介绍一个相对小众的深度学习框架Darknet,其YOLO神经网络算法对目标检测效果显著
Posted 路同学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了介绍一个相对小众的深度学习框架Darknet,其YOLO神经网络算法对目标检测效果显著相关的知识,希望对你有一定的参考价值。
Darknet——一个源码为C的神经网络框架
今天路同学介绍一个相对小众的深度学习框架——Darknet。
与流行的Tensorflow以及Caffe框架相比,Darknet框架在某些方面有着自己独特的优势。
关于Darknet深度学习框架
Darknet深度学习框架是由Joseph Redmon提出的一个用C和CUDA编写的开源神经网络框架。它安装速度快,易于安装,并支持CPU和GPU计算。
你可以在GitHub上找到源代码:
https://github.com/pjreddie/darknet
你也可以在官网上阅读完成更多事情:
https://pjreddie.com/darknet/
YOLO算法
YOLO(You Only Look Once)是Joseph Redmon针对这一框架提出的核心目标检测算法。

作者在YOLO算法中把物体检测问题处理成回归问题,用一个卷积神经网络结构就可以从输入图像直接预测bounding box和类别概率。

YOLO算法的优点:
1、YOLO的速度非常快。在Titan X GPU上的速度是45 fps(frames per second),加速版的YOLO差不多是150fps。
2、YOLO是基于图像的全局信息进行预测的。这一点和基于sliding window以及region proposal等检测算法不一样。与Fast R-CNN相比,YOLO在误检测(将背景检测为物体)方面的错误率能降低一半多。
3、可以学到物体的generalizable-representations。可以理解为泛化能力强。
4、准确率高。有实验证明。
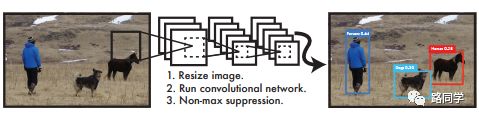
事实上,目标检测的本质就是回归,因此一个实现回归功能的CNN并不需要复杂的设计过程。YOLO没有选择滑窗或提取proposal的方式训练网络,而是直接选用整图训练模型。这样做的好处在于可以更好的区分目标和背景区域,相比之下,采用proposal训练方式的Fast-R-CNN常常把背景区域误检为特定目标。当然,YOLO在提升检测速度的同时牺牲了一些精度。

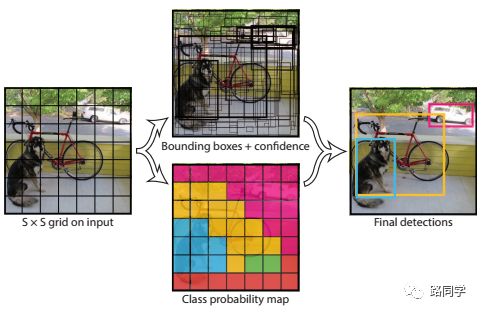
YOLO的设计理念遵循端到端训练和实时检测。YOLO将输入图像划分为S*S个网格,如果一个物体的中心落在某网格(cell)内,则相应网格负责检测该物体。

在训练和测试时,每个网络预测B个bounding boxes,每个bounding box对应5个预测参数,即bounding box的中心点坐标(x,y),宽高(w,h),和置信度评分。
这里的置信度评分(Pr(Object)*IOU(pred|truth))综合反映基于当前模型bounding box内存在目标的可能性Pr(Object)和bounding box预测目标位置的准确性IOU(pred|truth)。如果bouding box内不存在物体,则Pr(Object)=0。如果存在物体,则根据预测的bounding box和真实的bounding box计算IOU,同时会预测存在物体的情况下该物体属于某一类的后验概率Pr(Class_i|Object)。
假定一共有C类物体,那么每一个网格只预测一次C类物体的条件类概率Pr(Class_i|Object), i=1,2,...,C;每一个网格预测B个bounding box的位置。即这B个bounding box共享一套条件类概率Pr(Class_i|Object), i=1,2,...,C。基于计算得到的Pr(Class_i|Object),在测试时可以计算某个bounding box类相关置信度:Pr(Class_i|Object)*Pr(Object)*IOU(pred|truth)=Pr(Class_i)*IOU(pred|truth)。
如果将输入图像划分为7*7网格(S=7),每个网格预测2个bounding box (B=2),有20类待检测的目标(C=20),则相当于最终预测一个长度为S*S*(B*5+C)=7*7*30的向量,从而完成检测+识别任务,整个流程可以通过下图理解。
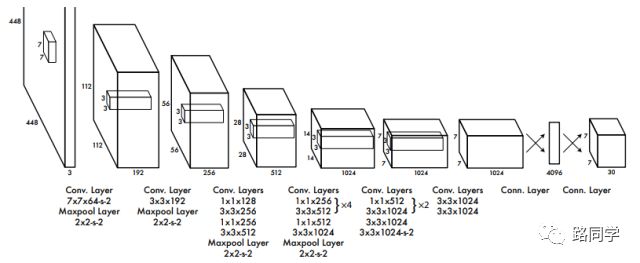
YOLO网络设计遵循了GoogleNet的思想,但与之有所区别。YOLO使用了24个级联的卷积(conv)层和2个全连接(fc)层,其中conv层包括3*3和1*1两种Kernel,最后一个fc层即YOLO网络的输出,长度为S*S*(B*5+C)=7*7*30.此外,作者还设计了一个简化版的YOLO-small网络,包括9个级联的conv层和2个fc层,由于conv层的数量少了很多,因此YOLO-small速度比YOLO快很多。如下图所示给出了YOLO网络的架构。
YOLO算法的缺点:
1、位置精确性差,对于小目标物体以及物体比较密集的也检测不好,比如一群小鸟。
2、YOLO虽然可以降低将背景检测为物体的概率,但同时导致召回率较低。

路同学最近就在使用这一深度学习框架,亲测好用!
最后,附上关于YOLO的论文原文:
https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Redmon_You_Only_Look_CVPR_2016_paper.pdf
爱胡思乱想
渴望成为优秀学生的
路同学愿和你谈谈心。
路同学
以上是关于介绍一个相对小众的深度学习框架Darknet,其YOLO神经网络算法对目标检测效果显著的主要内容,如果未能解决你的问题,请参考以下文章