数据库AIOps案例:快速诊断数据库性能问题 Posted 2021-04-29 智能运维前沿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库AIOps案例:快速诊断数据库性能问题相关的知识,希望对你有一定的参考价值。
编辑| 王昆 Vicky
在线事务处理系统(OLTP)数据库往往是企业用来支持其关键任务和实时应用程序的重要工具,数据库性能会直接影响企业收入和用户体验。所以DBA需要不断监视、诊断和纠正其性能上发生的任何下降。这也成为了DBA所面临的最艰巨的任务之一。
然而,调试和诊断OLTP性能问题的手动过程非常繁琐。OLTP数据库中的性能问题通常不是由单个慢查询引起的,而是由于大量的并发和竞争事务导致难以隔离的复合非线性效应所引起。请求量,事务模式,网络流量或数据分布的突然变化可能导致以前充裕的资源变得紧缺,进而造成性能直线下降。
本文介绍了一种可帮助DBA快速可靠地诊断OLTP数据库中的性能问题的实用工具:DBSherlock。通过分析在系统生命周期内收集的数百个统计信息和配置,算法可以快速识别导致性能下降的潜在原因并将其呈现给DBA。最终由DBA所确定的根因又会被重新反馈并纳入算法,作为一种新的因果模型,以改善未来的诊断。
许多企业应用程序依赖于对其数据库后端执行事务来存储,查询和更新数据。运行在线事务处理(OLTP)工作负载的数据库是企业中最关键的组件之一。这些数据库中的任何服务中断或性能问题都会直接导致收入损失。
大型组织中数据库管理员的主要职责是不断监视其OLTP工作负载是否存在任何性能故障或速度降低,并及时采取适当的措施来恢复性能。但诊断性能问题的根因非常繁琐,需要DBA手动检查各种日志文件来综合考虑各种可能性。原本大多数事务只需要几分之一毫秒即可完成。但竞争相同资源(例如,CPU,磁盘I / O,内存)的数万个并发事务可能会对数据库性能产生高度非线性的影响。这种非线性的影响使得OLTP工作负载的微小变化可能迅速导致以前的资源稀缺。
现代数据库和操作系统随着时间的推移收集大量详细的统计数据和日志文件,创建了指数级的DBMS变量子集和统计数据。 但除了基本的可视化和监视机制之外,现有数据库无法为DBA提供使用这些丰富数据集分析性能问题的有效工具。 为了避免这种繁琐,论文提出了一个名为DBSherlock的性能解释框架,它结合了异常值检测和根因分析的技术,以帮助DBA更轻松,更准确地诊断性能问题。 通过DBSherlock的可视界面,用户指定其认为异常的某些实例。 DBSherlock自动分析大量过去的统计数据,以找出用户感知异常的最可能原因,将其与置信度值一起呈现给用户。 DBA可以在这几种可能性中识别实际原因。 一旦DBA确认了真实根因,DBA的反馈将被整合回DBSherlock以改进其因果模型和未来的诊断。
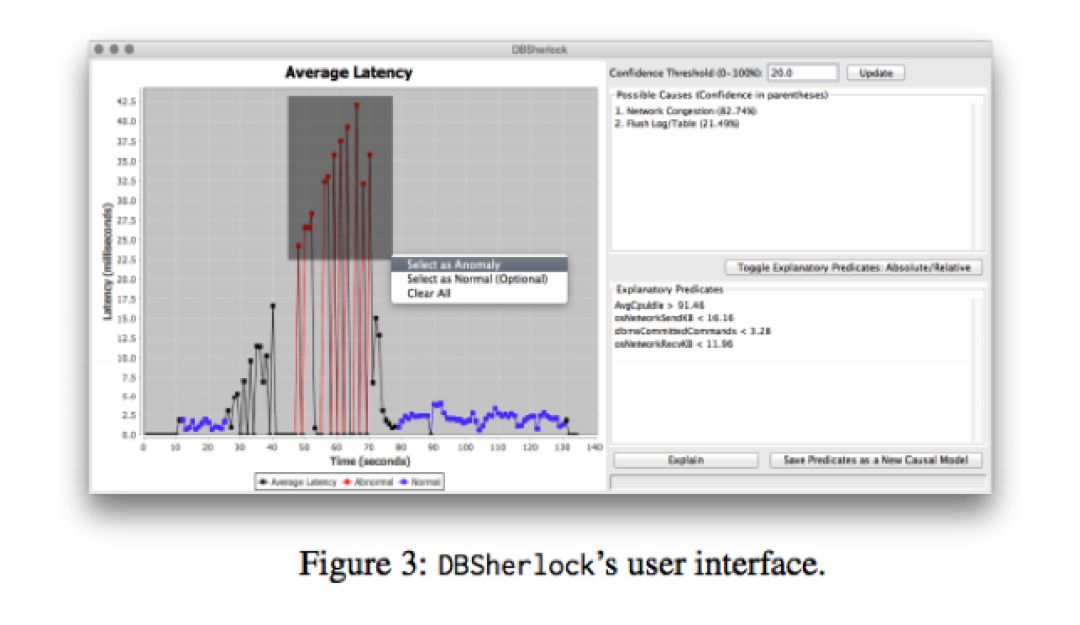
现实中找到这种延迟峰值的根本原因非常具有挑战性。但在以下情况下观察到几乎相同的性能图:(i)总体工作负载突然增加(ii)写入不良的查询数量激增,(iii)网络短时不可用(network hiccup)发生。为了确定正确的原因,DBA必须在与延迟峰值相同的时间范围内绘制其他几个性能指标进行进一步的观察分析。DBSherlock可以通过生成适当的解释性断言来帮助DBA区分不同的可能原因,从而显着缩小此搜索空间。在图1示例中,DBSherlock的统计分析将根据不同的原因反馈出不同的断言。当(i)发生时,DBSherlock生成一个断言,显示与正常情况相比,锁定等待和运行DBMS线程的数量增加。在(ii)的情况下,DBSherlock的断言表明读取请求以及DBMS的CPU使用率的突然上升。最后,如果原因是(iii)则会导致断言显示在特定时间期间发送或接收的网络分组数量低于通常数量。也就是说DBSherlock的断言通过为DBA提供适当的提示和指标来帮助解释问题发生的根本原因。
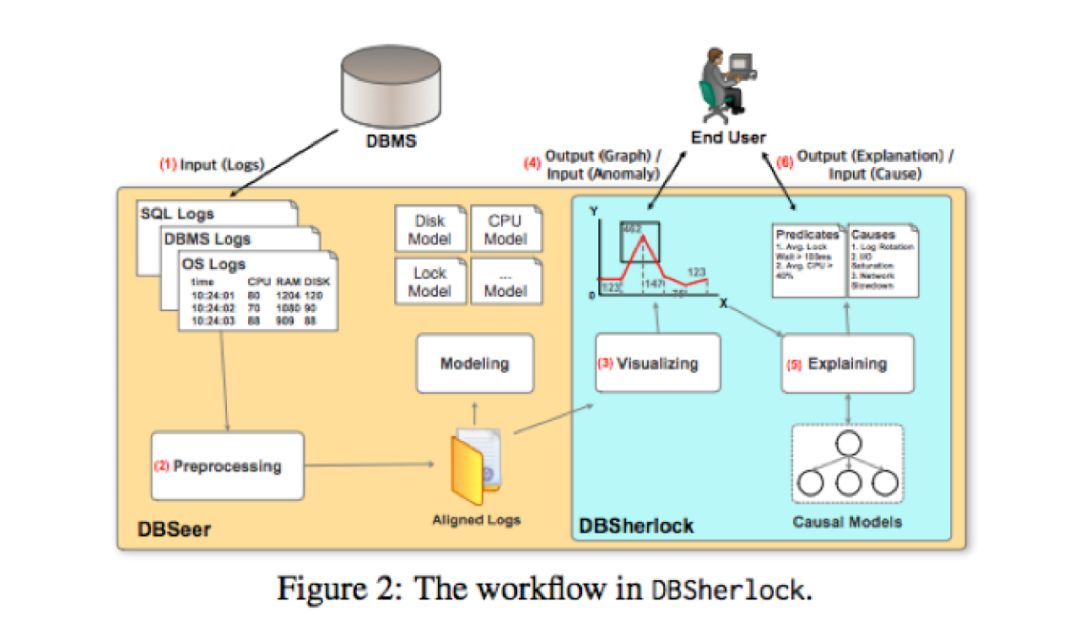
DBSherlock的性能解释和诊断工作流程包括六个步骤,如图2蓝色区域所示。
DBSherlock的性能解释和诊断工作流程包括六个步骤,如图2蓝色区域所示。
DBSherlock从DBMS和OS收集各种日志文件,配置和统计信息。
收集的日志通过它们的时间戳以固定的时间间隔进行汇总和对齐。
通过DBSherlock的图形用户界面,可以生成DBMS随时间的各种性能统计的散点图。
如果最终用户认为DBMS的任何性能指标在某一段异常或可疑,便可以简单地选择该图的区域并向DBSherlock询问对观察到的异常的解释(如上图所示)。另外用户还可以依赖DBSherlock的自动异常检测功能。
鉴于用户选中的异常区域,DBSherlock会随着时间的推移分析收集的统计数据和配置,并使用描述性断言来解释异常。例如,DBSherlock可以通过生成以下断言来解释由网络减速引起的异常:
使用DBSherlock的解释作为诊断线索,DBA尝试确定观察到的性能问题的真正根因。一旦DBA诊断出实际原因,会向DBSherlock提供评估反馈。然后将此反馈作为因果模型并入DBSherlock中,并用于改进未来的解释。
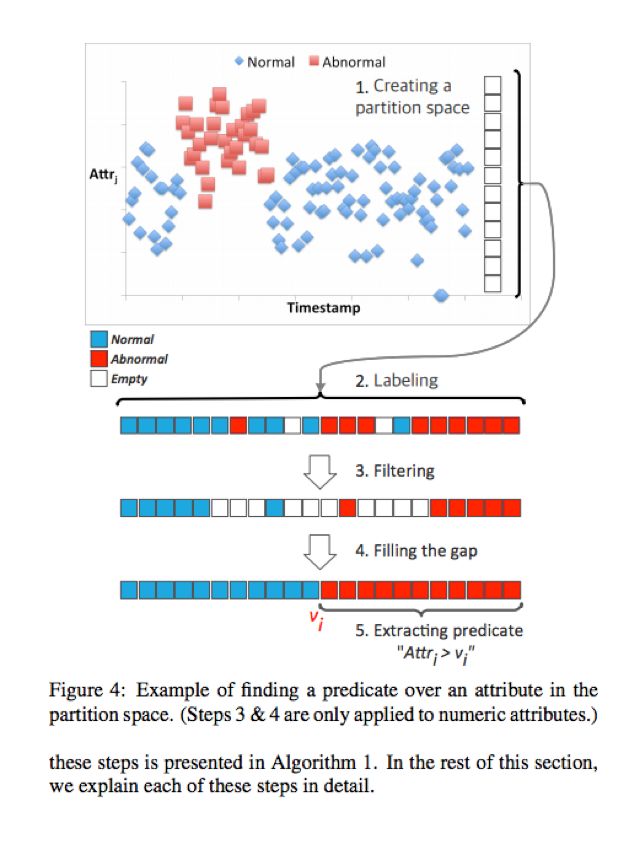
上图说明了DBSherlock算法的设计思路,该图描述了对模型某一特定属性进行预测的方法,算法将对齐的元组作为输入,横轴为时间,纵轴为属性值。对于数值型和非数值型属性,算法进行了不同的处理,具体来说分为以下步骤:
根据属性值的max 和 min值确定分区空间的大小。
Pj代表某一属性值的全部分布,包含了该属性的全部value,Pj的上限 ub(Pj),下限 lb(Pj),其中任意时刻该属性的value值满足 ub(Pj) <=val <=lb(Pj)。
创建分区空间的第二个目的是 可以解决正常元组多,而选中的异常元组少的现象,离散过程可以使用户专注于正常和异常交界处的属性值的分布。
根据用户在图形界面中的勾选 将属性值分别标注为正常 异常 和 空值。
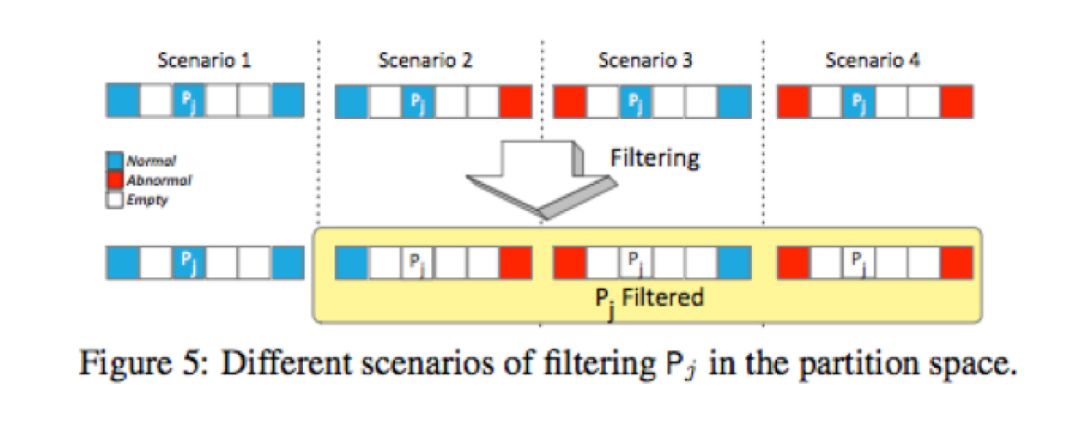
过滤掉混合的异常和正常分区通过将一些正常和异常分区替换为空标签来实现。
图5展示了Pj保持不变的唯一情况:Pj两个非空相邻分区都具有与Pj相同的标签,若只有一个异常或者正常,算法会认为该点非常重要,不会删除或者替换它。
注:其中第三四步是为了去除数值型属性中存在的嘈杂值,以便推测出真实准确的属性范围。
当DBSherlock生成了可读性强的故障分析建议后,该框架还支持通过DBA分析的真正错误原因反馈结合因果模型来优化算法。
针对广泛的性能问题对算法进行验证后发现,相比于之前最先进的性能解释技术。DBSherlock的故障分析断言准确率比前者高出28%(高达55%)DBSherlock主要通过更加详细的Domain Knowledge和基于用户反馈的算法优化技术来提高故障分析的准确率。
原文:DBSherlock: A Performance Diagnostic Tool for Transactional Databases
作者:
Dong Young Yoon, Ning Niu, Barzan Mozafari @ University of Michigan
免责声明:本文内容来自网络,版权归原作者所有,如涉及作品版权问题,请与我们联系。
由于篇幅限制,本文未进行具体叙述,有兴趣的读者可以点击“阅读原文”。
介绍世界范围内智能运维的前沿进展
推动智能运维算法在实践中落地和普世化
长按二维码,关注我们
以上是关于数据库AIOps案例:快速诊断数据库性能问题的主要内容,如果未能解决你的问题,请参考以下文章
微软故障分诊AIOps案例
使用AWR报告诊断oracle性能案例
使用AWR报告诊断oracle性能案例
走进RDS之SQL Server性能诊断案例分析
微软亚研院的AIOps底层算法: KPI快速聚类
快速诊断I/O性能问题