专治脑壳疼 | 傻傻分不清各种数据库概念?一文带你理清它!
Posted IT inside
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了专治脑壳疼 | 傻傻分不清各种数据库概念?一文带你理清它!相关的知识,希望对你有一定的参考价值。
近期,小伙伴们一起做数据库选型相关工作,经常会遇到一些莫名其妙的讨论……
说着说着有人一头雾水两眼懵逼,有人咬牙切齿欲言又止,一场撕x大战一触即发,办公室弥漫着不可名状的气氛……
实在是让人摸不着头脑!
比如下面这种情况:
▽


还有这种……
▽

这都是啥???
不了解数据库 还没办法交流了是吧??
没办法就没办法 我这就……学习去!
如果读者也一样做过Oracle DBA,就很容易理解这种定向思维——对于当下新兴的各种数据库产品技术,总下意识地想用Oracle的套路去理解和比较……
但想这样就能做好数据库选型?

于是便出现了以上鸡同鸭讲的尴尬局面,为了挽回IT人应有的尊严,小编邀请了一位神秘嘉宾、重量级数据库大咖(名字偏不说~文末揭晓)为大家梳理了数据库选型之初经常碰到的概念,整理了一套数据库新手入门“葵花宝典”,往下看,涨知识!

1
数据库基础概念科普

N0.1
关于OldSQL、NoSQL、NewSQL

OldSQL、NoSQL、NewSQL主要是从数据库产品演进发展逐步总结出来的分类,NoSQL和NewSQL的出现与非结构化大数据的需求、分布式技术的演进等紧密相关;非结构化的大数据需求推动了各种NOSQL解决方案;分布式技术与SQL相结合催生了NewSQL数据库。
那这三个“SQL孪生兄弟”到底有什么不同?
OldSQL
释义:
传统关系型数据库,为了突出NewSQL强加个“OLD”;
强调高度组织化、结构化数据,数据和关系都存储在单独的表中,使用SQL,满足ACID强一致性原则。
代表产品:
Oracle、SqlServer、DB2、Timesten内存数据库等
NoSQL
释义:
全称为Not Only SQL;
强调非关系型的、分布式的、不保证遵循ACID原则,甚至不用SQL而使用API实现。
代表产品:
Redis/memcache(缓存数据)、MongoDB(文档数据)、Neo4J(图)、InfluxDB(时序数据)、HBase(列式)、Elasticsearch(检索)
NewSQL
释义:
融合SQL与NoSQL各自特性的新型数据库,目前很多数据库产品都可以归结为此类;
强调既满足ACID原则,保持关系型模型,使用SQL,同时又提供NOSQL的分布式架构,实现高扩展性、高并发特性。
代表产品:
OceanBase、PolarDB、TDSql、TBase、GaussDB、GreenPlum、TiDB等
N0.2
关于ACID、CAP、BASE
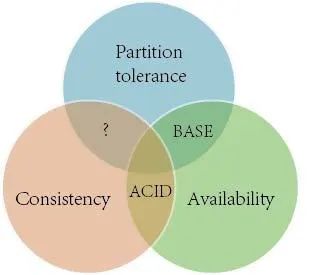
这几个术语经常在数据库或分布式系统理论中碰到,属于技术实现的理论原则。
掌握这些原则,有助于我们在新产品调研时更好地了解产品设计的逻辑和实现细节,比如调研XX产品是如何保障ACID?
ACID原则
关系型数据库事务机制设计的基本原则,旨在保证在事务过程中数据的正确性,分别是原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
在运营商的交易型应用务必要保障ACID,否则这锅,100个小编加100个你也背不动啊~~~
保障ACID就会引入数据库的核心原理,包括Redo日志/WAL日志、Undo、隔离级别、锁设计等,另外在NewSQL分布式数据库中,为保障ACID就需要引入分布式事务管理。
CAP理论
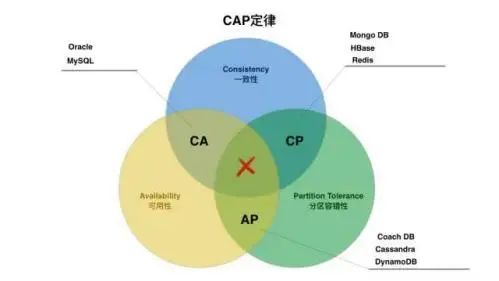
分布式计算领域公认的定理,核心思想是一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
分布式数据库属于分布式系统,离不开CAP的制约,如,传统数据库没有分区,一般定义属于CA数据库,而分布式数据库由于分区(Partition)的存在,一般选择放弃A或C,来换取高性能或高并发。
BASE原则

在分布式系统中分区容错性(P)是必须的,因此研究人员通过总结提出了BASE原则(Basically Available、Soft state、和Eventually consistent),主要对CAP中C(一致性)和A(可用性)权衡的结果,其核心思想是牺牲强一致性来确保可用性,采用适当折中的方法达到最终一致性。
N0.3
关于TPC-C、TPC-H
在数据库产品介绍中经常会提及TPC-C测试情况,比如“OceanBase登顶TPC-C”等等。
那么, TPC-C测试到底是个什么东东?

TPC-C测试是由国际事务性能委员会(TPC)组织发布的针对不同场景制定的基准测试标准,各种测试标准详细描述了关于数据模型、测试方法等,比如TPC-C主要制定关于OLTP的测试模型、TPC-H/TPC-DS主要是制定OLAP的测试模型。
TPC-C
针对OLTP的基准测试,定义了9张表的数据模型及各种测试事务。
TPC-H
针对OLAP的基准测试,定义了8张表,22个查询测试业务。
TPC-DS
针对OLAP的基准测试,定义了7张事实表,17张纬度表,对四种查询进行模拟(报告查询、临时查询、迭代OLAP查询、数据挖掘查询)。
另外还有很多不同的测试标准。
但这些测试结果跟实际业务的负载以及应用使用情况有较大的偏差,具体业务系统选型只能作为很初步的参考,需要做大量的业务验证测试。

基础术语部分就介绍得差不多啦,不知道小伙伴们记住了没有?

如果一时记不住,可以先把文章收藏起来,再慢慢消化~~
本着IT人的钻研精神,基础科普哪够咱塞牙缝!
善解人意的大咖又为我们分享了部分数据库选型的详细介绍,满满干货等你来提!
2
部分数据库选型详细介绍
数据库选型参考因素众多,来张图感受一下子孙满堂的它~
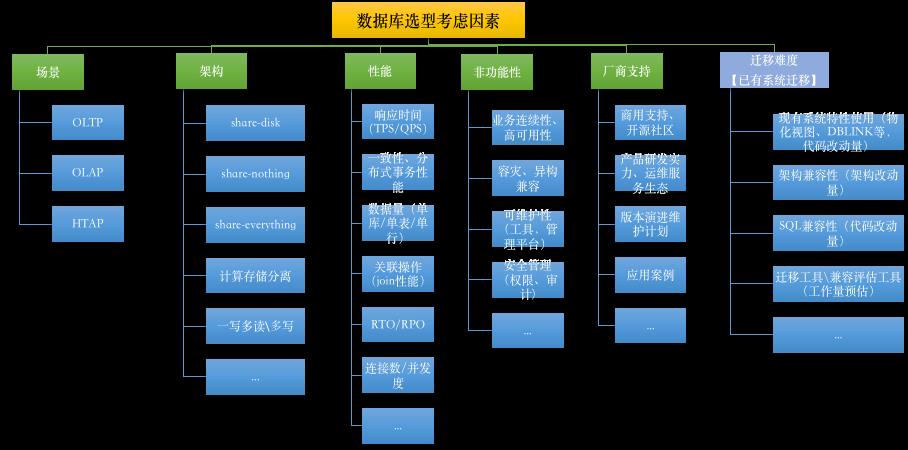
不同因素之间又可能受其它因素影响,比如场景或技术架构的变化就会带来其它几个因素的变化,也就涉及更多细节层面的实现技术。
下面我们选取“场景”和“架构”这两方面涉及的基础概念进行介绍~
N0.1
关于OLTP、OLAP、HTAP
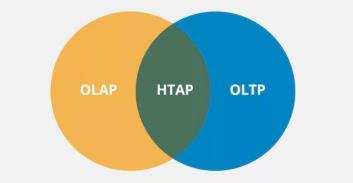
这几个概念主要在业务场景上进行分类,在选型上可以有个作为初步的判断:
OLTP
联机事务处理(On-Line Transaction Processing,如充值、扣费、业务订购等属于OLTP场景业务
Oracle、Oceanbase等主要应用在OLTP系统
OLAP
联机实时分析处理(On-Line Analytical Processing,如报表统计查询等属于OLAP场景业务
Greenplum、GBase 8a等主要应用在OLAP系统
HTAP
混合事务和分析处理(Hybrid Transaction and Analytical Process),打破OLTP和OLAP之间的隔阂,既可以应用于事务型数据库场景,亦可以应用于分析型数据库场景。
目前行业内很多新的数据库产品都介绍其支持HTAP场景,如腾讯TBase、阿里PolarDB、PingCap的TiDB等等。
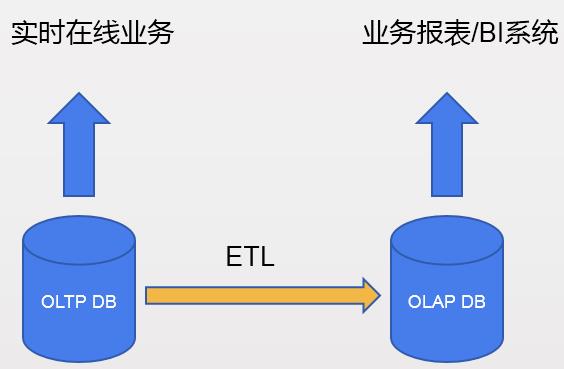
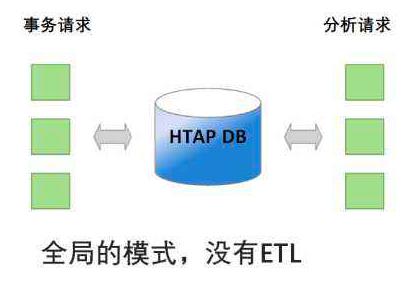
一般来说数据库产品设计会有所侧重的支持OLTP或OLAP业务,而在近年出现了HTAP新型数据库概念,其核心思想是通过一个数据库,解决过去从OLTP到OLAP数据库要经过大量数据抽取入库的问题(如延迟、采购成本、ETL开发等等)。
当前的HTAP产品通过在不同层面进行混合优化实现,比如在存储层同时支持行存和列存、在计算引擎使用不同的优化器技术、硬件隔离解决资源冲突等等。
N0.2
关于Shared-Everything、
Shared-Disk、Shared-Nothing
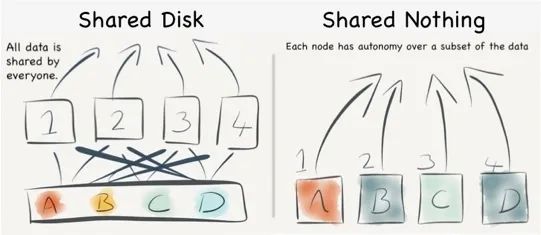
在选型中“架构”因素极为关键,其会带很多扩展性、高可用性和迁移改造难度等细节问题,如果能提前识别相应的风险点,就能更好地提前做好优化措施。
实际上在当前如此多数据库产品的情况下,笔者认为仅凭这三组单词已经很难快速厘清架构的差别(比如pgpool和pg-xc/xl都是Shared-Nothing架构,但实际上有所区别)。
随着技术架构演进、硬件性能提升,这几个概念对数据库集群架构的区分已经很粗颗粒度,因此笔者在下面尝试按个人理解细分下,在具体介绍前先插播两个在架构中常见的术语~
|
扩展性(Scalability) |
scaleup/Vertical 垂直扩展 |
增强单机性能,主要包括: |
|
scale-out /Horizontal 横向扩展 |
增加机器提升性能,主要包括: 2、数据分片到多个节点并行处理 |
|
|
数据分片 |
sharding |
将单表的数据分散到多节点并行处理 |
|
Non-sharding 数据集中 |
全库数据可在单节点集中访问处理 |
首先Shared-Everything架构不做过多介绍,可以理解为单机数据库,CPU、内存、存储全共享,扩展性、并发性差,基本不做考虑。
下面我们着重了解一下工作中经常碰到的两个架构:Shared-Disk/Shared-Nothing。
Shared-Disk共享存储架构
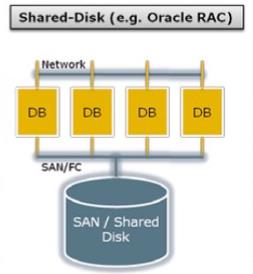
Shared-Disk共享存储架构具有以下几个共同点:
1、计算存储分离
2、节点间共享访问存储
3、节点间CPU/内存资源独享
也可以细分为不同的类型:
Shared-Disk细分
|
典型类型 |
代表产品 |
高可用/扩展性实现 |
存在风险 |
|
多写 |
Oracle RAC |
存储:多副本、RAID、ASM冗余等 计算:服务切换、节点间使用Cache Fusion等技术保障缓存一致性、支持Scale-out |
一般使用双节点RAC,更多节点时可能存在网络性能瓶颈 |
|
一写多读 |
PolarDB |
存储:多副本、RAID 计算:主备切换,节点间使用redo重放等技术保障缓存一致性,支持读节点Scale-out |
✦写节点性能瓶颈,扩展能力有限 ✦主备节点同步性能 ✦一般通过代理实现读写分离,可能涉及应用改造 |
Shared-Nothing不共享架构
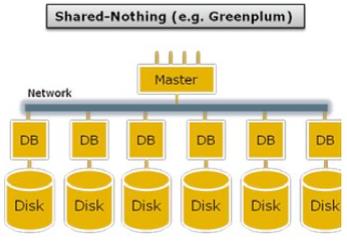
Shared-Nothing不共享架构具有以下几个共同点:
1、计算存储在同一节点
2、节点间CPU/内存/存储不共享
3、多节点并行处理,支持Scale-out
同样也可以细分为不同的类型:
Shared-Nothing细分
|
典型类型 |
代表产品 /解决方案 |
高可用 /扩展性实现 |
存在风险 |
|
Sharding |
分布式数据库:PG-XC/XL、OceanBase、TDSQL、TBase、GreenPlum等 |
数据多副本 一般两级架构(接入节点和数据节点) 支持分布式事务处理 |
✦分表设计对性能影响 ✦跨节点查询、排序性能 ✦迁移改造大,后期维护成本较高 ✦接入层性能风险 |
|
中间件型:Mycat、DRDS等 |
|||
|
Non-Sharding 数据集中 |
中间件型:PgPool |
主从复制/多节点写入 读写分离分担负荷等 |
✦接入层故障/性能风险 ✦节点间同步性能效率 ✦单节点处理性能瓶颈 |
|
集群型:mysql-MGR |
|||
|
主备型:主从式PG/Mysql、或者部分分布式数据库做主备架构部署等 |
另外,网上有大神写了文章[Improving the Scalability of Cloud-Based Reslient Database Servers]用简化模型介绍下几种常见架构,通过定义ProcessEngine(PE)、StorageEngine(SE)、Coordination三个组件的关系得到不同架构的数据库,其中Coordination在不同架构设计中起关键作用,也是各产品大显神通的地方,如复制技术、共享技术等。
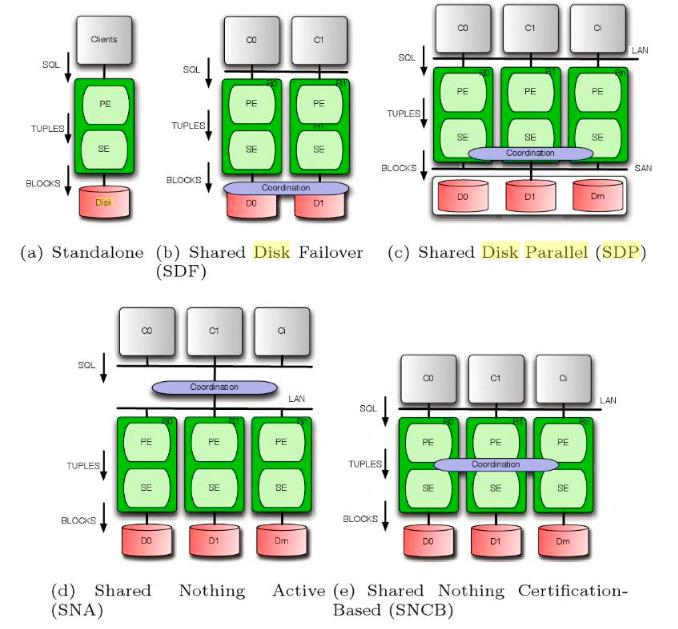
推荐大家深入看看这篇文章,大佬的智慧是最有效的学习资源~
以上就是本期【专治脑壳疼系列】的全部内容啦!
在实际工作中数据库的概念术语所涉及的技术细节或延展内容更多,一篇文章可介绍不完~
想了解更多关于数据库的知识?欢迎大家跟本期大咖沟通交流,下面隆重揭晓本期嘉宾▼▼▼
【本期嘉宾】
∆ 广东移动信息系统部 张炳华
集团运维专家,具备OCM、RHCE等认证,多年业务支撑系统数据库运维经验。现主要负责IT系统数据库建设工作。
欢迎各位热爱技术的小伙伴们移步评论区,小编等你们来battle!
以上是关于专治脑壳疼 | 傻傻分不清各种数据库概念?一文带你理清它!的主要内容,如果未能解决你的问题,请参考以下文章
带你了解 Android的 JIT AOTDalvikART ,不再傻傻分不清