互联网的常见推荐算法
Posted 孜孜视角
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了互联网的常见推荐算法相关的知识,希望对你有一定的参考价值。
一、《》
什么是协同过滤
协同过滤的3步骤
一张excel表格,秒懂协同过滤
二、《》
什么是基于内容的推荐
基于内容的推荐的3步骤
明明职位要求6000+,为啥会出3000+的推荐结果
三、《》
没有用户行为数据,能不能做电影推荐
相似度推荐的简易原理与实现
如何计算《我不是潘金莲》与《芳华》的距离
工程架构方向的程序员,看到推荐/搜索/广告等和算法相关的技术,心中或多或少有一丝胆怯。但认真研究之后,发现其实没有这么难。
今天的1分钟系列,给大家介绍下推荐系统中的“协同过滤”,绝无任何公式,保证大伙弄懂。
什么是协同过滤(Collaborative Filtering)?
答:通过找到兴趣相投,或者有共同经验的群体,来向用户推荐感兴趣的信息。
举例,如何协同过滤,来对用户A进行电影推荐?
答:简要步骤如下
找到用户A(user_id_1)的兴趣爱好
找到与用户A(user_id_1)具有相同电影兴趣爱好的用户群体集合Set<user_id>
找到该群体喜欢的电影集合Set<movie_id>
将这些电影Set<Movie_id>推荐给用户A(user_id_1)
具体实施步骤如何?
答:简要步骤如下
(1)画一个大表格,横坐标是所有的movie_id,纵坐标所有的user_id,交叉处代表这个用户喜爱这部电影
如上表:
横坐标,假设有10w部电影,所以横坐标有10w个movie_id,数据来源自数据库
纵坐标,假设有100w个用户,所以纵坐标有100w个user_id,数据也来自数据库
交叉处,“1”代表用户喜爱这部电影,数据来自日志
画外音:什么是“喜欢”,需要人为定义,例如浏览过,查找过,点赞过,反正日志里有这些数据
(2)找到用户A(user_id_1)的兴趣爱好
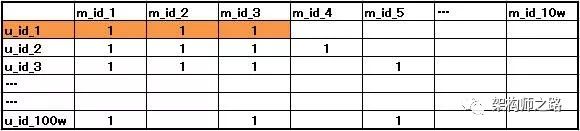
如上表,可以看到,用户A喜欢电影{m1, m2, m3}
(3)找到与用户A(user_id_1)具有相同电影兴趣爱好的用户群体集合Set<user_id>
如上表,可以看到,喜欢{m1, m2, m3}的用户,除了u1,还有{u2, u3}
(4)找到该群体喜欢的电影集合Set<movie_id>
如上表,具备相同喜好的用户群里{u2, u3},还喜好的电影集合是{m4, m5}
画外音:“协同”就体现在这里。
(5)未来用户A(use_id_1)来访问网站时,要推荐电影{m4, m5}给ta。
协同过滤大致原理如上,希望大家有收获。
什么是基于内容的推荐(Content-based Recommendation)?
答:通过用户历史感兴趣的信息,抽象信息内容共性,根据内容共性推荐其他信息。
比如,如何通过基于内容的推荐,来对求职者A进行职位推荐?
答:简要步骤如下
找到用户A历史感兴趣的职位集合
找到职位集合的具化内容
抽象具化内容的共性内容
由这些共性内容查找其他职位,并实施推荐
具体实施步骤如何?
答:简要步骤如下
(1)得到求职者A访问过三个职位,假设分别是{zw1, zw2, zw3},这些数据可以从历史日志得到。
(2)由职位集合得到职位具化内容
zw1 -> {程序员, 北京, 月薪8000, 3年经验, 本科}
zw2 -> {程序员, 北京, 月薪6000, NULL, 研究生}
zw3 -> {程序员, 北京, 月薪6000, 5年经验, NULL}
这些数据可以从职位数据库里得到。
(3)由职位具化内容抽象出职位共性信息
例如,由上述职位1,职位2,职位3抽象出的共性职位信息为:
{程序员, 北京, 月薪6000+, NULL, NULL}
(4)由这些共性内容查找其他职位并实施推荐
以{程序员, 北京, 月薪6000+, NULL, NULL}为查询条件,查询职位数据库,并按照一些规则进行排序(例如,最新发布的职位先推荐,点击过的职位不推荐等),完成推荐。
如果查询的结果集过小,可以缩小条件召回,例如可以将查询条件缩小为{程序员, 北京, 月薪3000+, NULL, NULL}
基于内容的推荐,原理如上,希望这1分钟,大家能有收获。
什么是“相似性推荐”?
答:对于新用户A,没有ta的历史行为数据,在ta点击了item-X的场景下,可以将与item-X最相似的item集合推荐给新用户A。
问题转化为,如何用一种通用的方法,表达item之间的相似性。
仍以电影推荐为例,新用户A进入了《我不是潘金莲》电影详情页,如何对A进行电影推荐呢?
先看二维空间的点N,如何推荐与其最近的点?
答:可以用二维空间中,点与点之间的距离,表示点之间的远近。
对于全集中的任何一个点M(xi, yi),它与点N(x1, y1)的距离:
distance = (x1-xi)^2 + (y1-yi)^2
所以,只要计算全集中所有点与N的距离,就能计算出与它最近的3个点。
再看三维空间的点N,如何推荐与其最近的点?
答:可以用三维空间中,点与点之间的距离,表示点之间的远近。
对于全集中的任何一个点M(xi, yi, zi),它与点N(x1, y1, z1)的距离:
distance = (x1-xi)^2 + (y1-yi)^2 + (z1-zi)^2
所以,只要计算全集中所有点与N的距离,就能计算出与它最近的3个点。
循序渐进,对于一部电影《我不是潘金莲》,假设它有10个属性,则可以把它看做一个十维空间中的点:
点N《我不是潘金莲》
{
导演:冯小刚
女主:范冰冰
男主:郭涛
女配:张嘉译
男配:大鹏
类型:剧情
地区:中国大陆
语言:普通话
日期:2016
片长:140
}
对于电影全集中的任何一部电影,都可以计算与点N《我不是潘金莲》之间的距离。二维三维中的点,可以用直线距离计算远近,10维空间{导演, 女主, 男主, 女配, 男配, 类型, 地区, 语言, 日期, 片长}中的两个点的距离,需要重新定义一个距离函数,例如:
distance = f1(导演) + f2(女主) + … +f10(片长)
这个距离,通俗的解释,就是每个维度贡献分值的总和。
分值可以这么定义:
f1(导演){
如果两部电影导演相同,得1分;
如果导演不同,得0分;
}
例如,现在10维空间中,有另一个点M《芳华》
{
导演:冯小刚
女主:苗苗
男主:黄轩
女配:NULL
男配:NULL
类型:剧情
地区:中国大陆
语言:普通话
日期:2017
片长:140
}
要计算点M《芳华》与点N《我不是潘金莲》的距离,代入distance距离计算公式:
distance = f1(导演) + f2(女主) + … +f10(片长)
=1 + 0 + … + 1
=5
即:导演、类型、地区、语言、片长相同各得1分,其他维度不同得0分。
遍历电影全集中的10w部电影,就能找到与点N《我不是潘金莲》最相近的3部电影,当用户点击《我不是潘金莲》的详情页时,直接推荐这3部最相近的电影即可。
相似性推荐,原理大致如上,要说明的是:
由于没有用户历史行为积累,不是个性化推荐,所以所有用户的推荐结果都是相同的
一般来说,距离公式确实是线性的
一般来说,每个维度的权重不一样
这个线性公式,以及维度的权重,都可以通过机器学习训练出来
以上是关于互联网的常见推荐算法的主要内容,如果未能解决你的问题,请参考以下文章