hive中join导致的数据倾斜问题排查
Posted 小象
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive中join导致的数据倾斜问题排查相关的知识,希望对你有一定的参考价值。
我 相 信 这 么 优秀 的 你
已 经 置 顶 了 我
从事大数据相关开发,曾经为多个开源框架如Hive、Yarn、Pig、Tez贡献代码。
◇◆◇◆◇
场景
如果某个key下记录数远超其他key,在join或group的时候可能会导致某个reduce任务特别慢。本文分析下join的场景。
本例子SQL如下:查询每个appid打开的次数,需要排除掉作弊的imei。
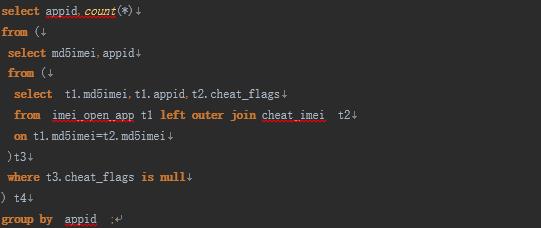
说明:表cheat_imei,7500万条,无大key,为作弊的imei。表imei_open_app,5亿6526万条,为每个imei打开的appid。该表中存在大key,md5imei=54bc0748b1c0fb46135d117b6d26885e的记录数有2亿3659万条。
◇◆◇◆◇
Hadoop环境
Hadoop 2.6.0-cdh5.8.0
hive-1.1.0-cdh5.8.0
◇◆◇◆◇
会导致的问题
可能会导致下面2个问题
1)某个reduce task,卡在99.9%半天不动。如下
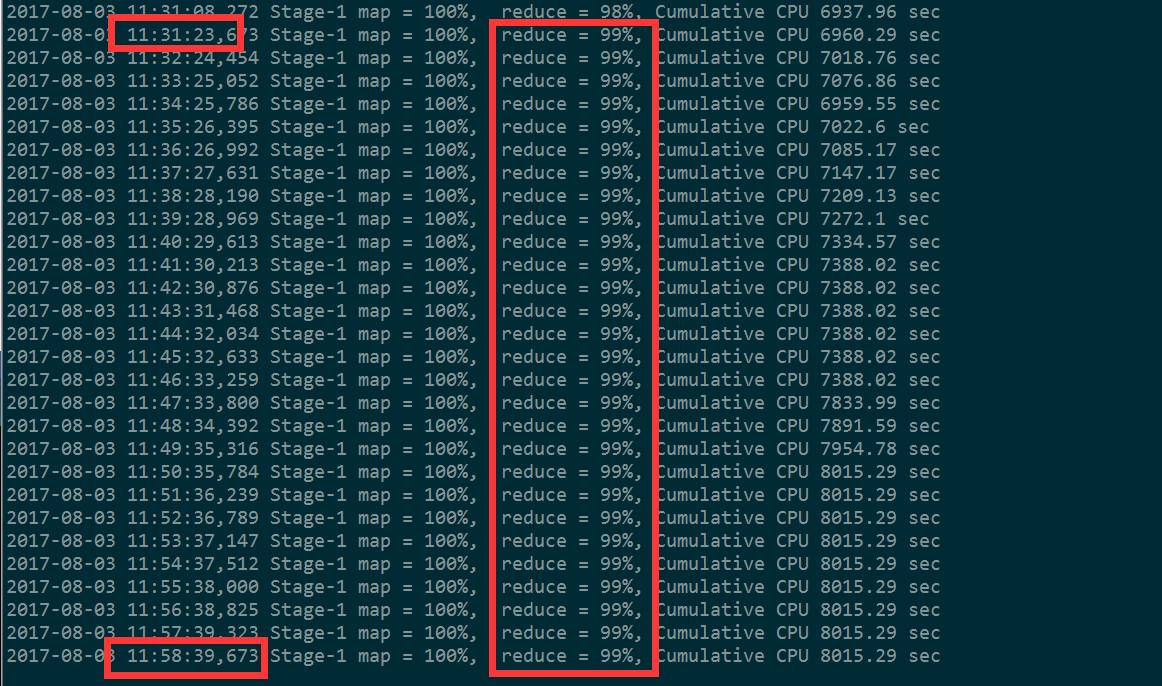
2)任务超时被杀掉
Reduce处理的数据量巨大,在做full gc的时候,stop the world。导致响应超时,超出默认的600秒,任务被杀掉。报错信息
AttemptID:attempt_1498075186313_242232_r_000021_1 Timed outafter 600 secs Container killed by the ApplicationMaster. Container killed onrequest. Exit code is 143 Container exited with a non-zero exit code 143。

◇◆◇◆◇
如何判断是大key导致的问题
可以通过下面方法。
4.1 通过时间判断
如果某个reduce的时间比其他reduce时间长的多。(注意:如果每个reduce执行时间差不多,都特别长,则可能是reduce设置过少导致的)。如下图。大部分task在4分钟之内完成,只有r_000021这个task在30分钟内还没完成。
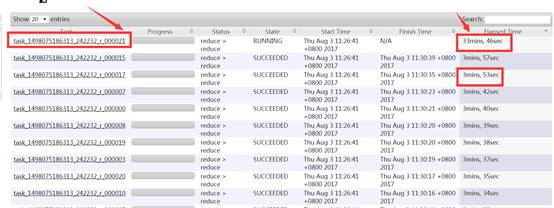
另外注意,这里面需要排除一种特殊情况。有时候,某个task执行的节点可能有问题,导致任务跑的特别慢。这个时候,mapreduce的推测执行,会重启一个任务。如果新的任务在很短时间内能完成,通常则是由于task执行节点问题导致的个别task慢。如果推测执行后的task执行任务也特别慢,那更能说明该task可能会有倾斜问题。
4.2 通过任务Counter判断
Counter会记录整个job以及每个task的统计信息。counter的url一般类似:
http://rm:9099/proxy/application_1498075186313_242232/mapreduce/taskcounters/task_1498075186313_242232_r_000017
1)通过输入记录数
普通的task counter如下

而task=000021的counter如下,其输入记录数是2亿4000万。是其他任务的10几倍

2)通过输出字符数
普通的task counter如下,

而task=000021的counter如下,是其他任务的几十倍

◇◆◇◆◇
如何找到大key及对应SQL执行代码
5.1 找到对应大key
一般情况下,hive在做join的时候,会打印join的日志。我们通过日志查找大key。
1)找到任务特别慢的那个task,打开对应日志,url类似于
http://rm:8042/node/containerlogs/container_e115_1498075186313_242232_01_000416/hdp-ads-audit/syslog/?start=0
2)搜索日志中出现的“rows for joinkey”,如下图。

3) 找到时间跨度最大的那条记录,如下图。
比如[54bc0748b1c0fb46135d117b6d26885e],处理的时间从2017-08-03 11:31:30 一直到2017-08-03 11:46:35,耗时15分钟,任务依然没有结束。

。。。。。。由于日志过长,中间部分省略。。。。。。。

另外,从日志中也可能看到,54bc0748b1c0fb46135d117b6d26885e已经处理了236528000条数据,实际情况该key在imei_open_app中确实有2亿3659万条数据。
5.2 确定任务卡住的stage
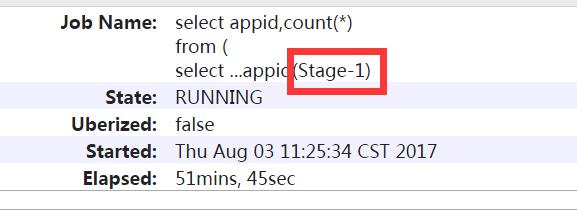
1)通过jobname确定stage
一般通过Hive的默认jobname会带上名称会带上stage阶段,如下为Stage-1。
2)如果jobname是自定义的,那可能没法通过jobname判断stage。需要借助于任务日志。
找到执行特别慢的那个task,搜索 “CommonJoinOperator: JOIN struct” 。Hive在做join的时候,会把join的key打印到日志中。如下。

上图中的关键信息是struct<_col1:string,_col6:string>
这时候,需要参考该SQL的执行计划。通过参考执行计划,可以断定该阶段为stage1阶段。
这时候,需要参考该SQL的执行计划。通过参考执行计划,可以断定该阶段为stage1阶段。
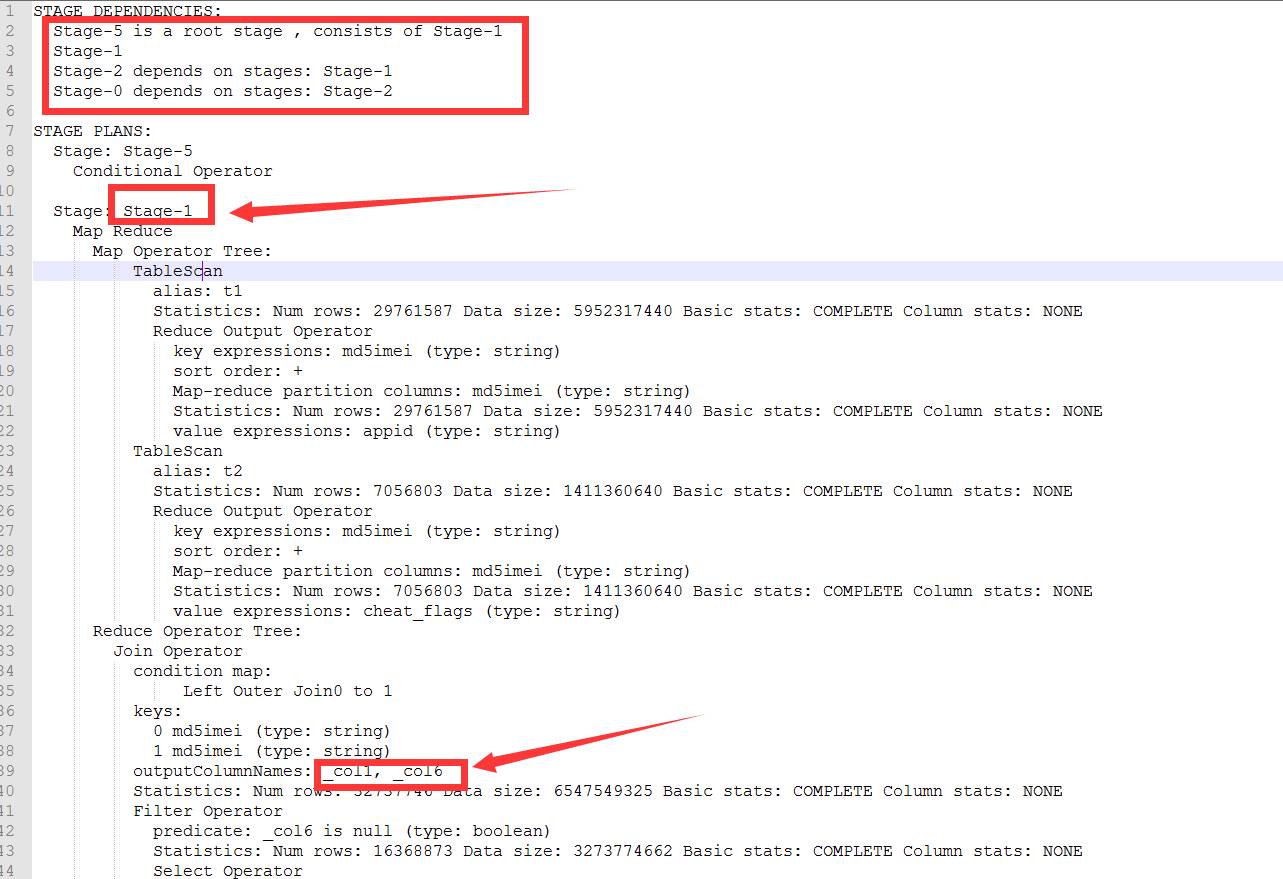
5.3 确定SQL执行代码
确定了执行阶段,即stage。通过执行计划,则可以判断出是执行哪段代码时出现了倾斜。还是从上图,可以推测出是在执行下面红框中代码时出现了数据倾斜。
◇◆◇◆◇
解决方案
6.1 过滤掉脏数据
如果大key是无意义的脏数据,直接过滤掉。本场景中大key无实际意义,为非常脏数据,直接过滤掉。
6.2 数据预处理
数据做一下预处理,尽量保证join的时候,同一个key对应的记录不要有太多。
6.3 增加reduce个数
如果数据中出现了多个大key,增加reduce个数,可以让这些大key落到同一个reduce的概率小很多。
6.4 转换为mapjoin
如果两个表join的时候,一个表为小表,可以用mapjoin做。
6.5 大key单独处理
将大key和其他key分开处理,sql如下
6.6 hive.optimize.skewjoin
会将一个join sql 分为两个job。另外可以同时设置下hive.skewjoin.key,默认为10000。参考:
https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
参数对full outer join无效。
6.7 调整内存设置
适用于那些由于内存超限内务被kill掉的场景。通过加大内存起码能让任务跑起来,不至于被杀掉。该参数不一定会明显降低任务执行时间。
如:
setmapreduce.reduce.memory.mb=5120 ;
setmapreduce.reduce.java.opts=-Xmx5000M -XX:MaxPermSize=128m ;
以上是关于hive中join导致的数据倾斜问题排查的主要内容,如果未能解决你的问题,请参考以下文章