深入解析PostgreSQL数据库架构
Posted 云容灾备份安全治理
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入解析PostgreSQL数据库架构相关的知识,希望对你有一定的参考价值。
PostgreSQL的内部架构,以及各个组件之间如何交互。
一、PostgreSQL的架构
PostgreSQL的物理架构非常简单,它由共享内存、一系列后台进程和数据文件组成。(如下图)
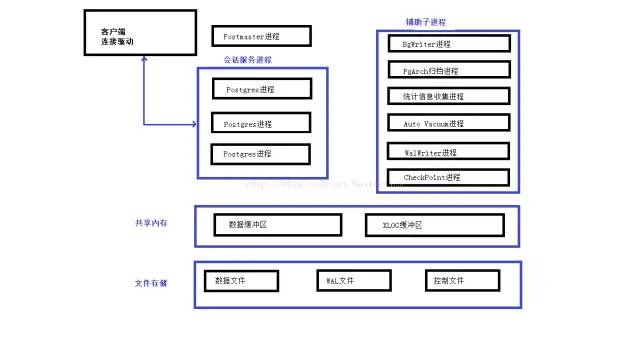
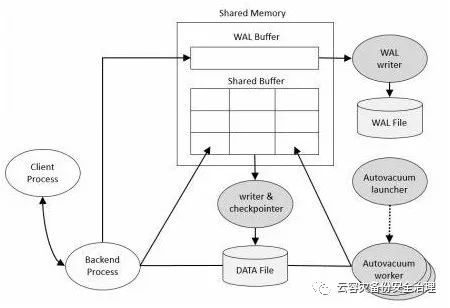
二、Shared Memory
共享内存是服务器服务器为数据库缓存和事务日志缓存预留的内存缓存空间。其中最重要的组成部分是Shared Buffer和WAL Buffer。
Shared Buffer
Shared Buffer的目的是减少磁盘IO。为了达到这个目的,必须满足以下规则:
当需要快速访问非常大的缓存时(10G、100G等)
如果有很多用户同时使用缓存,需要将内容尽量缩小
频繁访问的磁盘块必须长期放在缓存中
WAL Buffer
WAL Buffer是用来临时存储数据库变化的缓存区域。存储在WAL Buffer中的内容会根据提前定义好的时间点参数要求写入到磁盘的WAL文件中。在备份和恢复的场景下,WAL Buffer和WAL文件是极其重要的。
三、PostgreSQL 进程类型
PostgreSQL有四种进程类型
Postmaster (Daemon) Process(主后台驻留进程)
Background Process(后台进程)
Backend Process(后端进程)
Client Process(客户端进程)
Postmaster Process
主后台驻留进程是PostgreSQL启动时第一个启动的进程。启动时,他会执行恢复、初始化共享内存爱你的运行后台进程操作。正常服役期间,当有客户端发起链接请求时,它还负责创建后端进程。
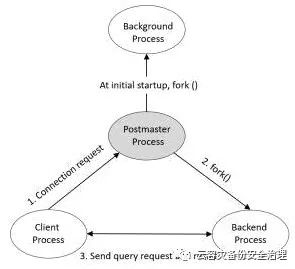
如果通过pstree命令查看进程之间的关系,你会发现Postmaster进程是其他所有进程的父进程。

Background Process
PostgreSQL操作需要的后台进程列表如下:
| 进程 | 作用 |
|---|---|
| logger | 将错误信息写到log日志中 |
| checkpointer | 当检查点出现时,将脏内存块写到数据文件 |
| writer | 周期性的将脏内存块写入文件 |
| wal writer | 将WAL缓存写入WAL文件 |
| Autovacuum launcher | 当自动vacuum被启用时,用来派生autovacuum工作进程。autovacuum进程的作用是在需要时自动对膨胀表执行vacuum操作。 |
| archiver | 在归档模式下时,复制WAL文件到特定的路径下。 |
| stats collector | 用来收集数据库统计信息,例如会话执行信息统计(使用pg_stat_activity视图)和表使用信息统计(pg_stat_all_tables视图) |
Backend Process
最大后台链接数通过max_connections参数设定,默认值为100。后端进程用于处理前端用户请求并返回结果。查询运行时需要一些内存结构,就是所谓的本地内存(local memory)。本地内存涉及的主要参数有:
work_mem:用于排序、位图索引、哈希链接和合并链接操作。默认值为4MB。
maintenance_work_mem:用于vacuum和创建索引操作。默认值为64MB。
temp_buffers:用于临时表。默认值为8MB。
Client Process
客户端进程需要和后端进程配合使用,处理每一个客户链接。通常情况下,Postmaster进程会派生一个紫禁城用来处理用户链接。
四、数据库结构
想要理解PostgreSQL的数据库结构,需要先了解一些重要的概念。
数据库相关概念:
PostgreSQL由一系列数据库组成。一套PostgreSQL程序称之为一个数据库群集。
当initdb()命令执行后,template0 , template1 , 和postgres数据库被创建。
template0和template1数据库是创建用户数据库时使用的模版数据库,他们包含系统元数据表。
initdb()刚完成后,template0和template1数据库中的表是一样的。但是template1数据库可以根据用户需要创建对象。
用户数据库是通过克隆template1数据库来创建的;
表空间相关概念:
initdb()后马上创建pg_default和pg_global表空间。
建表时如果没有指定特定的表空间,表默认被存在pg_default表空间中。
用于管理整个数据库集群的表默认被存储在pg_global表空间中。
pg_default表空间的物理位置为$PGDATA\base目录。
pg_global表空间的物理位置为$PGDATA\global目录。
一个表空间可以被多个数据库同时使用。此时,每一个数据库都会在表空间路径下创建为一个新的子路径。
创建一个用户表空间会在$PGDATA\pg_tblspc目录下面创建一个软连接,连接到表空间制定的目录位置。
表相关概念:
每个表有三个数据文件。
一个文件用于存储数据,文件名是表的OID。
一个文件用于管理表的空闲空间,文件名是OID_fsm。
一个文件用于管理表的块是否可见,文件名是OID_vm。
索引没有_vm文件,只有OID和OID_fsm两个文件
其他需要注意的地方
表和索引创建时文件名是OID,此时的OID和pg_class.relfilenode的值是一样的。不管怎样,当我们执行重写操作时(truncate,cluster,vacuum full,reindex等),被修改对象的relfilenode值也会被修改,文件名也会随着reffilenode值一起改变。我们可以通过pg_relation_filepath('<object_name>')视图很容易的检查文件位置和名称。
五、运行测试
initdb()完成后,如果登录数据库查询视图pg_database,我们可以看到template0 , template1和 postgres数据库已经被创建好了。
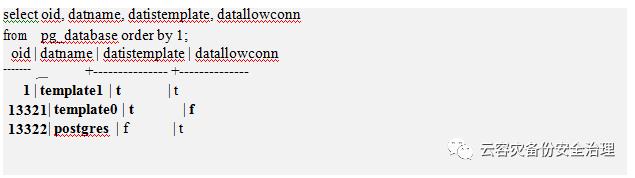
通过datistemplate列,我们可以看到template0和template1是用户创建数据库时使用的模版数据库,其他的都不是模版数据库。
通过datlowconn列,可以看出该数据库是否允许访问。因为template0数据库不能被访问,所以该数据库的内容不能被修改。
设置两个模版数据库的原因是template0是初始状态,而template1数据库则是可以集成用户某些需求的模版数据库。
postgres数据库时使用模版template1创建的默认数据库,如果链接时不指定数据库名称,默认连接到postgres数据库。
数据库存储在$PGDATA\base目录下。路径的名称和数据库OID的名称一致。

六、创建用户数据库
上文提过,用户数据库创建是通过克隆template1数据库。为了验证这个规则,我们现在template1中创建一个表t1,紧接着创建一个mydb01数据库,检查t1表是否在mydb01中存在。

pg_default tablespace
initdb()后,如果登录数据库查询pg_tablespace视图,会发现pg_global和pg_default表空间已经创建好。

pg_default表空间的位置为$PGDATA\base。每一个数据库都拥有一个以自己OID命令的子路径。

pg_global表空间
pg_global表空间用于存储集群级别的数据。
例如pg_开头的表
pg_global表空间路径为$PGDATA\global.
七、创建用户表空间
pg_tablespace视图显示myts01表空间已经被创建好。

$PGDATA/pg_tblspc路径下有一个符号链接指到目标目录。
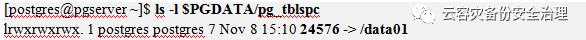
下面分别连接到postgres和mydb01数据库,创建表。

如果查看/data01路径下的内容,会发现上面创建的两个数据库中的t1表,分别在下面有一个对应OID的文件夹存在。
修改表空间位置
PostgreSQL在创建表空间时指定一个特定的路径。因此,如果该特定路径已经满了,数据就不能在向里面存储了。为了解决该问题,我们可以使用磁盘管理程序扩展空间。但是如果不想使用磁盘管理程序,我们可以通过该表表空间的位置来解决该问题。命令如下:
八、Vacuum是什么?
vacuum执行如下操作:
收集表和索引的统计信息
整理表
清理表和索引中的死亡块
被XID冻结,防止XID回绕
#1 和 #2 是数据库管理需要的。#3 和 #4 PostgreSQL MVCC 特性的要求。
九、PostgreSQL和Oracle mysql之间的区别
二者之间最大的不同是MVCC模型和共享池(shared pool)。
| 指标 | ORACLE | PostgreSQL |
|---|---|---|
| MVCC模型 | UNDO | Store previous |
| 实现方法 | Segment | record within block |
| 共享池 | exists | it does not exist |
MVCC模型的区别
为了增加并发,必须遵循“读操作不阻塞写操作,写操作不阻塞读操作”的原则。为了实现这个原则,多版本并发控制(MVCC)理论被引入。Oracle使用UNDO段实现MVCC。而PostgreSQL存储之前的记录在数据块中,它通过事务XID和事务的xmin、xmax来控制事务版本。
Shared Pool
PostgreSQL不提供共享池。这对于熟悉Oracle的用户来说有点尴尬。共享池是Oracle中最基本和最重要的组件。PostgreSQL在进程级别提供SQL信息的共享能力,而不是共享池。换句话说,如果我们在同一个进程中多次执行相同的SQL,它只会硬解析一次。
以上是关于深入解析PostgreSQL数据库架构的主要内容,如果未能解决你的问题,请参考以下文章
一篇掌握MySQL ,Oracle和PostgreSQL数据库体系架构