阿里云大数据利器MaxCompute学习之—假如你使用过hive
Posted 养码场
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里云大数据利器MaxCompute学习之—假如你使用过hive相关的知识,希望对你有一定的参考价值。
如果您是一个大数据开发工程师并且使用过hadoop的hive框架,那么恭喜你,阿里云的大数据计算服务-MaxCompute,你已经会了90%。
这是一篇对比MaxCompute和hive的异同的文章,场主希望帮助刚开始使用MaxCompute的技术人,阅完此文,能够从hive秒速迁移到MaxCompute的使用上。
首先,回顾下hive的概念
1、hive是基于hadoop的,以表的形式来存储数据,实际上数据是存储在hdfs上,数据库和表其实是hdfs上的两层目录,数据是放在表名称目录下的,计算还是转换成mapreduce计算。
2、hive可以通过客户端命令行和java api操作数据
3、hive是hql语言操作表,跟通用sql语言的语法大致相同,可能会多一些符合本身计算的函数等。hql会解析成mapreduce进行相关逻辑计算
4、hive有分区分桶的概念
5、hive可以通过命令从本地服务器来上传下载表数据
6、hive可以通过外部表功能映射hbase和es等框架的数据
7、hive任务可以通过hadoop提供的webUI来查看任务进度,日志等
8、hive支持自定义函数udf,udaf,udtf
9、hive可以通过hue界面化操作
10、hive可以通过sqoop等工具和其他数据源交互
11、资源调度依赖于hadoop-yarn平台
那么如果你对这些hive的功能稍微熟悉的话,现在我告诉你,MaxCompute的功能以及用法和上述hive功能基本一致。
MaxCompute的组件:
MaxCompute 主要服务于批量结构化数据的存储和计算,可以提供海量数据仓库的解决方案以及针对大数据的分析建模服务,支持sql查询计算,自定义函数udf实现复杂逻辑,mapreduce程序实现更具体的业务计算,支持Graph面向迭代的图计算处理框架,提供java api来连接操作sqltask。
是不是初步看起来MaxCompute也是和hive一样,可以用sql,udf,mr。
①文件系统对比
对比差异之前,容许我先简单介绍下阿里云的基石-飞天系统,详细的可以网上搜下。飞天系统是分布式的文件存储和计算系统,听起来是不是好熟悉,是不是和hadoop的味道一样。
这里对于MaxCompute可以暂时把它当作是hadoop类似的框架,那MaxCompute就是基于飞天系统的,类似于hive基于hadoop。
hive的数据实际上是在hdfs上,元数据一般放在mysql,以表的形式展现。你可以直接到hdfs上查到具体文件。Maxcompute的数据是在飞天文件系统,对外不暴露文件系统,底层优化会自动做好。
②hive和MaxCompute客户端
直接上图来对比hive的客户端:
MaxCompute(原odps)的客户端:
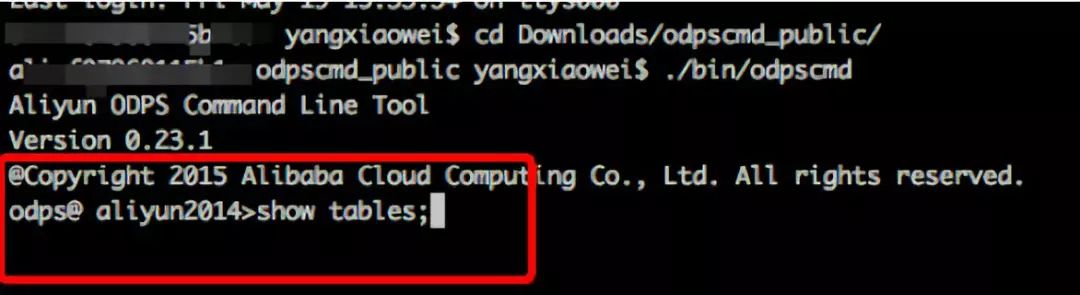
是不是看起来一致。
实际上,项目空间(Project)是 MaxCompute 的基本组织单元,它类似于传统数据库的Database 或 Schema 的概念,是进行多用户隔离和访问控制的主要边界 。一个用户可以同时拥有多个项目空间的权限
配置文件如图
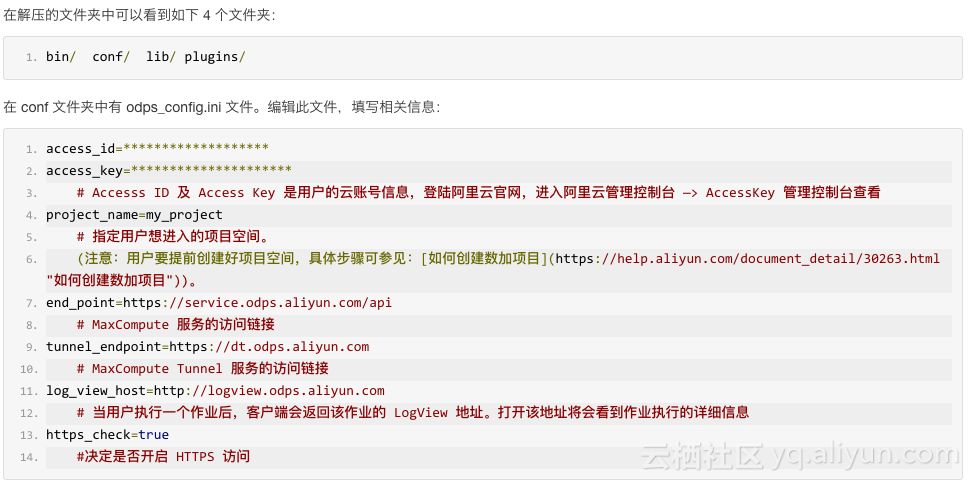
在客户端中可以执行sql和其他命令。
那么MaxCompute除了命令行客户端也提供了python和java的sdk来访问。不说了直接上代码!
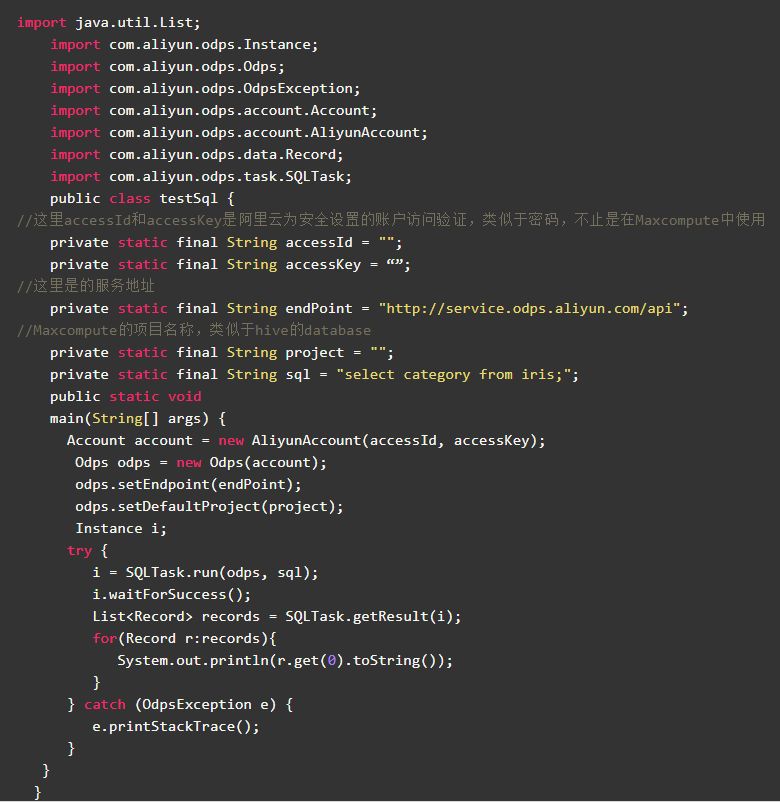
是不是觉得很亲切,跟大多数数据库的访问方式一样。
③odpscmd和hivesql
首先来看建表语句
hive标准建表语句:
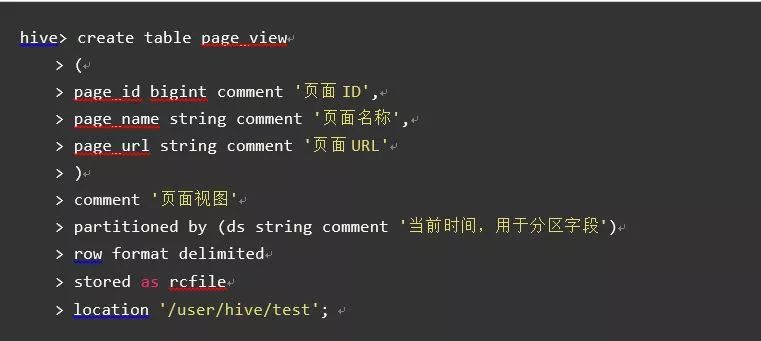
MaxCompute建表语句:

从建表语句上明显的可以感觉出来,MaxCompute没有指定分隔符,没有指定文件存储路径,没有指定文件的存储格式。难道是默认的吗?不!
因为MaxCompute是基于阿里云飞天文件系统,用户无需关心文件存储格式,压缩格式,存储路径等,这些操作由阿里云来完成,用户也不用来疲于文件存储成本,压缩性价比,读写速度等优化,可以将精力集中在业务的开发上。
另外二者的数据的上传下载;hive可以通过命令,比如上传。
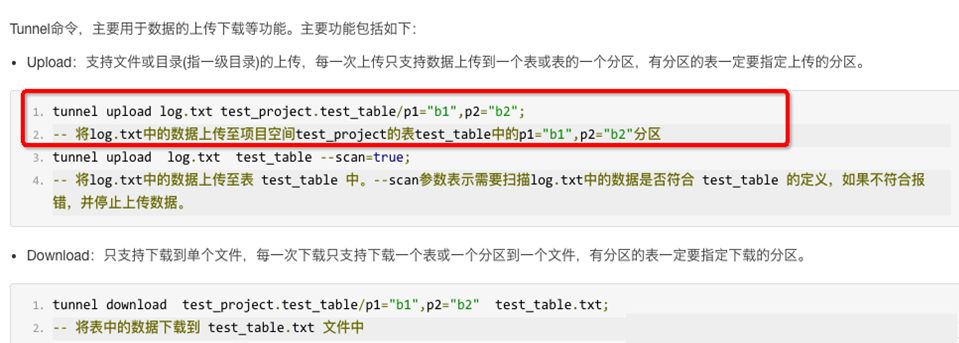
MaxCompute是通过命令工具 tunnel上传下载,同时支持在上传过程校验文件格式脏数据等。
④分区和分桶
分区的概念相信使用hive的同学很熟悉,其实就是在表目录上再套一层目录,将数据区分,目的就是提高查询效率。那么从上面建表语句中可以看出MaxCompute和hive都是支持分区的,概念用法一致。
关于分桶,上面建表语句中hive中有分桶语句,MaxCompute没有分桶的操作,实际上分桶是把一个大文件根据某个字段hash成多个小文件,适当的分桶会提高查询效率,在MaxCompute中这些优化底层已经做了。
⑤外部表功能
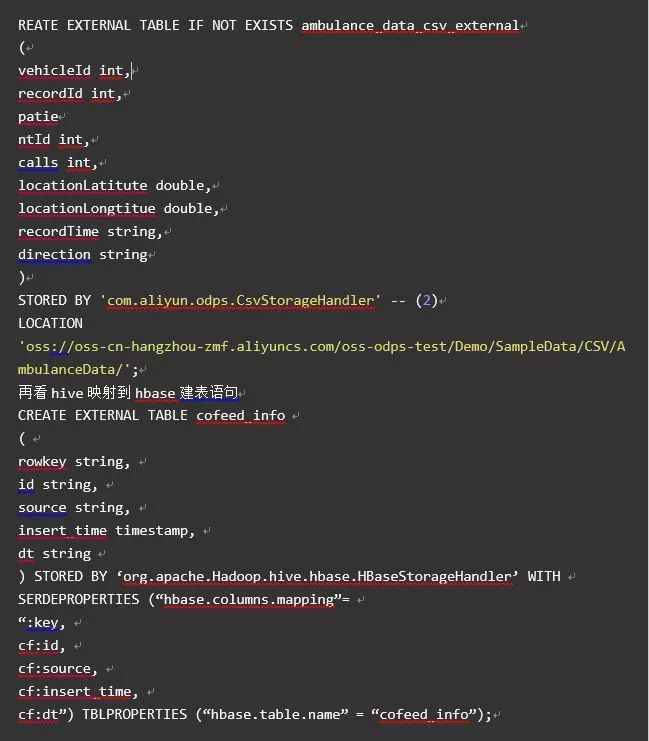
hive可以通过外部表的功能来操作例如hbase和es的数据。外部表功能MaxCompute (2.0版本支持)中也是同样适用,MaxCompute通过外部表来映射阿里云的OTS和OSS两个数据存储产品来处理非结构化的数据,例如音频视频等。看下建表语句:
语法基本一致,MaxCompute可以自定义extractor来处理非结构化数据,可以参考https://yq.aliyun.com/articles/61567来学习。
⑥webui
hive任务依赖于hadoop的hdfs和yarn提供的webui访问。看下对比
hadoopwebui
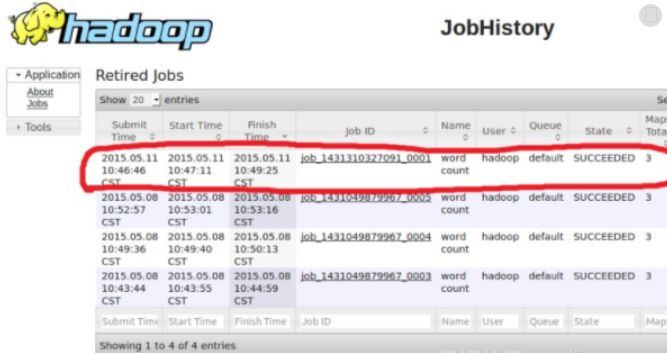
在这里可以通过历史任务来查看hive任务的执行情况。个人觉得页面不是很友好。
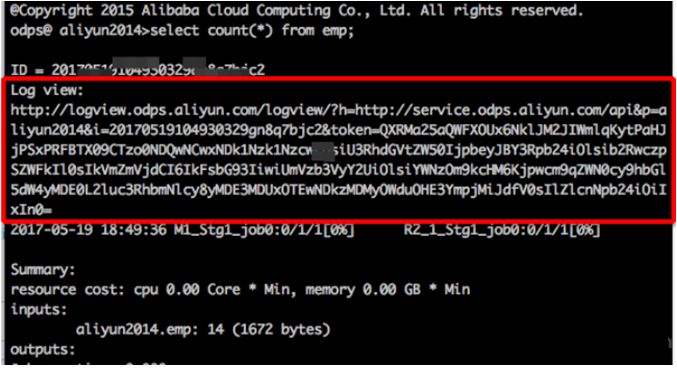
在浏览器中打开,总体上一看,非常清晰明了:任务开始时间结束时间,任务状态,绿色进度条。很方便的获取任务的总体情况。
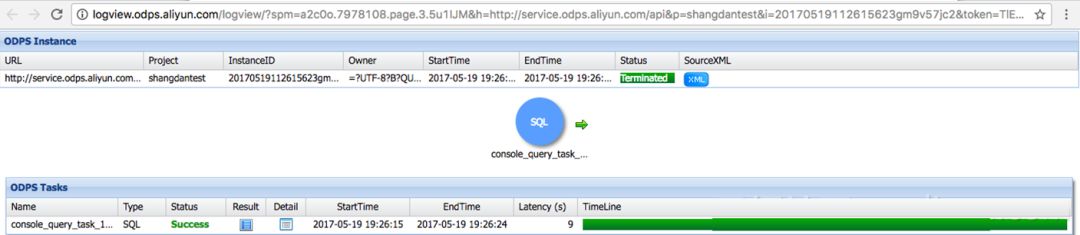
点击Detail按钮可以看更具体的调度,日志等
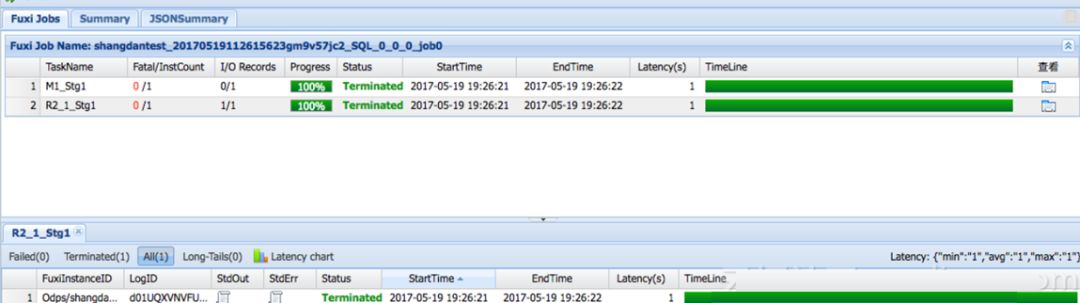
点击jsonsumary可以看到非常详细的执行过程
那么可以看到MaxCompute的webui还是比较友好的,方便用户很快定位问题。调度方面这里也说一下是由阿里云统一调度,用户无需关心优化。
⑦自定义函数的支持
hive和MaxCompute都支持自定函数。同样是三种,udf,udtf,udaf。
代码写法一致。最大的区别在于数据类型的支持上。
目前MaxCompute支持的数据类型是UDF 支持, MaxCompute SQL 的数据类型有:Bigint, String, Double, Boolean 类型 。MaxCompute 数据类型与 Java 类型的对应关系如下:

注意:
java 中对应的数据类型以及返回值数据类型是对象,首字母请务必大写;
目前暂不支持 datetime 数据类型,建议可以转换成 String 类型传入处理 。
SQL 中的 NULL 值通过 Java 中的 NULL 引用表示,因此 Java primitive type 是不允许使用的,因为无法表示 SQL 中的 NULL 值 。所以不同于hive中支持各种类型。
看MaxCompute代码示例
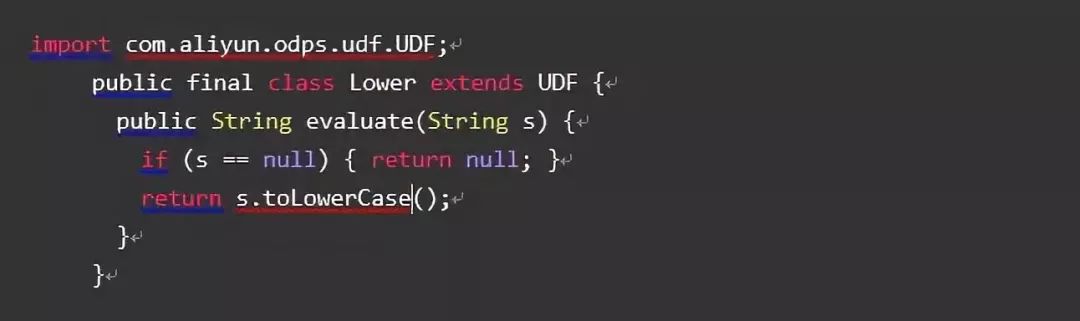
用法一致,所以使用hive的用户基本可以直接迁移。
在此强调一下,在MaxCompute中处于安全层面的考虑对udf和mr是有java沙箱限制的,比如在udf代码中不能启用其他线程等等,具体可以参考
https://help.aliyun.com/document_detail/27967.html
那么可以看到MaxCompute的webui还是比较友好的,方便用户很快定位问题。调度方面这里也说一下是由阿里云统一调度,用户无需关心优化。
⑧界面化操作
谈到界面化的操作,阿里云的产品基本上都是界面化操作,可拖拽等等,开发门槛非常低,所以也是非常适合初学大数据或者公司没有相关开发人力的公司。
hive可以借助hue工具来操作查询数据,但是实际上交互性不是很强。
那么这里就将MaxCompute的界面化操作以及数据同步,权限控制,数据管理,和其他数据源交互,定时调度等简单介绍下,就是阿里云的产品-大数据开发套件,目前是免费使用的。需要开通MaxCompute项目进入操作。等不及了直接上图~
1、MaxCompute sql 查询界面化
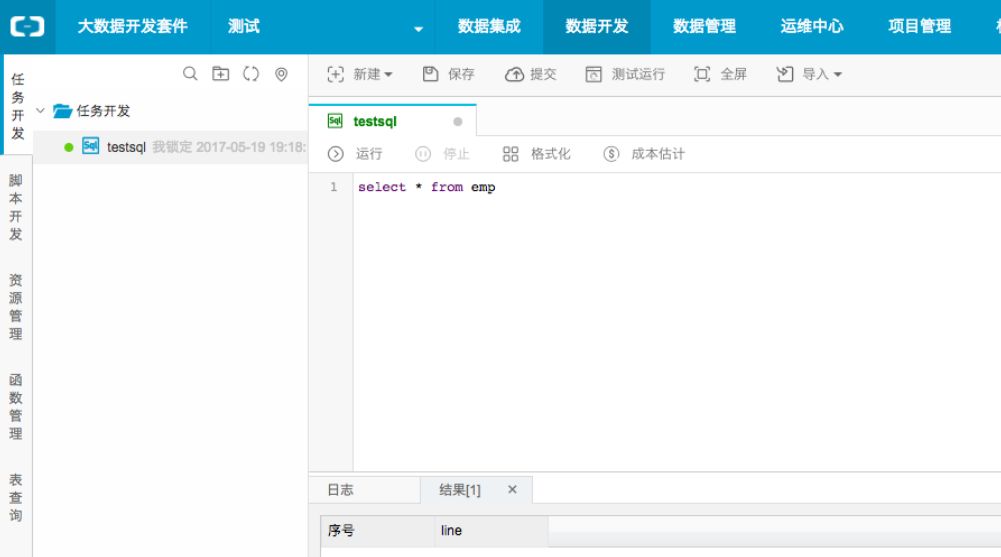
2、MaxCompute mapreduce界面化配置
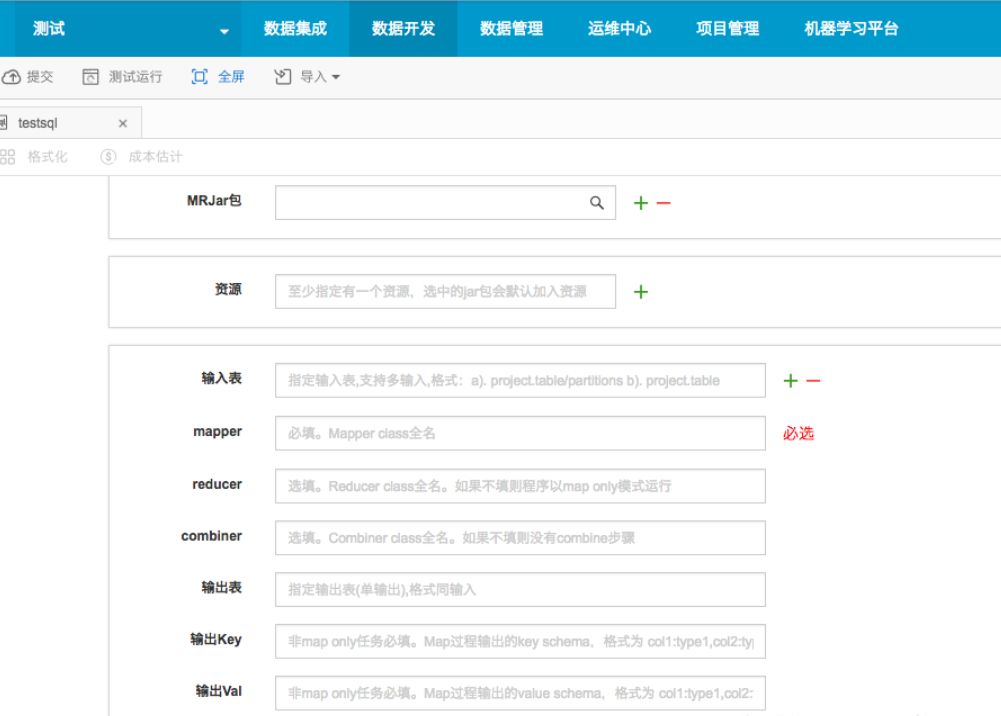
3、MaxCompute数据同步界面化
hive可以通过sqoop工具和多种数据源进行数据同步。MaxCompute在大数据开发套件中也是非常方便的和其他数据源进行同步。
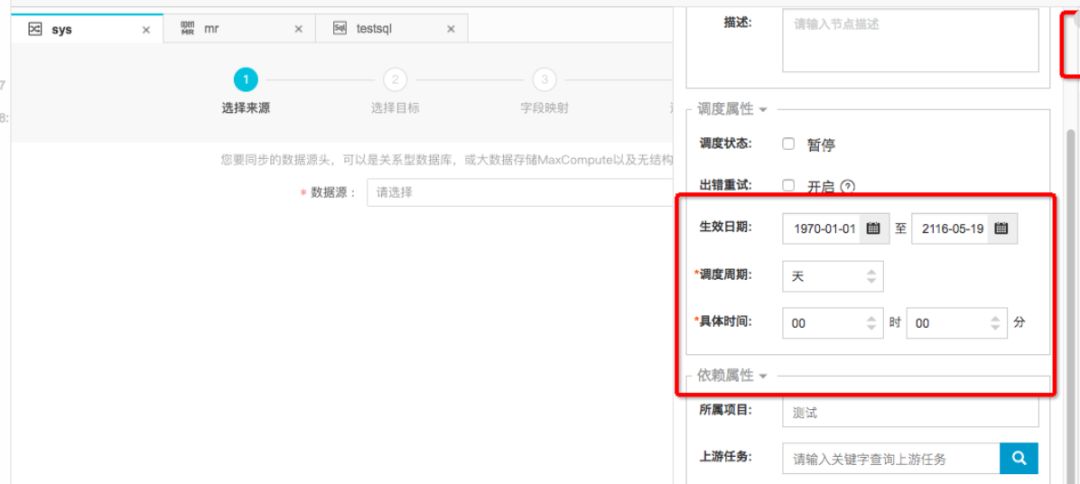
并且可以配置流程控制,调度
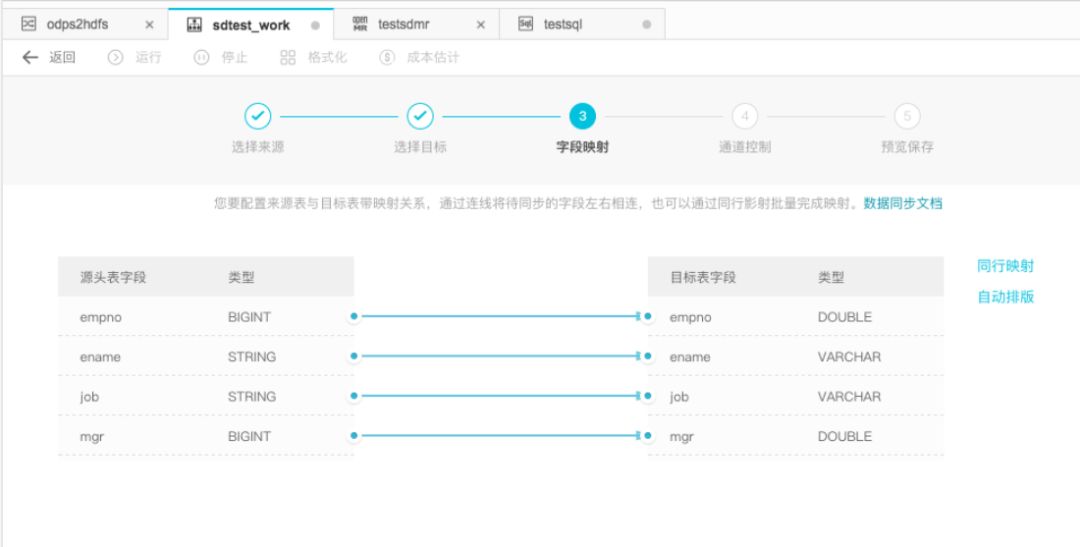
是不是很神奇,惊不惊喜,意不意外。具体的使用还是大家亲自体验,这里就不一一介绍了。
那最后来看下hadoop-mapreduce和MaxCompute-mapreduce的使用对比。还是用大家最喜欢的wordcount来做示例。
介绍之前还是要强调一下:
1,MaxCompute-mapreduce输入输出都是表(或者分区)的形式,如果需要引用其他文件,需要先上传。
2,MaxCompute-mapreduce也是有沙箱限制,不允许在代码中启用别的框架线程等。
hadoop-mr代码就不贴了,直接上MaxCompute-mapreduce代码
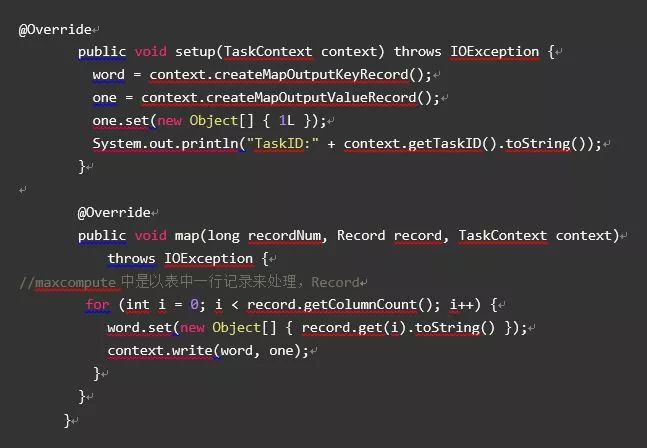
再看job主函数配置,代码逻辑是通用的。
那么基本上主要的功能对比差不多了,大家可以发现,如果您是一位使用过hive的开发人员可以秒迁移到MaxCompute上,更加方便简洁的来做开发,将开发人员从苦逼的加班中解放出来,实际上公司节省了大量的运维成本,开发人力成本等等,将主要精力放在业务开发。
如果非要问我hive和MaxCompute的性能对比,那我只能告诉它是经历双十一考验过的。
总结:如果说工业革命是将人们从体力劳动解放出来,那么如今的互联网革命,尤其是云计算大数据的飞速发展是将人们从脑力中解放出来。
“养码场”
现有技术人80000+
80%级别在P6及以上,含P9技术大咖30人
技术总监和CTO 500余人
更多精彩技术干货
以上是关于阿里云大数据利器MaxCompute学习之—假如你使用过hive的主要内容,如果未能解决你的问题,请参考以下文章
阿里云大数据MaxCompute计算资源分布以及LogView分析优化