Hive生产上,压缩和存储结合使用案例
Posted 若泽大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive生产上,压缩和存储结合使用案例相关的知识,希望对你有一定的参考价值。
案例:
原文件大小:19M
1. ORC+Zlip结合
create table page_views_orc_zlib
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
STORED AS ORC
TBLPROPERTIES("orc.compress"="ZLIB")
as select * from page_views;
用ORC+Zlip之后的文件为2.8M

2. Parquet+gzip结合
set parquet.compression=gzip;
create table page_views_parquet_gzip
ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
STORED AS PARQUET
as select * from page_views;
用Parquet+gzip之后的文件为3.9M

3. Parquet+Lzo结合
3.1 安装Lzo
wget http://www.oberhumer.com/opensource/lzo/download/lzo-2.06.tar.gz
tar -zxvf lzo-2.06.tar.gz
cd lzo-2.06
./configure -enable-shared -prefix=/usr/local/hadoop/lzo/
make && make install
cp /usr/local/hadoop/lzo/lib/* /usr/lib/
cp /usr/local/hadoop/lzo/lib/* /usr/lib64/
vi /etc/profile
export PATH=/usr/local//hadoop/lzo/:$PATH
export C_INCLUDE_PATH=/usr/local/hadoop/lzo/include/
source /etc/profile
3.2 安装Lzop
wget http://www.lzop.org/download/lzop-1.03.tar.gz
tar -zxvf lzop-1.03.tar.gz
cd lzop-1.03
./configure -enable-shared -prefix=/usr/local/hadoop/lzop
make && make install
vi /etc/profile
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/lib64
source /etc/profile
3.3 软连接
ln -s /usr/local/hadoop/lzop/bin/lzop /usr/bin/lzop
3.4 测试lzop
lzop xxx.log
若生成xxx.log.lzo文件,则说明成功
3.5 安装Hadoop-LZO
git或svn 下载https://github.com/twitter/hadoop-lzo
cd hadoop-lzo
mvn clean package -Dmaven.test.skip=true
tar -cBf - -C target/native/Linux-amd64-64/lib . | tar -xBvf - -C /opt/software/hadoop/lib/native/
cp target/hadoop-lzo-0.4.21-SNAPSHOT.jar /opt/software/hadoop/share/hadoop/common/
3.6 配置
在core-site.xml配置
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec,
com.hadoop.compression.lzo.LzopCodec
</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
在mapred-site.xml中配置
<property>
<name>mapreduce.output.fileoutputformat.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
<property>
<name>mapred.child.env</name>
<value>LD_LIBRARY_PATH=/usr/local/hadoop/lzo/lib</value>
</property>
在hadoop-env.sh中配置
export LD_LIBRARY_PATH=/usr/local/hadoop/lzo/lib
3.7 测试
SET hive.exec.compress.output=true;
SET mapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.lzopCodec;
SET mapred.output.compression.codec=com.hadoop.compression.lzo.LzopCodec;
create table page_views_parquet_lzo ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"
STORED AS PARQUET
TBLPROPERTIES("parquet.compression"="lzo")
as select * from page_views;
用Parquet+Lzo(未建立索引)之后的文件为5.9M
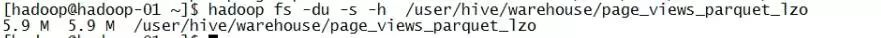
打个小小的广告哟
1.若泽数据 官网: www.ruozedata.com
(每周3篇大数据相关原创文章,联系客服领取若泽2017+2018年所有腾讯课堂公开课视频,尚未外泄,独此1家)

3.
4.若泽大数据--星星:ruoze_star
以上是关于Hive生产上,压缩和存储结合使用案例的主要内容,如果未能解决你的问题,请参考以下文章