AI技术大爆发背景下,开源深度学习框架的发展趋势如何?
Posted InfoQ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI技术大爆发背景下,开源深度学习框架的发展趋势如何?相关的知识,希望对你有一定的参考价值。
深度学习(Deep Learning)的概念由加拿大多伦多大学教授Geoffrey Hinton等人于2006年提出,它本质上是一种神经网络算法,其原理是通过模拟人脑进行分析学习,算法训练时可以不用人工干预,因此它也属于一种无监督式机器学习算法。从深度学习的概念提出到今天,已历经十年时间,在这十年当中,无论是国际互联网巨头Google、微软、百度,还是全世界各大学术研究机构,都投入了巨大的人力、财力用于理论和工业级应用的探索,并在字符识别(OCR)、图像分类、语音识别、无人自动驾驭、自然语言处理等众多领域内取得了突破性的进展,极大地推动了人工智能(AI)的发展。

图1:深度学习的典型应用场景示例
2012年斯坦福大学的Andrew Ng和Jeff Dean教授共同主导的Google Brain项目通过使用深度学习让系统能够自动学习并识别猫,这项目研究引起了学术界和工业界极大的轰动,激起了全世界范围研究深度学习的热潮,《纽约时报》披露了Google Brain项目,让普通大众对深度学习有了最初的认知。2016年3月,Google旗下DeepMind公司开发的AlphaGo以4:1的总比分战胜了世界围棋冠军、职业九段选手李世石,这让人们对人工智能(AI)的认知跨越到一个新的阶段。
深度学习在众多领域的成功应用,离不开学术界及工业界对该技术的开放态度,在深度学习发展初始,相关代码就被开源,使得深度学习“飞入寻常百姓家”,大大降低了学术界研究及工业界使用的门槛。本文并不打算对深度学习算法的发展趋势进行分析,而是跳出算法层面,对当前主流的开源深度学习框架的发展趋势进行分析。
在计算机视觉领域内,神经网络算法一直被用来解决图像分类识别等问题,学术界采用的算法研究工具通常是Matlab、Python,有很多深度学习工具包都是基于Matlab、Python语言,在使用海量图像训练深度学习算法模型时,由于单台机器CPU的计算能力非常有限,通常会使用专门的图形处理器(Graphics Processing Unit,GPU)来提高算法模型速度。
但在工业级应用当中,由于Matlab、Python、R语言的性能问题,大部分算法都会使用C++语言实现,而且随着深度学习在自然语言处理、语音识别等领域的广泛应用,专用的GPU也慢慢演变为通用图像处理器(General Purpose GPU,GPGPU),处理器不仅仅被用于渲染处理图像,还可以用于需要处理大数据量的科学计算的场景,这种提高单台机器的处理能力的方式属于纵向扩展(Scale Up)。
随着大数据时代的来临,大数据处理技术的日趋成熟为解决深度学习模型训练耗时问题提供了重要发展方向,因此如何通过大数据训练深度学习模型在当前引起了广泛关注,大量的研究表明:增加训练样本数或模型参数的数量,或同时增加训练样本数和模型参数的数量,都能够极大地提升最终分类的准确性。由于Hadoop已经成为构建企业级大数据基础设施的事实标准,有许多的分布式深度学习算法框架被构建在Hadoop生态体系内,这种通过分布式集群提高处理能力的扩展方式被称为横向扩展(Scale Out)。
虽然利用Spark等平台训练深度学习算法可以极大地提高训练速度,但近年来,存储设备和网络在性能方面的提升远超CPU,如图2所示。
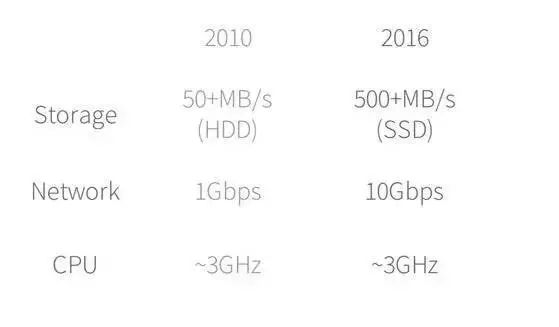
图2:存储系统、网络及CPU的性能变化比较
CPU性能瓶颈极大地限制了分布式环境下,单台节点的处理速度。为解决这一问题,许多优秀的开源深度学习框架都在尝试将开源大数据处理技术框架如Spark和GPGPU结合起来,通过提高集群中每台机器的处理性能来加速深度学习算法模型的训练,图3给出的是SparkNet的架构原理图。这种通过结合横向扩展及纵向扩展提高处理能力的方式被称为融合扩展。图4对深度学习提升性能的方式进行了总结,图中分别给出了横向扩展、纵向扩展及融合扩展的典型开源深度学习框架。
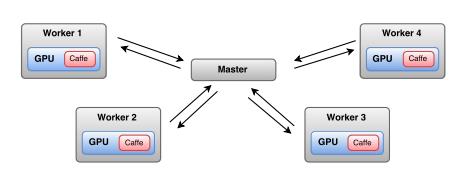
图3.SparkNet中的Scale Up和Scale Out
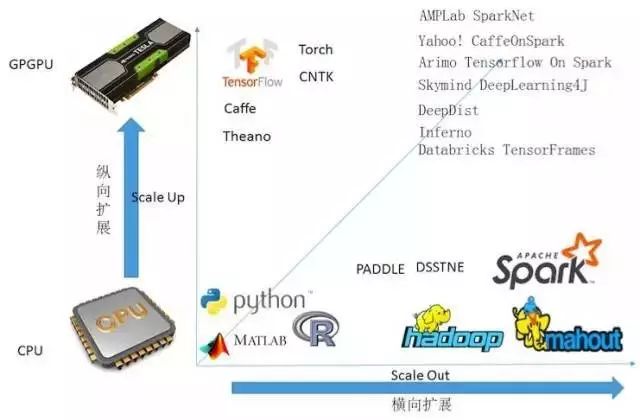
图4.深度学习提升性能的方式
下面将对目前一些优秀的开源深度学习框架进行介绍,包括基于GPU的单机开源深度学习框架和融合了GPU的开源分布式深度学习框架。让大家熟悉目前开源深度学习主流框架的同时,又能够进一步窥探开源分布式深度学习框架的发展方向。
目前拥有众多的学术机构如国际顶级名校加州大学伯克利分校,以及互联网巨头如Google、微软等开源的深度学习工具,比较成熟的基于GPU的单机开源深度学习框架有:
Theano:深度学习开源工具的鼻祖,由蒙特利尔理工学院时间开发于2008年并将其开源,框架使用Python语言开发。有许多在学术界和工业界有影响力的深度学习框架都构建在Theano之上,并逐步形成了自身的生态系统,这其中就包含了著名的Keras,Lasagne 和Blocks。
Torch:Facebook 和 Twitter主推的一款开源深度学习框架,Google和多个大学研究机构也在使用Torch。出于性能的考虑,Torch使用一种比较小众的语言(Lua)作为其开发语言,目前在音频、图像及视频处理方面有着大量的应用。大名鼎鼎的Alpha Go便是基于Torch开发的,只不过在Google 开源TensorFlow之后,Alpha Go将迁移到TensorFlow上。
TensorFlow:Google开源的一款深度学习工具,使用C++语言开发,上层提供Python API。在开源之后,在工业界和学术界引起了极大的震动,因为TensorFlow曾经是著名的Google Brain计划中的一部分,Google Brain项目的成功曾经吸引了众多科学家和研究人员往深度学习这个“坑”里面跳,这也是当今深度学习如此繁荣的重要原因,足见TensorFlow的影响力。TensorFlow一直在往分布式方向发展,特别是往Spark平台上迁移,这点在后面会有介绍。
Caffe:Caffe是加州大学伯克利分校视觉与学习中心(Berkeley Vision and Learning Center ,BVLC)贡献出来的一套深度学习工具,使用C/C++开发,上层提供Python API。Caffe同样也在走分布式路线,例如著名的Caffe On Spark项目。
CNTK:CNTK (Computational Network Toolkit)是微软开源的深度学习工具,现已经更名为Microsoft Cognitive Toolkit,同样也使用C++语言开发并提供Python API。目前在计算视觉、金融领域及自然处理领域已经被广泛使用。
DeepLearning4J官网有篇文章《DL4J vs. Torch vs. Theano vs. Caffe vs. TensorFlow》,对这些主流的深度学习框架的优劣势进行了详细的分析比较,感兴趣的读者可以点击查看。
Google研究员Jeffy Dean在2012发表了一篇《Large Scale Distributed Deep Networks》对分布式环境下的深度学习算法设计原理进行了阐述,给出了深度学习在分布式环境下的两种不同的实现思路:模型并行化(Model parallelism)和数据并行化(Model Parallelism)。模型并行化将训练的模型分割并发送到各Worker节点上;数据并行化将数据进行切分,然后将模型复本发送到各Worker节点,通过参数服务器(Parameter Server)对训练的参数进行更新。具体原理如图5所示。
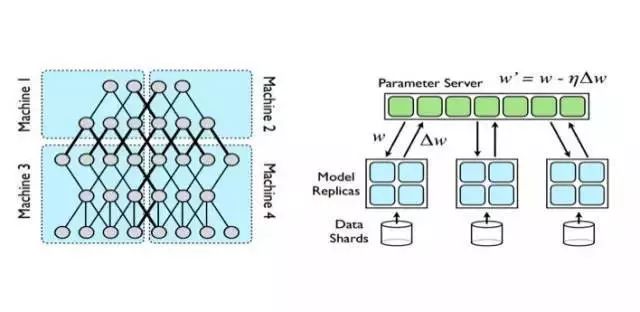
图5.深度学习并行化的两种方式:模型并行化(左)和数据并行化(右)
目前开源分布式深度学习框架大多数采用的是数据并行化的方式进行设计。目前有两大类:框架自身具备分布式模型训练能力;构建在Hadoop生态体系内,通过分布式文件系统(HDFS)、资源调度系统(Yarn)及Spark计算平台进行深度学习模型训练。其中框架自身具备分布式模型训练能力的开源深度学习框架有:
DSSTNE:亚马逊开源的一套深度学习工具,英文全名为Deep Scalable Sparse Tensor Network Engine(DSSTNE),由C++语言实现,解决稀疏数据场景下的深度学习问题。值得一提的是,亚马逊在是否走开源的道路上一直扭扭捏捏,开源DSSTNE,似乎也是在Google、Facebook等巨头抢占开源深度学习领域高地之后的无奈之举。
Paddle:百度开源的并行分布式深度学习框架(PArallel Distributed Deep Learning,PADDLE),由C++语言实现并提供Python API。Paddle框架已经经过百度内部多个产品线检验,包括搜索广告中的点击率预估(CTR)、图像分类、光学字符识别(OCR)、搜索排序、计算机病毒检测等。
由于Hadoop生态体系已经占据了企业级大数据市场的大部分份额,因此目前许多开源分布式都在往Hadoop生态体系迁移,这其中有Caffe、TensorFlow,也有百度的Paddle。构建在Hadoop/Spark生态体系下的深度学习框架实现原理图如下:
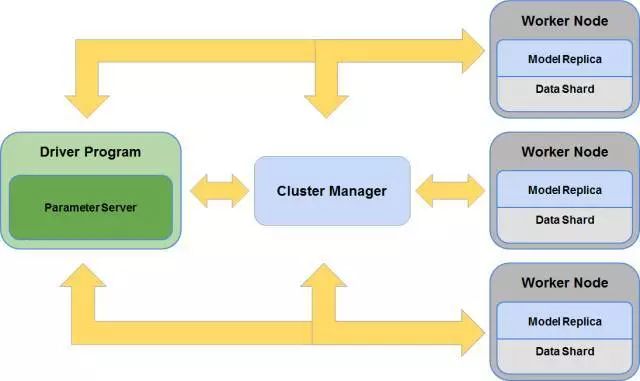
图6 .Hadoop生态体系分布式深度学习算法实现原理
目前比较有影响力的基于Hadoop/Spark的开源分布式深度学习框架有:
SparkNet:由AMPLab于2015年开源,底层封装Caffe和Tensorflow,采用集中式的参数服务器进行实现,具体实现原理及架构参见论文《SPARKNET: TRAINING DEEP NETWORKS IN SPARK》。
Deeplearning4J:由Skymind公司于2014年开发并开源的分布式深度学习项目,采用Java语言实现,同时也支持Scala语言。它使用的参数服务器模式为IterativeReduce。
Caffe On Spark:Yahoo于2015年开源的分布式深度学习框架,采用Java语言和Scala语言混合实现,使用Spark+MPI架构以保障性能,其参数服务器采用点对点(Peer-to-Peer)的实现方式。通过将Caffe纳入到Hadoop/Spark生态系统,解决大规模分布式环境下的深度学习问题,意图将Caffe On Spark成为继Spark SQL、Spark ML/MLlib、Spark Graphx及Spark Streaming之后的第五个组件。
Tensorflow on Spark:2014年由Arimo公司创建,将TensorFlow移植到Spark平台之上。
TensorFrames (TensorFlow on Spark Dataframes) :Databricks开源的分布式深度学习框架,目的是将Google TensorFlow移植到Spark的DataFrames,使用DataFrame的优良特性,未来可能会结合
Spark的Structure Streaming对深度学习模型进行实时训练。
Inferno:由墨尔本La Trobe大学博士生Matthias Langer开发的基于Spark平台的深度学习框架,作者正在整理发表关于Inferno的实现原理论文,同时也承诺在论文发表后会将代码开源到GitHub上。
DeepDist:由Facebook的资深数据科学家Dirk Neumann博士开源的一套基于Spark平台的深度学习框架,用于加速深度信念网络(Deep Belief Networks)模型的训练,其实现方式可以看作是论文《Large Scale Distributed Deep Networks》中 Downpour随机梯度下降(Stochastic Gradient Descent,SGD)算法的开源实现。
Angel:腾讯计划于2017年开源的分布式机器学习计算平台,Angel可以支持Caffe、TensorFlow和Torch等开源分布式学习框架,为各框架提供计算加速。Angel属于腾讯第三代机器学习计算平台,第一代基于Hadoop,只支持离线计算场景,第二代基于Spark/Storm,使用自主研发的Gala调度平台替换YARN,能够同时支持在线分析和实时计算场景,第三代属于腾讯自研的平台,除底层文件系统使用HDFS外,资源调度和计算引擎全部为腾讯自研产品。
SparkNet、Deeplearning4J及Caffe On Spark等构建在Spark平台上的深度学习框架在性能、易用性、功能等方面的详细比较,参见《Which Is Deeper Comparison of Deep Learning Frameworks Atop Spark》、《inferno-scalable-deep-learning-on-spark》。
由于近几年在大数据技术的日趋成熟和流行,特别是基于JVM的语言(主要是Java和Scala)构建的大数据处理框架如Hadoop、Spark、Kafka及Hive等几乎引领着大数据技术的发展方向,相信以后将会有越来越多的开源深度学习框架构建在Hadoop生态体系内,并且基于Java或Scala语言实现。
本文首先介绍了深度学习提升性能的三种方式:纵向扩展(给机器加GPU)、横向扩展(通过集群训练模型)及融合扩展(在分布式的基础上,给每个集群中的Worker节点加GPU),然后对主流的开源深度学习框架进行了介绍。通过对这些开源深度学习框架的了解,可以看到当前开源深度学习框架的发展有以下几个趋势:
分布式深度学习框架特别是构建在Hadoop生态体系内的分布式深度学习框架(基于Java或Scala语言实现)会越来越流行,并通过融合扩展的方式加速深度学习算法模型的训练。
在分布式深度学习方面,大数据的本质除了常说的4V特性之外,还有一个重要的本质那就是Online,数据随时可更新可应用,而且数据本质上具备天然的流式特征,因此具备实时在线、模型可更新算法的深度学习框架也是未来发展的方向。
当待训练的深度学习算法模型参数较多时,Spark与开源分布式内存文件系统Tachyon结合使用是提升性能的有效手段。
深度学习作为AI领域的一个重要分支,俨然已经成为AI的代名词,人们提起AI必定会想到深度学习,相信随着以后大数据和深度学习技术的不断发展,更多现象级的应用将不断刷新人们对AI的认知,让我们尽情期待“奇点”临近。
周志湖,电子科技大学计算机硕士,研究方向为计算机视觉、机器学习,曾在国内外核心期刊发表机器学习相关注水论文若干,现为绿城中国资深数据平台架构师、专业经理,主要从事房产行业大数据应用。
赵永标,宁波大学应用数学硕士,11年互联网从业经验,现为杭州以数科技有限公司CTO、联合创始人,主攻工业、公安及房产行业大数据应用。
今日荐号

冷眼观AI
实事求是, 以客观、专业的态度, 带您“冷眼观AI”
微信ID:partakeAI
今日荐文
不管你承认与否,人工智能的时代即将来临
以上是关于AI技术大爆发背景下,开源深度学习框架的发展趋势如何?的主要内容,如果未能解决你的问题,请参考以下文章
Alluxio:2022年大数据五大趋势,多云下数据湖兴起,AI成为主流
飞桨升级 创新引领 12月12日上海,邀您共话深度学习框架创新大趋势