手写迷你 SpringMVC 框架
Posted 编程技术圈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了手写迷你 SpringMVC 框架相关的知识,希望对你有一定的参考价值。
每天早上8点20分,第一时间与你相约
每日英文
No matter when you start, it is important that you do not stop after starting. No matter when you end, it is more important that you do not regret after ended.
不论你在什么时候开始,重要的是开始之后就不要轻言放弃;不论你在什么时候结束,重要的是结束之后就不要后悔。
每日掏心话
做人不要那么敏感,也不要那么心软,太敏感和太心软的人,肯定过得也不快乐,别人随便的一句话,你都要胡思乱想一整天。或许太重感情的人,日子终究不会好过,分分钟把你虐的万劫不复。
来自:炭烧生蚝 | 责编:乐乐
链接:cnblogs.com/tanshaoshenghao/p/11433999.html
图片来自网络
往日回顾:
00 前言
学习如何使用Spring,SpringMVC是很快的,但是在往后使用的过程中难免会想探究一下框架背后的原理是什么,本文将通过讲解如何手写一个简单版的springMVC框架,直接从代码上看框架中请求分发,控制反转和依赖注入是如何实现的。
https://github.com/liuyj24/mini-spring
01 项目搭建
项目搭建可以参考github中的项目,先选好jar包管理工具,Maven和Gradle都行,本项目使用的是Gradle。
然后在项目下建两个模块,一个是framework,用于编写框架;另外一个是test,用于应用并测试框架(注意test模块要依赖framework模块)。
接着在framework模块下按照spring创建好beans,core,context,web等模块对应的包,完成后便可以进入框架的编写了。
02 请求分发
在讲请求分发之前先来梳理一下整个web模型:
1、首先用户在客户端发送一个请求到服务器,经操作系统的TCP/IP栈解析后会交到在某个端口监听的web服务器。
2、web服务器程序监听到请求后便会把请求分发给对应的程序进行处理。比如Tomcat就会将请求分发给对应的java程序(servlet)进行处理,web服务器本身是不进行请求处理的。
本项目的web服务器选择Tomcat,而且为了能让项目直接跑起来,选择了在项目中内嵌Tomcat,这样框架在做测试的时候就能像spring boot一样一键启动,方便测试。
03 Servlet
既然选择了使用Java编写服务端程序,那就不得不提到Servlet接口了。为了规范服务器与Java程序之间的通信方式,Java官方制定了Servlet规范,服务端的Java应用程序必须实现该接口,把Java作为处理语言的服务器也必须要根据Servlet规范进行对接。
在还没有spring之前,人们是这么开发web程序的:一个业务逻辑对应一个Servlet,所以一个大项目中会有多个Servlet,这大量的Servlet会被配置到一个叫web.xml的配置文件中,当服务器运行的时候,tomcat会根据请求的uri到web.xml文件中寻找对应的Servlet业务类处理请求。
但是你想,每来一个请求就创建一个Servlet,而且一个Servlet实现类中我们通常只重写一个service方法,另外四个方法都只是给个空实现,这太浪费资源了。而且编起程序来创建很多Servlet还很难管理。能不能改进一下?
04 Spring的DispatcherServlet
方法确实有:
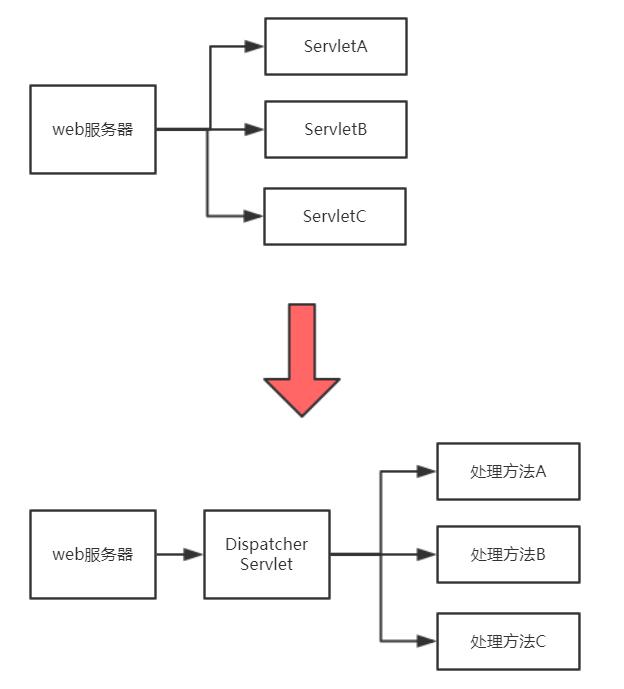
从上图可以看到,我们原来是经过web服务器把请求分发到不同的Servlet;我们可以换个思路,让web服务器把请求都发送到一个Servlet,再由这个Servlet把请求按照uri分发给不同的方法进行处理。
这样一来,不管收到什么请求,web服务器都会分发到同一个Servlet(DispatcherServlet),避免了多个Servlet所带来的问题,有以下好处:
1、把分发请求这一步从web服务器移动到框架内,这样更容易控制,也方便扩展。
2、可以把同一个业务的处理方法集中到同一个类里,把这种类起名为controller,一个controller中有多个处理方法,这样配置分散不杂乱。
3、配置uri映射路径的时候可以不使用配置文件,直接在处理方法上用注解配置即可,解决了配置集中,大而杂的问题。
05 实操
建议配合文章开头给出的源码进行参考
1、首先在web.mvc包中创建三个注解:Controller,RequestMapping,RequestParam,有了注解我们才能在框架启动时动态获得配置信息。
2、由于处理方法都是被注解的,要想解析被注解的类,首先得获得项目中相关的所有类,对应是源码中core包下的ClassScanner类
public class ClassScanner {public static List<Class<?>> scanClass(String packageName) throws IOException, ClassNotFoundException {//用于保存结果的容器List<Class<?>> classList = new ArrayList<>();//把文件名改为文件路径String path = packageName.replace(".", "/");//获取默认的类加载器ClassLoader classLoader = Thread.currentThread().getContextClassLoader();//通过文件路径获取该文件夹下所有资源的URLEnumeration<URL> resources = classLoader.getResources(path);int index = 0;//测试while(resources.hasMoreElements()){//拿到下一个资源URL resource = resources.nextElement();//先判断是否是jar包,因为默认.class文件会被打包为jar包if(resource.getProtocol().contains("jar")){//把URL强转为jar包链接JarURLConnection jarURLConnection = (JarURLConnection)resource.openConnection();//根据jar包获取jar包的路径名String jarFilePath = jarURLConnection.getJarFile().getName();//把jar包下所有的类添加的保存结果的容器中classList.addAll(getClassFromJar(jarFilePath, path));}else{//也有可能不是jar文件,先放下//todo}}return classList;}/*** 获取jar包中所有路径符合的类文件* @param jarFilePath* @param path* @return*/private static List<Class<?>> getClassFromJar(String jarFilePath, String path) throws IOException, ClassNotFoundException {List<Class<?>> classes = new ArrayList<>();//保存结果的集合JarFile jarFile = new JarFile(jarFilePath);//创建对应jar包的句柄Enumeration<JarEntry> jarEntries = jarFile.entries();//拿到jar包中所有的文件while(jarEntries.hasMoreElements()){JarEntry jarEntry = jarEntries.nextElement();//拿到一个文件String entryName = jarEntry.getName();//拿到文件名,大概是这样:com/shenghao/test/Test.classif (entryName.startsWith(path) && entryName.endsWith(".class")){//判断是否是类文件String classFullName = entryName.replace("/", ".").substring(0, entryName.length() - 6);classes.add(Class.forName(classFullName));}}return classes;}}
1、然后在handler包创建MappingHandler类,在将来框架运行的过程中,一个MappingHandler就对应一个业务逻辑,比如说增加一个用户。所以一个MappingHandler中要有“请求uri,处理方法,方法的参数,方法所处的类”这四个字段,其中请求uri用于匹配请求uri,后面三个参数用于运行时通过反射调用该处理方法
public class MappingHandler {private String uri;private Method method;private Class<?> controller;private String[] args;MappingHandler(String uri, Method method, Class<?> cls, String[] args){this.uri = uri;this.method = method;this.controller = cls;this.args = args;}public boolean handle(ServletRequest req, ServletResponse res) throws IllegalAccessException, InstantiationException, InvocationTargetException, IOException {//拿到请求的uriString requestUri = ((HttpServletRequest)req).getRequestURI();if(!uri.equals(requestUri)){//如果和自身uri不同就跳过return false;}Object[] parameters = new Object[args.length];for(int i = 0; i < args.length; i++){parameters[i] = req.getParameter(args[i]);}Object ctl = BeanFactory.getBean(controller);Object response = method.invoke(ctl, parameters);res.getWriter().println(response.toString());return true;}}
1、接下来在handler包创建HandlerManager类,这个类拥有一个静态的MappingHandler集合,这个类的作用是从获得的所有类中,找到被@controller注解的类,并将controller类中每个被@ReqeustMapping注解的方法封装成一个MappingHandler,然后把MappingHandler放入静态集合中
public class HandlerManager {public static List<MappingHandler> mappingHandlerList = new ArrayList<>();/*** 处理类文件集合,挑出MappingHandler* @param classList*/public static void resolveMappingHandler(List<Class<?>> classList){for(Class<?> cls : classList){if(cls.isAnnotationPresent(Controller.class)){//MappingHandler会在controller里面parseHandlerFromController(cls);//继续从controller中分离出一个个MappingHandler}}}private static void parseHandlerFromController(Class<?> cls) {//先获取该controller中所有的方法Method[] methods = cls.getDeclaredMethods();//从中挑选出被RequestMapping注解的方法进行封装for(Method method : methods){if(!method.isAnnotationPresent(RequestMapping.class)){continue;}String uri = method.getDeclaredAnnotation(RequestMapping.class).value();//拿到RequestMapping定义的uriList<String> paramNameList = new ArrayList<>();//保存方法参数的集合for(Parameter parameter : method.getParameters()){if(parameter.isAnnotationPresent(RequestParam.class)){//把有被RequestParam注解的参数添加入集合paramNameList.add(parameter.getDeclaredAnnotation(RequestParam.class).value());}}String[] params = paramNameList.toArray(new String[paramNameList.size()]);//把参数集合转为数组,用于反射MappingHandler mappingHandler = new MappingHandler(uri, method, cls, params);//反射生成MappingHandlermappingHandlerList.add(mappingHandler);//把mappingHandler装入集合中}}}
1、完成上面四步后,我们在框架启动的时候就获得了一个MappingHandler集合,当请求来到时,我们只要根据请求的uri从集合中找到对应的MappingHandler,就可以通过反射调用对应的处理方法,到此也就完成了框架请求分发的功能。
06 控制反转和依赖注入
完成了请求分发功能后,进一步想这么一个问题:
假设现在处理一个请求需要创建A,B,C三个对象,而
A 有个字段 D
B 有个字段 D
C 有个字段 B
如果按照顺序创建ABC的话,
首先要创建一个D,然后创建一个A;
接着先创建一个D,然后创建一个B;
接着先创建一个D,然后创建一个B,才能创建出一个C
总共创建了一个A,两个B,一个C,三个D。
上述是我们编写程序的一方创建对象的方式,可以看到由于对象不能被重复引用,导致创建了大量重复对象。
为了解决这个问题,spring提出了bean这么个概念,你可以把一个bean理解为一个对象,但是他对比普通的对象有如下特点:
1、不像普通对象一样朝生暮死,声明周期较长
2、在整个虚拟机内可见,不像普通对象只在某个代码块中可见
3、维护成本高,以单例形式存在
为了制作出上述的bean,我们得有个bean工厂,bean工厂的原理也很简单:在框架初始化的时候创建相关的bean(也可以在用到的时候创建),当需要使用bean的时候直接从工厂中拿。也就是我们把创建对象的权力交给框架,这就是控制反转
有了bean工厂后按顺序创建ABC的过程如下:
首先创建一个D,把D放入工厂,然后创建一个A,把A放入工厂;
接着从工厂拿出一个D,创建一个B,把B也放入工厂;
接着从工厂拿出一个B,创建一个C,把C也放入工厂;
总共创建了一个A,一个B,一个C,一个D
达到了对象重复利用的目的
至于创建出一个D,然后把D设置为A的一个字段这么个过程,叫做依赖注入
所以控制反转和依赖注入的概念其实很好理解,控制反转是一种思想,而依赖注入是控制反转的一种具体实现。
07 实操
1、首先在bean包下创建@Bean和@AutoWired两个注解,同样是用于框架解析类的。
2、接着在bean包下创建BeanFactory,BeanFactory要能提供一个根据类获取实例的功能,这就要求他要有一个静态的getBean()方法,和一个保存Bean的映射集合。
3、为了初始化Bean,要有一个根据类文件集合解析出bean的方法。该方法会遍历集合中所有的类,把有注解的,属于bean的类提取出来,创建该类的对象并放到静态集合中。
4、在这里有个有意思的点——按什么顺序创建bean?在本文给出的源码中,用了一个循环来创建bean,如果该bean没有依赖其他的bean就直接创建,如果有依赖其他bean就看其他bean有没被创建出来,如果没有就跳过当前的bean,如果有就创建当前的bean。
5、在循环创建bean的过程中可能出现一种bean之间相互依赖的现象,源码中暂时对这种现象抛出异常,没作处理。
public class BeanFactory {//保存Bean实例的映射集合private static Map<Class<?>, Object> classToBean = new ConcurrentHashMap<>();/*** 根据class类型获取bean* @param cls* @return*/public static Object getBean(Class<?> cls){return classToBean.get(cls);}/*** 初始化bean工厂* @param classList 需要一个.class文件集合* @throws Exception*/public static void initBean(List<Class<?>> classList) throws Exception {//先创建一个.class文件集合的副本List<Class<?>> toCreate = new ArrayList<>(classList);//循环创建bean实例while(toCreate.size() != 0){int remainSize = toCreate.size();//记录开始时集合大小,如果一轮结束后大小没有变证明有相互依赖for(int i = 0; i < toCreate.size(); i++){//遍历创建bean,如果失败就先跳过,等下一轮再创建if(finishCreate(toCreate.get(i))){toCreate.remove(i);}}if(toCreate.size() == remainSize){//有相互依赖的情况先抛出异常throw new Exception("cycle dependency!");}}}private static boolean finishCreate(Class<?> cls) throws IllegalAccessException, InstantiationException {//创建的bean实例仅包括Bean和Controller注释的类if(!cls.isAnnotationPresent(Bean.class) && !cls.isAnnotationPresent(Controller.class)){return true;}//先创建实例对象Object bean = cls.newInstance();//看看实例对象是否需要执行依赖注入,注入其他beanfor(Field field : cls.getDeclaredFields()){if(field.isAnnotationPresent(AutoWired.class)){Class<?> fieldType = field.getType();Object reliantBean = BeanFactory.getBean(fieldType);if(reliantBean == null){//如果要注入的bean还未被创建就先跳过return false;}field.setAccessible(true);field.set(bean, reliantBean);}}classToBean.put(cls, bean);return true;}}
1、有了bean工厂之后,凡是用到bean的地方都能直接通过bean工厂拿了
2、最后我们可以写一个小Demo测试一下自己的框架是否能正确地处理请求完成响应。相信整个迷你框架撸下来,Spring的核心功能,以及控制反转,依赖控制等名词在你脑海中不再只是概念,而是一行行清晰的代码了。
欢迎在留言区留下你的观点,一起讨论提高。如果今天的文章让你有新的启发,学习能力的提升上有新的认识,欢迎转发分享给更多人。
猜你还想看
关注「程序员小乐」,收看更多精彩内容
以上是关于手写迷你 SpringMVC 框架的主要内容,如果未能解决你的问题,请参考以下文章
ruby RubySteps 012 - Rails - 迷你框架片段