如何使用优秀的性能测试工具Locust?我们找了大神来做实战演示!忍不住收藏!
Posted 51Testing软件测试网
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何使用优秀的性能测试工具Locust?我们找了大神来做实战演示!忍不住收藏!相关的知识,希望对你有一定的参考价值。

APP的性能测试,对于服务端的压力其实和Web差别不大,通过JMeter/Loadrunner进行服务器的并发请求即可完成。
基于Python协程的Locust是一款优秀的性能测试工具,单机并发量远超于JMeter和Loadrunner。本文通过实例介绍Locust的使用,通过解决产品开发中的实际问题作为Locust实战的说明,最后结合该实例总结Locust的使用方法,为其他需要使用Locust的工程师提供思路。
Locust是一款开源的Web性能测试框架。该单词的原意是蝗虫,原作者之所以选择这个名字,估计也是听过这么一句俗语,“蝗虫过境,寸草不生”。
Locust工具生成的并发请求就跟一大群蝗虫一样,对我们的被测系统发起攻击,以此检测系统在高并发压力下是否能正常运转。在Locust测试框架中,测试场景是采用纯Python脚本进行描述的。对于最常见的HTTP(S)协议的系统,Locust采用Python的requests库作为客户端,使得脚本编写大大简化,富有表现力的同时且极具美感。而对于其它协议类型的系统,Locust也提供了接口,只要我们能采用Python编写对应的请求客户端,就能方便地采用Locust实现压力测试。从这个角度来说,Locust可以用于压测任意类型的系统。
主要特点如下:
1、使用纯粹的Python编写脚本。
用Locust就是写Python代码,这点比其他性能测试工具要先进。事实上界面点击代替编程,本身就是伪命题。不会编程的用不好JMeter,会编程的更喜欢写纯粹的代码。
2、单机可支持千级并发压力,且支持分布式。
Locust采用协程并发,单机比LoadRunner、JMeter的并发都会高很多。JMeter一个并发用户一个线程,当用户变多时,本身的性能会急剧下降。
3、Web管理界面。
内嵌的Web服务,并且支持扩展。
4、可以测试任何系统。
基于协议,通过协议模拟,可尝试任何系统。
5、简单耐玩。
Locust核心代码只有几百行,简单。扩展性强,有很强的二次开发属性,耐玩性很高。
关于Locust下载、安装和运行Demo测试的方法,可以参考官网的示例,以及网络上其他的信息。下面以一个实际的例子说明如何使用Locust进行并发测试。
需求说明:测试的App是面向C端客户的理财类软件,目前上线一个类似红包的空投优惠卷拉新活动,通过红包的发放宣传App。现在需要测试并发抢该优惠卷红包,是否存在问题。
需求分析:并发抢红包,在不考虑服务器并发性能的基础上,需求很简单,就是确认在并发的过程中,一个用户只能抢一次,红包不能被多抢。
3.1抓包确定接口逻辑
由于Locust使用接口进行并发请求发送,所以需要确定需要对哪个接口进行并发,以及如何串联整个场景。
App和服务器的抓包可以使用Fiddler进行。
PC端安装Fiddler,之后在菜单栏选择->Tools->Options->Connections,设置监听断开,默认为8888。
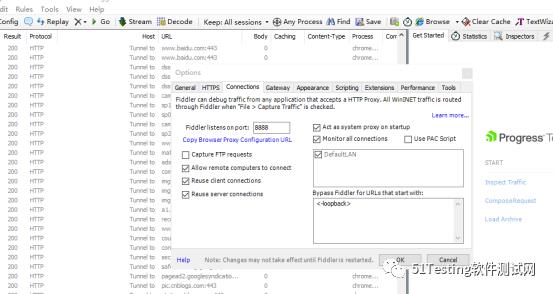
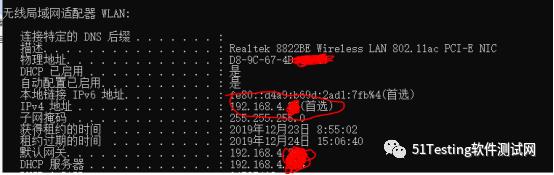
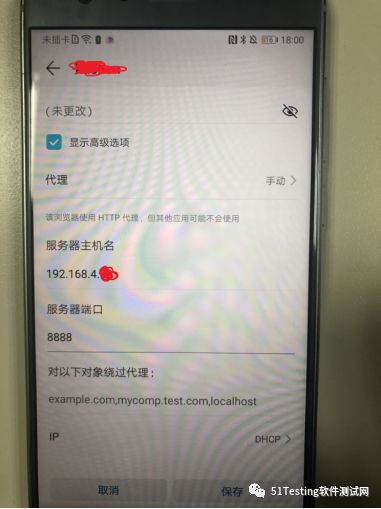
之后将App所在的手机连接同一Wi-Fi,并设置代理为上述IP和端口(默认8888)。
之后通过App操作的请求就可以在Fiddler上抓到包了。
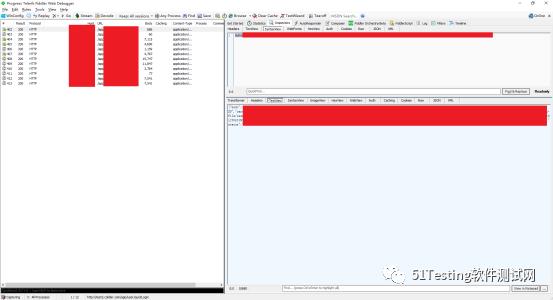
通过抓包可以确定如下流程:
1、发红包:登录-获取验证码-发红包请求。
2、抢红包:(1步获得红包分享链接)抢红包。
上述需要测试并发的就是2中抢红包的接口。
3.2编写脚本:获取红包链接
对照Locust官网的示例,我们知道Locust是通过单纯的Python脚本表达并发测试的过程。在一次并发测试中,每个用户就是一个Locust的实例,按照既定的流程进行测试。其含义就是指定的如此多的Locust,在系统中以随机又符合程序设定的方式进行测试。

上述示例表达将要对系统的根目录“/”和“/profile”进行访问,每次访问随机在5到9秒之间发起,每发起两次根目录访问,发起一次“/profile”访问。on_start和on_stop是对TaskSet的初始化和清理,类似TestNG中的BeforeClass和AfterClass。(之所以不是BeforeSuite和AfterSuite,是因为Locust还有整体的setup和teardown函数)。
获取红包链接虽然不需要并发,但是通过接口访问的方式能够更快速的获得链接,节省了手工点击的时间。通过对Locust示例的改造,实现如下。
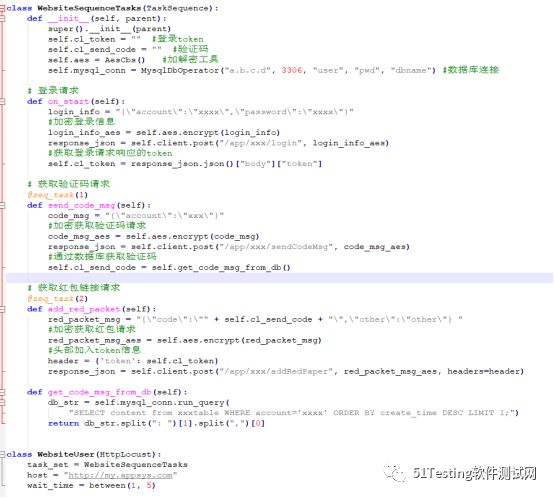
在官方示例中,增加了如下变化:
1)token获取和使用。App与后端的交互,在第一次登录后,后续请求都在请求头部增加token信息,表明链接的有效性。这里首先在on_start请求中通过用户名和密码方式登录接口,之后将返回体中的token字段获取,保存在成员变量cl_token中。在需要填入token的时候,如add_red_packet函数中,通过header的设定,放入请求中。
2)加解密的调用。为安全考虑,目前的App与后端交互的信息都是加密的,所以实现了加解密的工具类:AesCbs。在使用加解密的地方调用对应函数,如登录接口中,设定登录信息的JSON后,调用AesCbs的encrypt函数完成加密。
3)数据库的操作。这里是对mysql数据库的操作,请求验证码后,后续操作需要自动完成,不可能查阅手机记录。通过查询数据库的方式达成目的。MysqlDbOperator类是数据库工具类,完成数据库的连接,执行SQL语句等功能,在函数get_code_msg_from_db中调用工具类,查询得到结果,由于验证码是一串字符,在其中根据格式截取验证码。
4)seq_task的使用。另一个变化是@seq_task装饰器的使用,官网示例中的@task装饰器的请求,请求次数与其括号后面的权重有关,但顺序是随机的,如果想要请求按既定顺序执行,就需要使用@seq_task装饰器。这里实现的就是首先登录(on_start),之后执行获取验证码(send_code_msg),最后执行获取红包链接(add_red_packet)。
通过上述实现后,就可以直接访问后端接口,获取红包的分享链接。
3.3编写脚本:并发抢红包
通过上面的讲解,我们直接给出并发抢红包的脚本实现。
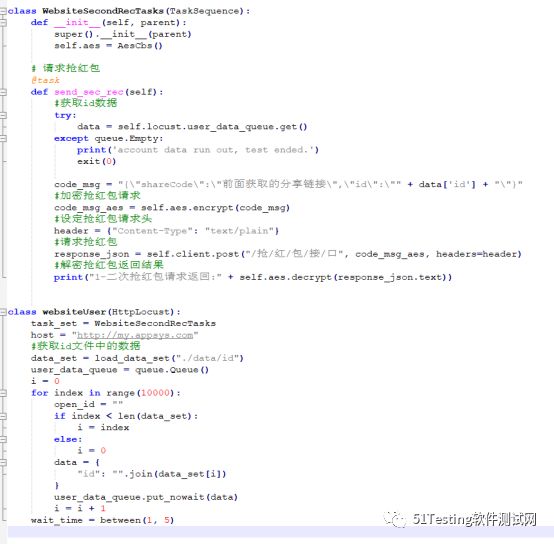
对比之前的脚本,这里增加了一个变化:在数据文件中获取id变量,作为每个Locust实例中的请求参数。
在websetUser类中(该类为HttpLocust的子类,所有Locust请求都是该类的子类),通过访问数据文件“./data/id”获取id的数据,该文件格式如下:
脚本中循环读取内容,放入队列中共后续使用。在抢红包请求send_sec_rec函数中,读取队列中的数据,为该用户抢红包。
3.4发起测试
通过如下命令,获取红包分享链接。

获取后设定抢红包的链接为该分享链接,之后运行抢红包的Locust文件。

在Web管理界面中设定并发数目。
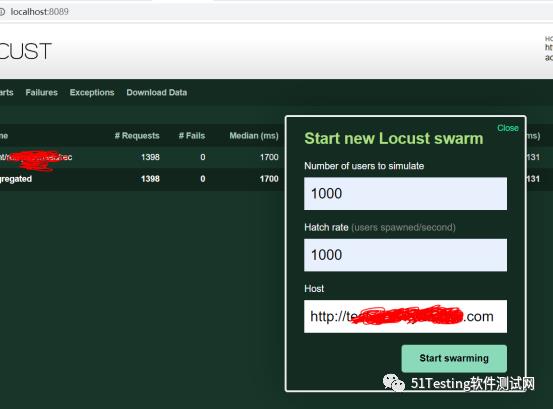
完成并发的测试,查看打印日志、后台流水等确定并发抢红包的结果。
总体说来,Locust通过纯Python编写压力测试脚本,而Locust框架提供了底层的API帮我们解决请求、并发、统计等问题。工程师需要做的是通过对业务的梳理,设计压力测试的场景,串联业务逻辑,之后通过Locust的API完成程序编写。
Locust支持的特性总结如下。
4.1Locust类
Locust是请求类。所有的HTTP并发请求都继承Locust的HttpLocust类,该类是Locust类的子类。
就像之前说明的一样,Locust类就是模拟的一个一个用户,类比如蝗虫在系统中进行冲击。在Locust类中,具有一个client属性,它对应着虚拟用户作为客户端所具备的请求能力,也就是我们常说的请求方法。通常情况下,我们不会直接使用Locust类,因为其client属性没有绑定任何方法。因此在使用Locust时,需要先继承Locust类,然后在继承子类中的client属性中绑定客户端的实现类。实际上Locust有一些实现子类。
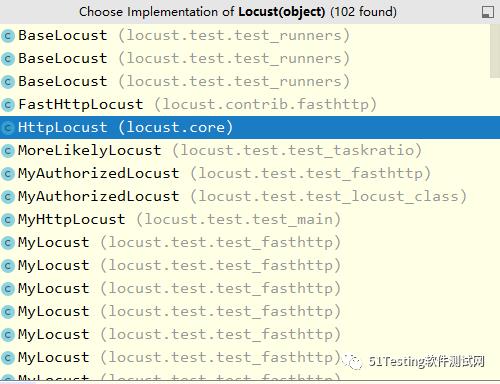
其中HttpLocust子类实现了常见的HTTP(S)协议,其client属性绑定了HttpSession类,而HttpSession又继承自requests.Session。因此在测试HTTP(S)的Locust脚本中,我们可以通过client属性来使用Python requests库的所有方法,包括GET/POST/HEAD/PUT/DELETE/PATCH等,调用方式也与requests完全一致。另外,由于requests.Session的使用,因此client的方法调用之间就自动具有了状态记忆的功能。常见的场景就是,在登录系统后可以维持登录状态的Session,从而后续HTTP请求操作都能带上登录态。当然也可以利用header的设置传递token等需要的信息。
一个Locust文件是一个或多个蝗虫的范本,可以定义多个继承于HttpLocust(或者说Locust)的Locust类,通过权重(weight)属性区别蝗虫的实例比例。如果不设定,则按照1:1的方式进行实例化。
而对于HTTP(S)以外的协议,我们同样可以使用Locust进行测试,只是需要我们自行实现客户端。在客户端的具体实现上,可通过注册事件的方式,在请求成功时触发events.request_success,在请求失败时触发events.request_failure即可。然后创建一个继承自Locust类的类,对其设置一个client属性并与我们实现的客户端进行绑定。后续,我们就可以像使用HttpLocust类一样,测试其它协议类型的系统。
在Locust类中,除了client属性,还有几个属性需要关注下:
otask_set: 指向一个TaskSet类,TaskSet类定义了用户的任务信息,该属性为必填;
owait_time: 每个用户执行两个任务间隔时间的上下限(秒,支持小数),具体数值在上下限中随机取值,若不指定则默认间隔时间固定为1秒;
ohost:被测系统的host,当在终端中启动locust时没有指定--host参数时才会用到;
oweight:同时运行多个Locust类时会用到,用于控制不同类型任务的执行权重。
以获取红包验证码的脚本为例,测试开始后,每个虚拟用户(Locust实例)的运行逻辑都会遵循如下规律:
1)先执行WebsiteSequenceTasks中的on_start(只执行一次),作为初始化;
2)按照WebsiteSequenceTasks设定的@seq_task顺序执行每个任务,如果以@task装饰器设定,则随机挑选(如果定义了任务间的权重关系,那么就是按照权重关系随机挑选)一个任务执行;
3)根据Locust类WebsiteUser中wait_time = between(1, 5)定义的间隔时间范围(如果TaskSet类中也定义了min_wait或者max_wait,以TaskSet中的优先),在时间范围中随机取一个值,休眠等待;
4)重复2~3步骤,直至测试任务终止。
4.2TaskSet类
TaskSet是请求任务类。如果说Locust类代表了一群冲击系统的蝗虫,那么请求任务类TaskSet就是这些蝗虫的冲击计划,官网的说法是“大脑”(brain)。
具体地,TaskSet类实现了并发用户所执行任务的调度算法,包括规划任务执行顺序(schedule_task)、挑选下一个任务(execute_next_task)、执行任务(execute_task)、休眠等待(wait)、中断控制(interrupt)等等。在此基础上,我们就可以在TaskSet子类中采用非常简洁的方式来描述虚拟用户的业务测试场景,对虚拟用户的所有行为(任务)进行组织和描述,并可以对不同任务的权重进行配置。
有两种方式声明TaskSet,使用@task装饰器和配置TaskSet类的tasks属性。

上述示例中,使用@task定义了TaskSet类的两个执行任务,并且通过括号中的weight属性对执行量进行了设定:task2的执行量是task1的两倍。
使用@task装饰器是推荐的做法,这样代码更为清晰,当然也可以通过tasks属性来定义TaskSet执行的任务,实际上@task装饰器就是设置task属性的实现。
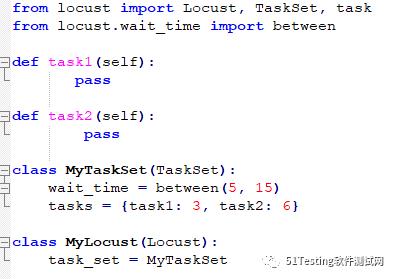
上述代码实现的功能与@task装饰器的功能一致。
TaskSet类支持嵌套定义,从而更便捷的对分层构建的网站设计模拟用户的行为。
之前我们使用的TaskSequence是按序请求类。上面介绍的项目实例中,抢红包我们使用的是TaskSequence,它也是TaskSet的子类。但其任务将按顺序执行。

上面的示例中,首先执行first_task一次,之后执行second_task一次,最后执行third_task十次。从这里也可以看出,@seq_task和@task装饰器可以组合使用,还可以将TaskSet嵌套在TaskSequences中,当然也可以反过来嵌套。
4.3环境设置和恢复类
通过setup、teardown、on_start、on_stop可以完成Locust并发测试环境设置和恢复。
Setup和teardown在一次测试中只会执行一次。Setup在所有任务开始运行之前运行,teardown在所有任务完成并在Locust退出之后运行。类似于TestNG的BeforeSuite和AfterSuite,这样可以利用这两个函数完成一些环境设置(如连接数据库),并在最后进行环境清理(如关闭数据库)。
on_start和on_stop函数,当对应的TaskSet任务执行时调用on_start方法,该TaskSet停止时调用on_stop方法。每运行一次调用一次。类似于TestNG的BeforeClass和AfterClass。典型的on_start用法是登录请求放在该函数中。
4.4参数关联
通过参数关联完成请求间的参数传递。
请求间的参数传递是并发测试中的必要需求,最典型的就是登录状态,如本例中的token传递。LoadRunner使用web_reg_save_param进行请求的参数提取,JMeter使用参数定义,也可以使用自带的vars字典进行参数存储和获取。Locust是纯Python脚本的编写,所以可以调用任意的Python库进行参数关联。
在本例中,我们在on_start函数中利用返回JSON内容提取的方式将token存储在self.cl_token中,在后续需要使用该参数的地方直接调用该参数。其他的情况都可以通过Python程序编写的方式完成参数关联。
4.5参数化
参数化设定并发测试的初始参数。
在并发初始前,设定测试的参数,最典型的就是登录的用户和密码。LoadRunner利用Parameter List进行参数化,支持界面配置和外部文件。JMeter有著名的CSV Data Config。与参数关联一样,通过Python脚本编写完成。
在本例中,我们抢红包的ID是需要参数化的,将参数存储在id配置文件中(格式见上),利用load_data_set函数完成该配置数据的读取,并放入队列中。在请求中直接完成调用。
4.6检查点
通过Python自带的assert实现断言。
通过Python脚本编程,完成需要断言数据的提取,之后使用assert进行判断。
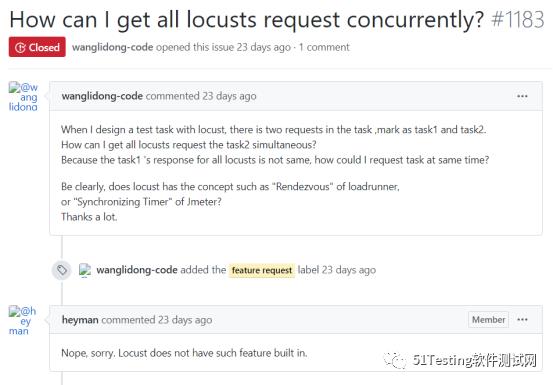
4.7集合点
Locust不支持集合点的设置。
Locust框架并不支持集合点的设置,没有类似于LoadRunner的Rendezvous和JMeter的同步定时器的特性。
4.8分布式运行
通过分布式运行提高性能测试的并发量。
当单台计算机不足以模拟所需的用户数量时,通过分布式运行Locust,利用多台计算机提高负载。
Locust采用主从模式进行分布式运行,这点和JMeter的分布式很类似。在其中一台负载测试机采用--master参数运行Locust,其他负载机使用--slave确定自己的身份,并使用--master-host指定从属于那个主节点。
下面的例子是通过多个进程运行Locust的方法, 分布式运行的方法与之一致。
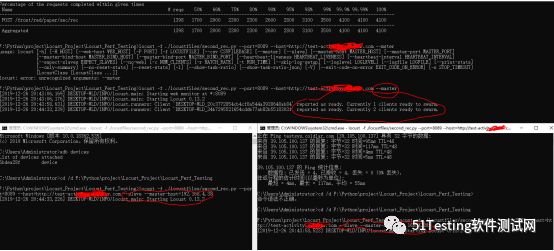
当我们打开Locust的Web管理界面是,也会看到Slave的个数为2。
4.9典型工程设计
通过更清晰的工程设计,提高Locust工程的可读性。。
由于纯Python编程,可以使用各种工程组织方式,如平面化的文件排布。
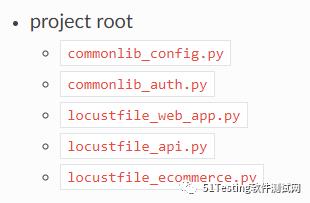
以Locustfile开头的是Locust请求类,其他的为通用函数,类似于本例中的加解密、数据连接等。这样的设计缺点是不能将普通的库文件和Locust文件分开,不利于管理。通过分目录管理的方式,会使得工程更清晰,比如下面的设计。
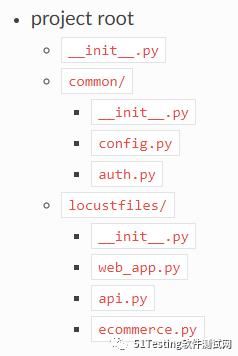
需要注意的是,由于Locust只会导入相对于运行的Locust文件所在路径下的模块,所以需要导入工程根目录的模块(比如在根目录下运行Locust测试),我们需要在Locust文件中使用“sys.path.append(os.getcwd())”来导入其他库文件。这样就可以确保根目录下的模块可以引用了。本例中我们采用类似的方式组织Locust工程。


点击阅读☞
点击阅读☞
点击阅读☞
点击阅读☞
点击阅读☞
以上是关于如何使用优秀的性能测试工具Locust?我们找了大神来做实战演示!忍不住收藏!的主要内容,如果未能解决你的问题,请参考以下文章