轻量级深度学习框架--YOLO V3
Posted 图视星云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了轻量级深度学习框架--YOLO V3相关的知识,希望对你有一定的参考价值。
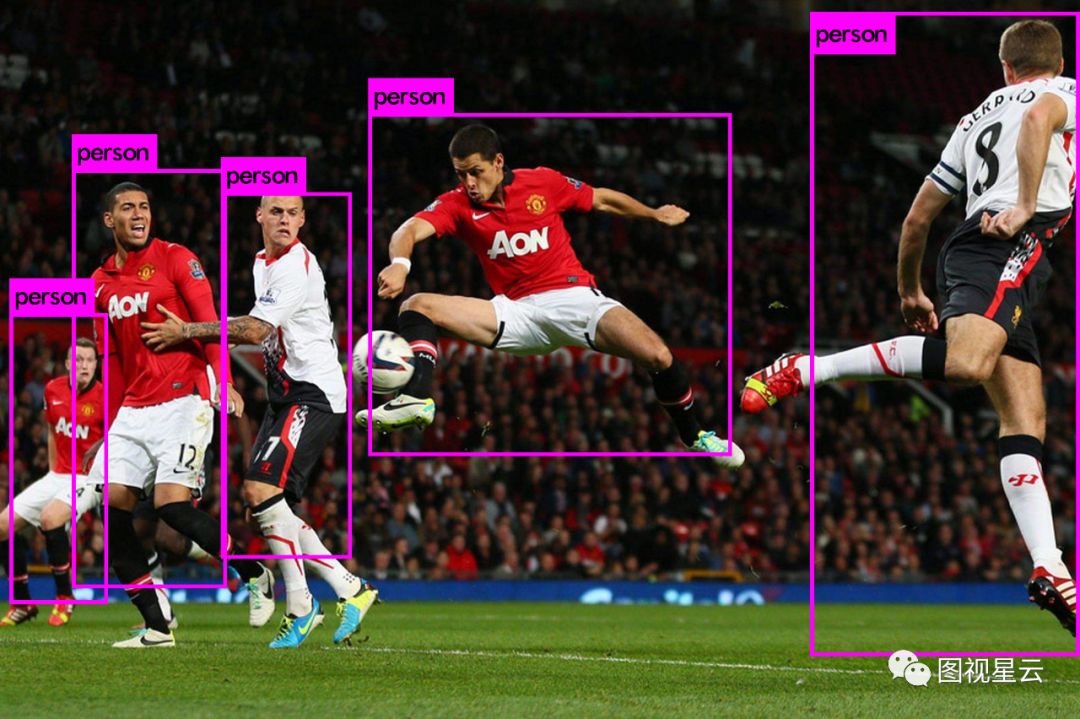
YOLO是一个实时目标检测框架,使用C语言编写,性能杠杠的。CPU版本可直接make,不依赖第三方库,代码结构清晰、轻量,适合深度学习入门研究。GPU版大幅提升了检测速度,可做到视频实时检测。在沉寂几个月后,作者于3月28日又在Github上发布了V3版本,将默认的网络结构由v2的30层增加到106层,识别准确度大幅提高,速度较v2也慢了不少。上图看检测效果比较。
YOLO V3可识别出足球
YOLO V2未识别出足球(在80分类中是有球的)
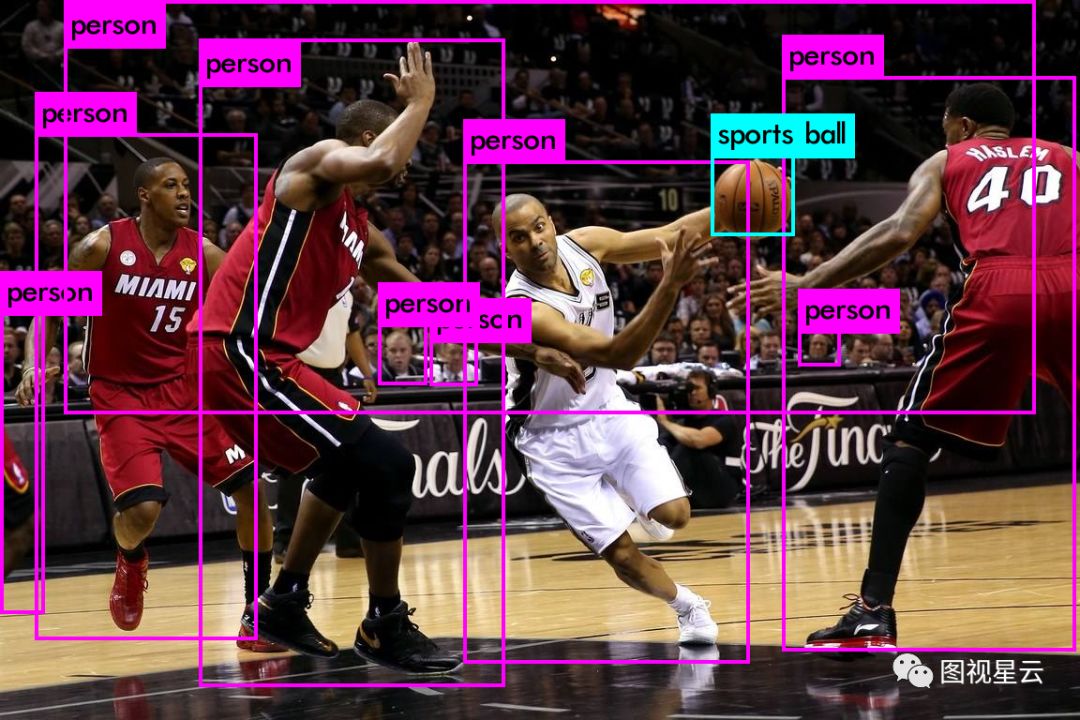
YOLO V3识别出了篮球,还有坐席上的几个人脸,将整个坐席也识别成了person
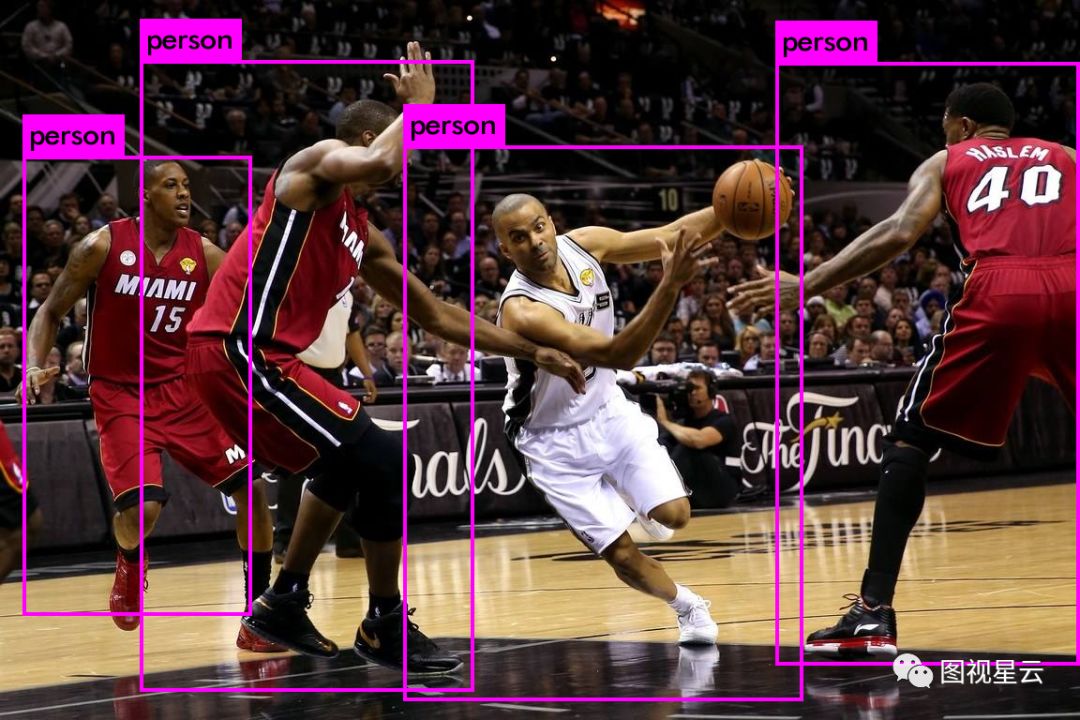
YOLO V2只将前景中几个关键的人识别了出来
YOLO V3识别出了鼠标和碗
YOLO V2识别出物体明显少于V3
PS:以上测试均是在默认阈值下检测的。
YOLO的主要特点:
速度快,能够达到实时的要求。在 Titan X 的 GPU 上 能够达到 45 帧每秒。
使用全图作为 Context 信息,背景错误(把背景错认为物体)比较少。
泛化能力强。
YOLO缺陷:(其实这是V2的,V3还未细看)
YOLO对相互靠的很近的物体(挨在一起且中点都落在同一个格子上的情况),还有很小的群体 检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
测试图像中,当同一类物体出现的不常见的长宽比和其他情况时泛化能力偏弱。
由于损失函数的问题,定位误差是影响检测效果的主要原因,尤其是大小物体的处理上,还有待加强。
以上是关于轻量级深度学习框架--YOLO V3的主要内容,如果未能解决你的问题,请参考以下文章
Pytorch深度学习50篇·······第五篇:YOLO----- YOLO V3 V4 V5的模型结构
介绍一个相对小众的深度学习框架Darknet,其YOLO神经网络算法对目标检测效果显著
深度学习和目标检测系列教程 13-300:YOLO 物体检测算法