MyCat使用
Posted 码农DS
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MyCat使用相关的知识,希望对你有一定的参考价值。
1. 必读:
Mycat是不是配置以后,就能完全解决分表分库和读写分离问题?
Mycat配合数据库本身的复制功能,可以解决读写分离的问题,但是针对分表分库的问题,不是完美的解决。或者说,至今为止,业界没有完美的解决方案。
分表分库写入能完美解决,但是,不能完美解决主要是联表查询的问题,Mycat支持两个表联表的查询,多余两个表的查询不支持。 其实,很多数据库中间件关于分表分库后查询的问题,都是需要自己实现的,而且节本都不支持联表查询,Mycat已经算做地非常先进了。
分表分库的后联表查询问题,大家通过合理数据库设计来避免。
Mycat支持哪些数据库,其他平台如 .net、php能用吗?
官方说了,支持的数据库包括mysql、SQL Server、Oracle、DB2、PostgreSQL 等主流数据库,很赞。
尽量用Mysql,我试过SQL Server,会有些小问题,因为部分语法有点差异。
Mycat 非JAVA平台如 .net、PHP能用吗?
可以用。这一点MyCat做的也很棒。
如果在启动时发现异常,在logs目录中查看日志。
启动的时候会需要一段的时候,一定要去看日志
wrapper.log 为程序启动的日志,启动时的问题看这个mycat.log 为脚本执行时的日志,SQL脚本执行报错后的具体错误内容,查看这个文件。mycat.log是最新的错误日志,历史日志会根据时间生成目录保存。
mycat启动后,执行命令不成功,可能实际上配置有错误,导致后面的命令没有很好的执行。
2. 导读:
系统开发中,数据库是非常重要的一个点。除了程序的本身的优化,如:SQL语句优化、代码优化,数据库的处理本身优化也是非常重要的。主从、热备、分表分库等都是系统发展迟早会遇到的技术问题问题。
Mycat是一个广受好评的数据库中间件,已经在很多产品上进行使用了。
3. 了解mycat
3.1. 什么是mycat (http://www.mycat.io/)
一个彻底开源的,面向企业应用开发的大数据库集群
支持事务、ACID、可以替代MySQL的加强版数据库
一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
一个新颖的数据库中间件产品
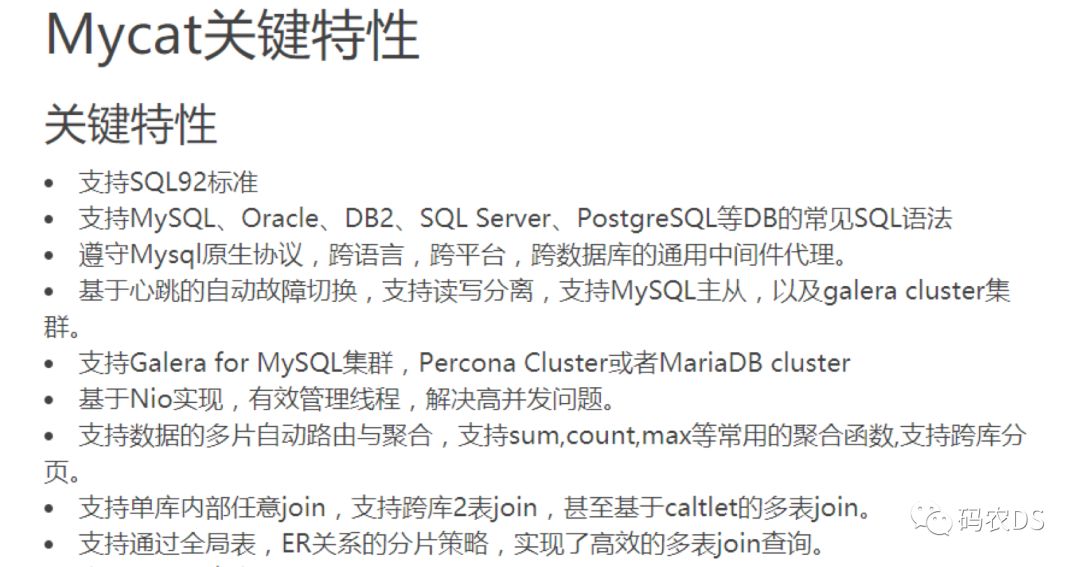
3.2 关键特征

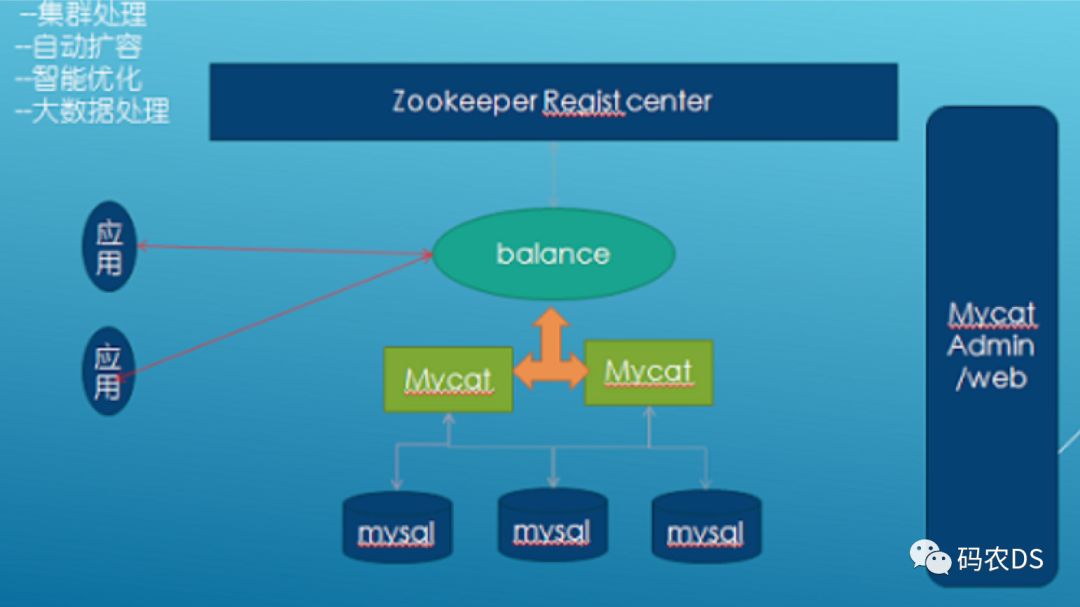
3.3 架构
4. Mycat下载
https://github.com/MyCATApache/Mycat-download/tree/master/1.6-RELEASE
5. MyCata安装
Mycat的安装很简单,只需要解压就可以了
5.1. 上传并解压
tar -zxvfMycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
5.2. 进入解压目录
5.3. 目录说明
目录 |
说明 |
bin |
mycat命令,启动、重启、停止等 |
catlet |
catlet为Mycat的一个扩展功能 |
conf |
Mycat 配置信息,重点关注 |
lib |
Mycat引用的jar包,Mycat是java开发的 |
logs |
日志文件,包括Mycat启动的日志和运行的日志。 |
5.4. 配置文件说明
Mycat的配置文件都在conf目录里面,这里介绍几个常用的文件:
文件 |
说明 |
server.xml |
Mycat的配置文件,设置账号、参数等 |
schema.xml |
Mycat对应的物理数据库和数据库表的配置 |
rule.xml |
Mycat分片(分库分表)规则 |
6. MyCat架构
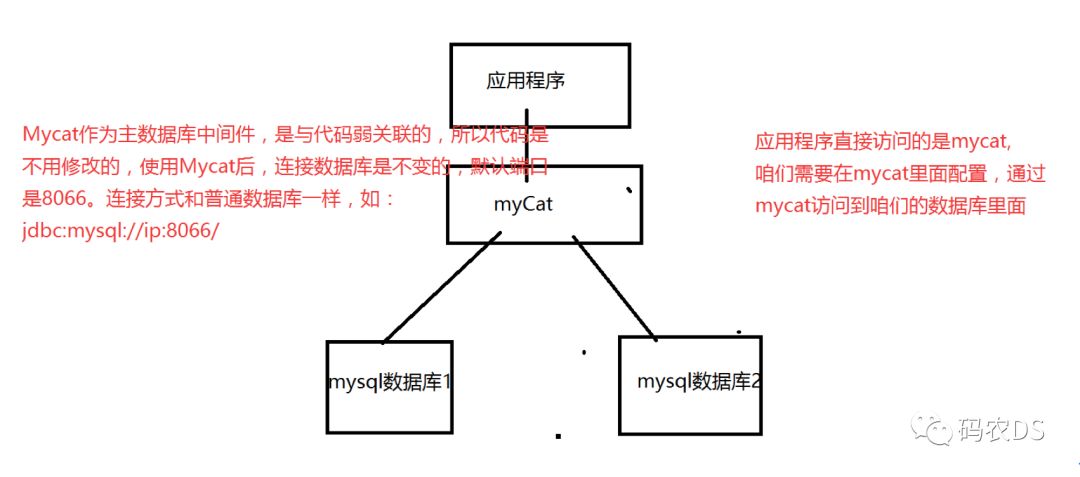
Mycat的架构其实很好理解,Mycat是代理,Mycat后面就是物理数据库。和Web服务器的nginx类似。对于使用者来说,访问的都是Mycat,不会接触到后端的数据库。
我们现在做一个主从、读写分离,简单分表的示例。结构如下图:
Mycat作为主数据库中间件,肯定是与代码弱关联的,所以代码是不用修改的,使用Mycat后,连接数据库是不变的,默认端口是8066。连接方式和普通数据库一样,如:jdbc:mysql://ip:8066/xx
7. 准备工作
服务器 |
IP |
说明 |
Mycat |
192.168.64.133 |
mycat服务器,连接数据库时,连接此服务器 |
database1 |
192.168.64.100 |
物理数据库1,真正存储数据的数据库 |
database2 |
192.168.209.81 |
物理数据库2,真正存储数据的数据库 |
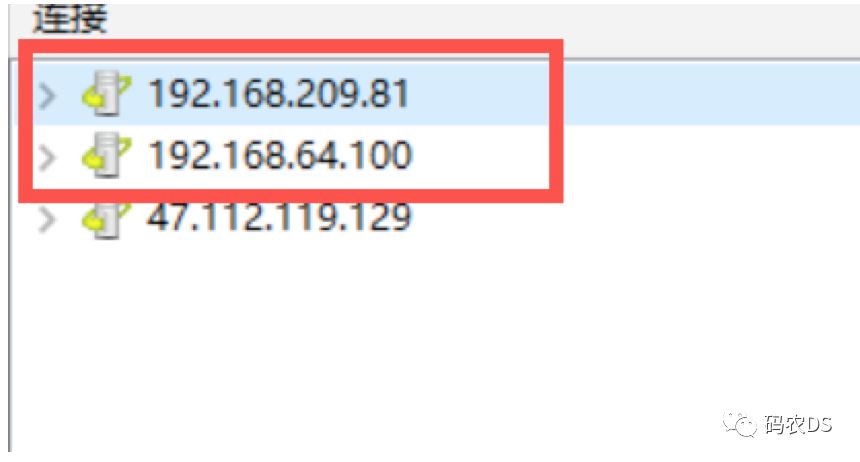
7.1. 数据库
7.2. 表
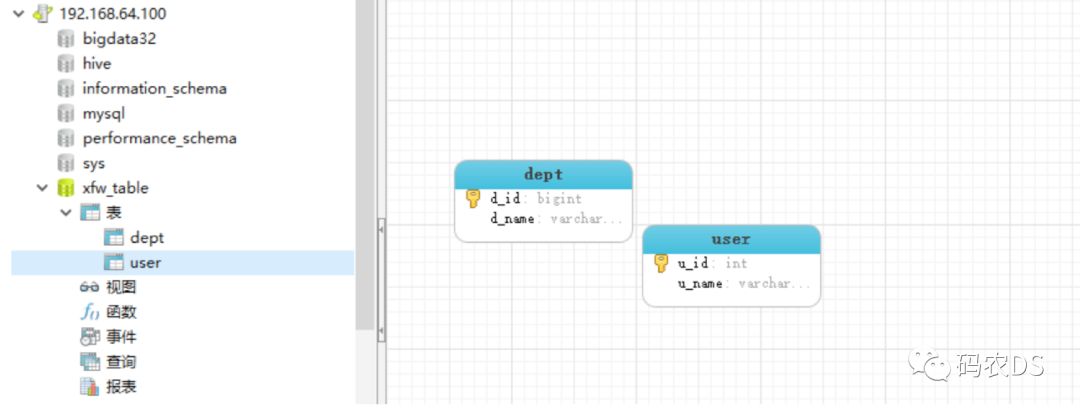
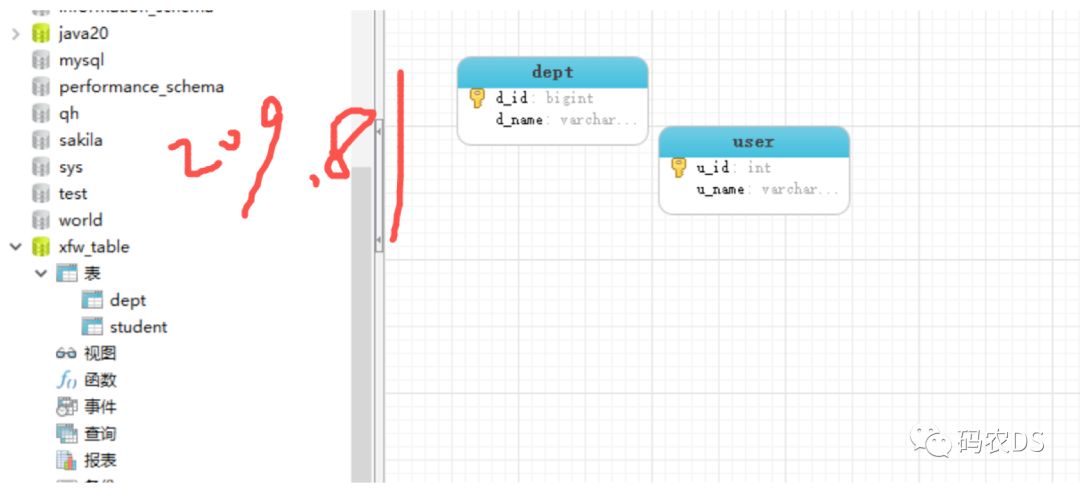
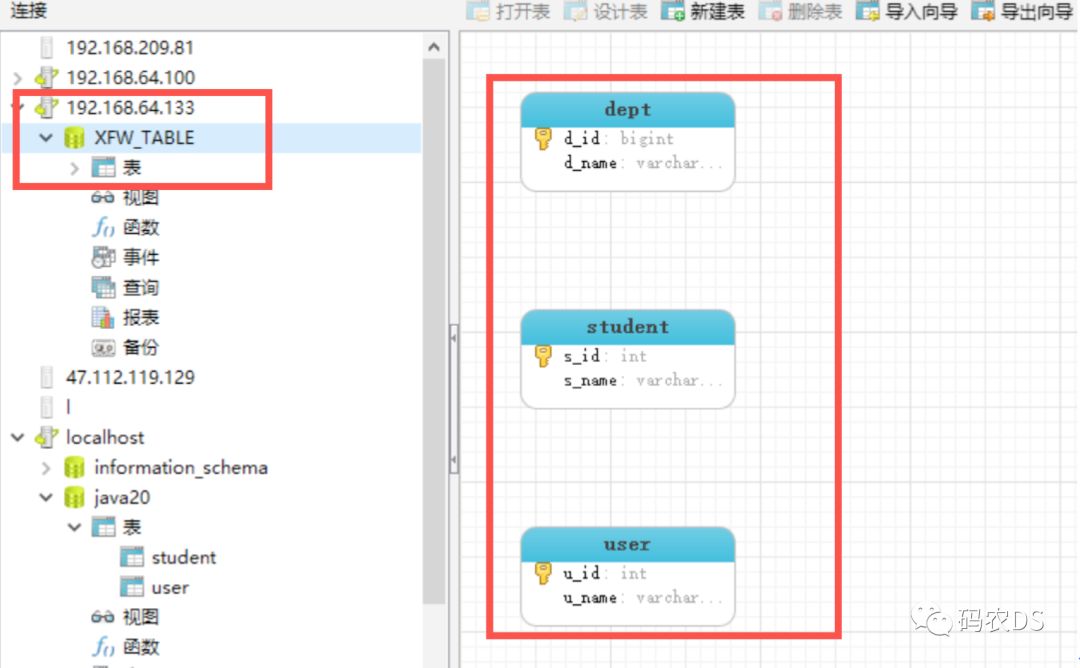
database1里面创建dept和user,
Database2里面创建dept和student
目的:分库分表来使用,dept是负载均衡的,两个数据库操作,user只操作数据库1,student只操作数据库2
dept的d_id用的是bigint类型,之后通过mycat自增的)
8. 配置文件说明
8.1. Server.xml
[root@ligong01conf]# vi server.xml
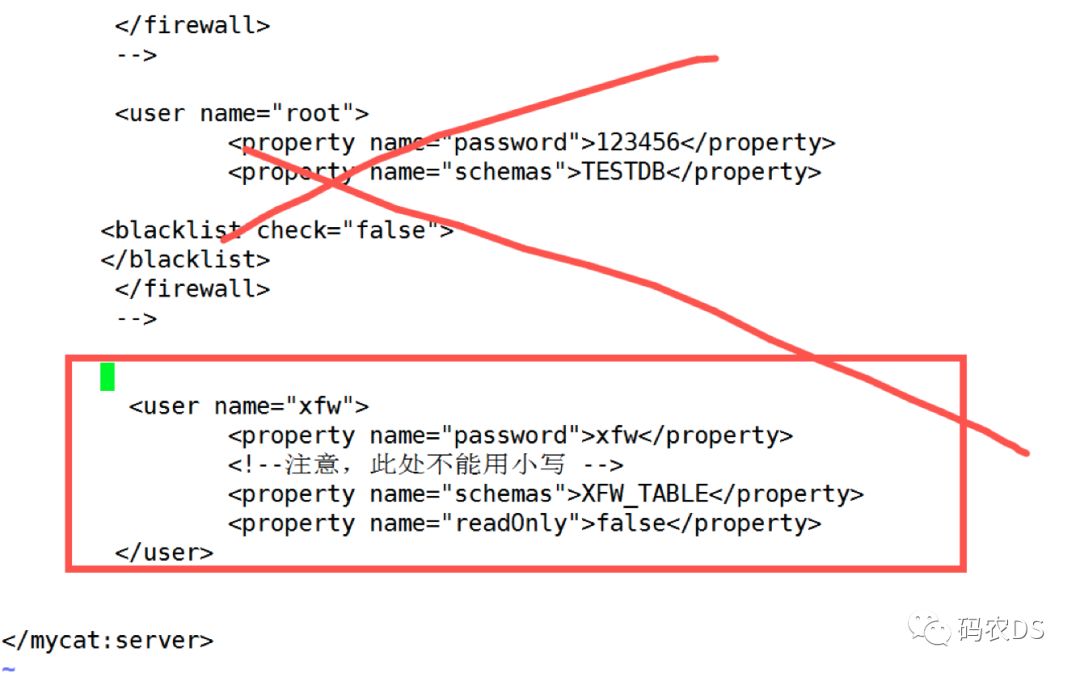
注意,把之前的删除掉
<username="xfw">
<propertyname="password">xfw</property>
<!-- 此处用大写的-->
<propertyname="schemas">XFW_TABLE</property>
<propertyname="readOnly">false</property>
</user>
参数 |
说明 |
user |
用户配置节点 |
--name |
登录的用户名,也就是连接Mycat的用户名 |
--password |
登录的密码,也就是连接Mycat的密码 |
--schemas |
数据库名,这里会和schema.xml中的配置关联,多个用逗号分开,例如需要这个用户需要管理两个数据库db1,db2,则配置db1,dbs |
--privileges |
配置用户针对表的增删改查的权限,具体见文档 |
说明:我设计的账号:xfw,密码xfw,数据库XFW_TABLE(这个与schema.xml文件中的name对应)
8.2. Schema.xml

8.2.1. 参数说明
参数 |
说明 |
schema |
数据库设置,此数据库为逻辑数据库,name与server.xml中schema对应 |
dataNode |
分片信息,也就是分库相关配置 |
dataHost |
物理数据库,真正存储数据的数据库 |
每个节点的属性逐一说明:
8.2.2. schema:
属性 |
说明 |
name |
逻辑数据库名,与server.xml中的schema对应 |
checkSQLschema |
数据库前缀相关设置,建议看文档,这里暂时设为false |
sqlMaxLimit |
select 时默认的limit,避免查询全表 |
8.2.3. table:
属性 |
说明 |
name |
表名,物理数据库中表名 |
dataNode |
表存储到哪些节点,多个节点用逗号分隔。节点为下文dataNode设置的name |
primaryKey |
主键字段名,自动生成主键时需要设置 |
autoIncrement |
是否自增 |
rule |
分片规则名,具体规则下文rule详细介绍 |
8.2.4. dataNode
属性 |
说明 |
name |
节点名,与table中dataNode对应 |
datahost |
物理数据库名,与datahost中name对应 |
database |
物理数据库中数据库名 |
8.2.5. dataHost
属性 |
说明 |
name |
物理数据库名,与dataNode中dataHost对应 |
balance |
均衡负载的方式 balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的writeHost 上。 balance="1",全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1 ->S1 , M2->S2,并且 M1 与 M2 互为主备),正常情况下, M2,S1,S2 都参与 select 语句的负载均衡。 balance="2",所有读操作都随机的在 writeHost、 readhost 上分发。 balance="3", 所有读请求随机的分发到 wiriterHost 对应的 readhost 执行,writerHost 不负担读压力,注意 balance=3 只在 1.4 及其以后版本有, 1.3 没有。
|
writeType |
写入方式 writeType="0", 所有写操作发送到配置的第一个 writeHost,第一个挂了切到还生存的第二个writeHost,重新启动后已切换后的为准,切换记录在配置文件中:dnindex.properties . writeType="1",所有写操作都随机的发送到配置的 writeHost。 writeType="2",没实现。 |
dbType |
数据库类型 |
heartbeat |
心跳检测语句,注意语句结尾的分号要加。 |
9. 应用场景-分库分表:
9.1. 配置hosts
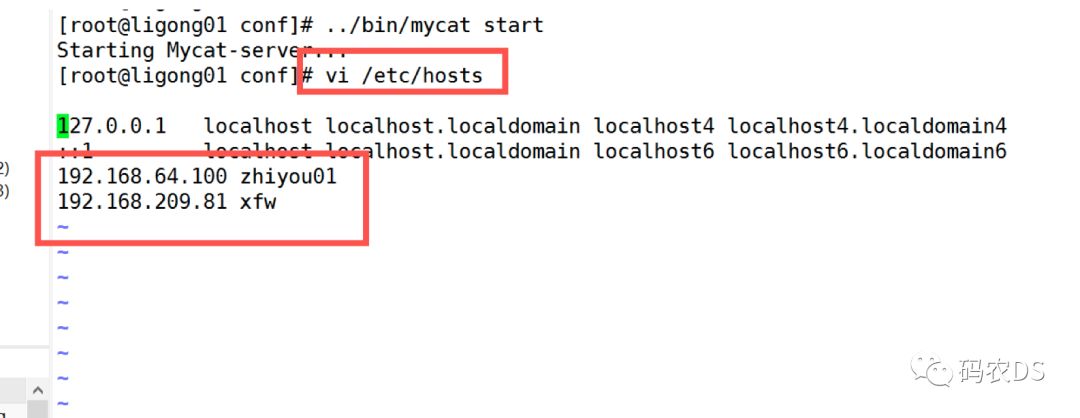
9.2. schema.xml (注意,把之前的删除掉;不然写起来麻烦,必须schema和schema在一起,datanode和datanode在一起)
注意:数据库的名字区别大小写
<?xmlversion="1.0"?>
<!DOCTYPE mycat:schema SYSTEM"schema.dtd">
<mycat:schemaxmlns:mycat="http://io.mycat/">
<!-- 数据库配置,与server.xml中的数据库对应 -->
<schema name="XFW_TABLE" checkSQLschema="false"sqlMaxLimit="100">
<table name="user"dataNode="dn1" />
<table name="student"dataNode="dn2" />
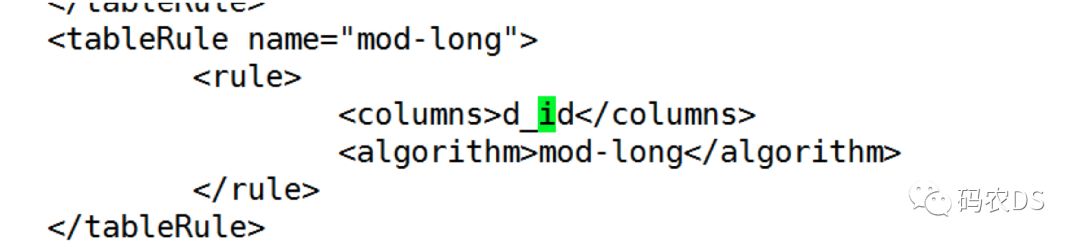
<table name="dept"primaryKey="d_id" autoIncrement="true"dataNode="dn1,dn2" rule="mod-long" />
</schema>
<!-- 分片配置 -->
<dataNode name="dn1"dataHost="test1" database="xfw_table" />
<dataNode name="dn2"dataHost="test2" database="xfw_table" />
<!-- 物理数据库配置 -->
<dataHost name="test1"maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql"dbDriver="native">
<heartbeat>selectuser();</heartbeat>
<writeHosthost="zhiyou01" url="192.168.64.100:3306" user="root"password="root">
</writeHost>
</dataHost>
<dataHost name="test2"maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql"dbDriver="native">
<heartbeat>selectuser();</heartbeat>
<writeHost host="xfw" url="192.168.209.81:3306"user="root" password="root">
</writeHost>
</dataHost>
</mycat:schema>
说明:
我在192.168.64.100、192.168.209.81均有数据库xfw_table。
user表只写入节点dn1,也就是192.168.64.100这个服务,
student表只写入节点dn2,也就是192.168.209.81这个服务,
而dept写入了dn1、dn2两个节点,也就是192.168.64.100、192.168.209.81这两台服务器。
分片的规则为:mod-long。
9.3. rule.xml
主要关注rule属性,rule属性的内容来源于rule.xml这个文件,Mycat支持10种分表分库的规则,基本能满足你所需要的要求,这个必须赞一个,其他数据库中间件好像都没有这么多。
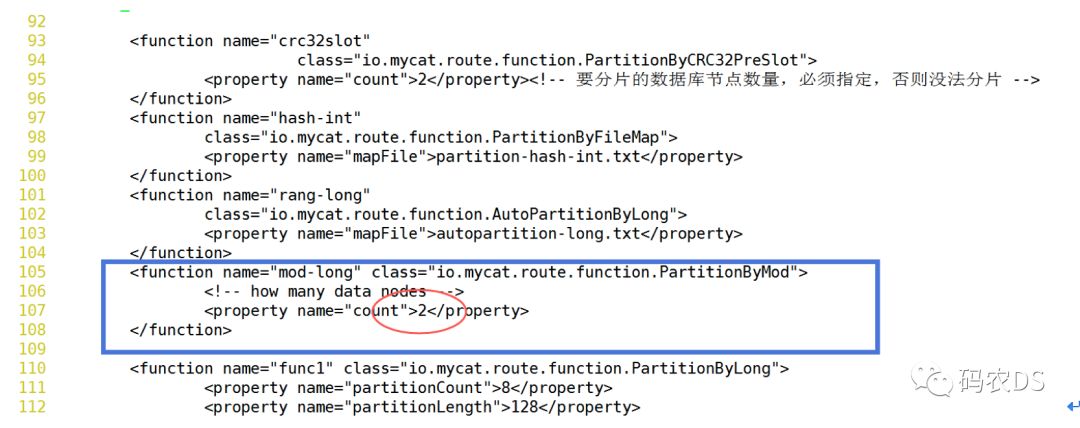
table中的rule属性对应的就是rule.xml文件中tableRule的name,具体有哪些分表和分库的实现,建议还是看下文档。我这里选择的mod-long就是将数据平均拆分。因为我后端是两台物理库,所以rule.xml中mod-long对应的function count为2,见下面部分代码:
9.4. 测试
9.4.1. 启动mycat

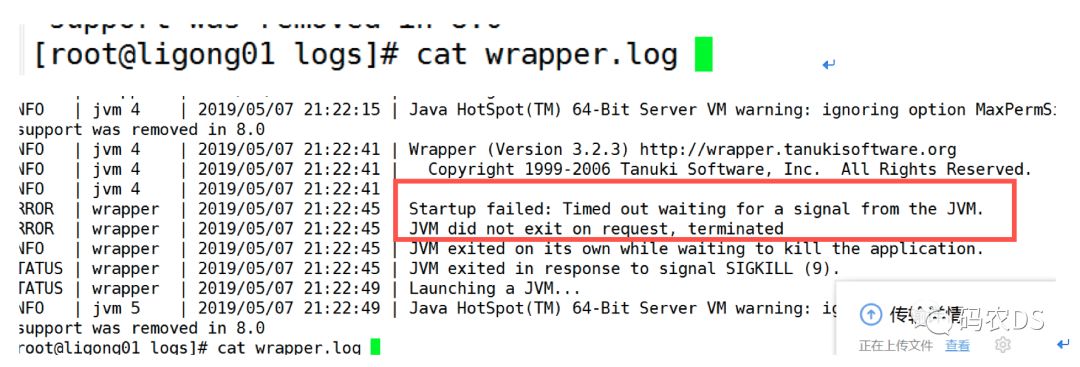
9.4.2. 查看启动日志:
原因
出现此消息的原因通常是您的cpu在大约30秒内达到100%。
(可能在索引过程中使用高CPU,或者高CPU可能由另一个应用程序如svn引起)。
解析度
尝试添加参数
wrapper.startup.timeout=300000
wrapper.ping.timeout=300000
到您的wrapper.conf文件,以增加超时时间,从而防止JVM被终止。设置此值后,您需要重新启动服务器。

9.4.3. 重启,查看日志
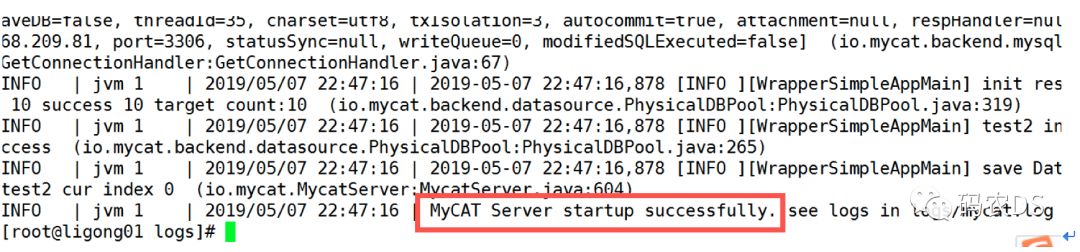
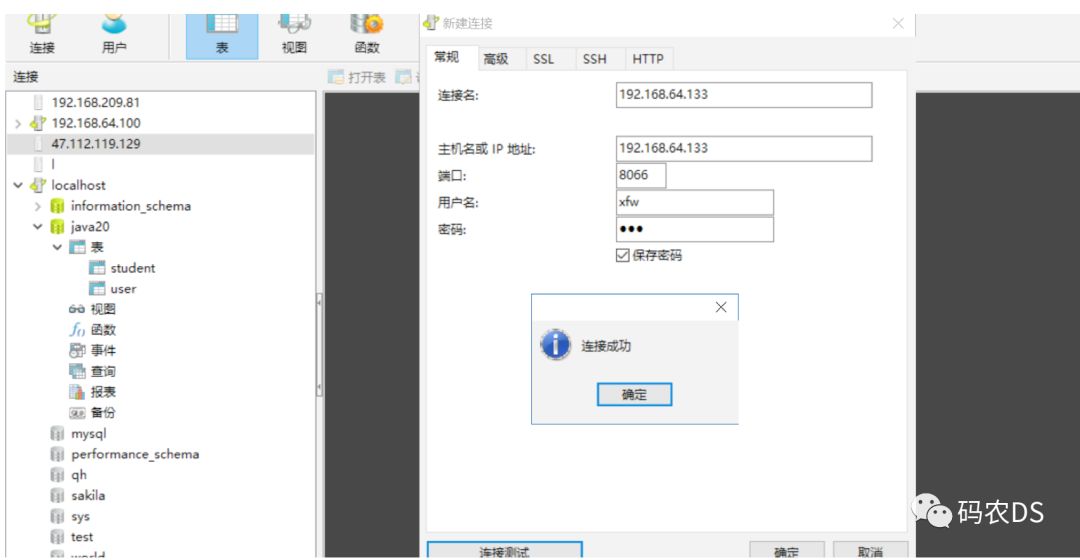
9.4.4. 通过navite连接到mycat(mycat里面是逻辑表)
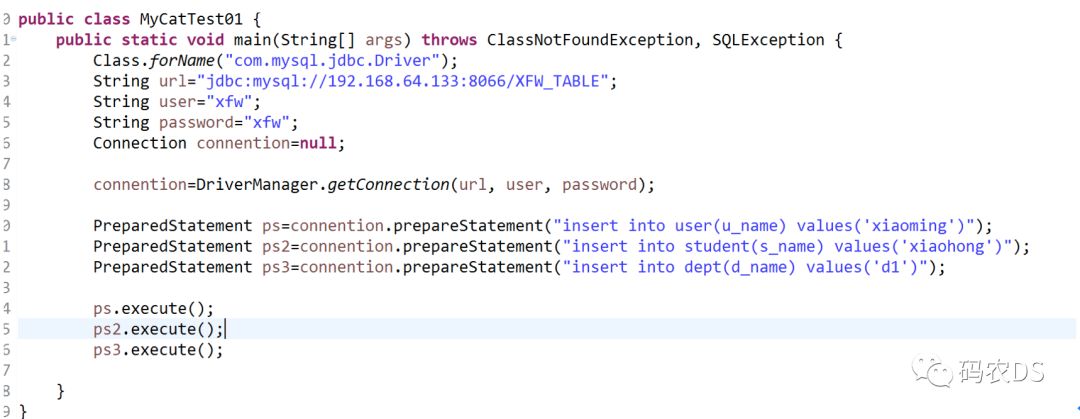
9.4.5. 写程序测试(和jave一样)(直接在工具里面操作mysql查询也一样)
9.4.6. 查看mycat (mycat里面都有)
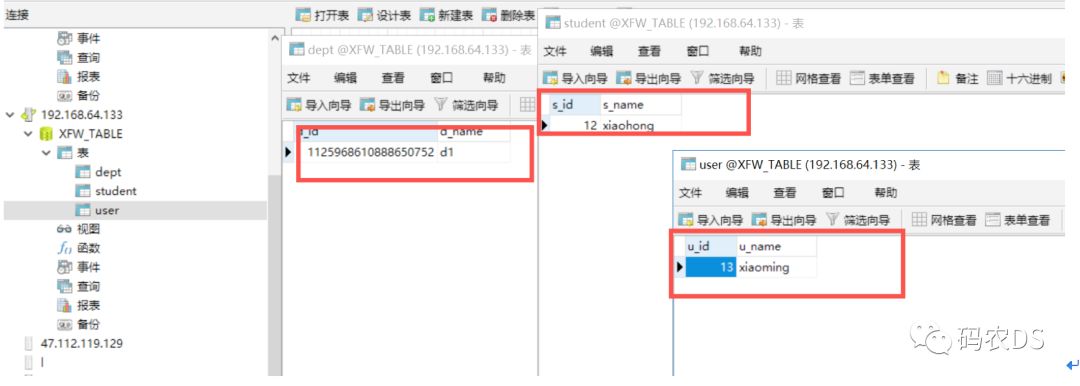
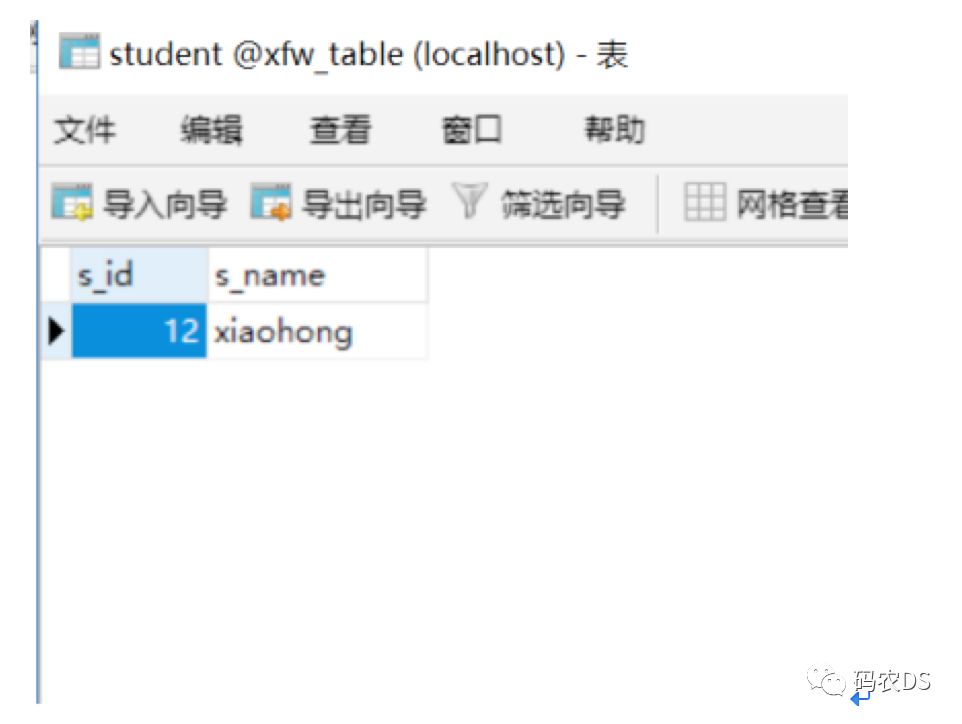
9.4.7. 查看192.168.64.100 ,user里面有数据
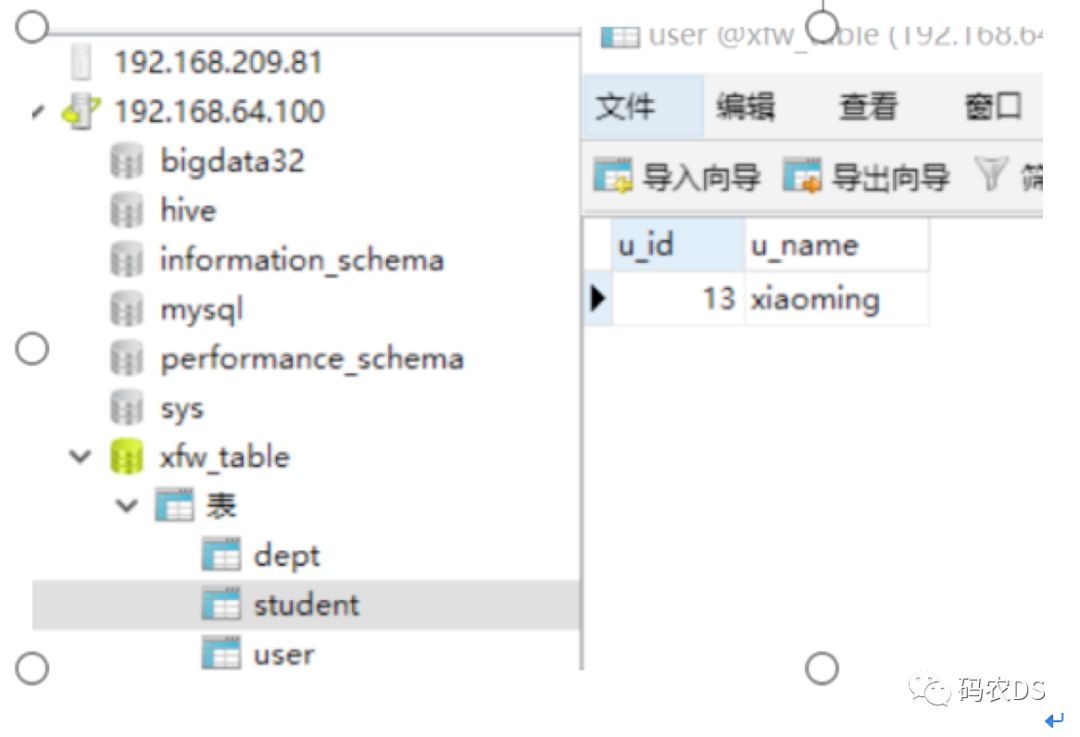
9.4.8. 查看192.168.209.81 ,student里面有数据
9.4.9. Dept是负载均衡了,那个快就到那个里面
10. 应用场景2-读写分离
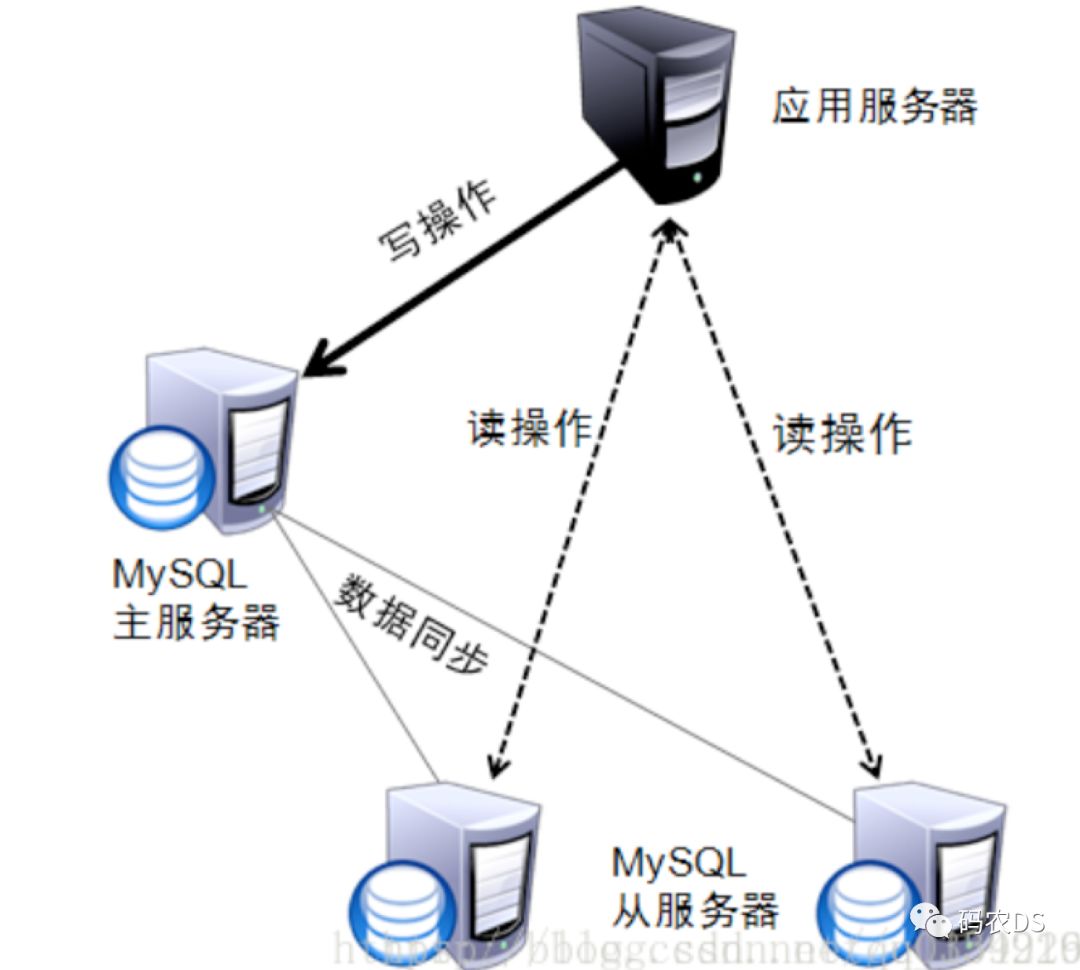
10.1. 原理
顾名思义,读写分离基本的原理是让主数据库处理事务性增、改、删操作,而从数据库处理查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
10.2. 实现方式
实现方式有很多,但是不外乎分为内部配置和使用中间件,下面列举几个
常用的方法:
1.配置多个数据源,根据业务需求访问不同的数据,指定对应的策略:增加,删除,修改操作访问对应数据,查询访问对应数据,不同数据库做好的数据一致性的处理。由于此方法相对易懂,简单,不做过多介绍。
2. 动态切换数据源,根据配置的文件,业务动态切换访问的数据库:此方案通过Spring的AOP,AspactJ来实现动态织入,通过编程继承实现Spring中的AbstractRoutingDataSource,来实现数据库访问的动态切换,不仅可以方便扩展,不影响现有程序,而且对于此功能的增删也比较容易。
3. 通过mycat来实现读写分离:使用mycat提供的读写分离功能,mycat连接多个数据库,数据源只需要连接mycat,对于开发人员而言他还是连接了一个数据库(实际是mysql的mycat中间件),而且也不需要根据不同业务来选择不同的库,这样就不会有多余的代码产生。
读写分离需要主从复制,此处使用mysql自带的复制;
10.3. 参考mysql主从复制文档-已经配好主从复制
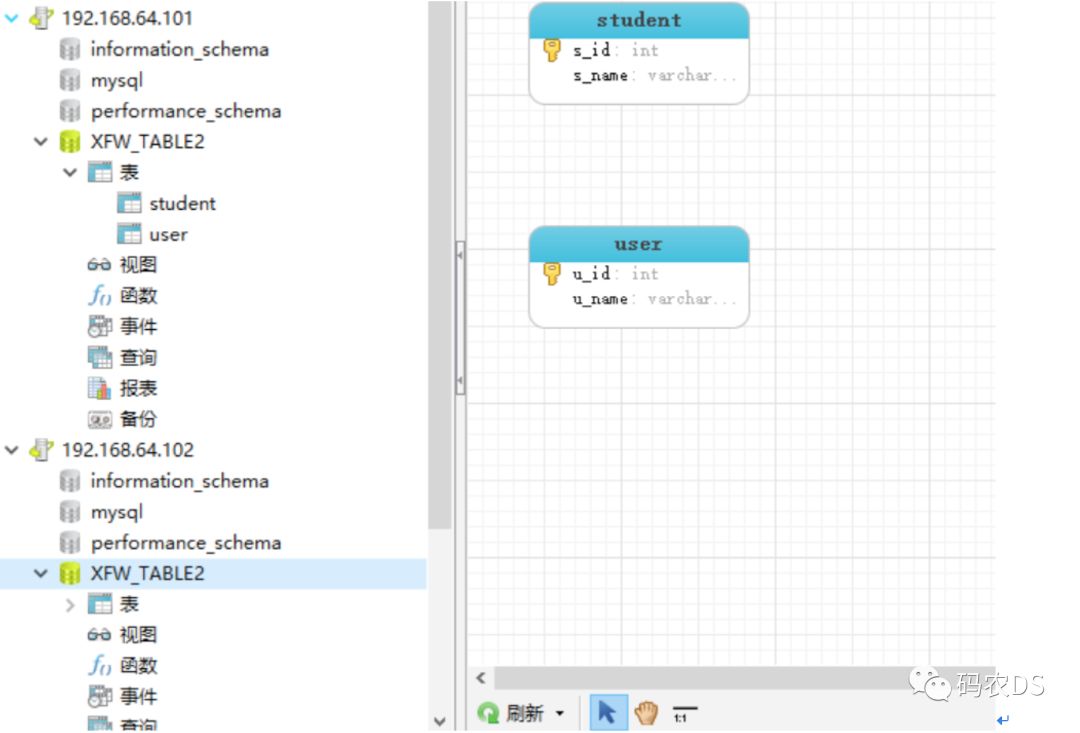
服务器 |
IP |
说明 |
Mycat |
192.168.64.133 |
mycat服务器,连接数据库时,连接此服务器 |
database1 |
192.168.64.101 |
物理数据库1,master |
database2 |
192.168.64.102 |
物理数据库2,slave |
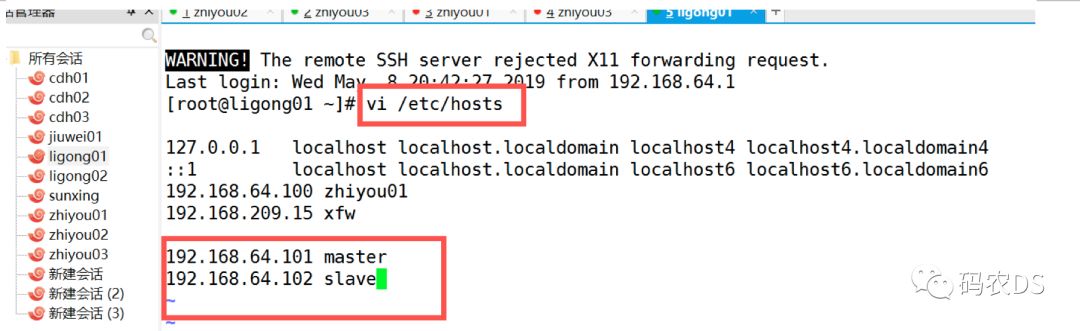
10.4. 配置hosts- Mycat服务器的
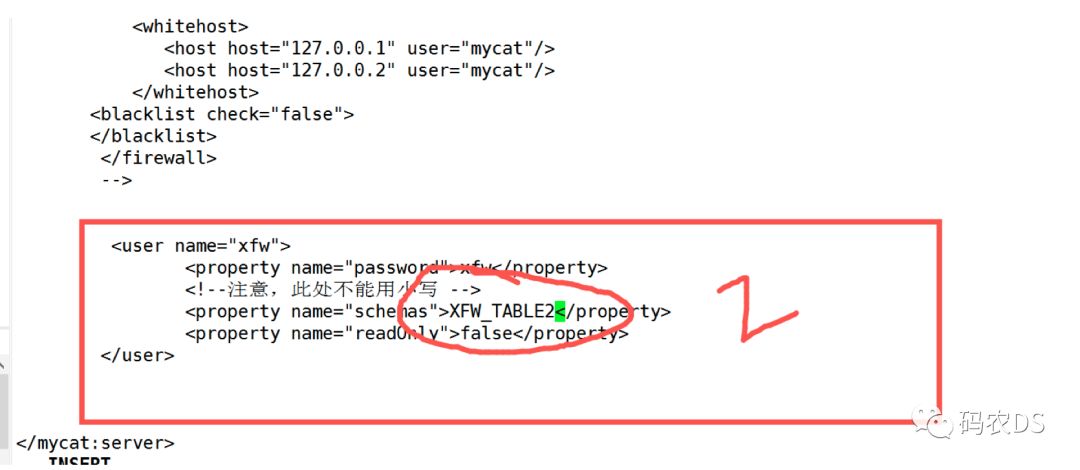
10.5. 配置server.xml
用的还是之前的(其他的都给注释掉)
10.6. 配置schema.xml
我是把之前的schema给替换了,又重新写了一个新的schema
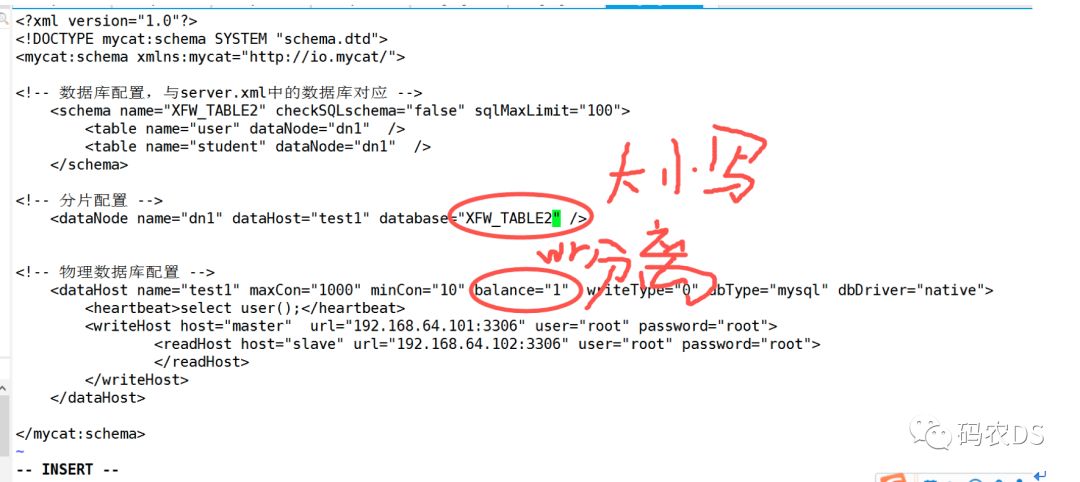
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 数据库配置,与server.xml中的数据库对应 -->
<schemaname="XFW_TABLE2" checkSQLschema="false"sqlMaxLimit="100">
<tablename="user" dataNode="dn1" />
<tablename="student" dataNode="dn1" />
</schema>
<!-- 分片配置 -->
<dataNodename="dn1" dataHost="test1" database="XFW_TABLE2"/>
<!-- 物理数据库配置 -->
<dataHostname="test1" maxCon="1000" minCon="10"balance="1" writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user();</heartbeat>
<writeHosthost="master" url="192.168.64.101:3306" user="root"password="root">
<readHost host="slave" url="192.168.64.102:3306"user="root" password="root">
</readHost>
</writeHost>
</dataHost>
</mycat:schema>
说明: 此处测试读写分离,没有用分库分表,所以dataNode只有一个,但是writehost总添加了readhost,balance改为1,表示读写分离。
在这个里面配置读写分离的,写入是的master,因为配置了主从复制,所以slave上面自动会有,读的时候直接从slave上面去读
10.7. 启动myCat
10.8. 查看日志-OK

10.9. 用navicat打开
10.10. 向表里面插入数据-myCat
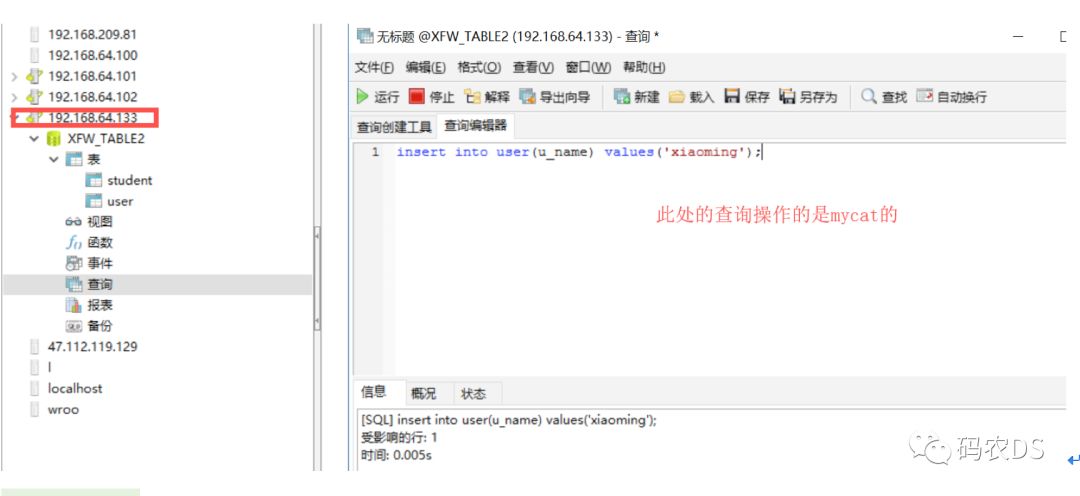
10.11. 查看mycat以及主从表
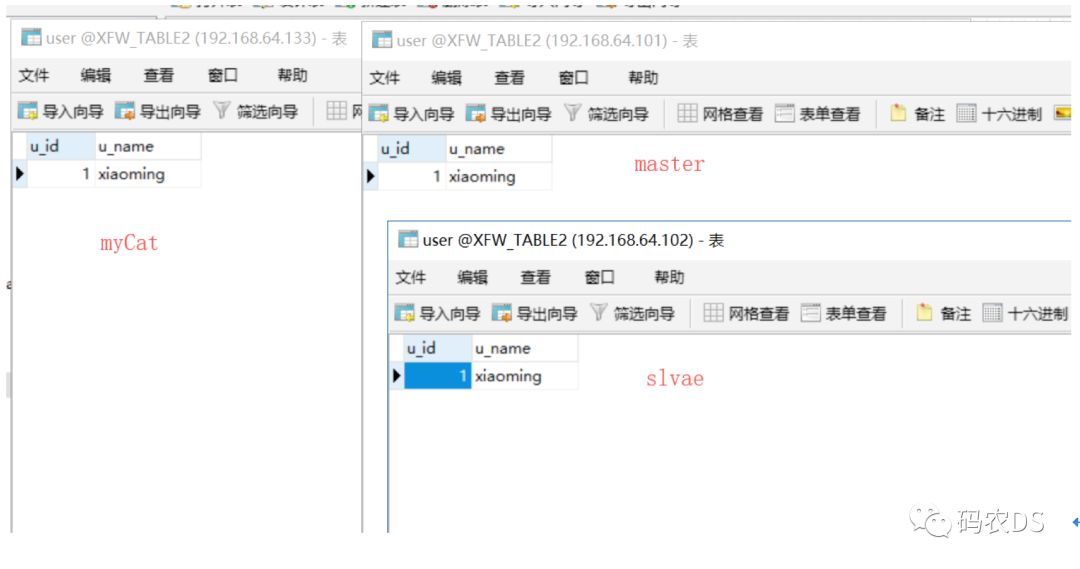
10.12. 修改slave里面的数据,然后从mycat里去查询
会发现查询的是从表里面的数据。
以上是关于MyCat使用的主要内容,如果未能解决你的问题,请参考以下文章