pipeline
{
public class DazhongdianpingPipeline : BasePipeline
{
/// <summary>
/// 处理餐厅信息
/// </summary>
/// <param name="resultItems"></param>
/// <param name="spider"></param>
public override void Process(IEnumerable<ResultItems> resultItems, ISpider spider)
{
//便利结果集
foreach (ResultItems entry in resultItems)
{
//定义EF实体
using (var rEntity = new FoodInfoEntity())
{
List<Restaurant> resList = new List<Restaurant>();
foreach (Restaurant result in entry.Results["RestaurantList"])
{
var resultList = rEntity.RestaurantInfo.Where(o => o.Name == result.Name && o.Address == result.Address).ToList();
if (resultList.Count == 0)
{
resList.Add(result);
}
}
if (resList.Count > 0)
{
rEntity.RestaurantInfo.AddRange(resList);
rEntity.SaveChanges();
}
}
}
}
}
}
好了,整体下来,就是这样简单,当然我还要强调一下几个问题:
1、如果需要对大量的页面进行数据爬取,可增加额外的xml配置文件,来定义抓取的规则或者任务。(不再细说,如有疑问可留言交流)
2、如果要完成比如美团网等网站的扩展,在Processor和Pipeline分别实现对应的类即可
3、关于数据实体,我采用了EF的Code first方式,大家可以随意扩展自己想要的方式,或者更换数据库等,请参阅网上大量的关于EF的文章。
看完本文有收获?请转发分享给更多人
关注「DotNet」,提升.Net技能
淘口令:复制以下红色内容,再打开手淘即可购买
范品社,使用¥极客T恤¥抢先预览(长按复制整段文案,打开手机淘宝即可进入活动内容)
以上是关于基于.NET的爬虫应用-DotnetSpider的主要内容,如果未能解决你的问题,请参考以下文章