大数据学习深入源码解析MapReduce的架构及实现过程
Posted 牛哥不牛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据学习深入源码解析MapReduce的架构及实现过程相关的知识,希望对你有一定的参考价值。
这几天学习了MapReduce,我参照资料,自己又画了两张MapReduce的架构图。
这里我根据架构图以及对应的源码,来解释一次分布式MapReduce的计算到底是怎么工作的。
话不多说,开始!
首先,结合我画的架构图来进行解释。
上图是MapReduce的基本运行逻辑。把图从中间切分,左边为Map任务,右边为Reduce任务。Map的输出是Reduce的输入。因此Map执行完毕Reduce才能执行,两者的执行顺序是一个线性关系,即输入输出的关系为:HDFS->Map->Reduce->HDFS。
在Map阶段,多个Map可并行执行,Map数量越多,执行速度越快。
在Reduce阶段,也可设置多个Reduce,但Reduce设置的大小依赖Map计算后的分组数量决定。换言之,在不破坏原语(“相同”的key为一组,调用一次reduce方法,方法内迭代这一组数据的计算)的情况下,Reduce程序数量由大数据研发人员确定。
这里举个例子:假设,有两台机器,有5个不同组的Map结果,Reduce的程序数量有以下A、B两种情况。A:一台机器中启动3个进程每个进程为一个Reduce程序,一台机器中启动2个进程,每个进程是一个Reduce程序B:两台机器各启动一个进程,每个进程是一个Reduce程序请问哪种情况效率更高?在机器为单核的情况下,采用B进程,因为若采用A方案,会涉及到进程切换以及争抢资源的损耗,反而不如直接用单进程跑划算。在机器为多核的情况下,采用A进程,因为当核的数量够的情况下,每个进程可独立运转,就允许并行计算,效率就会提升。所以说,Reduce数量的配置也是可以考验一个大数据研发人员水平的。
左边的每一个虚框中,都有split,意思是切片。根据图,可以得出,一个切片对应一个Map程序。切片通俗来讲,就是一个Map程序处理目标文件多大的数据,它采用的是窗口机制,可大可小,这是由大数据研发人员根据实际业务需求来进行确定的。在默认情况下是文件的一个块的大小。同时,切片会将数据输入格式化,变成多条记录流向map程序。换言之,以一条记录为单位调用一次map程序。在map任务执行完毕后,会输出key,value的映射对。
举个例子。假设,要处理一个文件中男性和女性的人数。原文件内容有5行,内容如下:张靓颖罗志祥蔡徐坤那英刘欢那么,经过map之后,每一行对应map的k,v输出为:女:1男:1男:1女:1男:1
在map输出成(k,v)之后,每个map会将输出的数据根据组进行排序,相同的key排成一组,等待Reduce程序进行拉取对应组的数据。
这里,需要注意,map的输出可以没有排序,但是有排序和没有排序会造成整个框架的效率的天壤之别。因为根据MR原语,相同的key为一组,进行Reduce计算若没有排序,Reduce每一次拉取都需要遍历各个map节点的输出的全部数据,时间成本大大增加!在大数据的背景下,不做排序几乎就要了整个分布式计算框架的命!
再看Reduce阶段,首先根据MR原语,Reduce要通过http协议请求拉取属于自己组的map输出结果。(这是一次网络IO操作,这里也是可以进行优化的地方,后续在讲。)
对于每一个Reduce而言,拷贝完之后生成的是一个内部有序外部无序的输入数据,之后进行归并排序,将同组文件放一起,就生成了可用于计算的数据序列。在将数据处理好之后,开始执行Reduce的方法,最终生成结果文件,传入HDFS中保存。
一个小总结,总结一下MR中的一些对应关系
1、Block和Split的对应关系- 1:1- N:1- 1:N2、Split和Map的对应关系- 1:13、Map和Reduce的对应关系- N:1- N:N- 1:1- 1:N4、Group(key)和Reduce的对应关系- 1:1- N:1- N:N5、Reduce和Output的对应关系- 1:1
再给个例子巩固一下
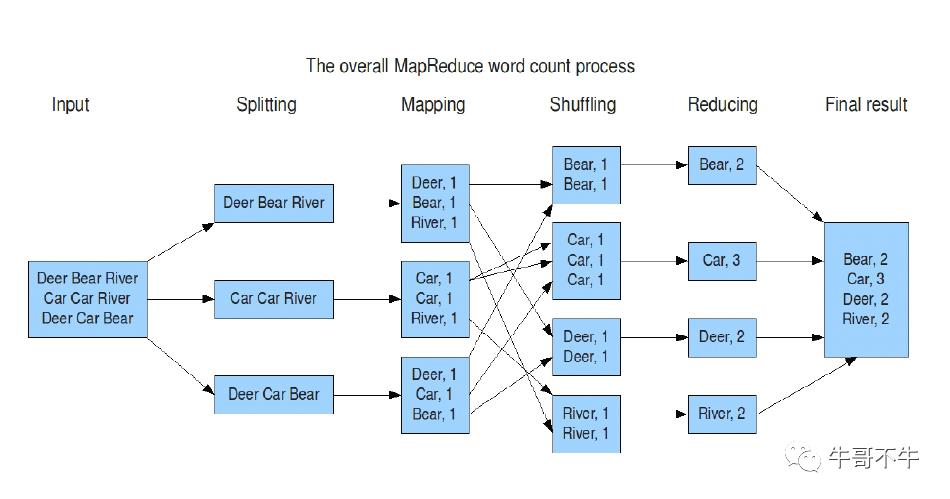
这里给出我画的更细致的架构图。
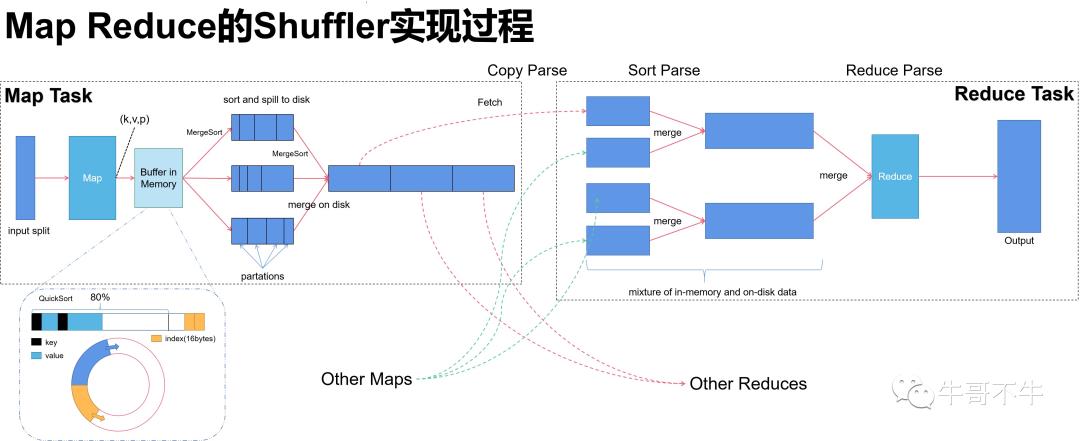
上面几段是一个很粗略的MR架构过程的分析,接下来细讲,这里结合源码。
首先,补充一个内容。
在map的输出阶段,输出了(k,v)之后,马上会调用一个算法,计算该输出属于哪个Reduce任务,所以实际上,map的输出为(k,v,p),p代表属于哪个Reduce任务,Reduce直接根据p的信息进行拉取操作。另外,map产生的中间的数据结果的存储在对应执行的主机的磁盘中存储,不经过HDFS。
开始细讲,这里分三个部分讲,分别是Client阶段、Map阶段、Reduce阶段。
Client阶段
在客户端开始运行后,主要功能是创建了一个job实例,并通过各种配置把这次的任务个性化,最后提交job给集群做计算
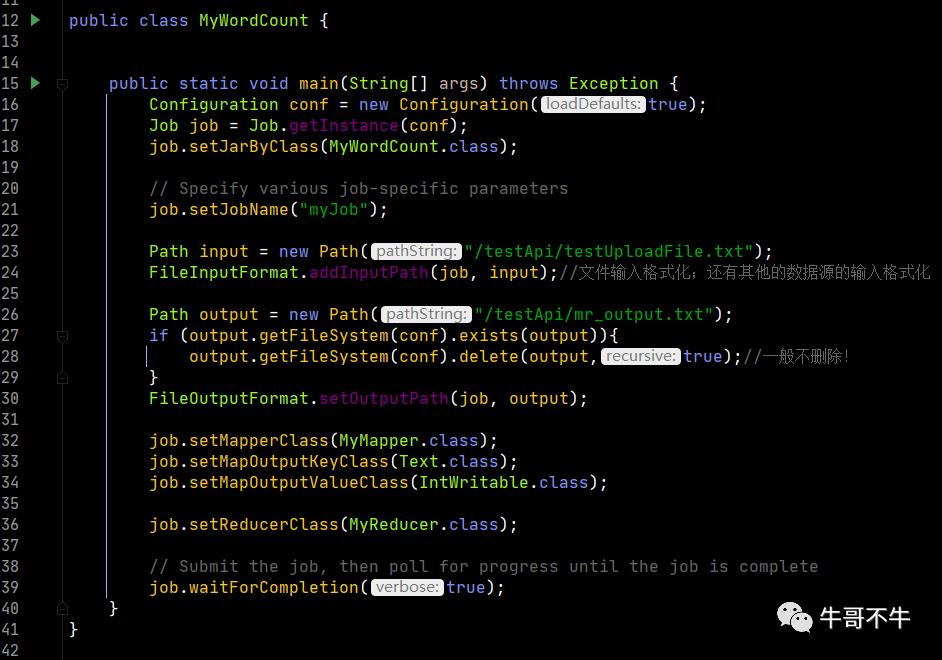
上图是客户端的代码
第16行和17行创建了配置对象以及根据配置对象创建job对象,然后指定要执行的方法类,设置此次任务的job名称。
第23行至36行对数据的输入输出进行格式化,为后续的计算做准备。
最后第39行,执行提交方法。
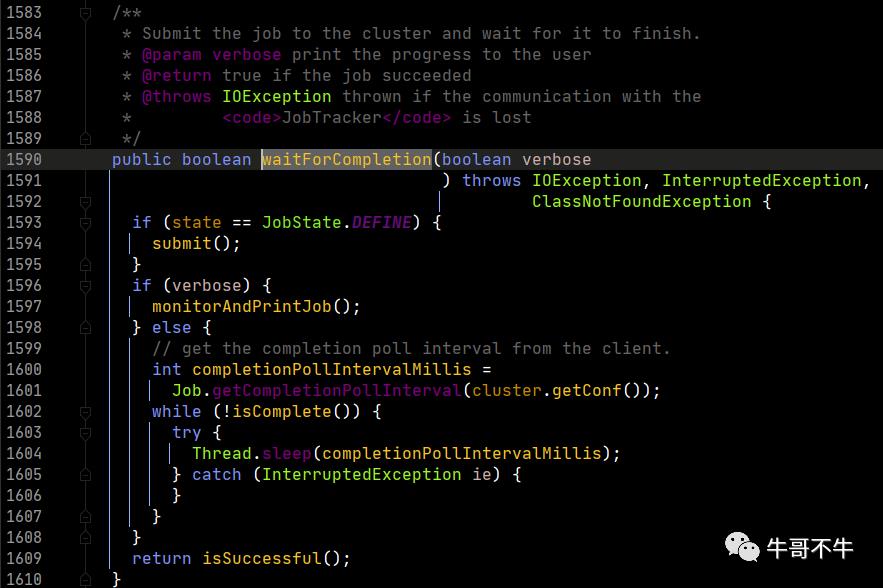
1590行,这个submit是真正提交的函数,之后要看。
下面首先根据传入的变量进行判断,如果为true则执行monitorAndPrintJob方法,即监控并打印job执行过程。最后该函数返回的是一个执行状态。
我们来看submit函数的实现。
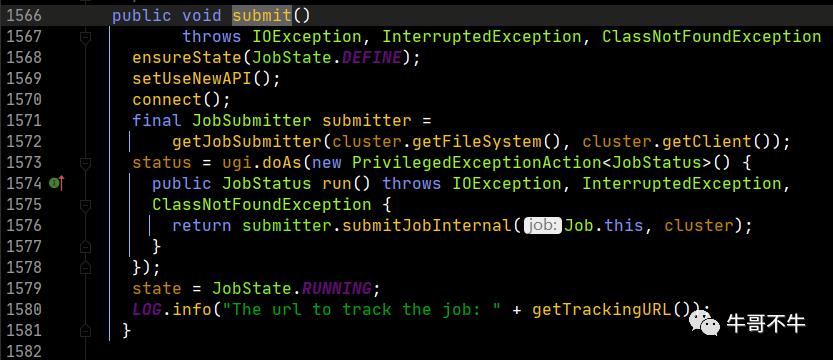
第1569行会判断是否执行新的API,这是因为第一版的hadoop和第二版的hadoop在计算上有变化,第一版叫做mapread,第二个版本才叫做mapreduce,因此为了兼容两个版本,直接新写一个函数。
第1570行是connect函数是调度层的事情,对集群进行连接,是对yarn的通信调度过程,这里不展开讨论。
第1576行返回一个JobSubmitter的对象方法,方法中包含全部job的运行逻辑,这里是一句关键代码。官方给的注释也写得明明白白,客户端一共要干5件事情,分别是检查输入输出、为job计算切片信息、设置账户信息、拷贝job的jar文件和配置到各个mapreduce计算节点上、监控job作业。
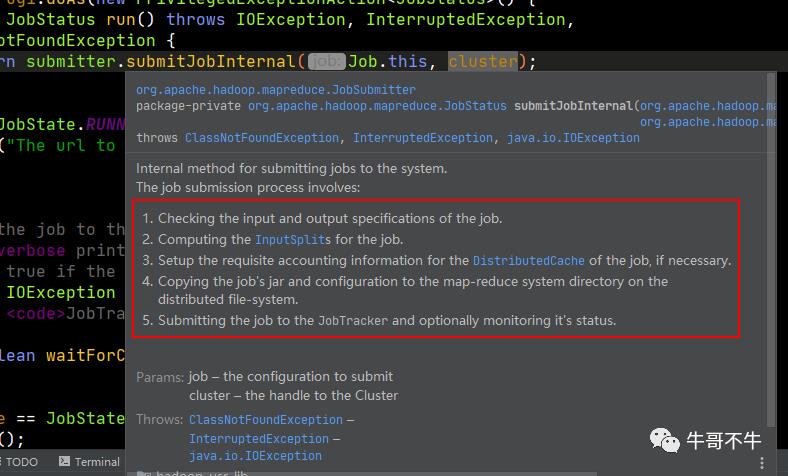
我们来看submitJobInternal

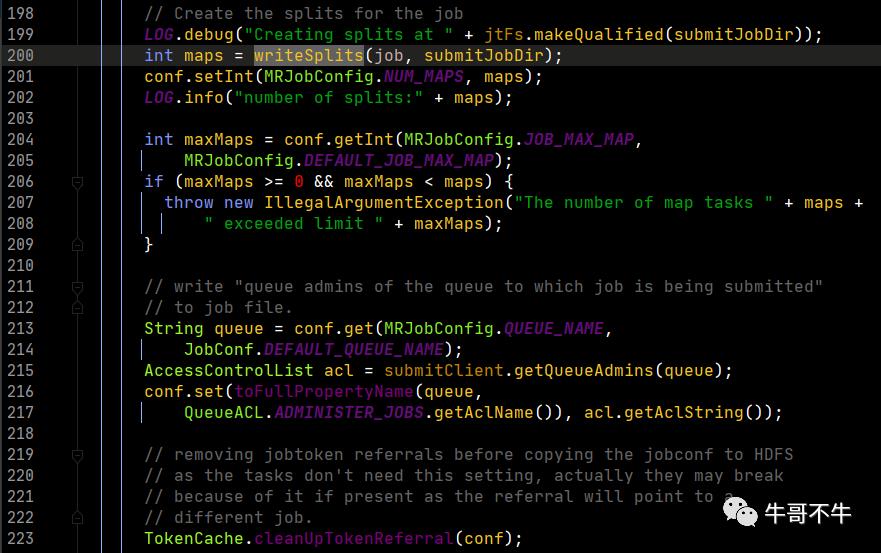
由于方法中内容太多,摘主要的进行分析。
看第200行,有一个writeSplits方法,这个方法就是要书写切片信息,这是一个关键方法,我们打开看看。
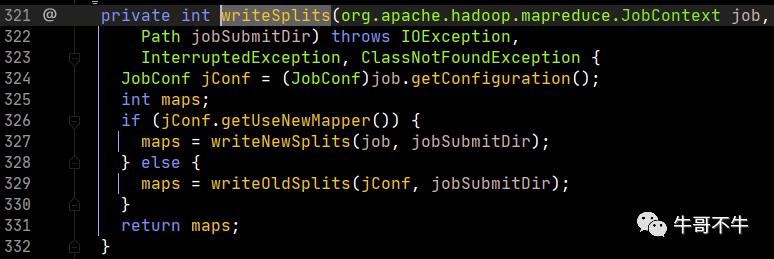
这个函数中根据判断会调用不同的计算方法,判断依据就是是否使用新的API。我们打开writeNewSplits方法。
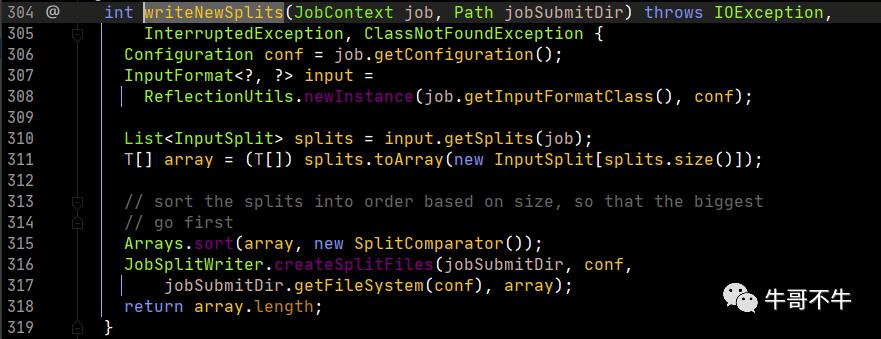
这里第306行,拿出job对象的配置信息实例化一个新的配置对象;然后看307、308行,要产生一个InputFormat的对象。产生这个对象的原理利用Java的反射机制。框架运行的个性化就是靠动态的反射机制来实现的,这种方法在框架源码中会大量出现。
我们来看看getInputFormatClass()这个类的实现。

第175行,意思是通过配置对象中是否存在INPUT_FORMAT_CLASS_ATTR的配置来获取信息,如果没有设置则读取第二个参数的信息进行返回。
跳回至writeNewSplits方法中,继续讲解。
根据阅读源码,我们应该知道框架默认应该返回文本的输入格式化类,即TextInputFormat
我们看310行getSplits()的实现。
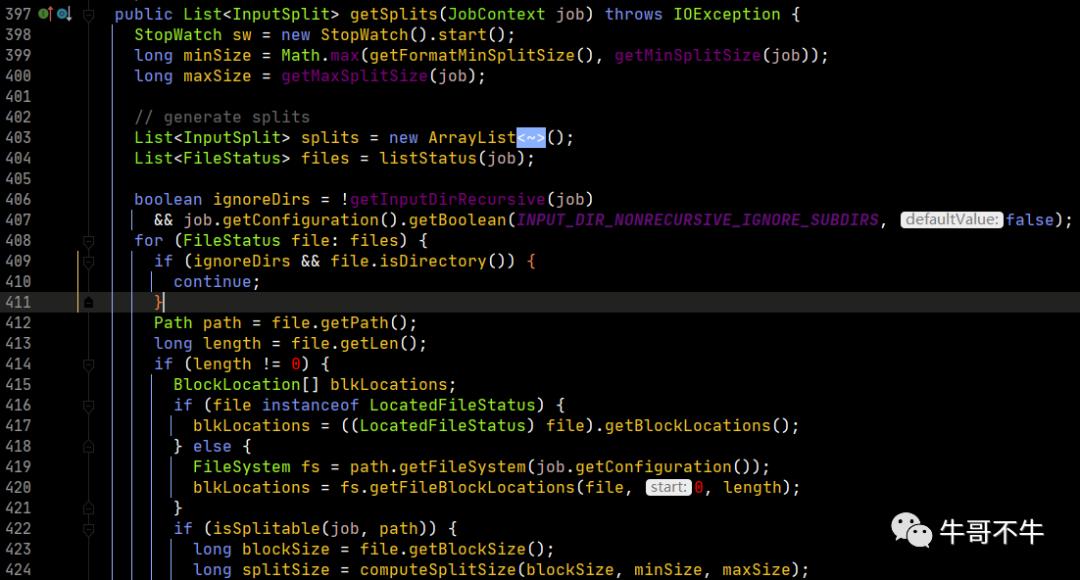
可以看到,第399行和第400行有两个变量,需要注意这两个变量的值是如何计算出来的。首先,minSize是通过getFormatMinSplitSize(), getMinSplitSize()两个方法的返回值的最大值得出来。分别进入两个方法中,看其返回值。


一个返回1,另一个通过先获取用户配置,若无则返回1。
因此,在框架默认情况下,minSize为1。
再看maxSize

这里,通过配置对象取用户的配置信息,若没有则返回Java的Long变量的最大长度
因此,在框架默认情况下,maxSize为一个非常大的数,具体就是Long变量的最大值。
继续返回getSplits函数查看。
第403行起,函数开始进行切片的生成,首先创建一个切片的序列对象。
第404行,FileStatus是HDFS的对象,因此这里的含义是生成一个包含全部要计算文件的的列表(元信息)。
第408行,开始进行for循环,迭代每一个文件进行切片的处理。因此,通过阅读源码,我们知道,切片不可能会跨文件,因为每个文件都是单独处理的。
第412行,获得文件在HDFS上的路径。
第413行,获得文件的大小。
第414行,判断文件是否为空,不为空进行计算,为空则创建一个长度为空的切片信息,用于对该空文件进行占位。
第419行,通过配置对象的返回的配置信息调用得到一个分布式文件系统对象。
第420行,取出文件所有的块。
第422行,首先判断文件是否允许切片,因为在HDFS文件中,有些文件被压缩或其他格式,切片之后也是乱码,无法读取,因此切片不适用,只能拿到全部的块组装成一个文件后进行操作。
第423行,若允许切片,则首先得到每一个块的大小。
第424行,切片的大小通过computeSplitSize函数决定,看其实现如下

我们分析框架默认的情况。当默认情况下, 首先maxSize是Long的最大值,非常大,blockSize肯定小于maxSize,因此两者取最小,则为blockSize,然后minSize为1,取最大值的情况下,返回blockSize的大小。所以,通过源码分析,框架默认切片大小等于文件块的大小。这里,可以继续深入一下,当我们需要切片比块小的情况下,改大值,当需要切片比块大的情况下,改小值。
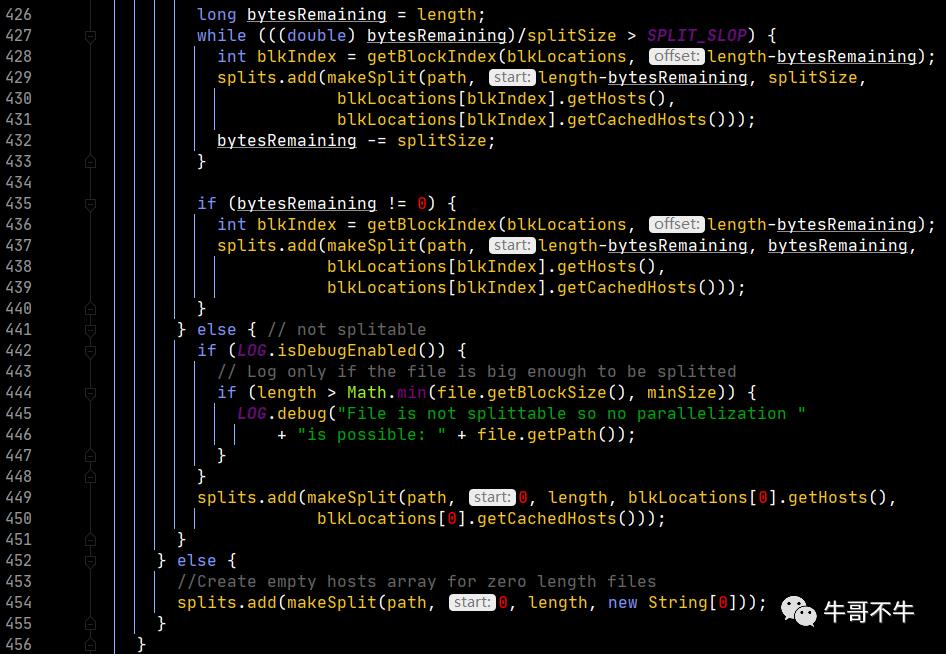
第426行,定义一个变量,值为一个文件的长度,后面的执行会用到。
第428行,length-byteRemaining为偏移量,第一次循环值为0,第二次循环,由于第449行的存在,其值为一个切片的大小,以此类推。这样得到了一个块的索引。这里需要注意以下,切片的偏移量,一定是大于等于一个块的起始偏移量,小于等于一个块的结束的偏移量,用人话说就是切片的偏移量要包含在块的偏移量之内。getBlockIndex函数有实现,这里不看了。这里其实还可以更深入,考虑切片大于和小于一个块的情况,不过这里暂时略过。
第429行,根据计算好的偏移量信息和块信息创建切片并添加至splits这个切片序列对象中。我们看一下这个makeSplit函数的参数,前4个参数是一个切片最核心的信息。
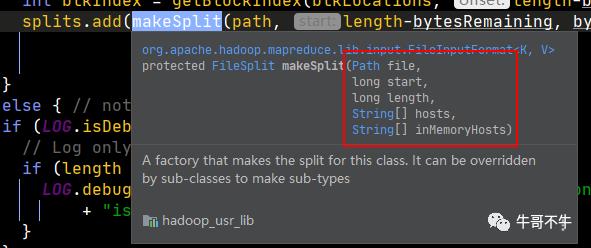
file,是该切片属于哪个文件;start是切片的起始偏移量;length是切片的大小;hosts是块的位置信息,其实就是实现了将块的位置信息赋值给了切片。
有一个切片,信息分别可以是1,0,4,[1,2,6]1,代表文件标识0,代表起始偏移量4,代表切片大小[],代表这个切片对应的块的副本的位置
到这里,基本上源码分析就差不多结束,从开始到这里,都是客户端要做的事情,做完之后将配置、jar以及切片信息上传至ResorceManager,然后进行后续调度,这里按住不表。
Map阶段
我们先来看MapTask中的run方法。
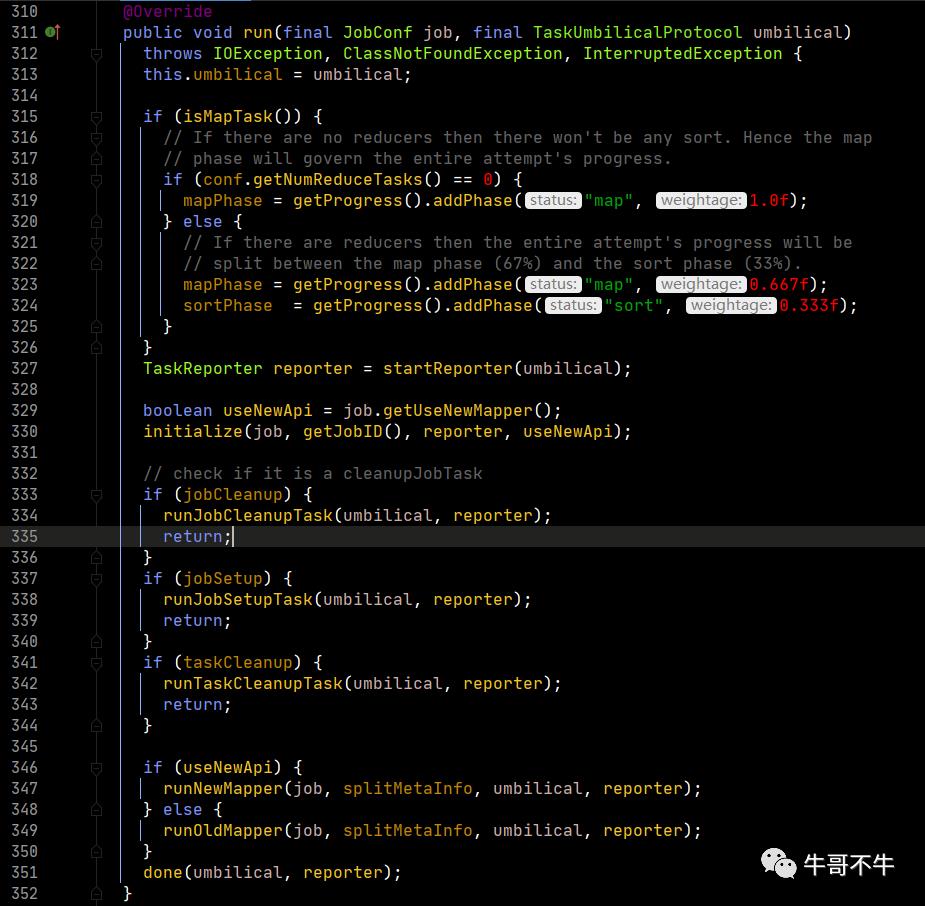
第318行,从配置信息中取reduce任务的数量并判断是否为0,即没有reduce阶段,则定义整个过程不调用reduce阶段。如果有,则进入下面的设置。
第323、324行,设置在存在reduce任务的情况下,除了有map阶段外,还有sort阶段。
然后跳转至347行,进入runNewMapper。
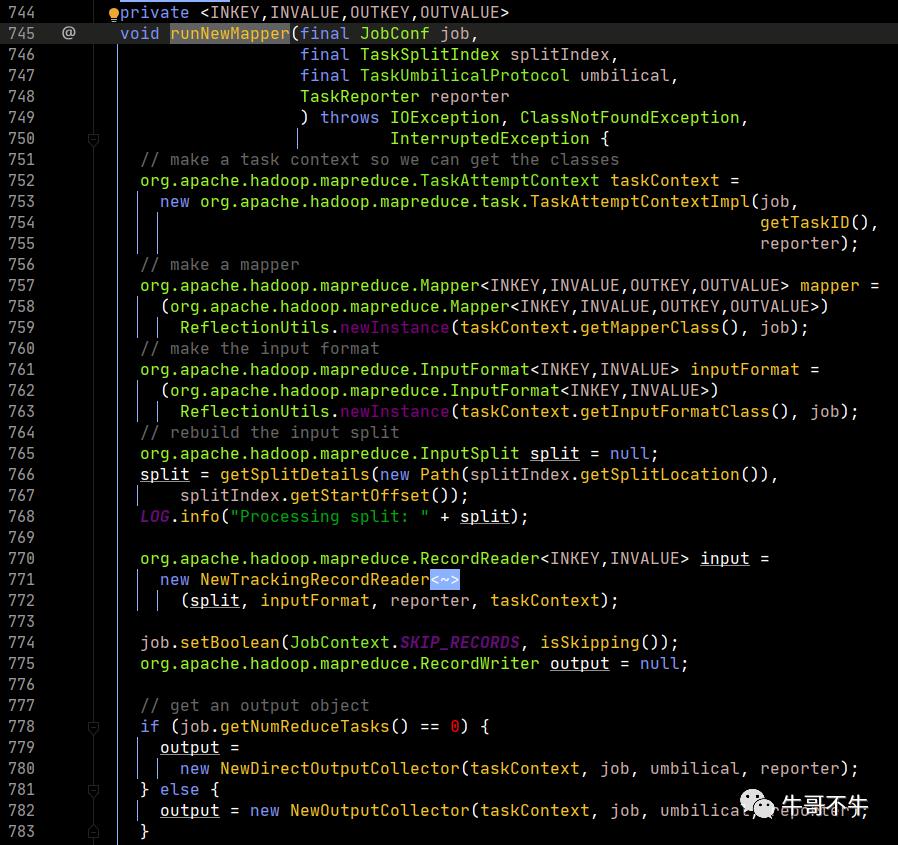
第752行,初始化任务上下文,里面包含了job对象。
第757行,通过反射,实例化一个map对象。这里根据研发人员在配置信息中指定的mapper类来进行。
第761行,通过反射,实例化一个输入格式化对象。这里根据研发人员在配置信息中指定的输入格式化类来返回,默认返回Text的输入格式化类。
第766行,生成一个切片对象。
第771行,创建一个输入格式化记录读取器对象,该对象默认返回一个行记录读取器,即LineRecordReader。这个类中有三个方法,经常被使用,即nextKeyValue、getCurrentKey、getCutrrentValue。
我们可以看一下实现。
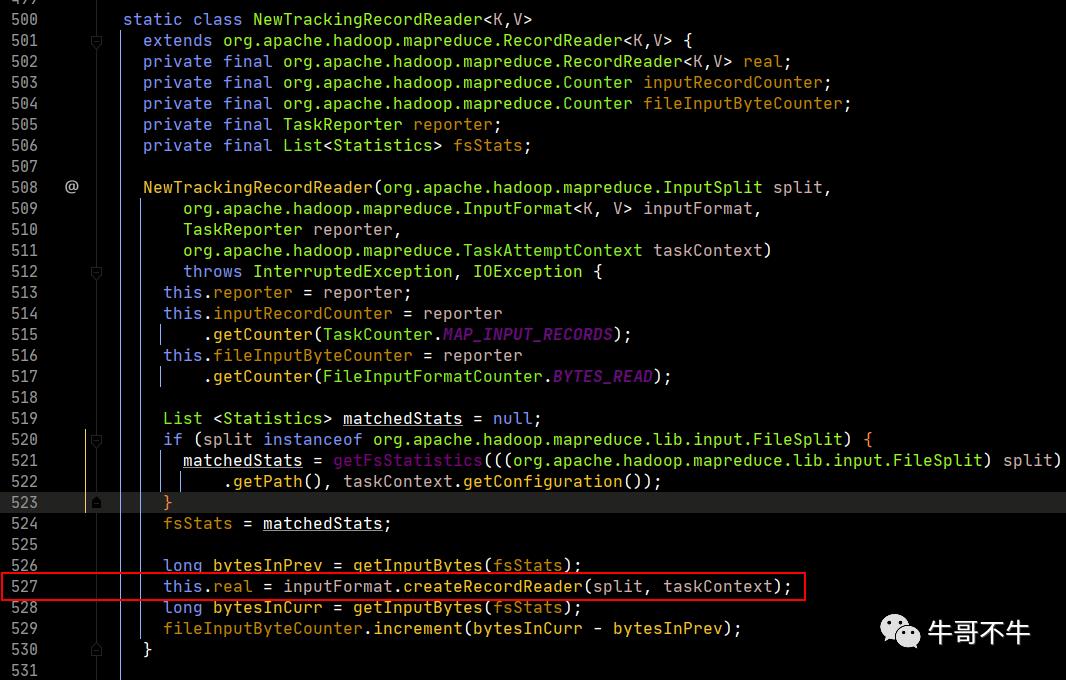
在第527行,记录读取器real被输入格式化对象创建记录读取器,这里我们再打开createRecordReader方法,看最终返回。
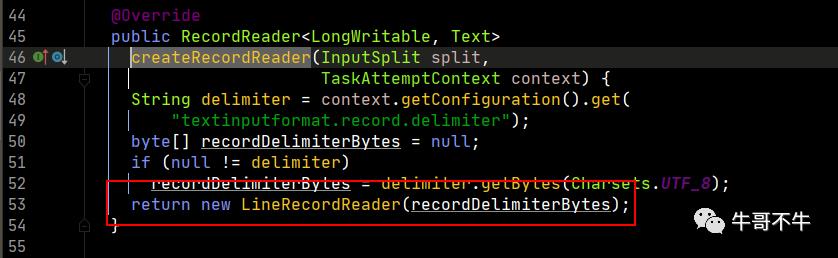
所以,最终干活的是LineRecordReader对象。
返回来,继续看。
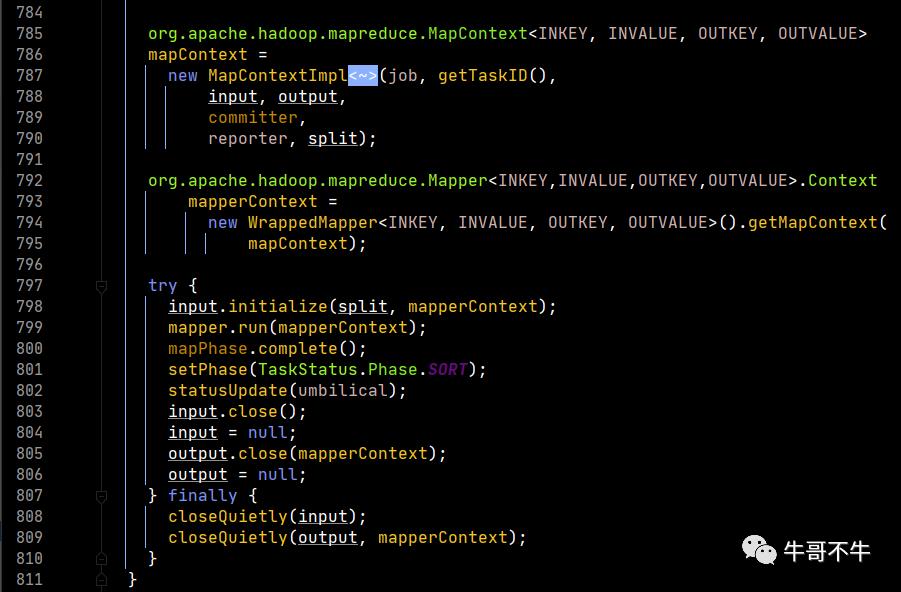
第786、787行,创建了map的上下文对象,这里传入的input,在框架默认情况下就是LineRecordReader。
第798行,首先进行输入初始化。因此map程序必须是输入初始化变为序列后,才执行map程序。
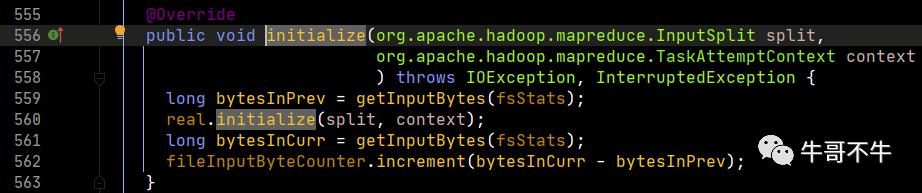
这里能够发现,真正的初始化是real的初始化,而real就是LineRecordReader,我们继续看这个初始化函数的实现。
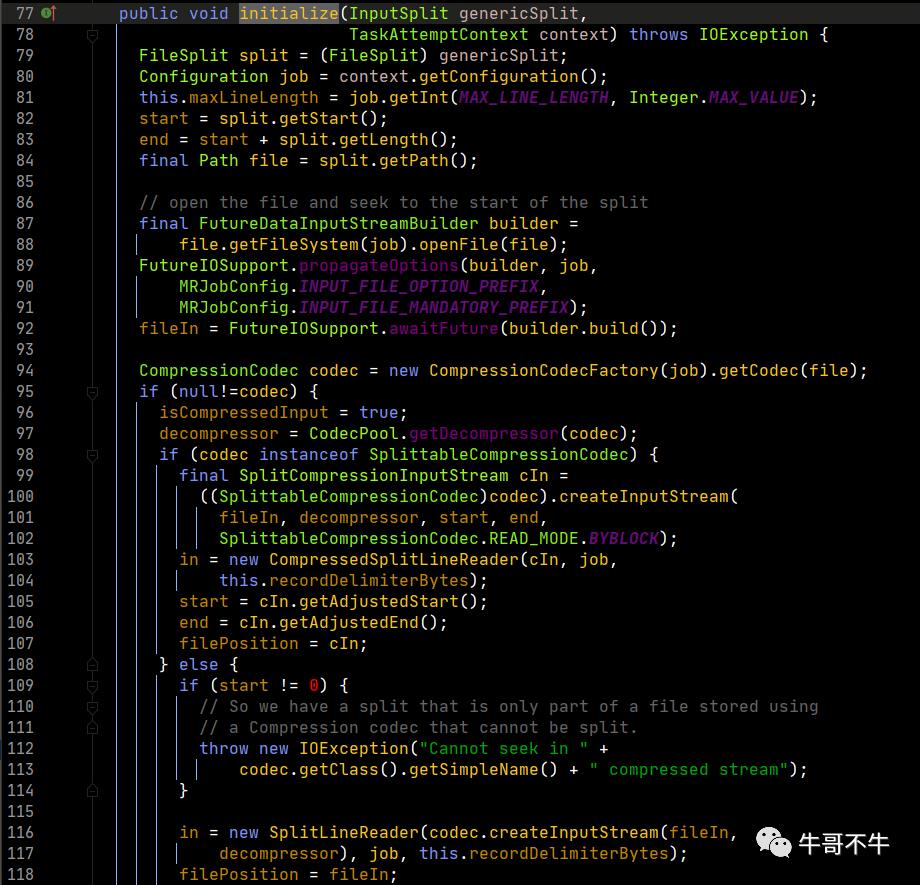
第81行,获得行数
第82行,获得切片的起始偏移量
第83行,获得切片结束的偏移量
第84行,从切片中获得对应的文件路径信息
第87行,获得HDFS的对象
第92行,获得对程序的输入流
第121行,定位到对应的起始的偏移量。这样每个map读取的文件都是自己对应的文件,和其他map就不会冲突。
第122行,获得的IncompressedSplitLineReader对象就是真正可以进行读取文件内容的对象。
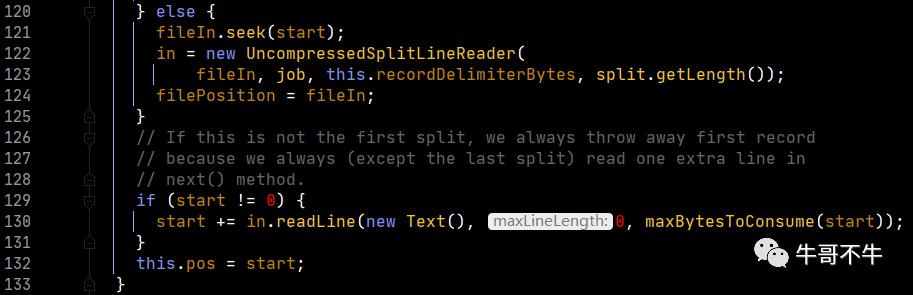
第129行,判断是否是读取第一行数据,不是则进入方法,是则跳过。目的是维护数据的完整性!因为HDFS文件切块时,可能会把连起来的一句话切到不同的块中,因此map在计算时,会默认开始读取第二行。而第一行的数据通过上一个切片的末尾进行补全后计算。这里比较重要!
第130行,in.readLine()返回读到了多少个字节,然后加上start就获得了新的偏移量
第132行,将start信息赋值给pos。
回到之前的RunNewMapper的方法。
第799行,执行mapper的run方法
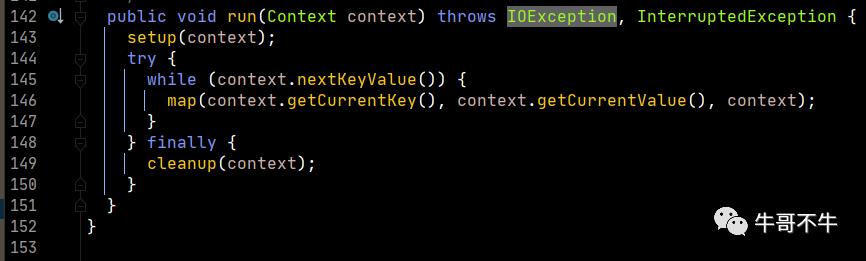
第143行,首先设置上下文对象,context包含了map任务的输入和输出信息。
第146行,将map对象中添加key和value的值,然后执行map方法进行计算。
不过这里需要注意一下,while循环判断中的nextKeyValue主要功能就是对key和value做了一次赋值操作,具体可以对源码再次打开查看,这里不详细展开了。
回到runNewMapper方法。
第800行,设置map阶段结束。
第801行,开始设置排序阶段。
第803-806,对输入输出置空。
这里就是map中最核心的代码,就干了两件事情,计算+排序。
接下来,看一下map的输出阶段。
第777-783行,构造了一个output实例,打开NewOutputCollector对象。
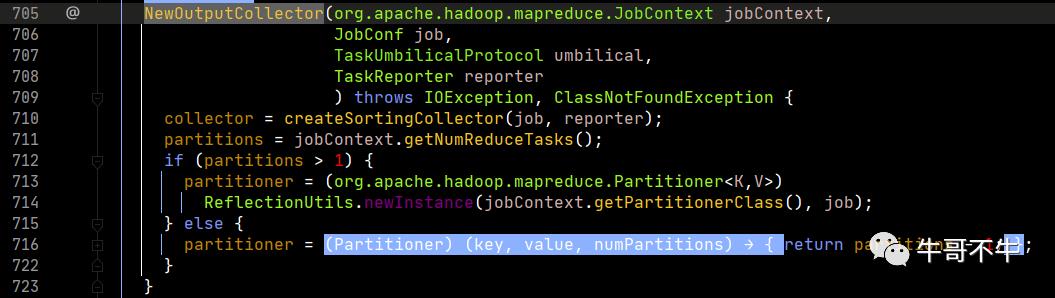
第711行,创建了一个分区的数量,也就是reduce的任务数量。
第712-723行,如果分区数量等于1,返回分区号0;若大于1,则查看用户是否设置,不设置默认返回hashPartitioner,这种方式会破坏数据原有的序列特征。
由于我们mapper类输出使用write进行输出,这里看一下write的实现,就会发现上面的partition是有用的。

我们看到,map输出就会输出k,v,p三个维度的值。
回到之前的方法,看一下collector的构造。
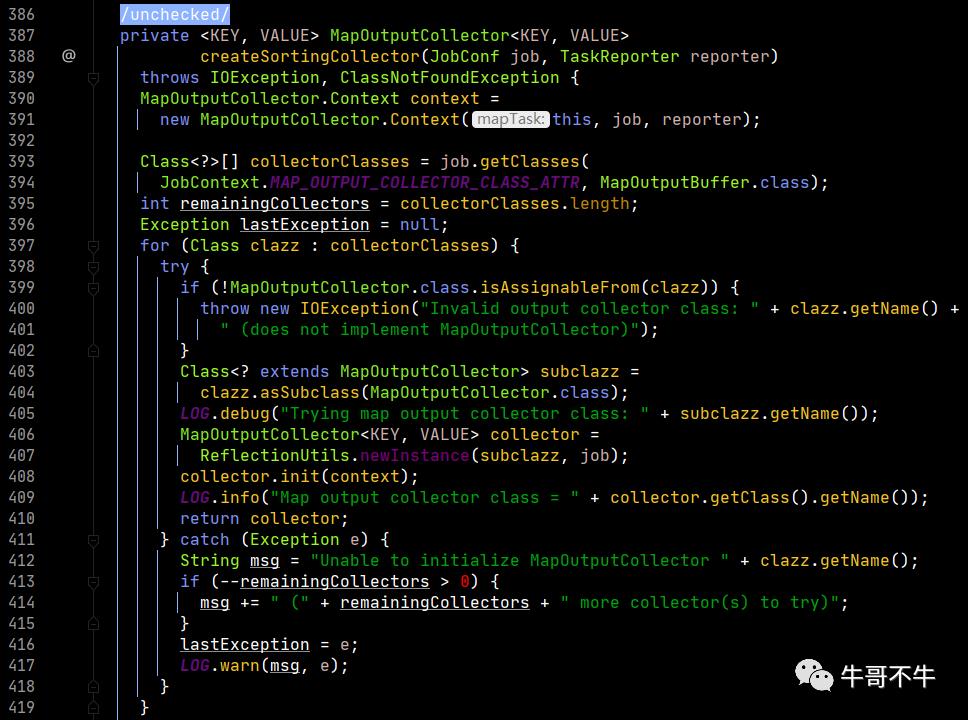
这个collector最后定位到了第393-394行,框架默认为MapOutputBuffer类,这里就联系到了缓冲区。
第408行,对collector进行了初始化,起始就是对MapOutputBuffer进行了初始化,我们看其实现。
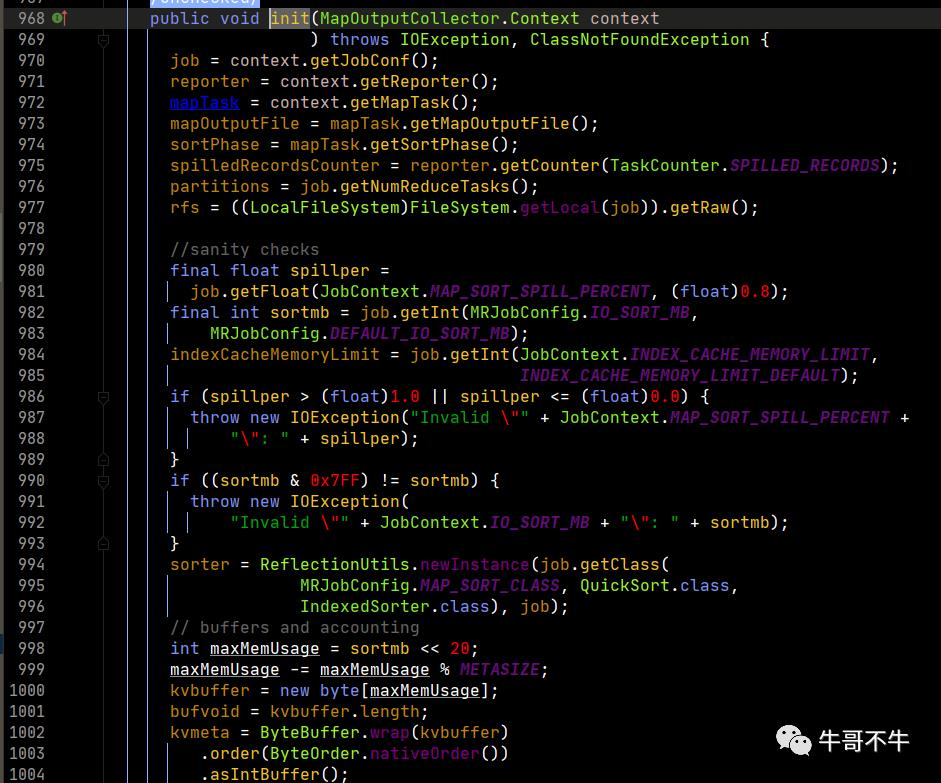
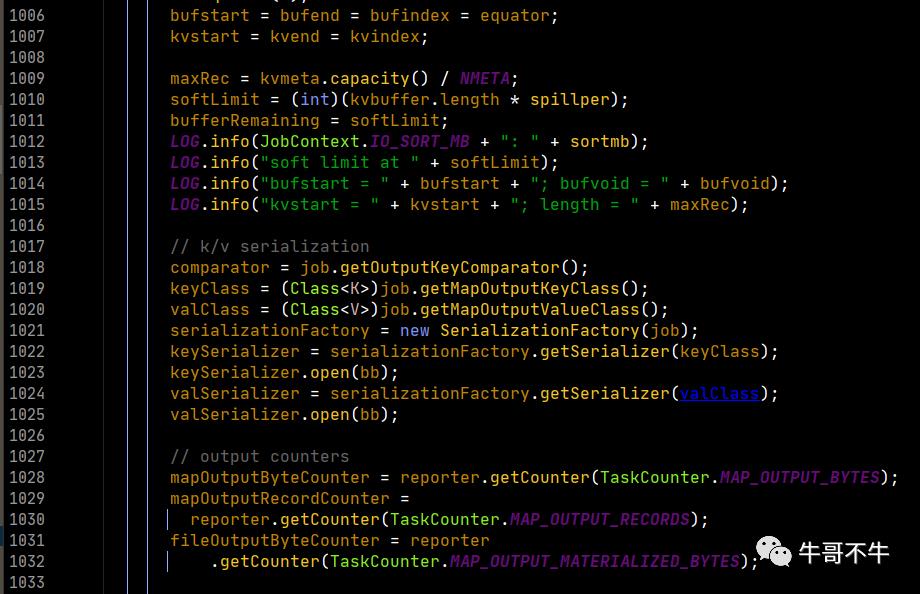
我们注意第980-981行,定义了一个spillper的值,定义了一个异写的百分比,80%。这里需要解释一下,80%是可以变化的,也是大数据开发中调优的一个点。当然,这个80%就是说当map输出大小到达缓冲区的80%之后,这80%的数据被锁定,进行本地磁盘的写入,同时,将map输出向20%的容量中继续写。这里就会压缩了写入磁盘的时间,因为有部分时间时同时进行本地磁盘的写入和缓冲区的写入工作。
然后注意到,第994-996行在缓冲区的数据的排序默认使用了快速排序算法。同时需要知道的是,在向磁盘写入的过程之前,框架就会在缓冲区内将80%的数据进行快速排序,变成一个有序的数据。
由于排序一定用到了比较,因此这里就需要一个比较器。第1018行就定义了一个比较器,看一下其实现。

当用户有配置比较器时,返回用户配置的;没有配置时,默认返回Map的key自身的接口的比较器。因为Map在数据序列化过程中也是需要比较器的。
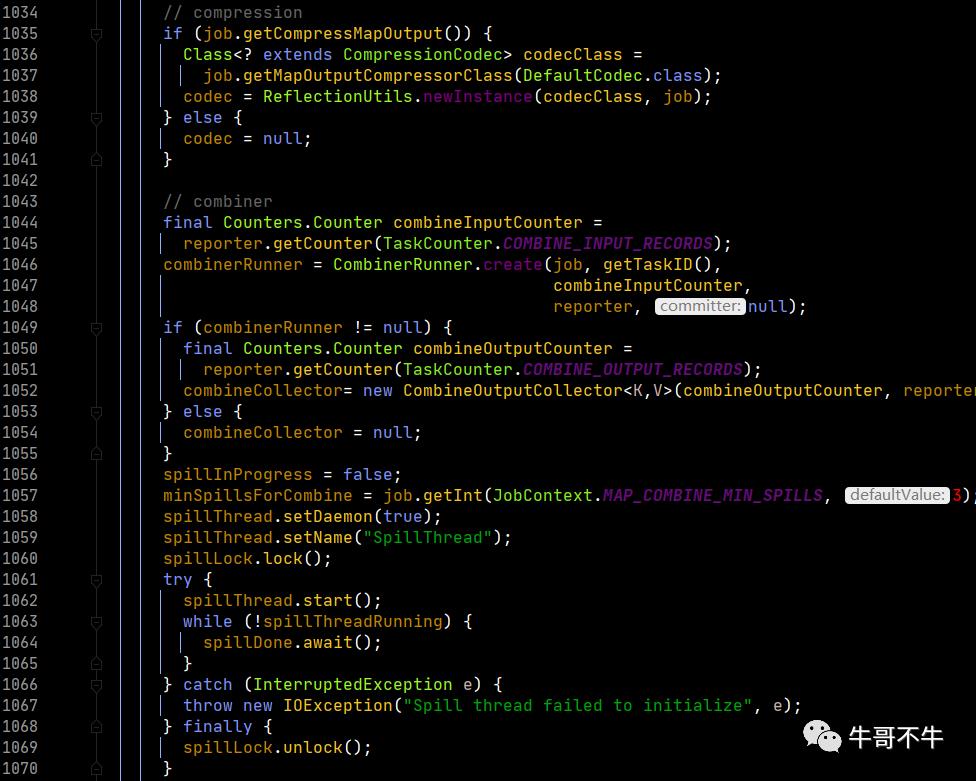
回到之前的函数,第1044-1045行,设置了一个combiner。目的是压缩数据,将重复的数据进行压缩,编程一个更小的数据,这里就是一个优化的点。这样做的好处就是减少了之后输出到磁盘的时间以及Reduce的I/O时间。这里的Combiner的原理类似于Reduce。Combiner的执行是在快排之后,写入磁盘之前进行。或者在向Reduce传输之前进行。
这里解释一下什么时内存缓冲区。
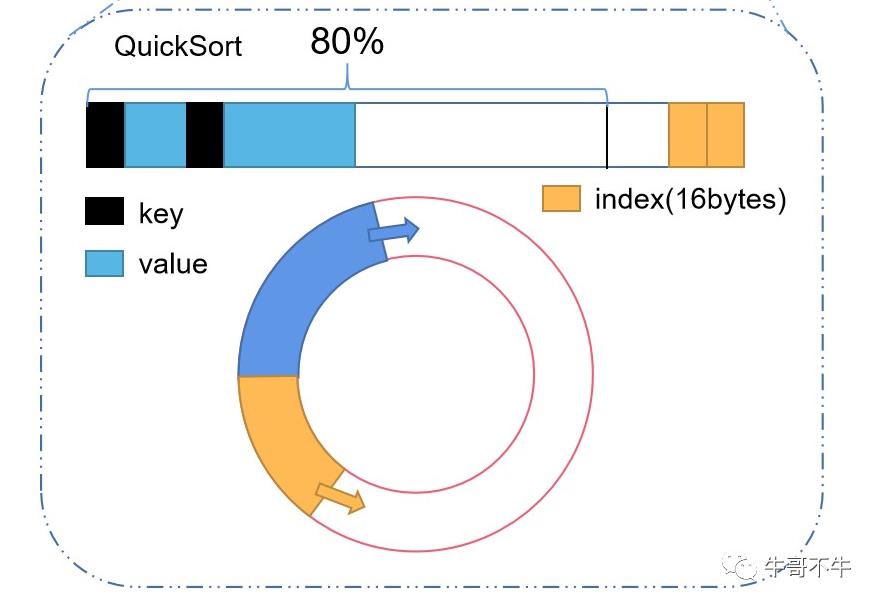
这是一个内存缓冲区,前面的kv对进行写入,后面的索引从尾部开始往回写。到达80%的情况后,锁定80%的内容进行后续的异写,在20%的空间继续写。为了能够循环往复的进行操作,将上述的缓冲区换成下面的环形,这样当到达80%的情况后,将剩余的部分中间切开,然后kv对从切开的部分往一个方向写,索引信息从切开的部分往另一个方向写,只要保证在20%没有被占满的情况下,80%的写入数据完毕就可以实现无限的循环往复。
这里,源码的阅读基本结束,一个map的任务基本介绍完毕。
Reduce阶段
首先看一下官方怎么介绍这个阶段。
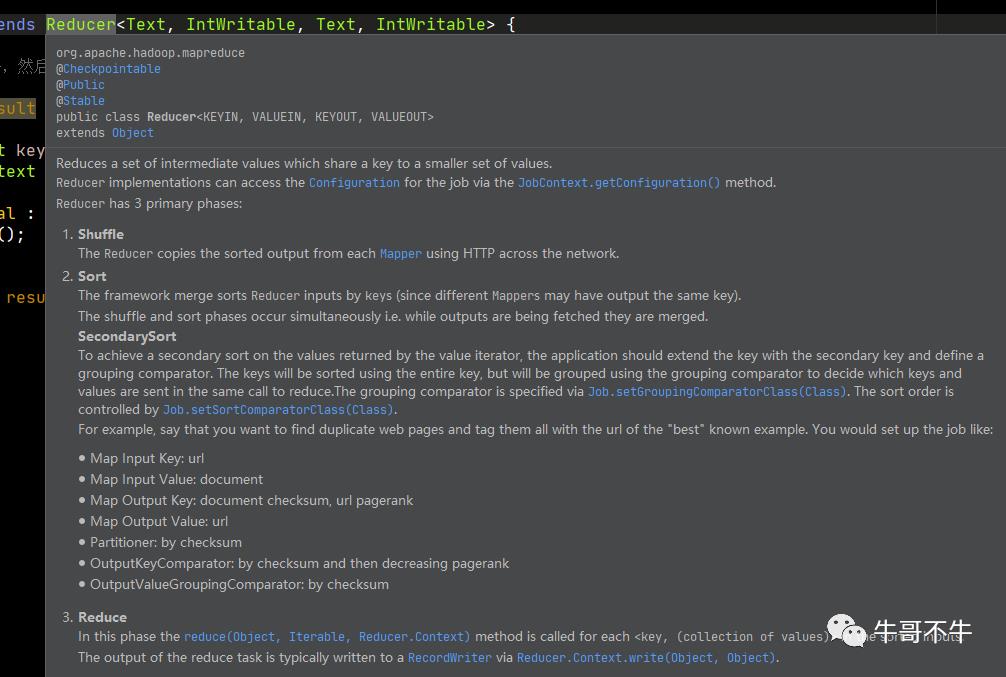
有三个阶段,洗牌、排序、Reduce。我们看Reduce源码,重点要知道如何实现Reduce的运行逻辑,还要知道如何规避内存溢出。
好了,我们继续,坚持就是胜利!
我们首先看ReduceTask.class中的run方法。
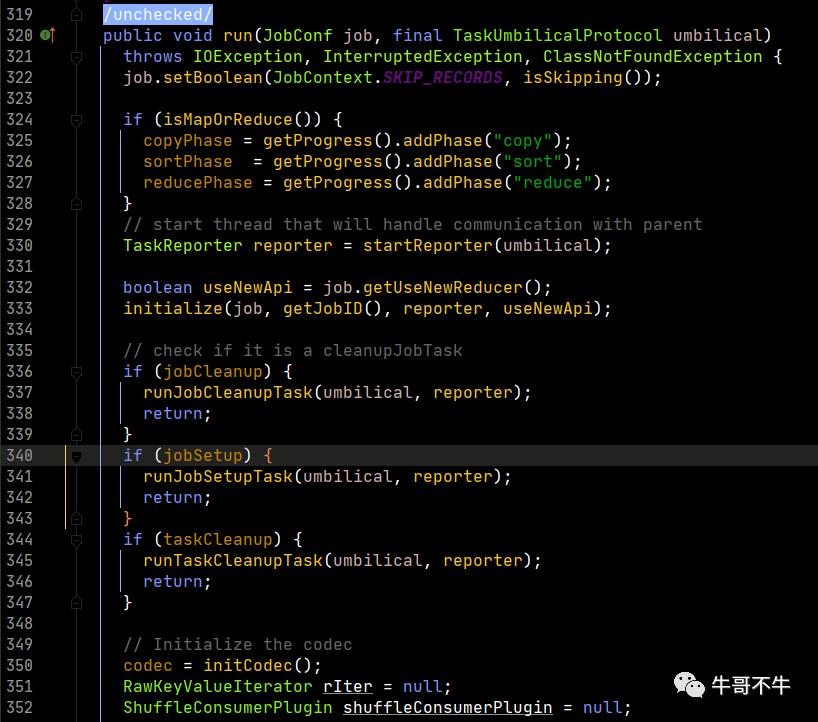
从第325-327,可知,过程添加了拷贝、排序和Reduce三个阶段。
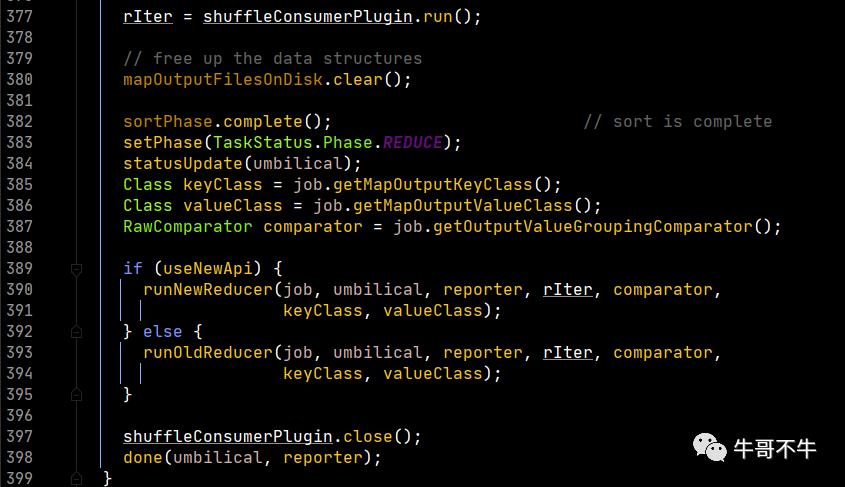
第377行,返回了一个迭代器,而迭代器时通过调用的时NodeManager中的插件拉取数据之后返回。因此,可以知道这个迭代器可以获得这个Reduce方法应该处理的所有数据。
第387行,定义了一个排序比较器,这个比较器是给排序用的,具体来说就是分组的比较器。这里的实现中,首先判断用户是否设置了组比较器,如果设置,则使用用户定义的,没有则判断用户是否设置了key比较器,如果没有则使用默认的key比较器。
之后,看runNewReducer的实现。
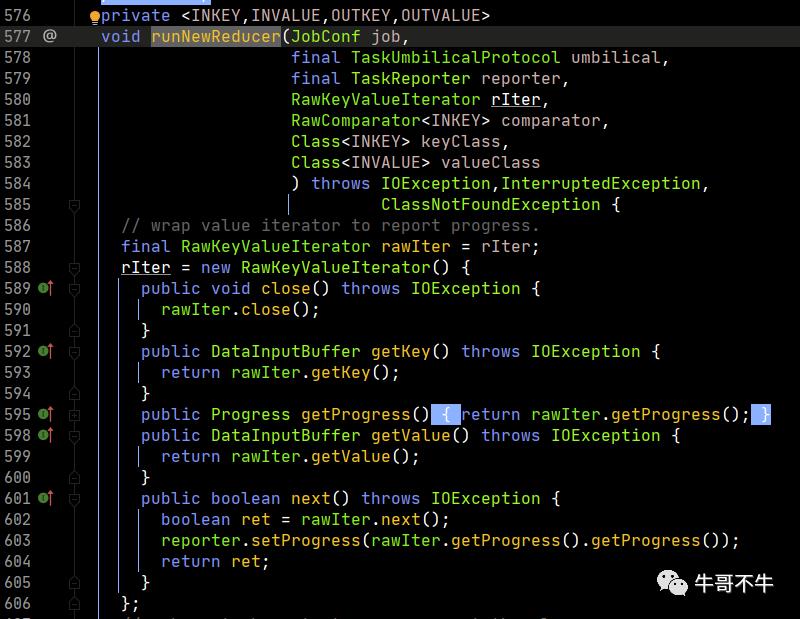
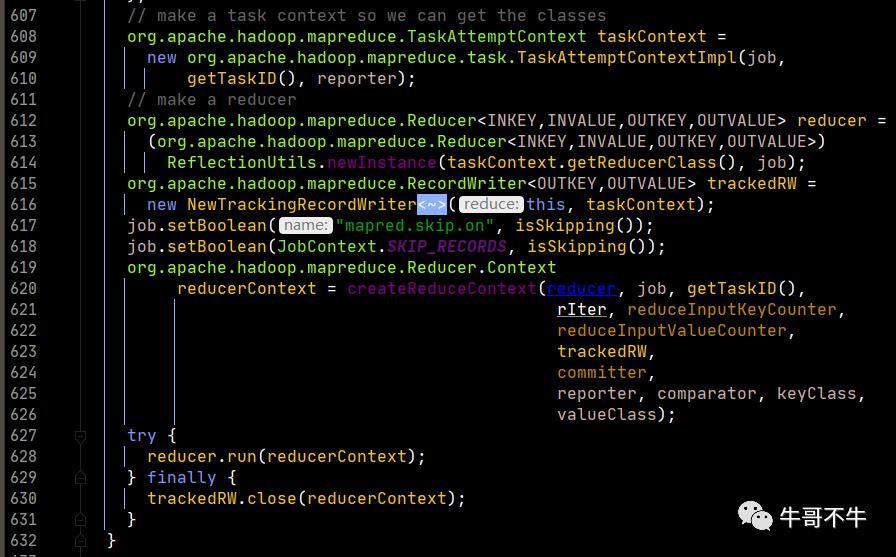
我们重点看一下run方法的实现。
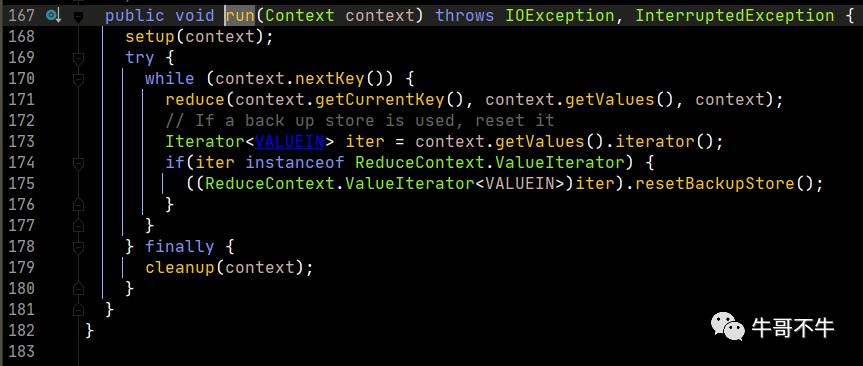
在run中,重点对context.nextKey()的实现进行分析,这里是最重要的部分,也是避免内存溢出的关键思想。
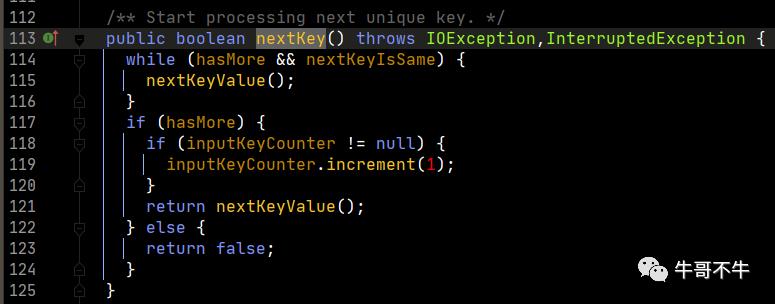
再看一下nextKeyValue的实现。
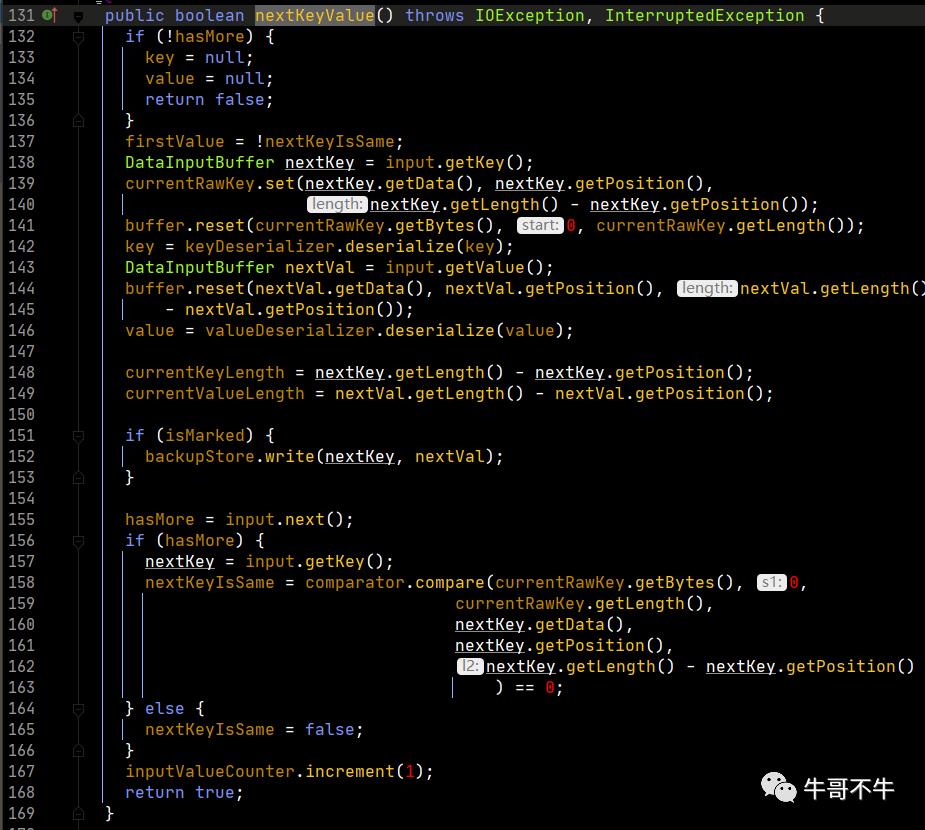
上述代码用人话来说nextKeyValue的功能,就是对k和v进行赋值操作。由于map输出的是把k和v变为序列化,存为字节数组,这里反序列化就是将字节数组再变为真正的k和v,也就是对key和value的赋值操作。
然后,从第156行开始,进行比较。首先,取得下一个key,然后通过分组比较器,比较当前的key和下一个key是否相等,相等是true,不等就是false。
我们再追踪一下,run方法中,context.getValues到底返回的是什么。
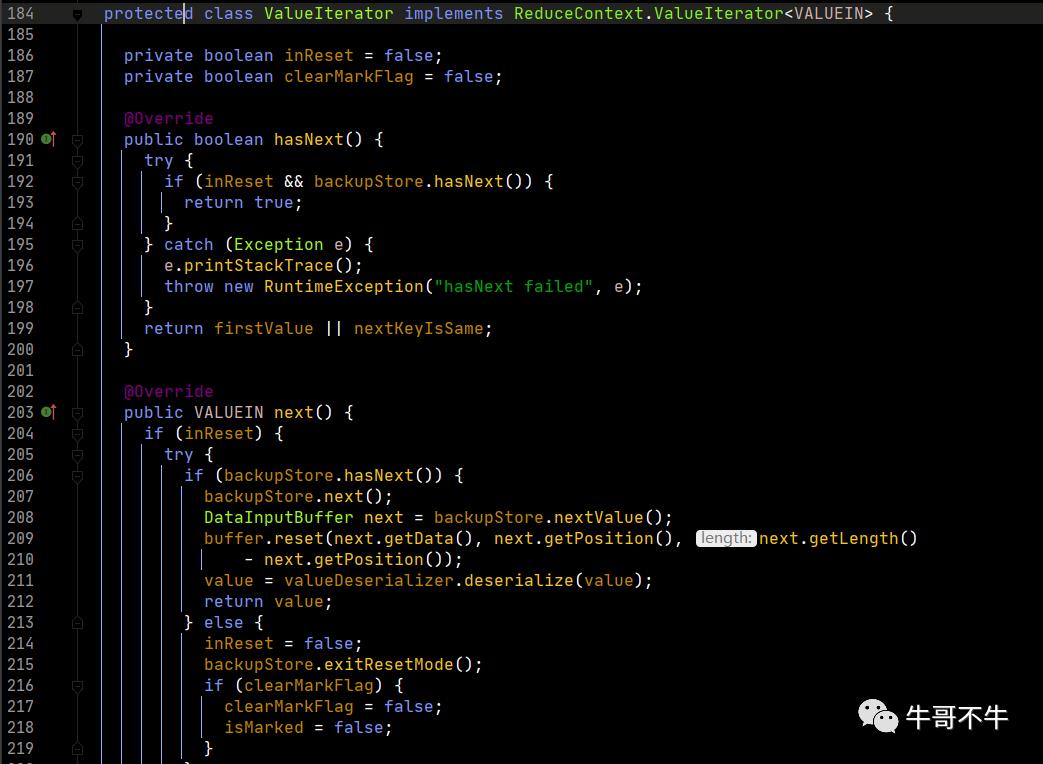
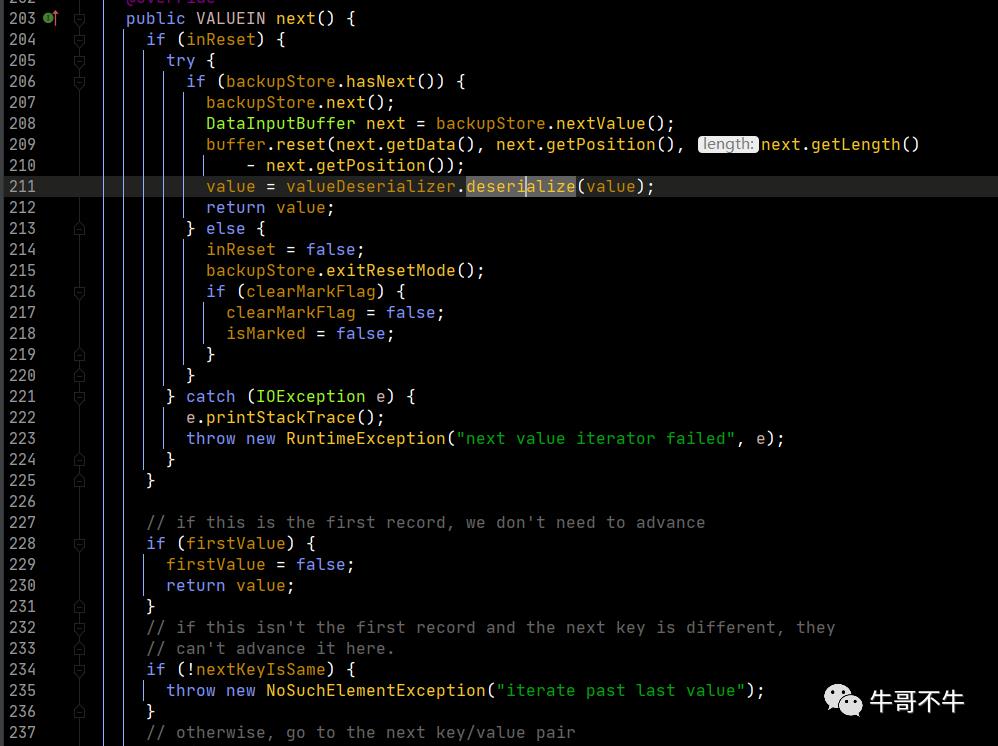
我们可以追踪到,最终value返回的迭代器是上图中的迭代器。这里需要注意的是第199行的nextKeyIsSame。这个判断是根据key来判断下一条的数据是否是同一组的数据。同时在next函数中,会调用nextKeyValue,这个函数就会更新nextKeyIsSame的值,从而hasNext使用的naxtKeyIsSame就更新了。
啰嗦了这么多,其实核心思想就是,在循环取值的过程中,reduce会预先判断下一个key与当前key是否一致,一致则取值,不一致,退出while循环。这样做的好处就是保证了MR原语,即相同的key为一组,调用reduce方法做计算。
也应该知道,一次while循环,只会把相同的key的值拿出来。
因此,我们也就清楚了避免内存溢出的解决方案了。就是以一条记录为单位,判断下一条记录是否和当前是一组,是则计算,不是则退出,等待下一次的循环。这样做就避免了直接把相同的key的值全部放在内存中,由于数据量可能会很大,超过内存限制,就会产生移除问题,而这样的话,只需要内存有两条数据的大小就可以完成MR原语的要求。
至此,Reduce阶段的分析结束。
最后,我想说,这是一个非常粗浅的源码分析,其实这个框架很大,能够设置的东西很多,过程中仅仅是摘了比较核心的部分进行了分析,要熟练掌握MR,需要多多分析源码原理,然后写出最适合的业务代码,最终让自己的技术能力得到提高!
以上是关于大数据学习深入源码解析MapReduce的架构及实现过程的主要内容,如果未能解决你的问题,请参考以下文章