hive原理
Posted 人工智能时代AI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive原理相关的知识,希望对你有一定的参考价值。
hive是什么
Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据。它架构在Hadoop之上,总归为大数据,并使得查询和分析方便。
最初,Hive是由Facebook开发,后来由Apache软件基金会开发,并作为进一步将它作为名义下Apache Hive为一个开源项目。它用在好多不同的公司。例如,亚马逊使用它在 Amazon Elastic MapReduce。
Hive通常意义上来说,是把一个SQL转化成一个分布式作业,如MapReduce,Spark或者Tez。无论Hive的底层执行框架是MapReduce、Spark还是Tez,其原理基本都类似。
hive不是什么
一个关系数据库
一个设计用于联机事务处理(OLTP)
实时查询和行级更新的语言
Hiver特点
它存储架构在一个数据库中并处理数据到HDFS。
它是专为OLAP设计。
它提供SQL类型语言查询叫HiveQL或HQL。
它是熟知,快速,可扩展和可扩展的。
Hive架构图解
Hive是最上层,即客户端层或者作业提交层。
MapReduce/Yarn是中间层,也就是计算层。
HDFS是底层,也就是存储层。
该组件图包含不同的单元。下表描述每个单元:
| 单元名称 | 操作 |
|---|---|
| 用户接口/界面 | Hive是一个数据仓库基础工具软件,可以创建用户和HDFS之间互动。用户界面,Hive支持是Hive的Web UI,Hive命令行,HiveHD洞察(在Windows服务器)。 |
| 元存储 | Hive选择各自的数据库服务器,用以储存表,数据库,列模式或元数据表,它们的数据类型和HDFS映射。 |
| HiveQL处理引擎 | HiveQL类似于SQL的查询上Metastore模式信息。这是传统的方式进行MapReduce程序的替代品之一。相反,使用Java编写的MapReduce程序,可以编写为MapReduce工作,并处理它的查询。 |
| 执行引擎 | HiveQL处理引擎和MapReduce的结合部分是由Hive执行引擎。执行引擎处理查询并产生结果和MapReduce的结果一样。它采用MapReduce方法。 |
| HDFS 或 HBASE | Hadoop的分布式文件系统或者HBASE数据存储技术是用于将数据存储到文件系统。 |
Hive工作原理
Hive的核心是Driver,Driver的核心是SemanticAnalyzer。 Hive实际上是一个SQL到Hadoop作业的编译器。 Hadoop上最流行的作业就是MapReduce,当然还有其它,比如Tez和Spark。Hive目前支持MapReduce, Tez, Spark三种作业,其原理和刚才回顾的MapReduce过程类似,只是在执行优化上有区别。
Hive作业的执行过程实际上是SQL翻译成作业的过程?那么,它是怎么翻译的?
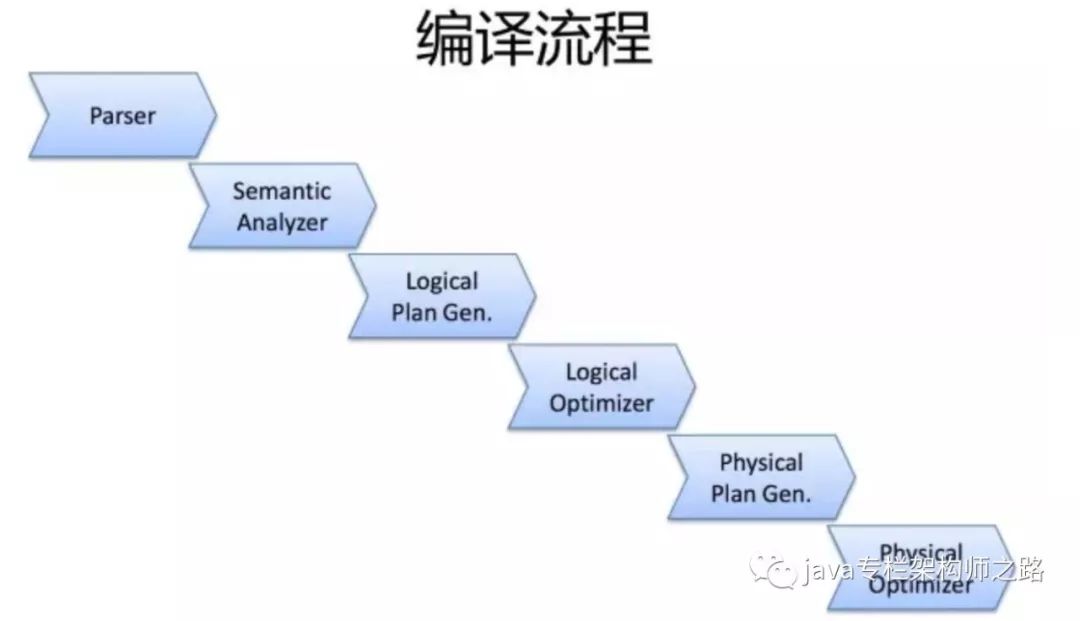
一条SQL,进入的Hive。经过上述的过程,其实也是一个比较典型的编译过程变成了一个作业。
1、首先,Driver会输入一个字符串SQL,然后经过Parser变成AST,这个变成AST的过程是通过Antlr来完成的,也就是Anltr根据语法文件来将SQL变成AST。
2、AST进入SemanticAnalyzer(核心)变成QB,也就是所谓的QueryBlock。一个最简的查询块,通常来讲,一个From子句会生成一个QB。生成QB是一个递归过程,生成的 QB经过GenLogicalPlan过程,变成了一个Operator图,也是一个有向无环图。
3、OP DAG经过逻辑优化器,对这个图上的边或者结点进行调整,顺序修订,变成了一个优化后的有向无环图。这些优化过程可能包括谓词下推(Predicate Push Down),分区剪裁(Partition Prunner),关联排序(Join Reorder)等等
4、经过了逻辑优化,这个有向无环图还要能够执行。所以有了生成物理执行计划的过程。GenTasks。Hive的作法通常是碰到需要分发的地方,切上一刀,生成一道MapReduce作业。如Group By切一刀,Join切一刀,Distribute By切一刀,Distinct切一刀。
5、这么很多刀砍下去之后,刚才那个逻辑执行计划,也就是那个逻辑有向无环图,就被切成了很多个子图,每个子图构成一个结点。这些结点又连成了一个执行计划图,也就是Task Tree.
6、把这些个Task Tree 还可以有一些优化,比如基于输入选择执行路径,增加备份作业等。进行调整。这个优化就是由Physical Optimizer来完成的。经过Physical Optimizer,这每一个结点就是一个MapReduce作业或者本地作业,就可以执行了。
7、这就是一个SQL如何变成MapReduce作业的过程。要想观查这个过程的最终结果,可以打开Hive,输入Explain + 语句,就能够看到。
Hive知识体系
以上是关于hive原理的主要内容,如果未能解决你的问题,请参考以下文章