MyCat - 使用篇
Posted V青山绿水
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MyCat - 使用篇相关的知识,希望对你有一定的参考价值。
Mycat水平拆分之十种分片规则:
http://www.cnblogs.com/756623607-zhang/p/6656022.html
数据库路由中间件MyCat - 使用篇(5)
配置MyCat
4. 配置schema.xml
schema.xml里面管理着MyCat的逻辑库、表,每张表使用的分片规则、分布在哪个DataNode以及DataSource上。
之前的例子: 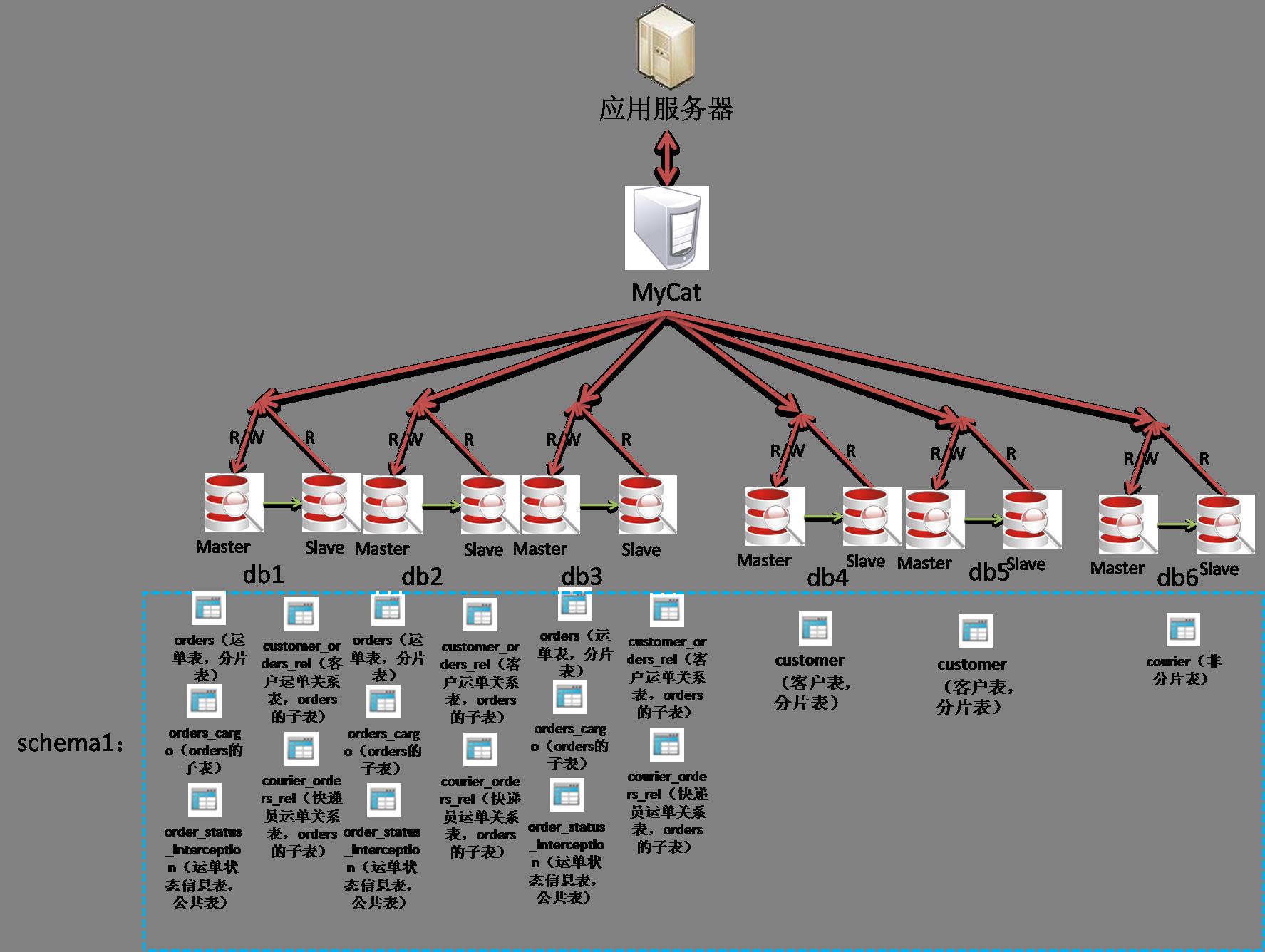
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://org.opencloudb/">
<!--schema就是逻辑库,相当于mysql实例的数据库,一个MySQL实例可以有多个数据库,同样的一个MyCat实例也可以有多个schema-->
<!-- checkSQLschema就是打开SQL语句检查,把带schema名字的查询改写成不带的,一般查询最好不要带schema名字 -->
<!--sqlMaxLimit每条执行的SQL语句,如果没有加上limit语句,MyCat也会自动的加上所对应的值-->
<schema name="schema1" checkSQLschema="false" sqlMaxLimit="10000" dataNode="test4">
<!-- 运单表,分片列在rule.xml配置,这里正好就是主键id,所以分片规则是主键id对3取模-->
<table name="orders" primaryKey="id" dataNode="test$1-3" rule="mod-long-orders">
<!-- 运单子母件表,运单表的子表,order_id与orders的id列对应 -->
<childTable name="orders_cargo" joinKey="order_id" parentKey="id">
</childTable>
<!-- 客户运单关系表,运单表的子表,order_id与orders的id列对应 -->
<childTable name="customer_order_rel" joinKey="order_id" parentKey="id">
</childTable>
<!-- 快递员运单关系表,运单表的子表,order_id与orders的id列对应 -->
<childTable name="courier_order_rel" joinKey="order_id" parentKey="id">
</childTable>
</table>
<!-- 运单状态信息表,公共表,放在和运单表同样的分片上 -->
<table name="order_status_interception" primaryKey="id" type="global" dataNode="test$1-3">
</table>
<!-- 快递员表,非分片表 -->
<table name="courier" primaryKey="id" dataNode="test4">
</table>
<!-- 客户表,对主键id对2取模 -->
<table name="customer" primaryKey="id" dataNode="test$5-6" rule="mod-long-customer">
</table>
</schema>
<!-- 规定dataNode,就是分片的位置-->
<dataNode name="test1" dataHost="test" database="db1" />
<dataNode name="test2" dataHost="test" database="db2" />
<dataNode name="test3" dataHost="test" database="db3" />
<dataNode name="test4" dataHost="test" database="db4" />
<dataNode name="test5" dataHost="test" database="db5" />
<dataNode name="test6" dataHost="test" database="db6" />
<!-- 规定每个分片host的读写服务器以及登录用户名密码,还有心跳语句-->
<dataHost name="test" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="-1" slaveThreshold="100">
<heartbeat>select 1 from dual</heartbeat>
<writeHost host="test" url="10.202.4.181:3306" user="test" password="test">
<readHost host="slave" url="10.202.4.181:3307" user="root" password="sf123456"/>
</writeHost>
</dataHost>
</mycat:schema>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
逻辑库配置schema标签:
<!--schema就是逻辑库,相当于MySQL实例的数据库,一个MySQL实例可以有多个数据库,同样的一个MyCat实例也可以有多个schema-->
<!-- checkSQLschema就是打开SQL语句检查,把带schema名字的查询改写成不带的,一般查询最好不要带schema名字 -->
<!--sqlMaxLimit每条执行的SQL语句,如果没有加上limit语句,MyCat也会自动的加上所对应的值-->
<schema name="schema1" checkSQLschema="false" sqlMaxLimit="10000" dataNode="test4">
</schema>- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
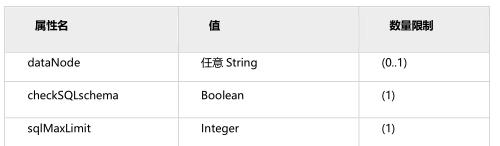
其中,这里配置的dataNode属性,是指这个逻辑库中逻辑表的默认分片节点是test4,如果逻辑表自己配置了分片节点,那么这个属性对那个逻辑表无效。
sqlMaxLimit防止过多的输出,如果sql语句中显式的指定了limit大小,那么这个属性就不会生效。而且,如果对于非分片表执行sql语句,这个属性也不会生效。
逻辑表配置table标签:
<!-- 运单表,分片列在rule.xml配置,这里正好就是主键id,所以分片规则是主键id对3取模-->
<table name="orders" primaryKey="id" dataNode="test$1-3" rule="mod-long-orders">
<!-- 运单子母件表,运单表的子表,order_id与orders的id列对应 -->
<childTable name="orders_cargo" joinKey="order_id" parentKey="id">
</childTable>
<!-- 客户运单关系表,运单表的子表,order_id与orders的id列对应 -->
<childTable name="customer_order_rel" joinKey="order_id" parentKey="id">
</childTable>
<!-- 快递员运单关系表,运单表的子表,order_id与orders的id列对应 -->
<childTable name="courier_order_rel" joinKey="order_id" parentKey="id">
</childTable>
</table>
<!-- 运单状态信息表,公共表,放在和运单表同样的分片上 -->
<table name="order_status_interception" primaryKey="id" type="global" dataNode="test$1-3">
</table>
<!-- 快递员表,非分片表 -->
<table name="courier" primaryKey="id" dataNode="test4">
</table>
<!-- 客户表,对主键id对2取模 -->
<table name="customer" primaryKey="id" dataNode="test$5-6" rule="mod-long-customer">
</table>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
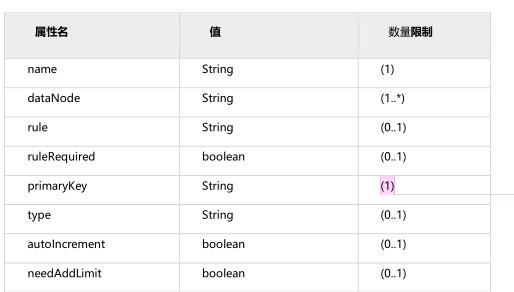
- name属性定义逻辑表的表名,这个名字就如同我在数据库中执行create table命令指定的名字一样,同个schema标签中定义的名字必须唯一。
- dataNode属性:定义这个逻辑表所属的dataNode, 该属性的值需要和dataNode标签中name属性的值相互对应。如果需要定义的dn过多可以使用上面配置的的方法减少配置
- rule属性:该属性用于指定逻辑表要使用的规则名字,规则名字在rule.xml中定义,必须与tableRule标签中name属性属性值一一对应。
- ruleRequired属性:该属性用于指定表是否绑定分片规则,如果配置为true,但没有配置具体rule的话 ,程序会报错。
- primaryKey属性:该逻辑表对应真实表的主键,例如:分片的规则是使用非主键进行分片的,那么在使用主键查询的时候,就会发送查询语句到所有配置的DN上;如果使用该属性配置真实表的主键,那么MyCat会缓存主键与具体DN的信息,那么再次使用非主键进行查询的时候就不会进行广播式的查询,就会直接发送语句给具体的DN,但是尽管配置该属性,如果缓存并没有命中的话,还是会发送语句给具体的DN,来获得数据。
- type属性:该属性定义了逻辑表的类型,目前逻辑表只有“全局表”和”普通表”两种类型。全局表:global。普通表:不指定该值为globla的所有表。
- autoIncrement属性:自增id相关,不推荐使用
- needAddLimit属性:指定表是否需要自动的在每个语句后面加上limit限制。由于使用了分库分表,数据量有时会特别巨大。这时候执行查询语句,如果恰巧又忘记了加上数量限制的话。那么查询所有的数据出来,也够等上一小会儿的。所以,mycat就自动的为我们加上LIMIT 100。当然,如果语句中有limit,就不会在次添加了。这个属性默认为true,你也可以设置成false`禁用掉默认行为。
分片表子表配置 childTable标签:
<table name="orders" primaryKey="id" dataNode="test$1-3" rule="mod-long-orders">
<!-- 运单子母件表,运单表的子表,order_id与orders的id列对应 -->
<childTable name="orders_cargo" joinKey="order_id" parentKey="id">
</childTable>
<!-- 客户运单关系表,运单表的子表,order_id与orders的id列对应 -->
<childTable name="customer_order_rel" joinKey="order_id" parentKey="id">
</childTable>
<!-- 快递员运单关系表,运单表的子表,order_id与orders的id列对应 -->
<childTable name="courier_order_rel" joinKey="order_id" parentKey="id">
</childTable>
</table>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
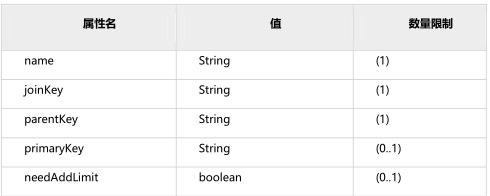
- name属性
- joinKey属性:插入子表的时候会使用这个列的值查找父表存储的数据节点。
- parentKey属性:属性指定的值一般为与父表建立关联关系的列名。程序首先获取joinkey的值,再通过parentKey属性指定的列名产生查询语句,通过执行该语句得到父表存储在哪个分片上。从而确定子表存储的位置。
- primaryKey属性:同table标签所描述的。
- needAddLimit属性:同table标签所描述的。
分片节点dataNode标签配置:
<!-- 规定dataNode,就是分片的位置-->
<dataNode name="test1" dataHost="test" database="db1" />
<dataNode name="test2" dataHost="test" database="db2" />
<dataNode name="test3" dataHost="test" database="db3" />
<dataNode name="test4" dataHost="test" database="db4" />
<dataNode name="test5" dataHost="test" database="db5" />
<dataNode name="test6" dataHost="test" database="db6" />- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
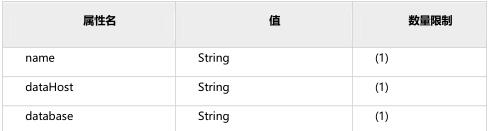
- name属性
- dataHost属性:该属性用于定义该分片属于哪个数据库实例的,属性值是引用dataHost标签上定义的name属性
- database属性:该属性用于定义该分片属性哪个具体数据库实例上的具体库,因为这里使用两个纬度来定义分片,就是:实例+具体的库。因为每个库上建立的表和表结构是一样的。所以这样做就可以轻松的对表进行水平拆分。
分片主机dataHost标签配置:
<!-- 规定每个分片host的读写服务器以及登录用户名密码,还有心跳语句-->
<dataHost name="test" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="-1" slaveThreshold="100">
<heartbeat>select 1 from dual</heartbeat>
<writeHost host="test" url="10.202.4.181:3306" user="test" password="test">
<readHost host="slave" url="10.202.4.181:3307" user="root" password="sf123456"/>
</writeHost>
</dataHost>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
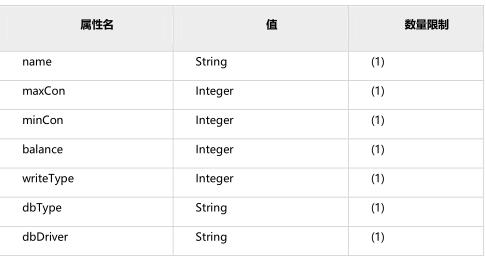
dataHost标签:该标签在mycat逻辑库中也是作为最底层的标签存在,直接定义了具体的数据库实例、读写分离配置和心跳语句。
- name属性
- maxCon属性:指定每个读写实例连接池的最大连接。也就是说,标签内嵌套的writeHost、readHost标签都会使用这个属性的值来实例化出连接池的最大连接数。
- minCon属性:指定每个读写实例连接池的最小连接,初始化连接池的大小。
- balance属性:
- balance=“0”, 所有读操作都发送到当前可用的writeHost上。
- balance=“1”,所有读操作都随机的发送到readHost。
- balance=“2”,所有读操作都随机的在writeHost、readhost上分发。 - writeType属性
- writeType=“0”, 所有写操作都发送到可用的writeHost上。
- writeType=“1”,所有写操作都随机的发送到readHost。
- writeType=“2”,所有写操作都随机的在writeHost、readhost分上发。 - dbType属性:指定后端连接的数据库类型,目前支持二进制的mysql协议,还有其他使用JDBC连接的数据库。例如:mongodb、oracle、spark等。
- dbDriver属性:指定连接后端数据库使用的Driver,目前可选的值有native和JDBC。使用native的话,因为这个值执行的是二进制的mysql协议,所以可以使用mysql和maridb。其他类型的数据库则需要使用JDBC驱动来支持。
- switchType属性:
-1 表示不自动切换
1 默认值,自动切换
2 基于 MySQL 主从同步状态决定是否切换,心跳语句必须为show slave status
3 基于 MySQL galary cluster 的切换机制(适合集群)心跳语句必须为show status like ‘wsrep%’ - slaveThreshold:主从同步状态决定是否切换,延迟超过这个就不切换
- heartbeat标签:这个标签内指明用于和后端数据库进行心跳检查的语句。例如,MYSQL可以使用select user(),Oracle可以使用select 1 from dual等。
- writeHost标签、readHost标签:这两个标签都指定后端数据库的相关配置给mycat,用于实例化后端连接池。唯一不同的是,writeHost指定写实例、readHost指定读实例,组着这些读写实例来满足系统的要求。在一个dataHost内可以定义多个writeHost和readHost。但是,如果writeHost指定的后端数据库宕机,那么这个writeHost绑定的所有readHost都将不可用。另一方面,由于这个writeHost宕机系统会自动的检测到,并切换到备用的writeHost上去。
- host属性:用于标识不同实例
- url属性:后端实例连接地址,如果是使用native的dbDriver,则一般为address:port这种形式。用JDBC或其他的dbDriver,则需要特殊指定。当使用JDBC时则可以这么写:jdbc:mysql://localhost:3306/。
- user属性:后端存储实例需要的用户名字
- password属性:后端存储实例需要的密码
5. 启动MyCat
以上,MyCat基本配置已经配置好。下面则启动,进入mycat的bin目录,启动MyCat:
./mycat start
查看启动状态:
./mycat status
停止:
./mycat stop
重启(改变上面的xml配置不用重启,管理端可以重新载入,以后会讲):
./mycat restart
查看logs/下的wrapper.log和mycat.log可以查看运行时问题和异常。
访问MyCat(这里为127.0.0.1:8066),可以看到: 
以上是关于MyCat - 使用篇的主要内容,如果未能解决你的问题,请参考以下文章