Hive 窗口与分析型函数
Posted Python数据平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive 窗口与分析型函数相关的知识,希望对你有一定的参考价值。
SQL 结构化查询语言是数据分析领域的重要工具之一。它提供了数据筛选、转换、聚合等操作,并能借助 Hive 和 Hadoop 进行大数据量的处理。但是,传统的 SQL 语句并不能支持诸如分组排名、滑动平均值等计算,原因是 GROUP BY 语句只能为每个分组的数据返回一行结果,而非每条数据一行。幸运的是,新版的 SQL 标准引入了窗口查询功能,使用 WINDOW 语句我们可以基于分区和窗口为每条数据都生成一行结果记录,这一标准也已得到了 Hive 的支持。
举例来说,我们想要计算表中每只股票的两日滑动平均值,可以编写以下查询语句:
SELECT
`date`, `stock`, `close`
,AVG(`close`) OVER `w` AS `mavg`
FROM `t_stock`
WINDOW `w` AS (PARTITION BY `stock` ORDER BY `date`
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW)
OVER、 WINDOW、以及 ROWS BETWEEN AND 都是新增的窗口查询关键字。在这个查询中, PARTITION BY和 ORDER BY 的工作方式与 GROUP BY、 ORDER BY 相似,区别在于它们不会将多行记录聚合成一条结果,而是将它们拆分到互不重叠的分区中进行后续处理。其后的 ROWS BETWEEN AND 语句用于构建一个 窗口帧。此例中,每一个窗口帧都包含了当前记录和上一条记录。下文会对窗口帧做进一步描述。最后, AVG是一个窗口函数,用于计算每个窗口帧的结果。窗口帧的定义( WINDOW 语句)还可以直接附加到窗口函数之后:
SELECT AVG(`close`) OVER (PARTITION BY `stock`) AS `mavg` FROM `t_stock`;
窗口查询的基本概念
图片来源
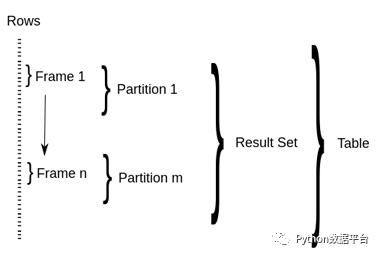
SQL 窗口查询引入了三个新的概念:窗口分区、窗口帧、以及窗口函数。
PARTITION 语句会按照一个或多个指定字段,将查询结果集拆分到不同的 窗口分区 中,并可按照一定规则排序。如果没有 PARTITION BY,则整个结果集将作为单个窗口分区;如果没有 ORDER BY,我们则无法定义窗口帧,进而整个分区将作为单个窗口帧进行处理。
窗口帧 用于从分区中选择指定的多条记录,供窗口函数处理。Hive 提供了两种定义窗口帧的形式: ROWS和 RANGE。两种类型都需要配置上界和下界。例如, ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW 表示选择分区起始记录到当前记录的所有行; SUM(close)RANGE BETWEEN100PRECEDING AND200FOLLOWING 则通过 字段差值 来进行选择。如当前行的 close 字段值是 200,那么这个窗口帧的定义就会选择分区中 close 字段值落在 100 至 400 区间的记录。以下是所有可能的窗口帧定义组合。如果没有定义窗口帧,则默认为 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW。
(ROWS | RANGE) BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN CURRENT ROW AND (CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN [num] FOLLOWING AND (UNBOUNDED | [num]) FOLLOWING
窗口函数 会基于当前窗口帧的记录计算结果。Hive 提供了以下窗口函数:
FIRST_VALUE(col),LAST_VALUE(col)可以返回窗口帧中第一条或最后一条记录的指定字段值;LEAD(col,n),LAG(col,n)返回当前记录的上n条或下n条记录的字段值;RANK(),ROW_NUMBER()会为帧内的每一行返回一个序数,区别在于存在字段值相等的记录时,RANK()会返回相同的序数;COUNT(),SUM(col),MIN(col)和一般的聚合操作相同。
Hive 窗口查询示例
Top K
首先,我们在 Hive 中创建一些有关员工收入的模拟数据:
CREATE t_employee (
id INT
,emp_name VARCHAR(20)
,dep_name VARCHAR(20)
,salary DECIMAL(7, 2)
,age DECIMAL(3, 0)
);
INSERT INTO t_employee VALUES
( 1, 'Matthew', 'Management', 4500, 55),
( 2, 'Olivia', 'Management', 4400, 61),
( 3, 'Grace', 'Management', 4000, 42),
( 4, 'Jim', 'Production', 3700, 35),
( 5, 'Alice', 'Production', 3500, 24),
( 6, 'Michael', 'Production', 3600, 28),
( 7, 'Tom', 'Production', 3800, 35),
( 8, 'Kevin', 'Production', 4000, 52),
( 9, 'Elvis', 'Service', 4100, 40),
(10, 'Sophia', 'Sales', 4300, 36),
(11, 'Samantha','Sales', 4100, 38);
我们可以使用 RANK() 函数计算每个部门中谁的收入最高:
SELECT dep_name, emp_name, salary
FROM (
SELECT
dep_name, emp_name, salary
,RANK() OVER (PARTITION BY dep_name ORDER BY salary DESC) AS rnk
FROM t_employee
) a
where rnk = 1;
通常情况下, RANK() 在遇到相同值时会返回同一个排名,并 跳过 下一个排名序数。如果想保证排名连续,可以改用 DENSE_RANK() 这个函数。
累积分布
我们可以计算整个公司员工薪水的累积分布。如, 4000 元的累计分布百分比是 0.55,表示有 55% 的员工薪资低于或等于 4000 元。计算时,我们先统计不同薪资的频数,再用窗口查询做一次累计求和操作:
SELECT
salary
,SUM(cnt) OVER (ORDER BY salary)
/ SUM(cnt) OVER (ORDER BY salary ROWS BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING)
FROM (
SELECT salary, count(*) AS cnt
FROM t_employee
GROUP BY salary
) a;
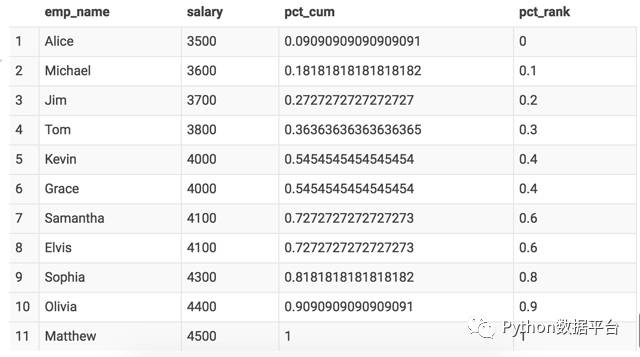
我们还可以使用 Hive 提供的 CUME_DIST() 来完成相同的计算。 PERCENT_RANK() 函数则可以百分比的形式展现薪资所在排名。
SELECT
salary
,CUME_DIST() OVER (ORDER BY salary) AS pct_cum
,PERCENT_RANK() OVER (ORDER BY salary) AS pct_rank
FROM t_employee;
点击流会话
我们可以根据点击流的时间间隔来将它们拆分成不同的会话,如超过 30 分钟认为是一次新的会话。我们还将为每个会话赋上自增 ID:
首先,在子查询 b 中,我们借助 LAG(col) 函数计算出当前行和上一行的时间差,如果大于 30 分钟则标记为新回话的开始。之后,我们对 new_session 字段做累计求和,从而得到一个递增的 ID 序列。
SELECT
ipaddress, clicktime
,SUM(IF(new_session, 1, 0)) OVER x + 1 AS sessionid
FROM (
SELECT
ipaddress, clicktime, ts
,ts - LAG(ts) OVER w > 1800 AS new_session
FROM (
SELECT *, UNIX_TIMESTAMP(clicktime) AS ts
FROM t_clickstream
) a
WINDOW w AS (PARTITION BY ipaddress ORDER BY ts)
) b
WINDOW x AS (PARTITION BY ipaddress ORDER BY ts);
窗口查询实现细节
简单来说,窗口查询有两个步骤:将记录分割成多个分区,然后在各个分区上调用窗口函数。分区过程对于了解 MapReduce 的用户应该很容易理解,Hadoop 会负责对记录进行打散和排序。但是,传统的 UDAF 函数只能为每个分区返回一条记录,而我们需要的是不仅输入数据是一张表,输出数据也是一张表(table-in, table-out),因此 Hive 社区引入了分区表函数(PTF)。
PTF 顾名思义是运行于分区之上、能够处理分区中的记录并输出多行结果的函数。下方的时序图列出了这个过程中重要的一些类。 PTFOperator 会读取已经排好序的数据,创建相应的“输入分区”; WindowTableFunction 则负责管理窗口帧、调用窗口函数(UDAF)、并将结果写入“输出分区”。
HIVE-896(链接)包含了将分析型函数引入 Hive 的讨论过程;这份演示文档(链接)则介绍了当时的主要研发团队是如何设计和实现 PTF 的。
参考资料
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+WindowingAndAnalytics
https://github.com/hbutani/SQLWindowing
https://content.pivotal.io/blog/time-series-analysis-1-introduction-to-window-functions
https://databricks.com/blog/2015/07/15/introducing-window-functions-in-spark-sql.html
以上是关于Hive 窗口与分析型函数的主要内容,如果未能解决你的问题,请参考以下文章