推荐算法之FFM:原理及实现简介
Posted 机器决策
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐算法之FFM:原理及实现简介相关的知识,希望对你有一定的参考价值。
推荐系统一般可以分成两个模块,检索和排序。比如对于电影推荐,检索模块会针对用户生成一个推荐电影列表,而排序模块则负责对这个电影列表根据用户的兴趣做排序。当把FFM算法应用到推荐系统中时,具体地是应用在排序模块。
FFM算法,全称是Field-aware Factorization Machines,是FM(Factorization Machines)的改进版。这个改进原理上比较简单,所以我想先把FM讲清楚。
我们知道推荐算法中,最广为人知的是协同过滤算法,协同过滤一般分为基于用户的协同过滤和基于物品的协同过滤,而除此之外,还有基于隐语义的协同过滤。我们来考虑一个电影评分的问题,用户对于电影的评分,可以构成一个评分矩阵M,这个矩阵是稀疏的,因为每个用户看过的电影都是有限的,这个矩阵里面会有很多缺失项,我们要做的便是将这个稀疏矩阵填满,我们可以怎么做呢?想象一个兴趣空间,这个空间里面有多个维度,维度一表示悬疑类型,维度二表示言情类型,等等。那么用户的兴趣可以表达为这个空间里的一个向量,而电影本身的特点也可以用这个空间里的向量表达,于是用户对电影的评分可以用内积来表示。通过这个方式,我们便可以对这个评分矩阵做矩阵分解:
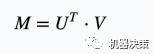
其中U是用户在隐语义空间对应的向量组成的矩阵,而V则是电影对应的矩阵。求解这个矩阵分解问题对应的优化问题是这样:
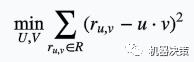
其中R是用户对电影的评分的集合,ru,v即表示用户对电影的评分。这里为了方便省略了正则项。通过求解这个优化问题,得到矩阵U和V,于是对于ru’,v’ not_in R,可以通过u'·v'得到。也就是说这个隐语义模型具有很好的泛化能力,可以对没有出现的用户对电影的评分做出比较准确的预测。
我们来看一下广泛应用在排序场景里的逻辑回归,先假设学习目标是点击与否,为了学习出不同特征之间的关联,逻辑回归的使用中往往会引入高阶特征。比如说(性别+手机品牌)对点击率的影响,通过引入(性别+手机品牌)的二阶特征,模型可以学习到不同性别与不同手机品牌的组合对点击率的影响。但如果训练样本中没有出现(女性+锤子),模型也就无法学习到(女性+锤子)的权重。那么如果说我就是想知道(女性+锤子)的权重呢?考虑上面的隐语义模型,如果我们把女性和锤子这些特征映射到隐语义空间,通过学习女性和锤子各自对应的向量,就可以用这两个向量的内积得到这个权重。这样尝试就得到了FM。
逻辑回归模型可以写成:
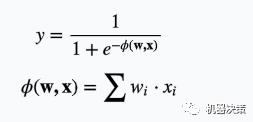
其中wi为xi对应的权重。将上面的Φ(w,x)改写为:
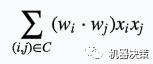
就得到了FM模型,其中wi为特征xi所对应的隐语义空间的向量,C则是二阶交叉特征的组合。隐语义空间的维度是一个超参数,用k表示。这里省略了一阶项和正则项。
FM模型相对于逻辑回归有了更好的泛化能力,可以学习出训练样本中没有的交叉特征的权重。而另一方面,在性能上也有很好的表现,使用逻辑回归的时候,对于有N个特征的情况,所有二阶特征对应的参数数量是N2(当然一般也没人会取遍所有二阶组合),而FM模型对应的参数总数只有Nk,一般地k<100<<N。
接下来,我们看下使用逻辑回归时特征处理的过程。对于分类特征,会做热独编码。比如手机品牌有华为小米苹果等等,那么当用户手机品牌为华为时,特征可以表示为{fea_mobile_huawei=1,fea_mobile_xiaomi=0, fea_mobile_apple=0…….}这样的形式。那么这样处理之后,fea_mobile_huawei可以称为特征(feature),而对于手机品牌在热独编码后对应的多个特征,可以称为域(field)。回头看一下基于隐语义的协同过滤模型,里面实际可以看做是涉及了两个域,即用户域和电影域,这个模型只涉及了两个域的互作用。对于FM模型呢,每个向量都是同时跟多个域互作用,比如手机品牌会同时跟用户的性别、推荐的商品等等域互作用。FFM算法的作者认为,两个域之间的互作用应该独立出来,也就是手机品牌跟用户性别互作用有一个对应的向量,而跟推荐的商品互作用时也有一个对应的向量,这也就是所谓的field-aware。FFM模型可以通过修改上面的Φ(w,x)得到,于是FFM模型的优化问题可以完整写出:
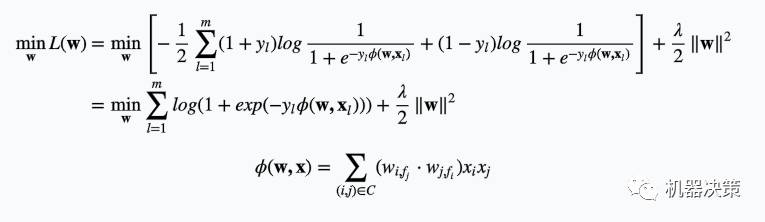 其中wi,f_j即xi与field=j的特征互作用时对应的向量,yl取值为{-1,1}。
其中wi,f_j即xi与field=j的特征互作用时对应的向量,yl取值为{-1,1}。
最后,来聊聊实现。将FFM发扬光大的台大团队提供了一个libffm实现,是一个单机版本的并行实现。其优化算法,无他,唯Stochastic-Gradient Dencent而已,对算法细节感兴趣的详见[1]。而其并行算法则有点意思。其实现使用了并行算法Hog-Wild!,这名字一看就很酷炫。这个算法说的是,对于大部分机器学习问题,往往一个训练样本所涉及的参数只是整个参数集的一小部分。那么把这一点作为基础的话,在多核环境下,开启多个线程,每个线程根据不同的训练样本同时对参数集进行优化,是没有问题的,更新的参数发生冲突的几率很低,即使冲突了,也没多大事。这个并行算法的伪代码见下图。

至于FFM的分布式实现,下回再聊。
最后致谢神秘的审稿人谢。
[1] Juan et. al. (2016) Field-aware Factorization Machines for CTR Prediction
VIP专区
以上是关于推荐算法之FFM:原理及实现简介的主要内容,如果未能解决你的问题,请参考以下文章