如何安装SAS并配置连接Hive/Impala
Posted Hadoop实操
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何安装SAS并配置连接Hive/Impala相关的知识,希望对你有一定的参考价值。
温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
Fayson的github:https://github.com/fayson/cdhproject
提示:代码块部分可以左右滑动查看噢
1.文档编写目的
SAS提供了从基本统计数的计算到各种试验设计的方差分析,相关回归分析以及多变数分析的多种统计分析过程,几乎囊括了所有最新分析方法,其分析技术先进,可靠。分析方法的实现通过过程调用完成。许多过程同时提供了多种算法和选项。Cloudera与SAS是相互认证的合作伙伴,在各自的官网都能找到集成安装的专业文档,也能得到专业的支持。本文主要是介绍如何安装SAS,并连接配置到Hive和Impala。
内容概述
1.SAS的安装与配置
2.SAS连接HDFS和操作
3.SAS连接Hive和操作
4.SAS连接Impala和操作
测试环境
1.CDH5.14.1
2.SAS 9.4
3.客户端Windows 7
2.SAS客户端下载并安装
1.下载SAS客户端安装软件
https://www.sas.com/zh_cn/software/university-edition/download-software.html#windows
(可左右滑动)
根据官网提示说明进行进行下载。
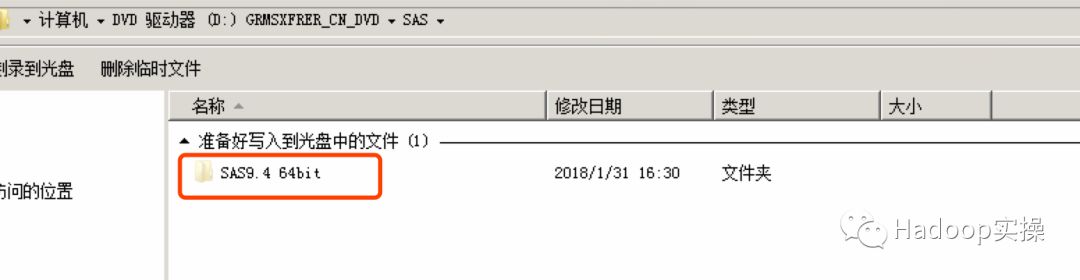
2.双击setup安装程序,安装SAS

选择语言
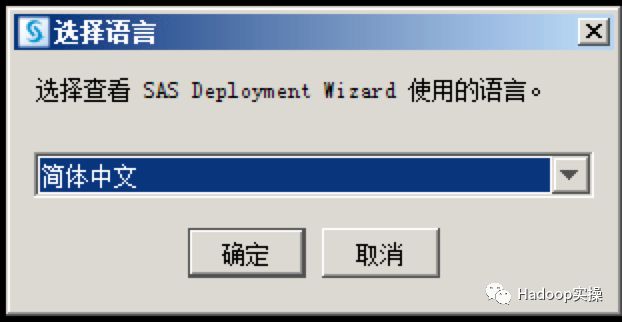
选择安装SAS软件
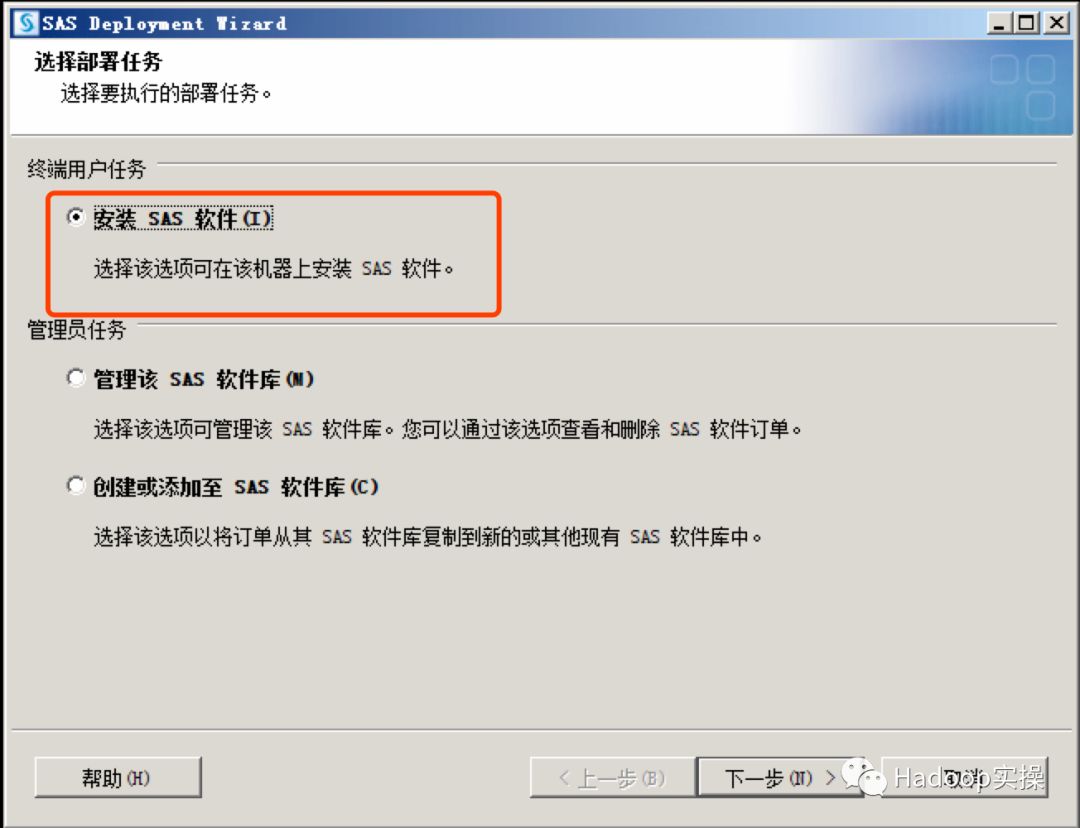
指定安装目录,注意安装目录不能含中文
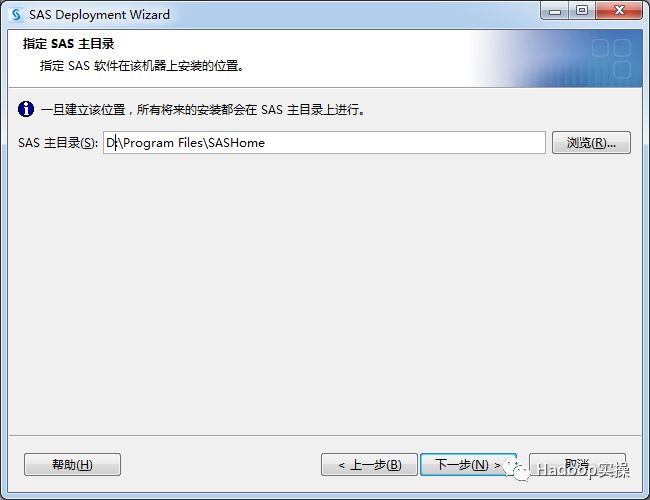
选择部署类型
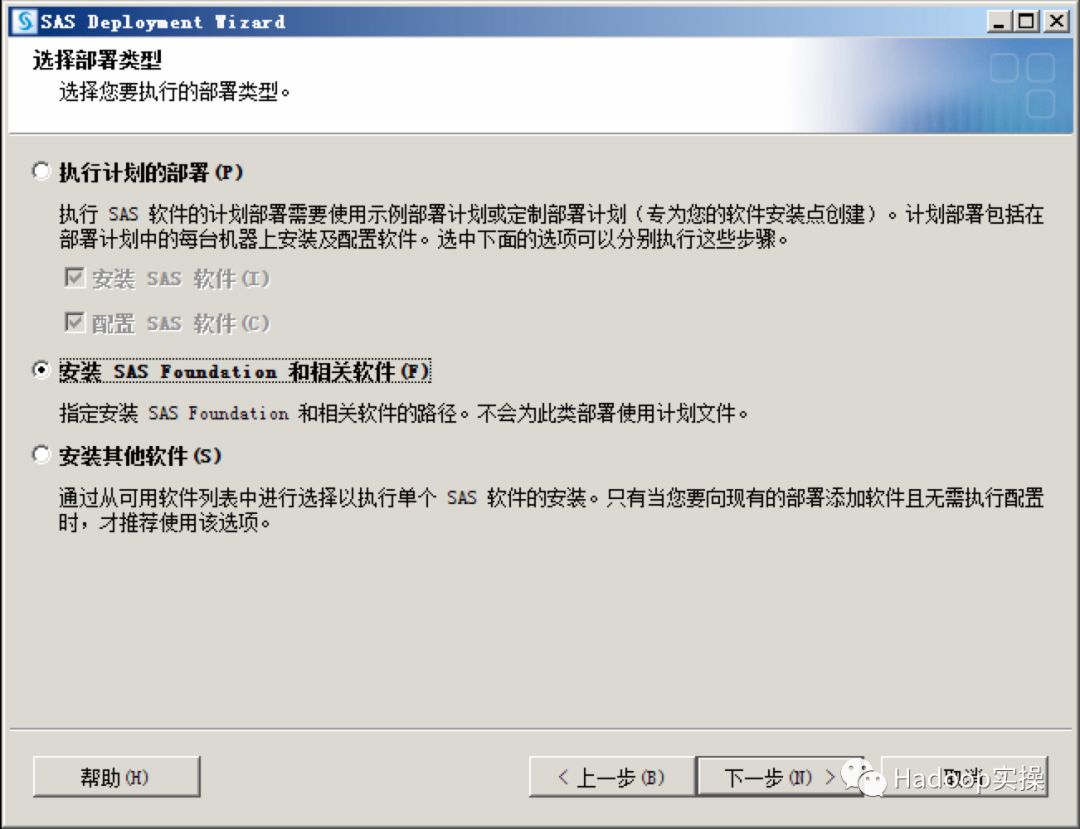
选择需要安装的产品,全选除”SAS Bridge for Esri”
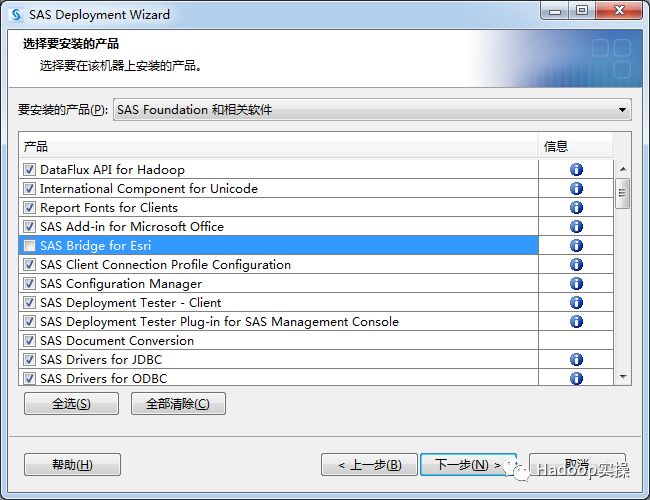
选择“SAS Enterprise Guide模式”
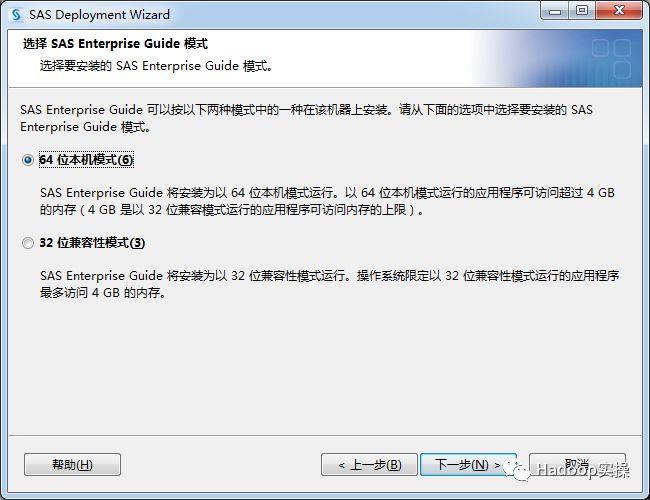
选择所有的“SAS Foundation产品”
指定SAS安装数据(SID)文件
选择安装语言
语言区域设置
选择“SAS文件类型的默认产品”
指定Internet浏览器
指定SAS/GRAPH Java Applet部署目录
选择SAS PC Files Server系统服务器选项
指定SAS PC Files Server的端口号
指定SAS Document Conversion主机和端口
检查系统
部署汇总
点击“开始”进行部署
安装成功
选择支持项
完成安装
到此为止完成SAS的安装。
3.打开SAS客户端,验证安装模块是否完整。
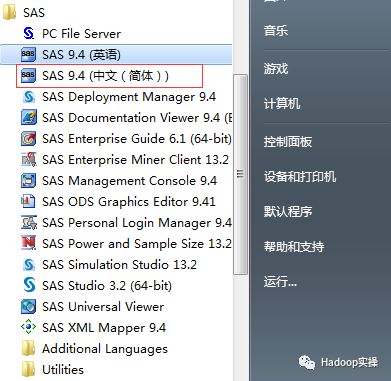
显示界面如下:
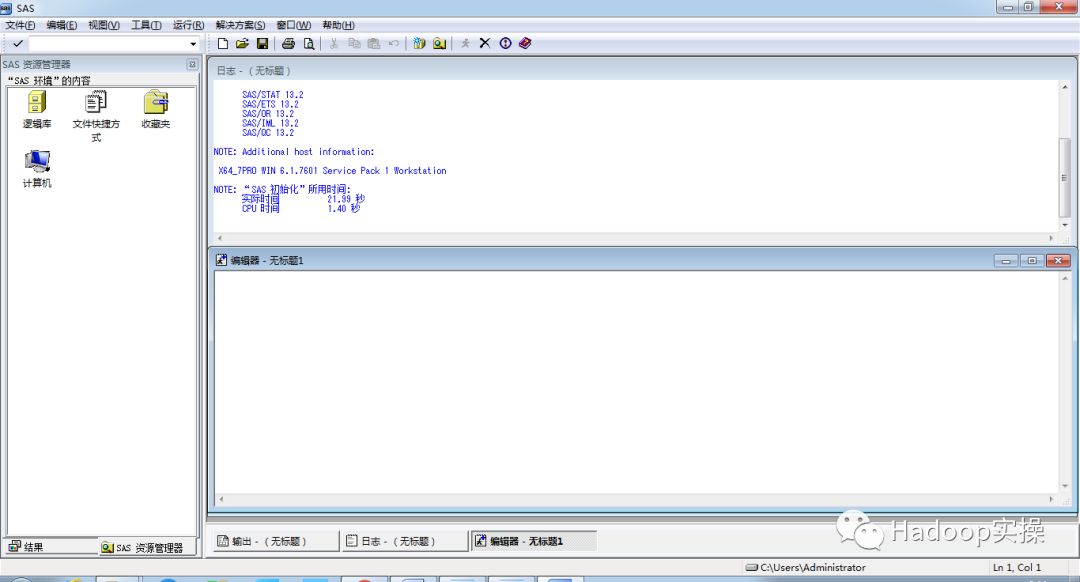
4.运行如下命令可以看到我们安装的模块
proc setinit;run;
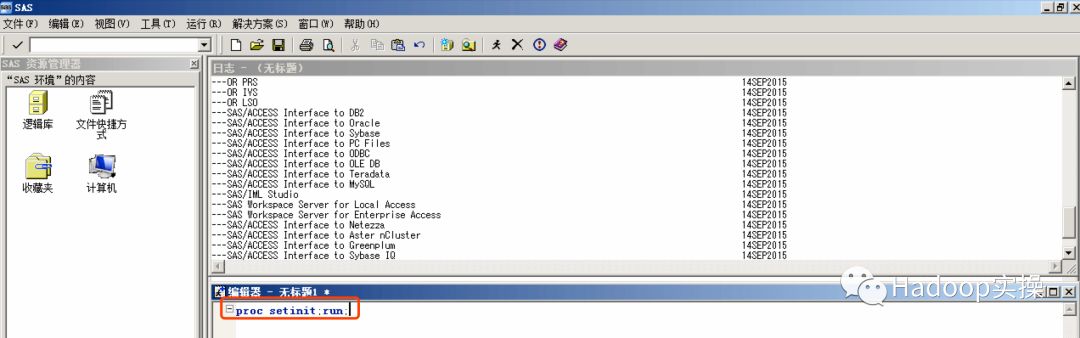
注意:在输出的安装模块中必须包含Hadoop,否则无法连接Hadoop集群。检查SID文件是否包含该模块,如果包含Hadoop模块则重新安装Hadoop模块。
3.SAS环境配置
1.配置SAS访问Hadoop的环境变量
将CDH集群/opt/cloudera/parcels/CDH/jars目录下的所有jar包下载至本地
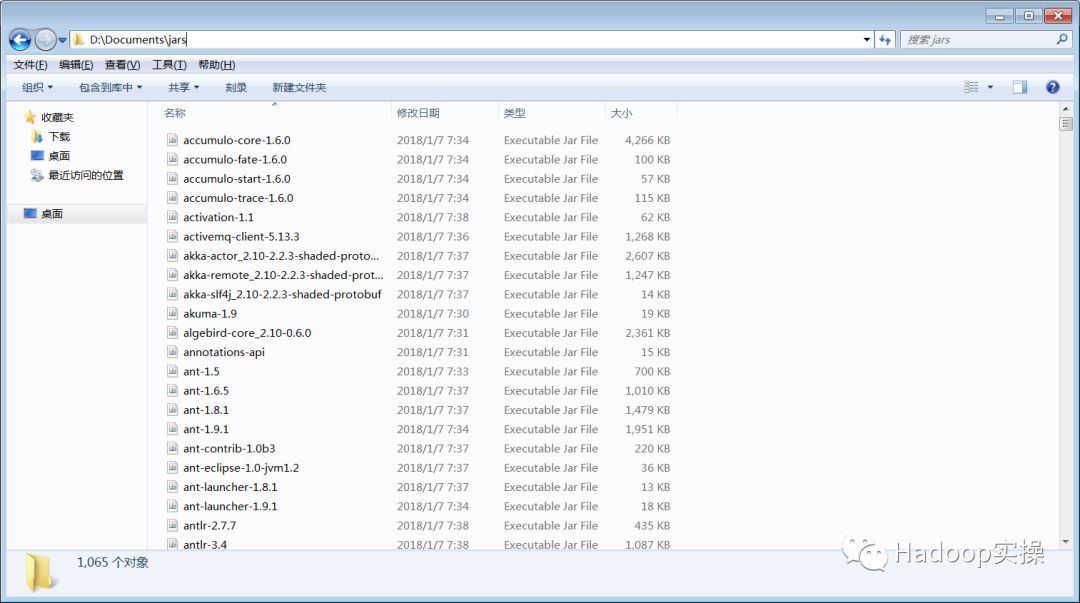
通过ClouderaManager Web界面下载HDFS的客户端配置文件至本地
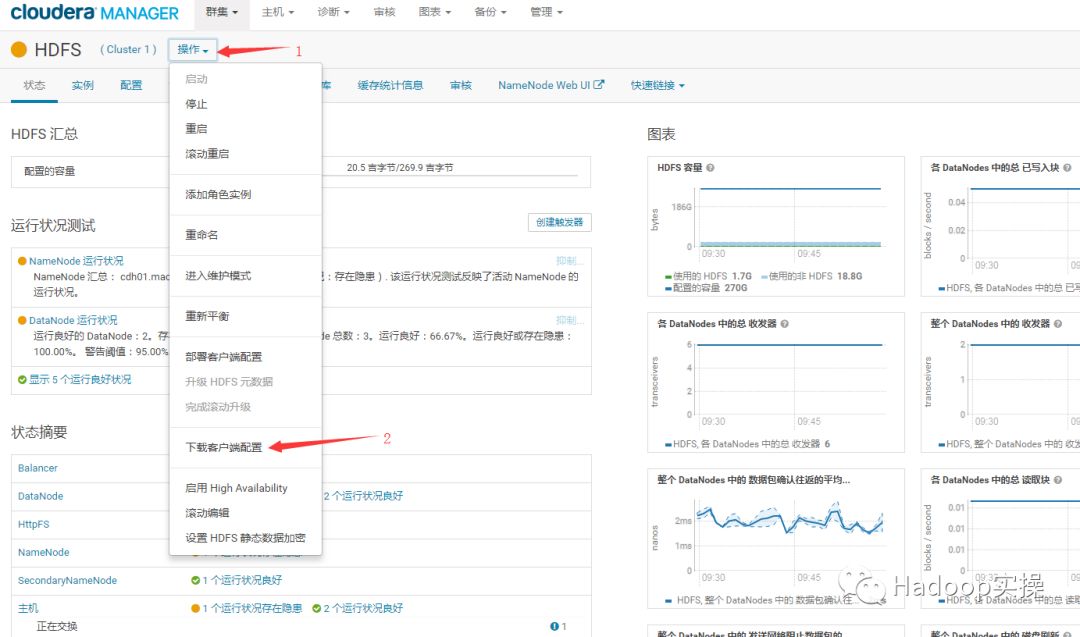
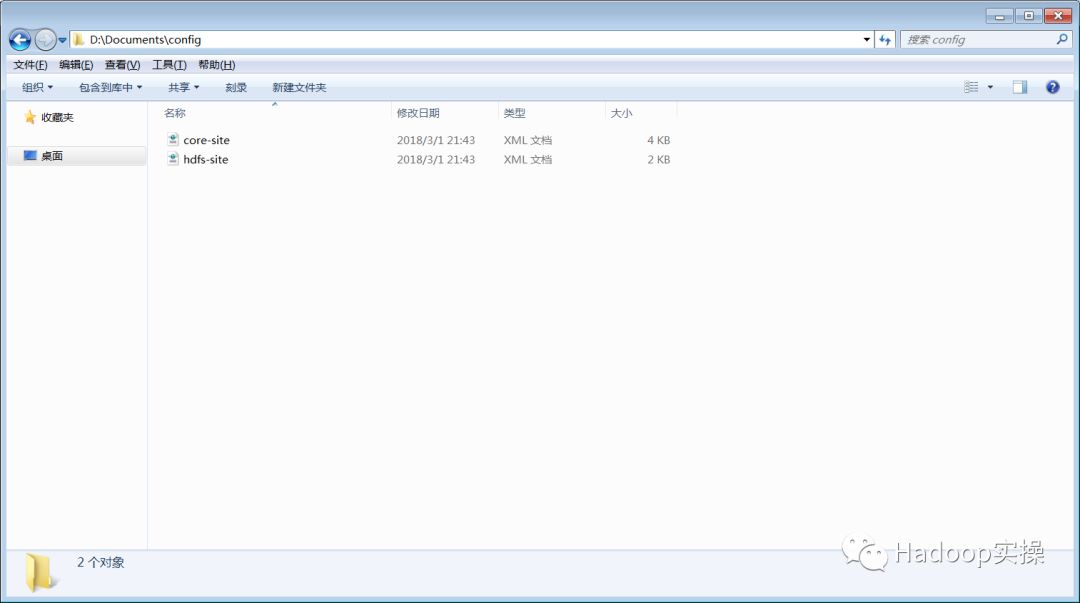
2.配置SAS客户端上的环境变量
右击计算机→属性→高级系统设置→环境变量
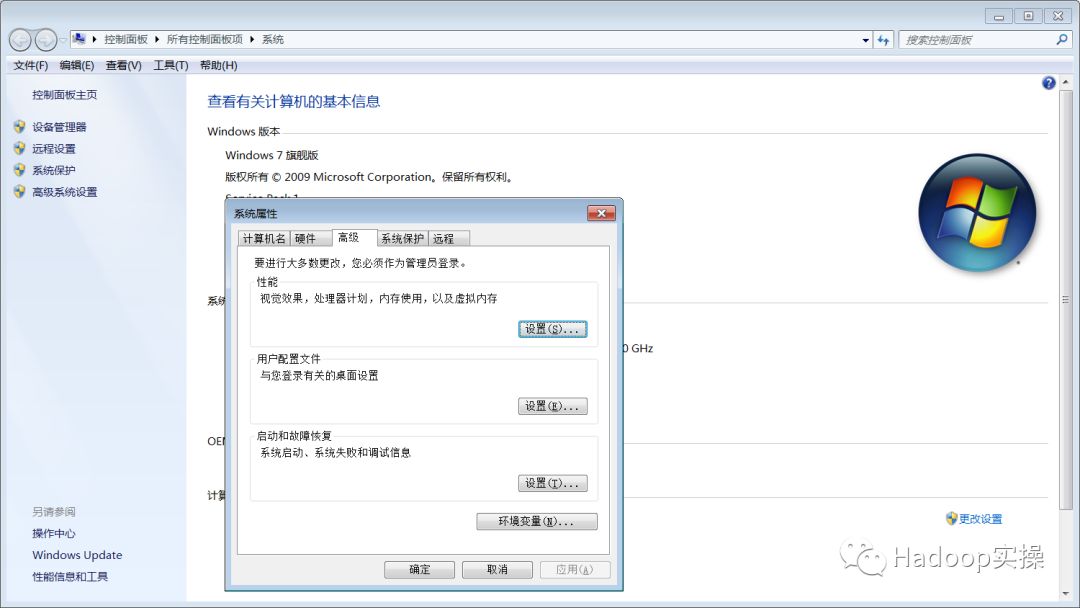
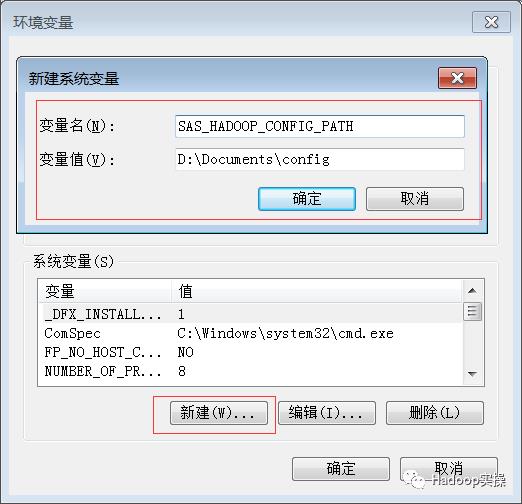
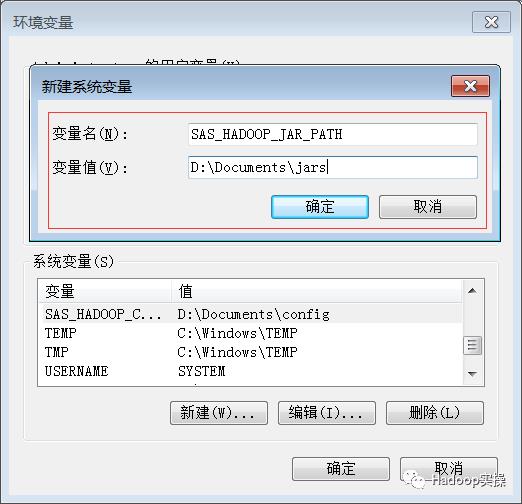
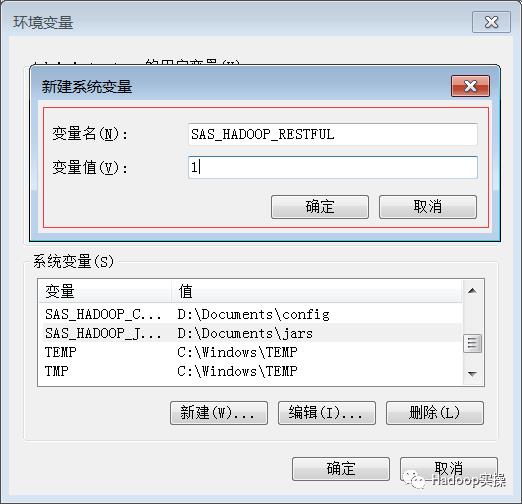
根据我们本地存放的路径,配置如下环境变量:
SAS_HADOOP_CONFIG_PATH= D:\Documents\config
SAS_HADOOP_JAR_PATH= D:\Documents\jars
SAS_HADOOP_RESTFUL=1
(可左右滑动)
配置方式如下:
3.配置SAS客户端上hosts文件
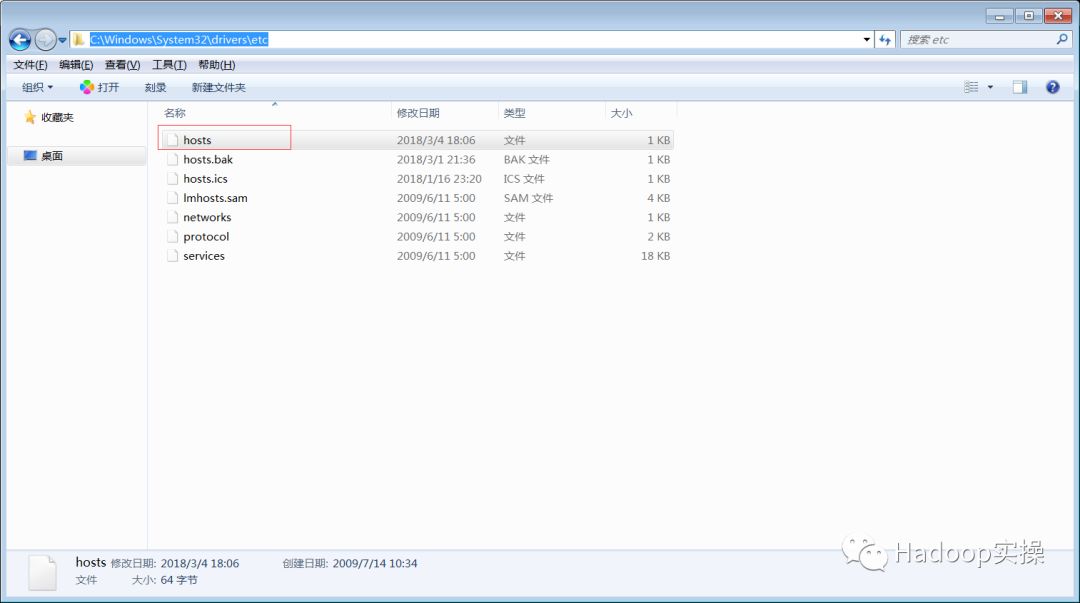
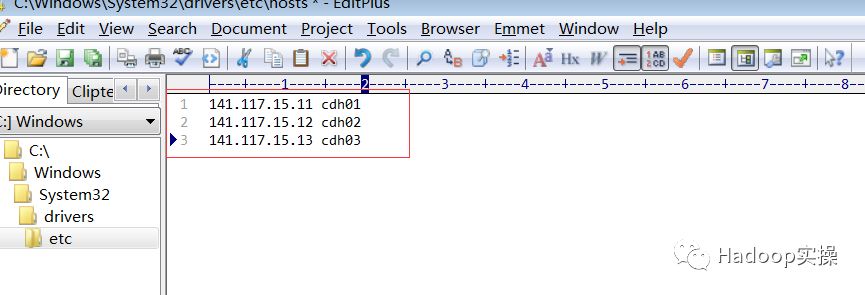
将CDH集群的hosts信息同步到C:\Windows\System32\drivers\etc\hosts文件中,内容如下:
4.HDFS的连接和操作
1.SAS访问HDFS示例
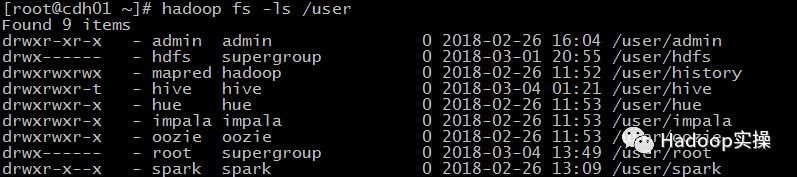
查看hdfs上/user目录下的文件
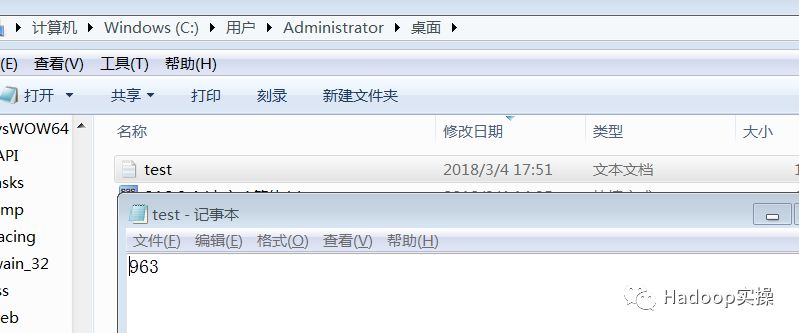
在本地的C:\Users\Administrator\Desktop\的目录下新建test.txt文件用于测试,内容如下:
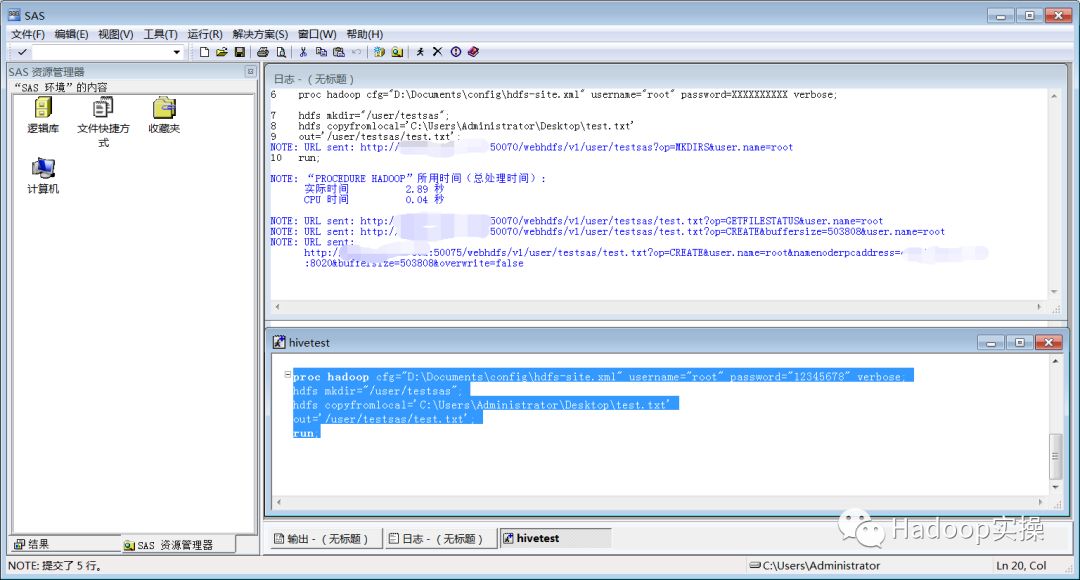
然后在sas软件上编辑程序内容如下:
proc hadoop cfg="D:\Documents\config\hdfs-site.xml" username="root" password="12345678" verbose;
hdfs mkdir="/user/testsas";
hdfs copyfromlocal='C:\Users\Administrator\Desktop\test.txt'
out='/user/testsas/test.txt';
run;
(可左右滑动)
代码说明:使用SAS的prochadoop访问HDFS,在HDFS的/user目录下新建testsas目录并将本地C:\Users\Administrator\Desktop\test.txt文件上传至HDFS的/user/testsas目录下。
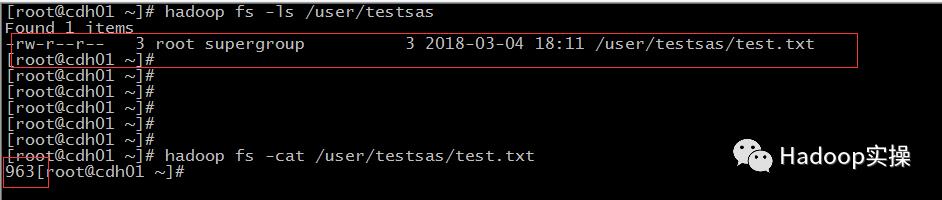
代码运行结果:
在CDH集群主机上用命令行查看,可以看到已经创建了testsas文件夹和文件test.txt,查看test.txt文件与本地文件内容一致,表示SAS访问HDFS并成功操作。
5.Hive的连接和操作
1.编写SAS访问Hive代码,示例如下:
libname hive Hadoop server="your_server_name" database="default" user="hive" password="12345678";
proc sql;
select * from hive.new1;
quit;
(可左右滑动)
代码说明:使用libname方式创建名为hive的逻辑库(使用hive用户访问Hive的default库),并查询hive逻辑库下的new1表。
示例中Procsql代码需要在表名前添加逻辑库名才可以正常运行,所以示例中表名是hive.new1。
在SAS中运行代码,执行结果如下:
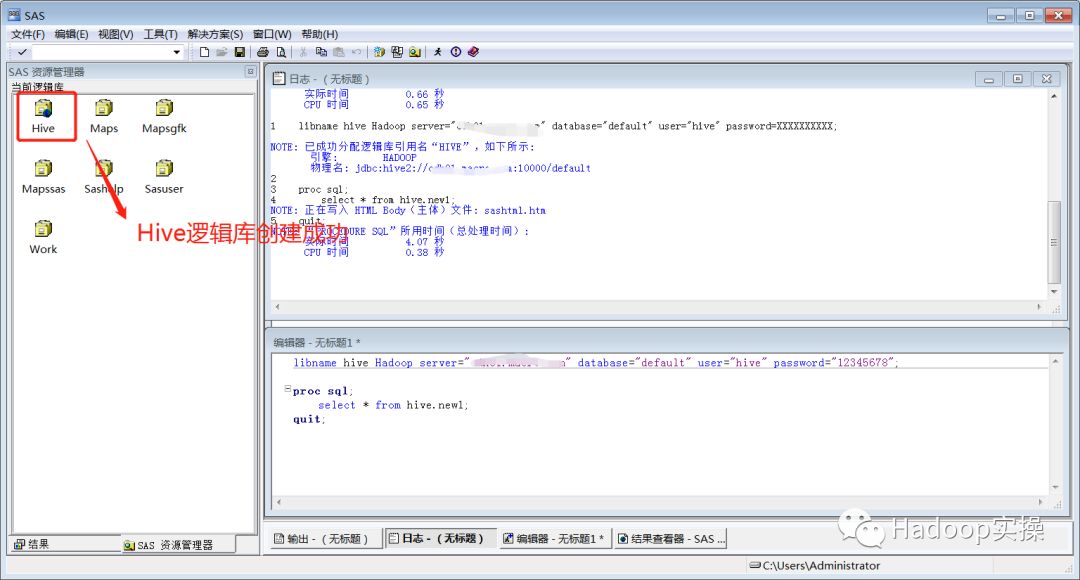
双击Hive逻辑库,查看逻辑库中的表
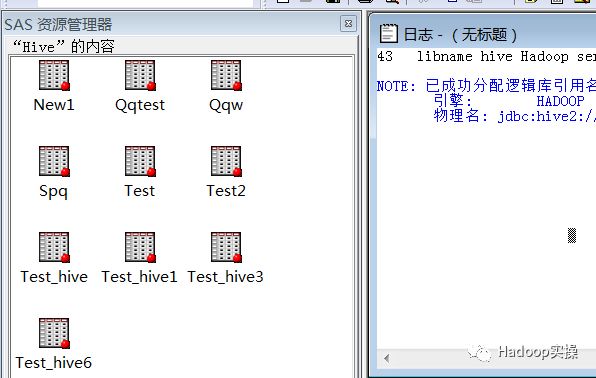
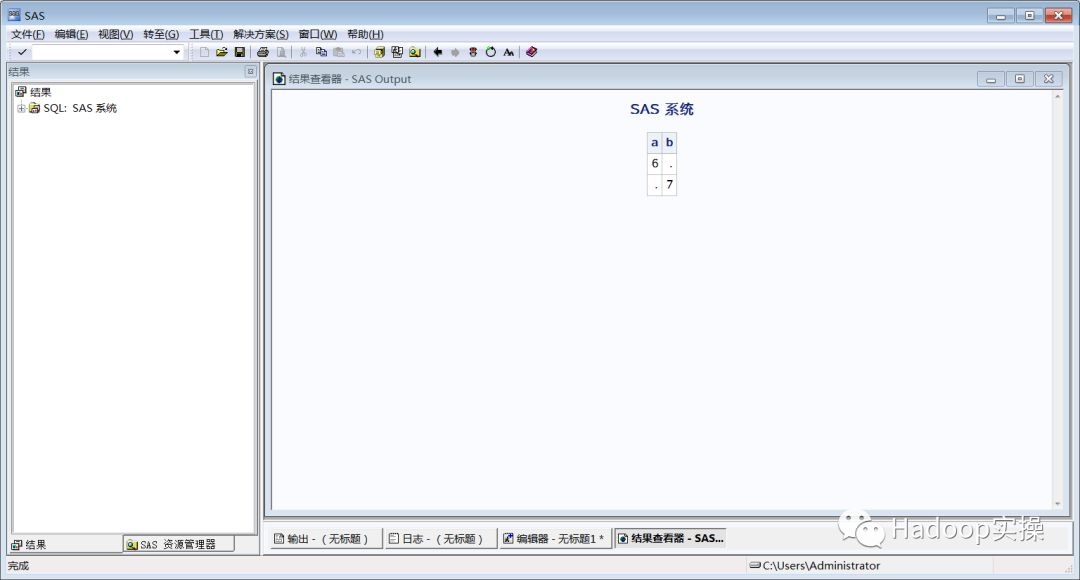
查看SQL执行结果
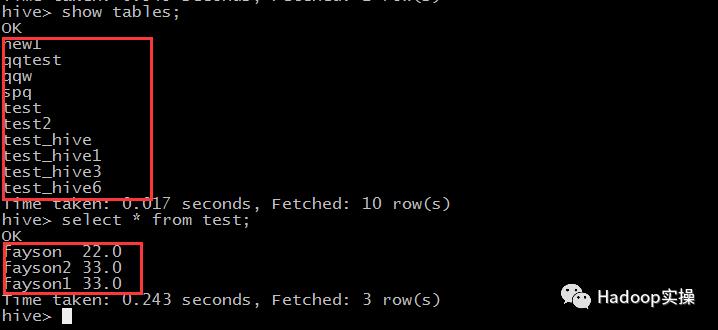
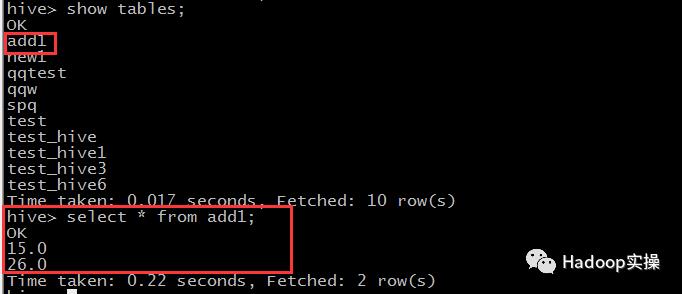
2.在集群的命令行使用hive命令查看default库下的表及new1表的数据
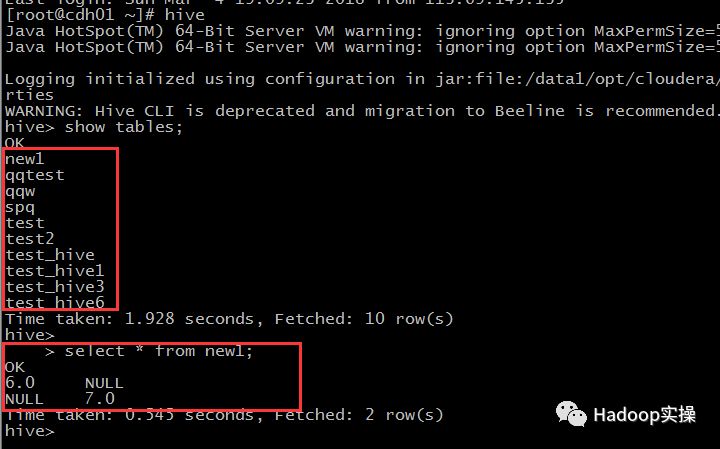
可以看到Hive逻辑库中的表与Hivedefault库中的表一致,new1表内容与SAS逻辑库下new1表数据一致。
3.也可以在SAS客户端通过界面的方式对Hive库中的表进行操作,通过点击SAS资源管理器->逻辑库->hive。
查看表数据:和命令行查询进行对比,结果一致。
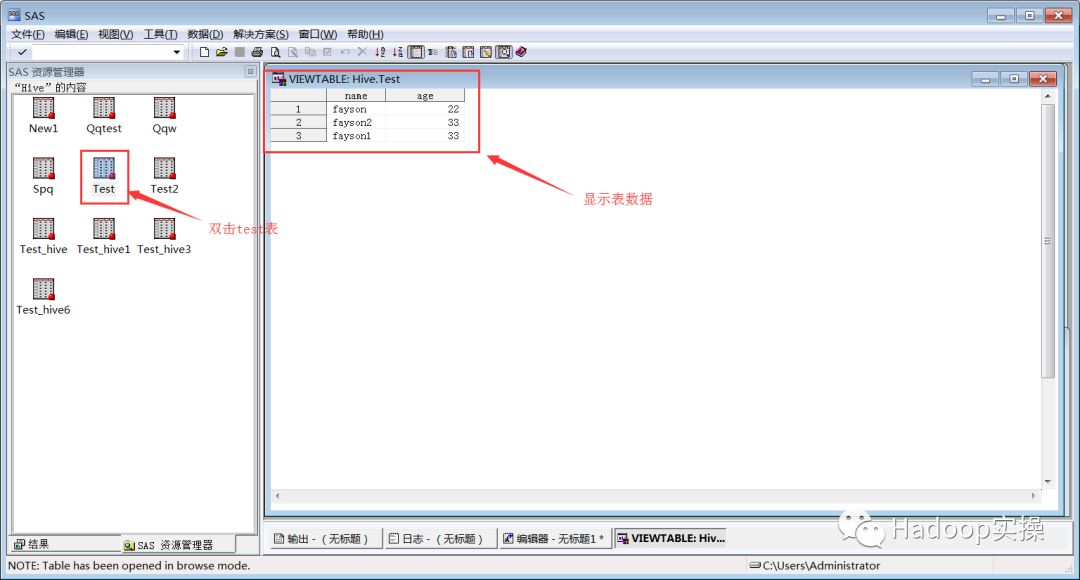
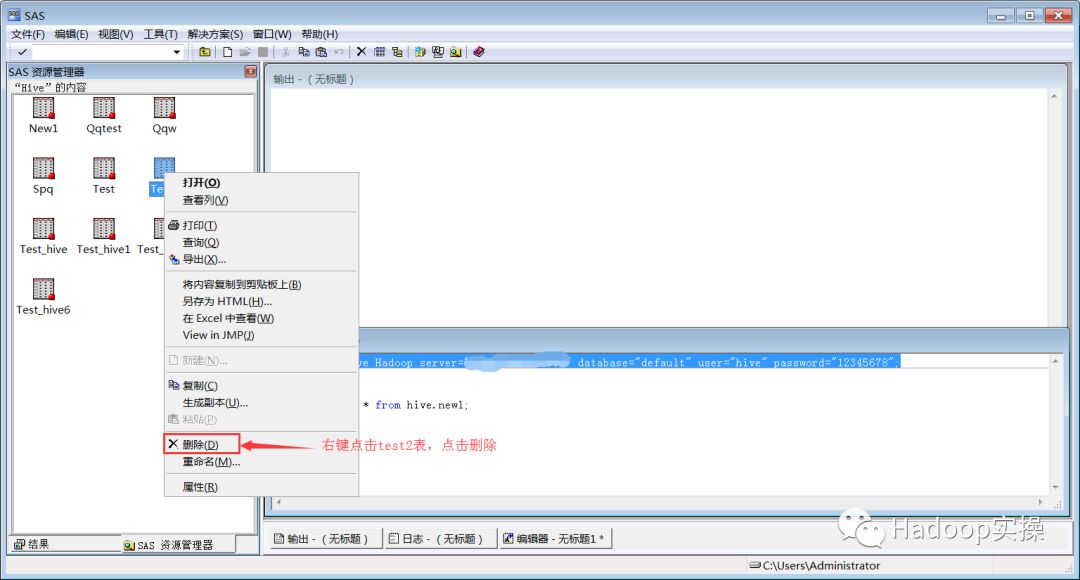
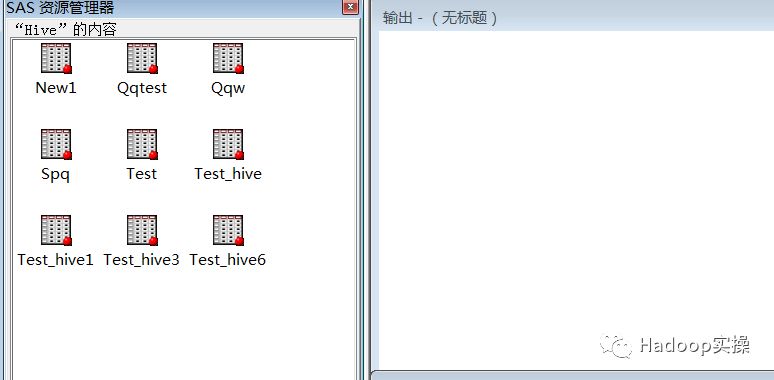
删除表:和命令行查询进行对比,结果一致。
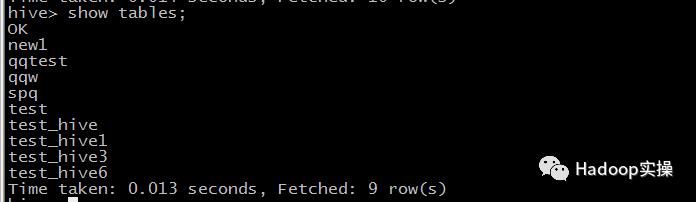
新增表:和命令行查询进行对比,结果一致。
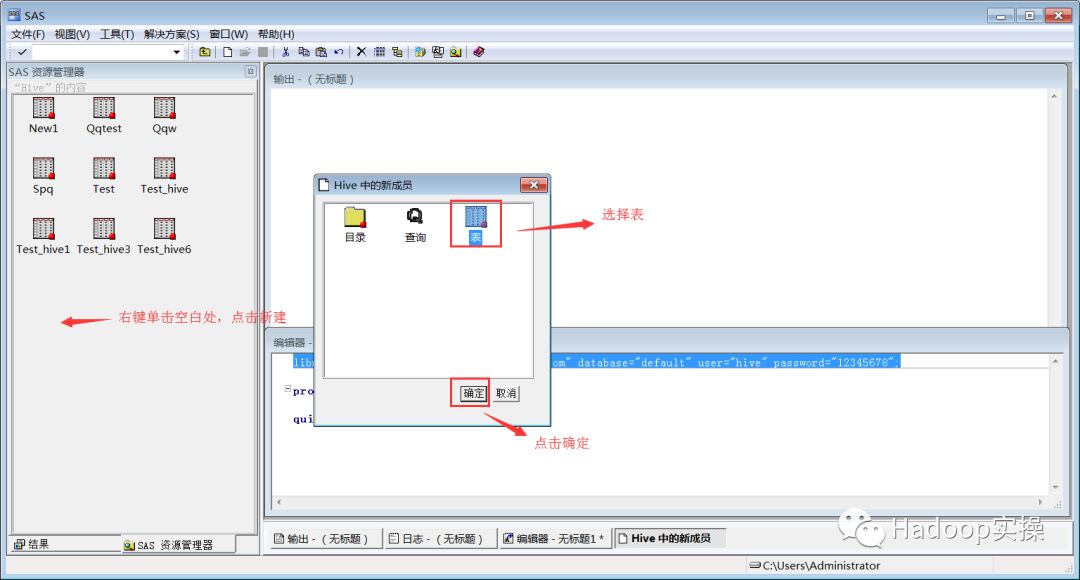
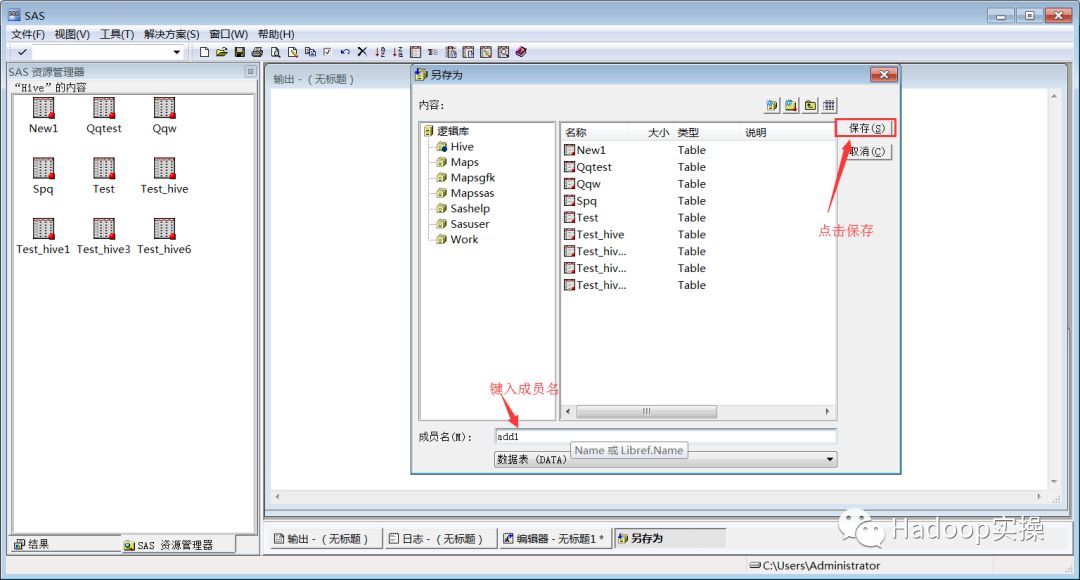
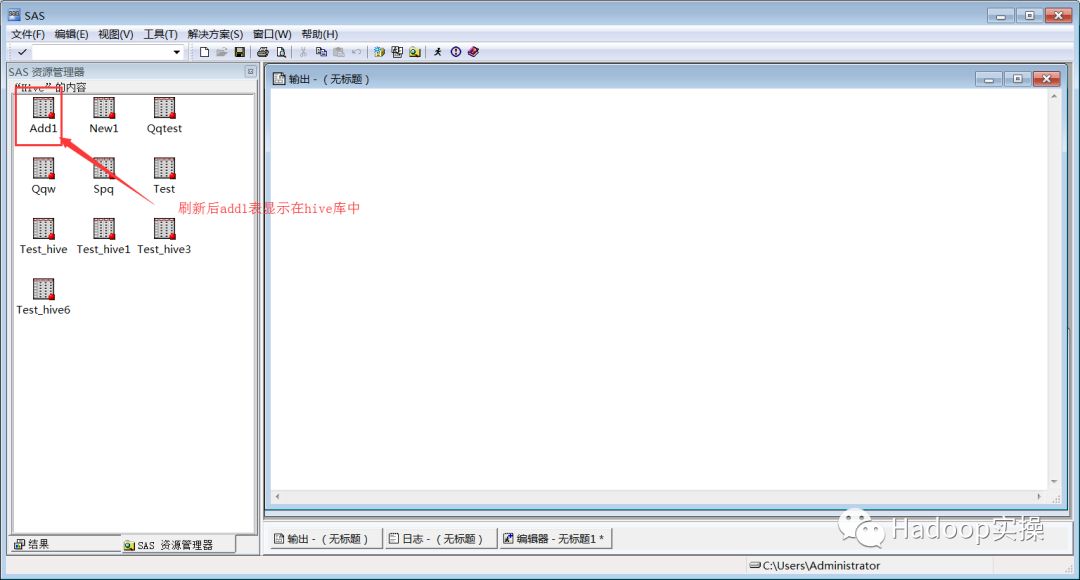
6.配置impala的ODBC连接并测试
1.下载Impala的ODBC驱动
https://www.cloudera.com/downloads/connectors/impala/odbc/2-5-40.html
(可左右滑动)
2.5.40为目前最新版本,根据你的操作系统的实际情况选择,Fayson的电脑是Windows的系统,64位。
2.安装Impala的ODBC驱动
双击下载好的msi文件进行安装
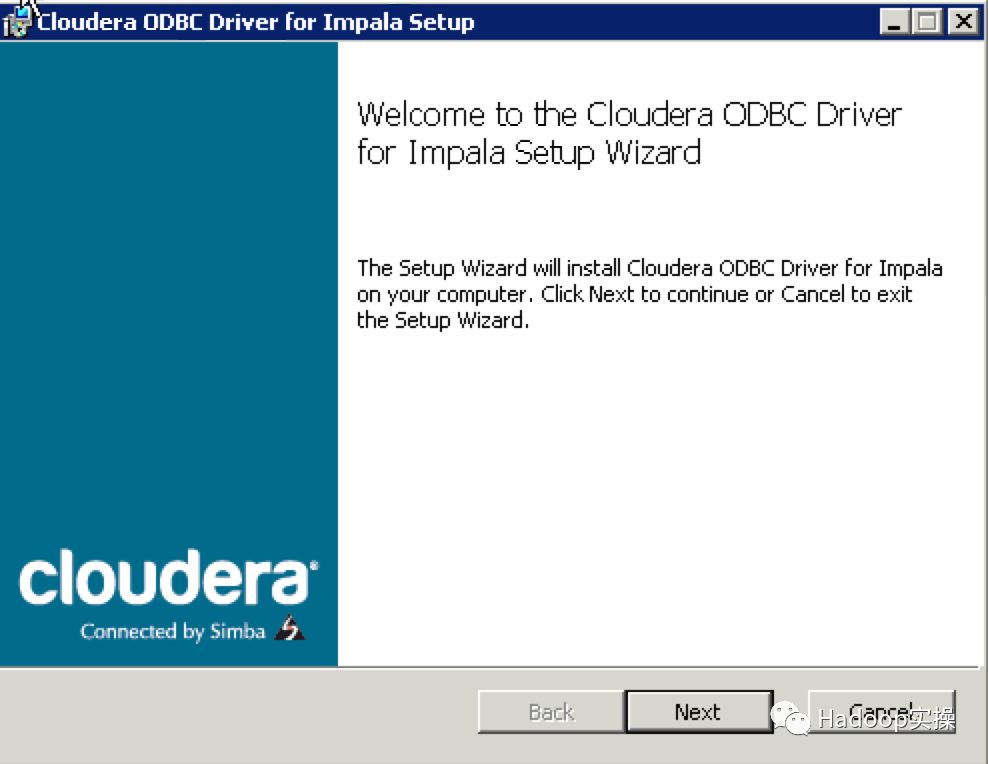
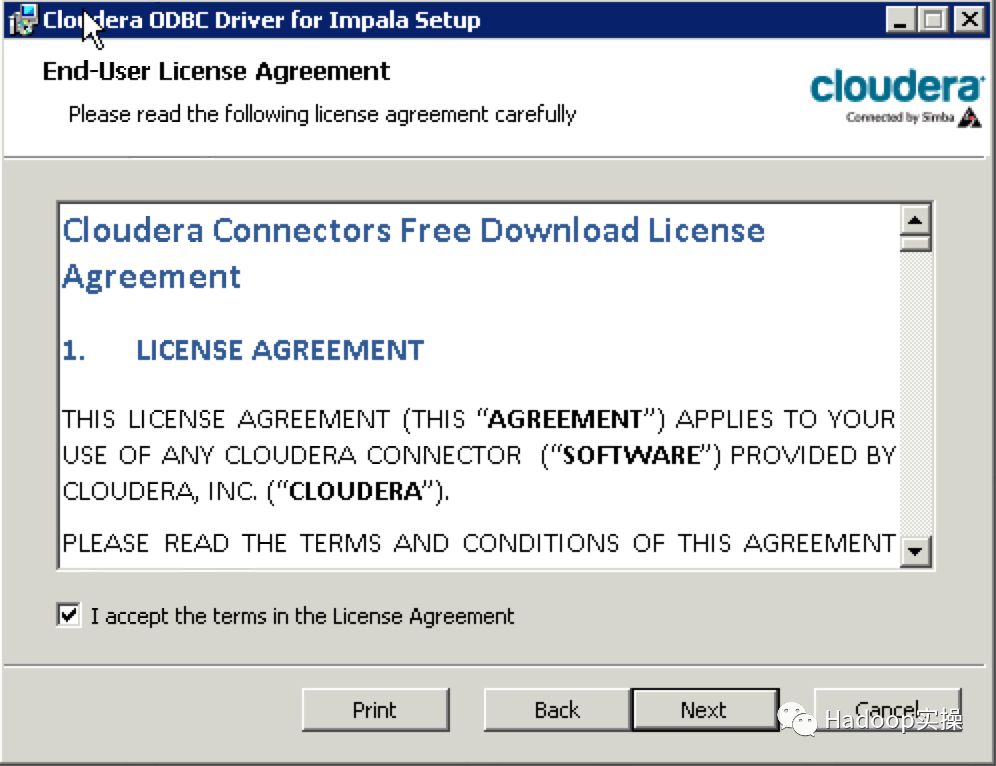
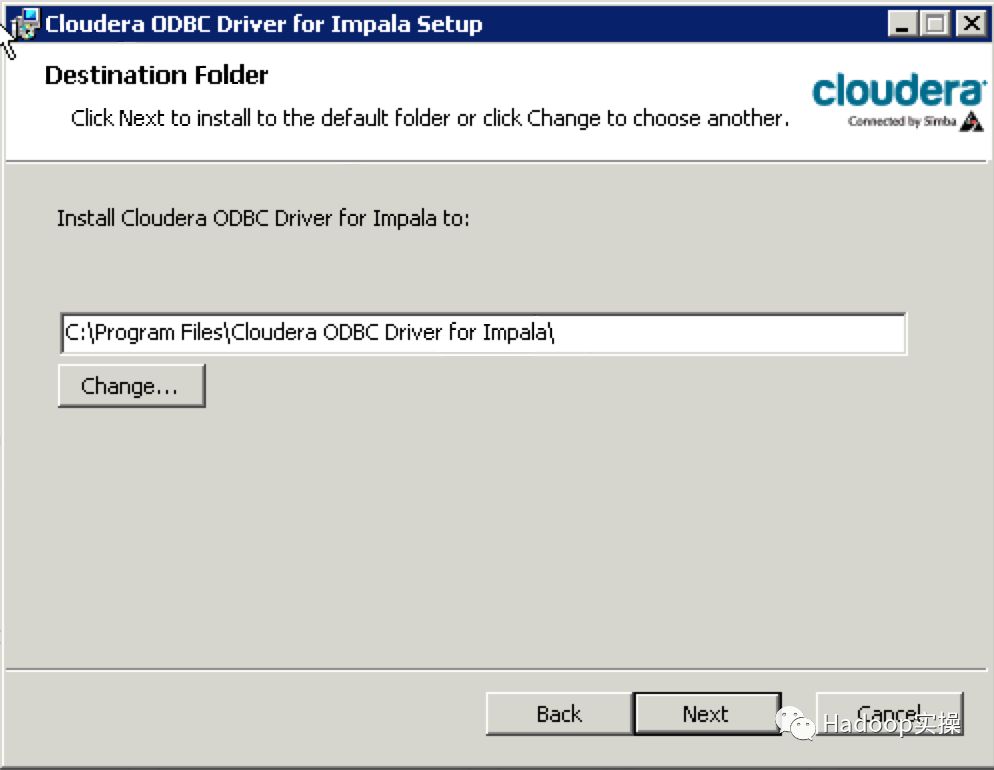
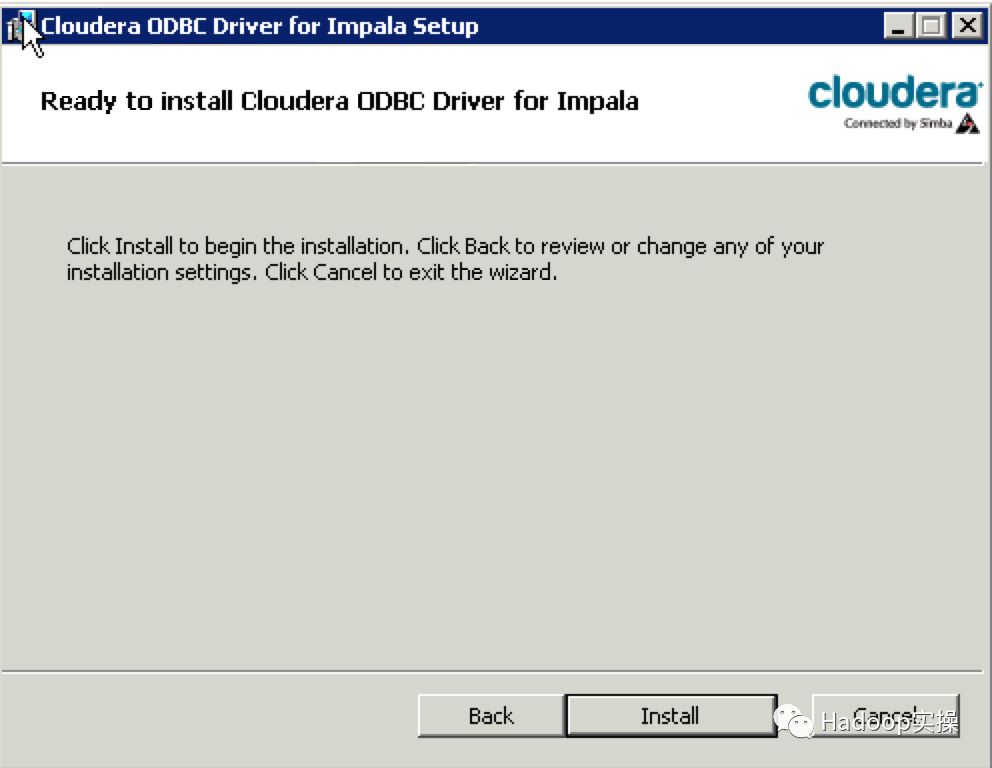
3.配置impala的ODBC连接并测试
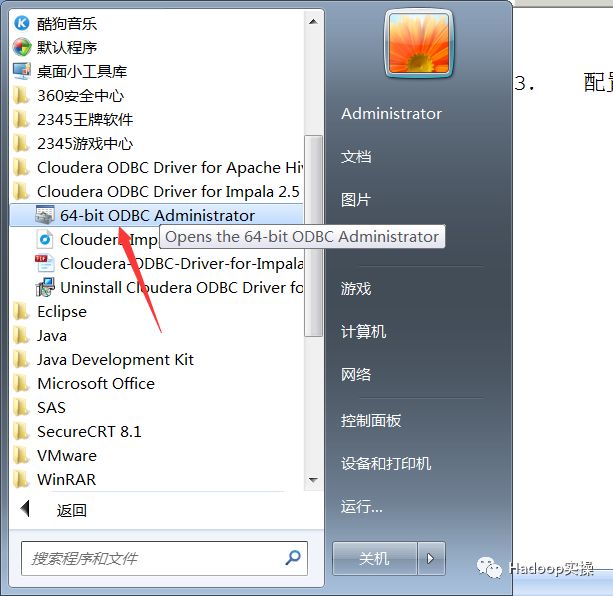
如图打开64-bit ODBC administrator → 用户DSN → 添加 → 选择cloudera odbcdriver for impala → 点击完成
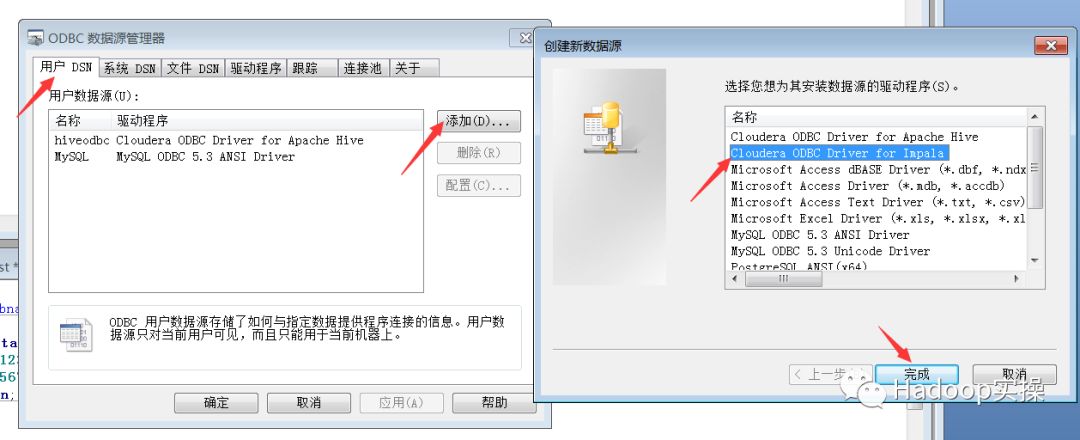
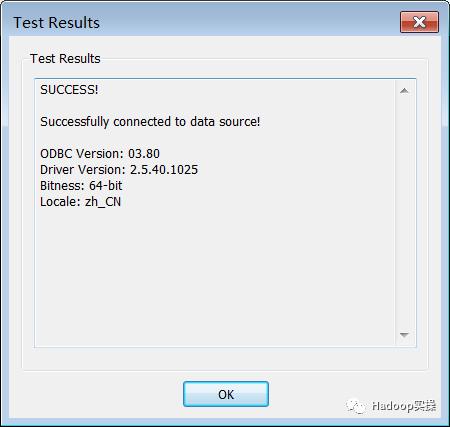
弹出配置界面→填写好host和其他信息→点击test→弹出success,配置完成
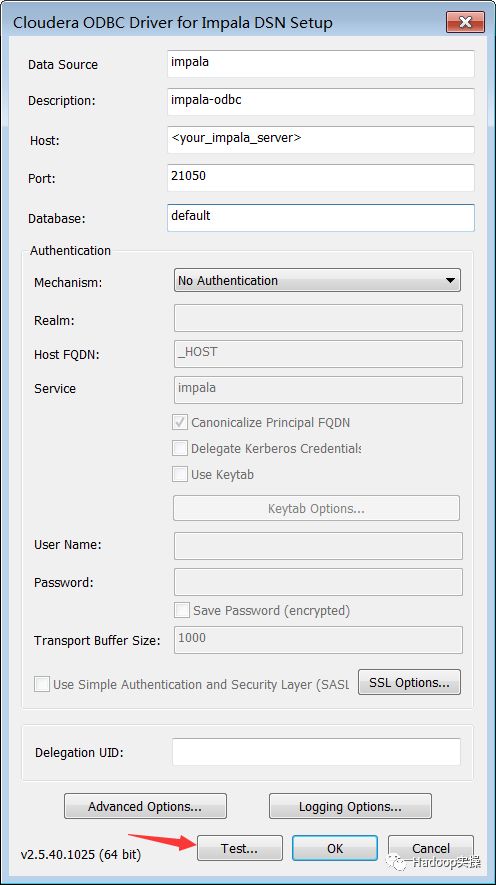
点击“Test…”按钮,测试结果如下则表示使用ODBC的方式连接Impala成功:
7.SAS连接Impala及操作
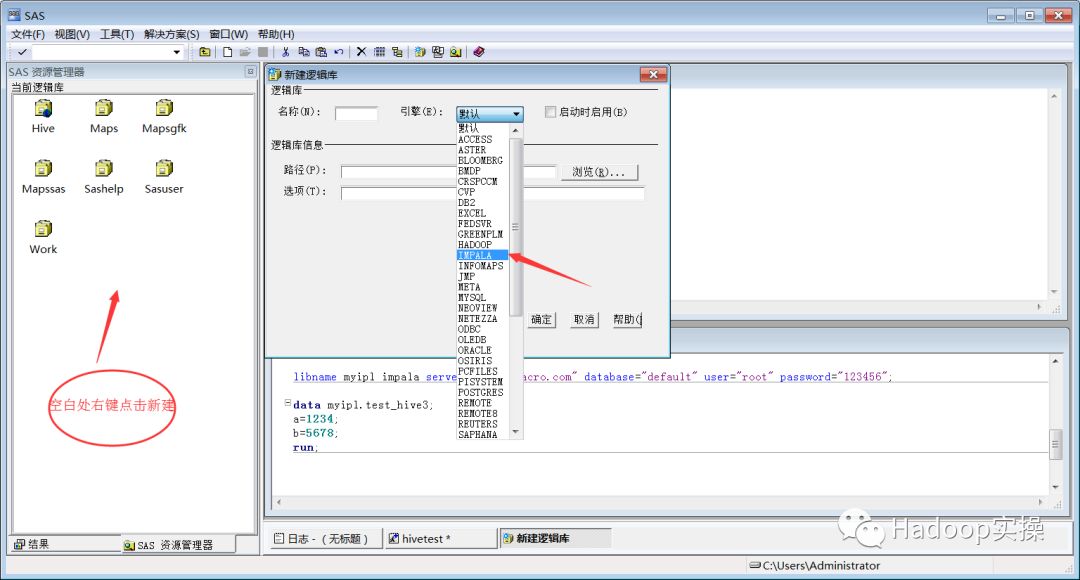
1.在sas资源管理器界面空白处右键点击新建→引擎选择impala,
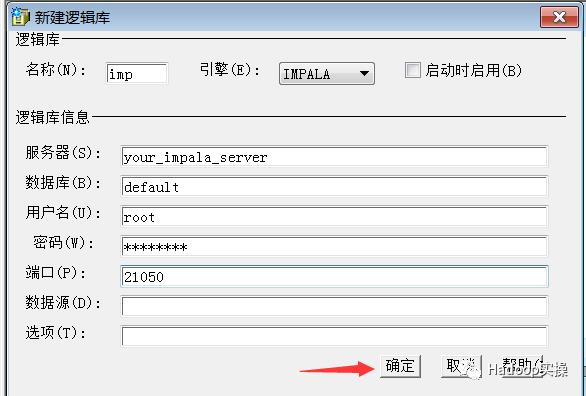
2.输入impala的库名、服务器,数据库名、端口,由于集群未启用安全所以这里用户名和密码可不填
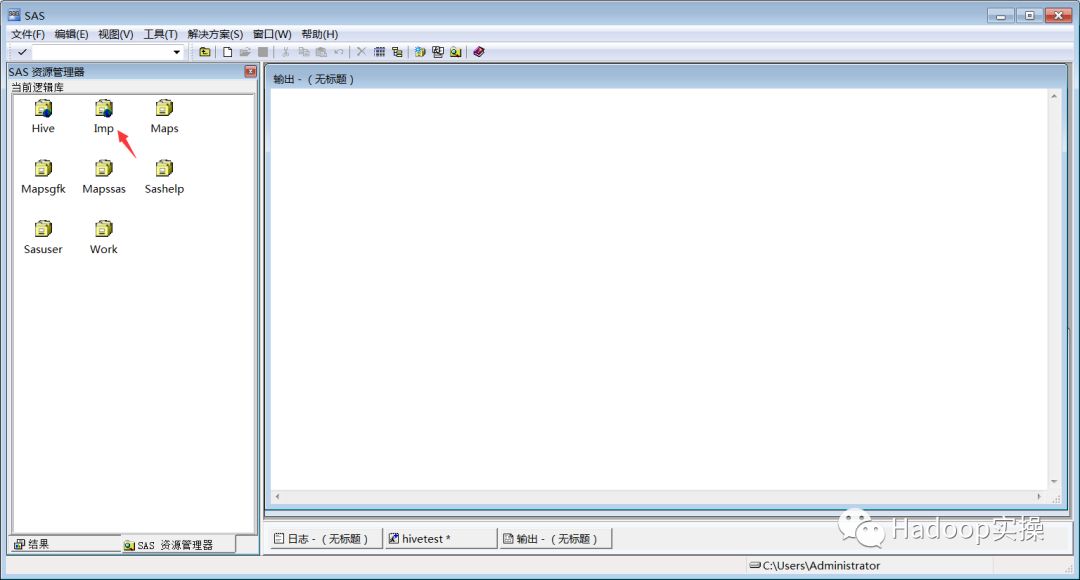
3.信息输入完成后,点击确定,可以看到在SAS的资源管理界面新增了一个imp的逻辑库
4.双击逻辑库名称进入imp逻辑库,查看逻辑库下的表及qqtest表内容
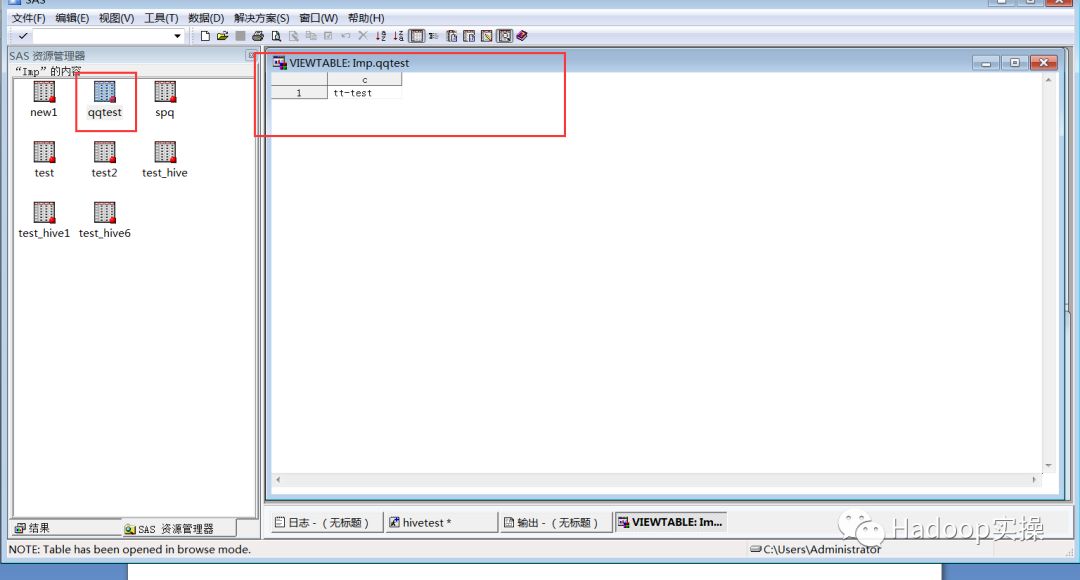
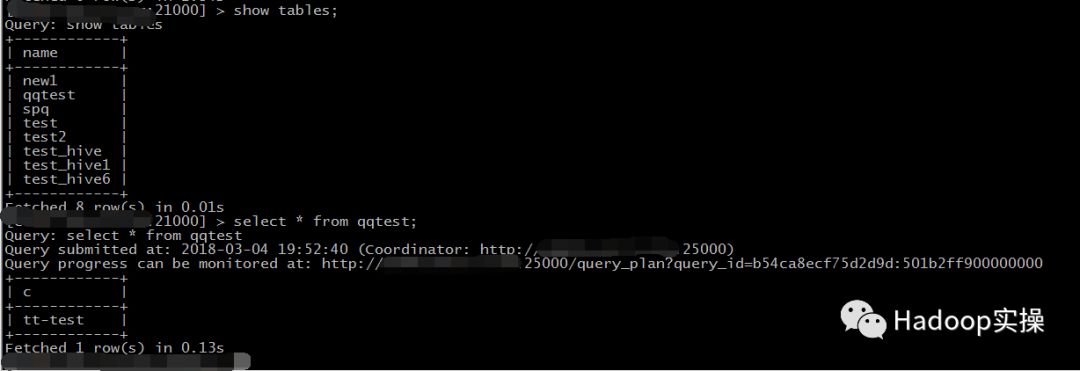
使用Impala-shell命令访问Impala,查看default库下表与imp逻辑库下表信息一致
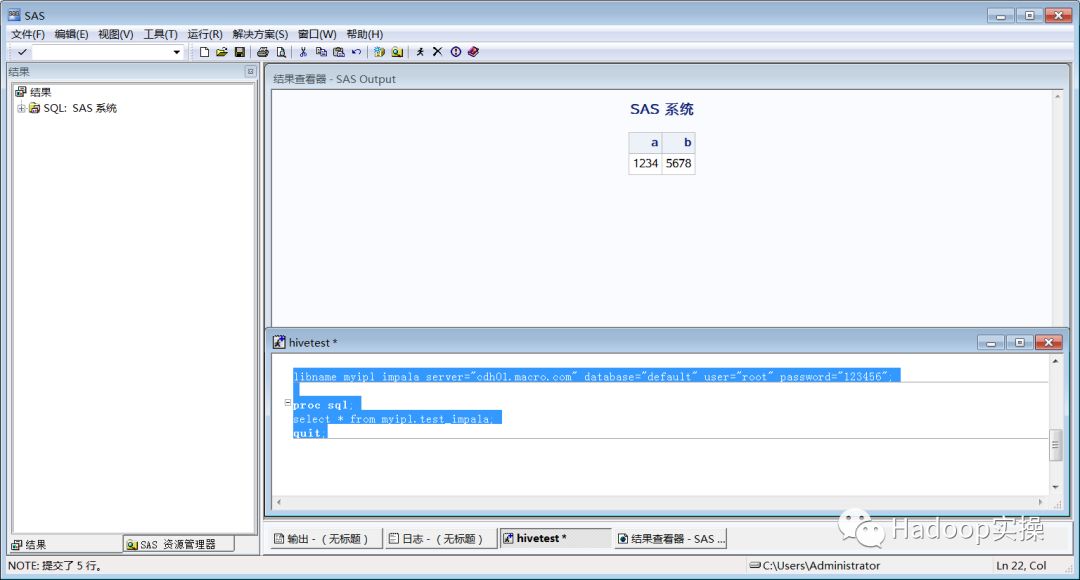
5.编写SAS访问Impala代码,其代码与hive相同,示例如下:
libname myipl impala server="your_impala_server" database="default" user="root" password="123456";
proc sql;
select * from myipl.test_impala;
quit;
(可左右滑动)
提示:代码块部分可以左右滑动查看噢
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。
以上是关于如何安装SAS并配置连接Hive/Impala的主要内容,如果未能解决你的问题,请参考以下文章