Hive调优及原理分析
Posted NC_NE
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive调优及原理分析相关的知识,希望对你有一定的参考价值。
一、Fetch 抓取
Fetch 抓取是指, Hive 中对某些情况的查询可以不必使用 MapReduce 计算。 Hive 可以简单地读取 employee 对应的存储目录下的文件,然后输出查询结果到控制台。可以在配置文件里面修改,也可以通过参数设置
在 hive-default.xml.template 文件中 hive.fetch.task.conversion 默认是 more,老版本 hive默认是 minimal,
more:在全局查找、字段查找、 limit 查找等都不走MR
minimal:仅在分区表分区字段过滤情况下不走MR
none:全部查询都走MR
配置文件修改:
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
<description>
Expects one of [none, minimal, more].
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have
any aggregations or distincts (which incurs RS), lateral views and joins.
0. none : disable hive.fetch.task.conversion
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only
2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)
</description>
</property>直接修改参数,执行查询sql前执行参数设置,只对当前session有用
set hive.fetch.task.conversion=none;
set hive.fetch.task.conversion=more;
select * from test;二、本地模式
当 Hive 的输入数据量是非常小,Hive 可以通过本地模式在单台机器上处理所有的任务,执行时间可以明显被缩短。
参数设置:
//开启本地 mr
set hive.exec.mode.local.auto=true;
//设置 local mr 的最大输入数据量,当输入数据量小于这个值时采用 local mr 的方式,默认为134217728,即 128M
set hive.exec.mode.local.auto.inputbytes.max=50000000;
//设置 local mr 的最大输入文件个数,当输入文件个数小于这个值时采用 local mr的方式,默认为 4
set hive.exec.mode.local.auto.input.files.max=10;三、MapJoin
在 Reduce 阶段完成 join。容易发生数据倾斜。可以用 MapJoin 把小表全部加载到内存在 map 端进行 join,避免 reducer 处理。如果开启了hive会通过读取的文件大小(根据集群内存资源来确定)来判断是否是小表,如果不是则转成reduce join
参数设置:
//设置自动选择 MapJoin,默认为 true
set hive.auto.convert.join = true;
//大表小表的阈值设置(默认 25M 一下认为是小表)
set hive.mapjoin.smalltable.filesize=25000000;MapJoin 工作机制

四、合并小文件
合并小文件有三个地方,
map输入,避免每一个小文件启一个mapTask
map输出,reduce输出
参数设置:
1) 设置map输入的小文件合并
set mapred.max.split.size=256000000;
//一个节点上split的至少的大小(这个值决定了多个DataNode上的文件是否需要合并)
set mapred.min.split.size.per.node=100000000;
//一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并)
set mapred.min.split.size.per.rack=100000000;
//执行Map前进行小文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
2) 设置map输出和reduce输出进行合并的相关参数:
//设置map端输出进行合并,默认为true
set hive.merge.mapfiles = true
//设置reduce端输出进行合并,默认为false
set hive.merge.mapredfiles = true
//设置合并文件的大小
set hive.merge.size.per.task = 256*1000*1000
//当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件merge。
set hive.merge.smallfiles.avgsize=16000000五、并行执行
某个 job 可能包含众多的阶段,而这些阶段可能并非完全互相依赖的,也就是说有些阶段是可以并行执行的,这样可能使得整个 job 的执行时间缩短
参数设置:
//打开任务并行执行
set hive.exec.parallel=true;
//同一个 sql 允许最大并行度,默认为 8
set hive.exec.parallel.thread.number=16; 六、动态分区
分区表实际上就是对应一个 HDFS 文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。 Hive 中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。
参数设置:
//开启动态分区功能
set hive.exec.dynamic.partition=true;
//设置分严格模式(允许不指定至少一个静态分区)
set hive.exec.dynamic.partition.mode=nonstrict;
//在所有执行 MR 的节点上,最大一共可以创建多少个动态分区。默认 1000
set hive.exec.max.dynamic.partitions=1000;
//在每个执行 MR 的节点上,最大可以创建多少个动态分区
set hive.exec.max.dynamic.partitions.pernode=100
//整个 MR Job 中,最大可以创建多少个 HDFS 文件。默认 100000
set hive.exec.max.created.files=100000
//当有空分区生成时,是否抛出异常。一般不需要设置。默认 false
set hive.error.on.empty.partition=false七、推测执行
推测执行(Speculative Execution)机制就是根据一定的法则推测出执行慢的任务,并为这样的任务启动一个备份任务,让该任务与原始任务同时处理同一份数据,并最终选用最先成功运行完成任务的计算结果作为最终结果。
设置开启推测执行参数: Hadoop 的 mapred-site.xml 文件中进行配置
<property>
<name>mapreduce.map.speculative</name>
<value>true</value>
<description>
If true, then multiple instances of some map tasks may be executed in parallel.
</description>
</property>
<property>
<name>mapreduce.reduce.speculative</name>
<value>true</value>
<description>
If true, then multiple instances of some reduce tasks may be executed in parallel.
</description>
</property>hive 提供的推测执行配置(默认是true),永久生效
<property>
<name>hive.mapred.reduce.tasks.speculative.execution</name>
<value>true</value>
<description>
Whether speculative execution for reducers should be turned on.
</description>
</property>当前session生效
set hive.mapred.reduce.tasks.speculative.execution=true八、压缩
Map输出阶段压缩
//开启hive中间传输数据压缩功能
set hive.exec.compress.intermediate=true;
//开启mapreduce中map输出压缩功能
set mapreduce.map.output.compress=true;
//设置mapreduce中map输出数据的压缩方式
set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;Reduce输出阶段压缩
//开启hive最终输出数据压缩功能
set hive.exec.compress.output=true;
//开启mapreduce最终输出数据压缩
set mapreduce.output.fileoutputformat.compress=true;
//设置mapreduce最终数据输出压缩方式
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
//设置mapreduce最终数据输出压缩为块压缩
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
九、Group by 倾斜优化
1、我们可以在map中会做部分聚集(combiner)操作,效率更高但需要更多的内存。
//开启map端聚合
set hive.map.aggr=true;
//(默认)执行聚合的条数
set hive.groupby.mapaggr.checkinterval=100000;
//#如果hash表的容量与输入行数之比超过这个数,那么map端的hash聚合将被关闭,默认是0.5,设置为1可以保证hash聚合永不被关闭;
set hive.map.aggr.hash.min.reduction=0.5;2、通过两个MRJob来进行,第一个MRJob 中,Map的输出结果集合会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的GroupBy Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MRJob再根据预处理的数据结果按照GroupBy Key分布到Reduce中(这个过程可以保证相同的GroupBy Key被分布到同一个Reduce中),最后完成最终的聚合操作。
参数设置:
//如果是group by过程出现倾斜 应该设置为true
set hive.groupby.skewindata=true;
//这个是group的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置
set hive.groupby.mapaggr.checkinterval=1000000;MR的执行原理
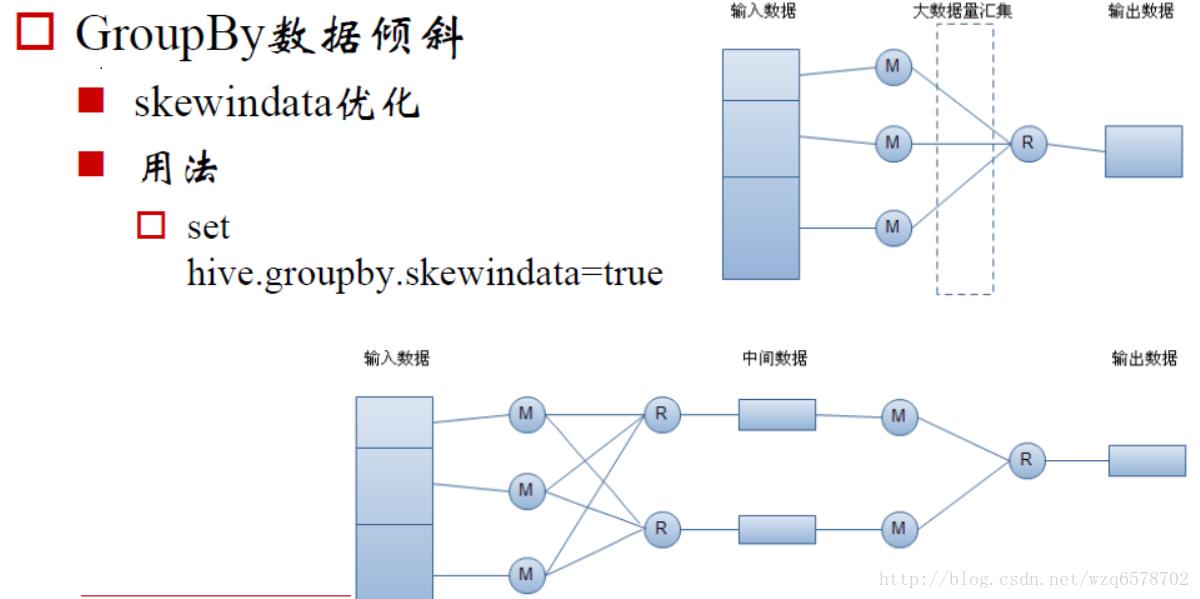
我们直接通过sql来实现set hive.groupby.skewindata=true;
select
t1.id,
count(t1.cnt) cnt
from (
select
id,
if(id = '1001',cast(rand() * 10 as int ),0),
count(1) as cnt
from test
group by id,if(id = '1001',cast(rand() * 10 as int ),0)
)t1
group by t1.id;十、join 倾斜优化
如果是小表join大表我们可以转换成MapJoin来优化,如上
如果是大表join大表我们使用skewjoin
参数设置:
//如果是join 过程出现倾斜 应该设置为true
set hive.optimize.skewjoin=true;
//这个是join的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置
set hive.skewjoin.key=1000000;
//处理数据倾斜的MapJoin的Map任务数
set hive.skewjoin.mapjoin.map.tasks=10000;
//处理数据倾斜的MapJoin的最小数据切分大小,以字节为单位,默认为32M
set hive.skewjoin.mapjoin.min.split=33554432;skewjoin原理
1、对于skewjoin.key,在执行job时,将它们存入临时的HDFS目录。其它数据正常执行
2、对倾斜数据开启map join操作,对非倾斜值采取普通join操作
3、将倾斜数据集和非倾斜数据及进行合并操作

以上是关于Hive调优及原理分析的主要内容,如果未能解决你的问题,请参考以下文章