MYCAT的初恋
Posted 海鲨数据库架构师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MYCAT的初恋相关的知识,希望对你有一定的参考价值。
数据库中间件如今火爆全国,除了大名鼎鼎的MYCAT外,自然还有官方的mysql route ;360公司的Atlas;percona公司的 ProxySQL;平民科技的ONEPROXY;
在众多热门候选佳丽当中,我们选择使用最久和最广的MYCAT(我的猫)小姐姐来谈个恋爱!
从中文豪门闺秀迎娶她!http://www.mycat.io/
这是她的颜值,身高以及三维!
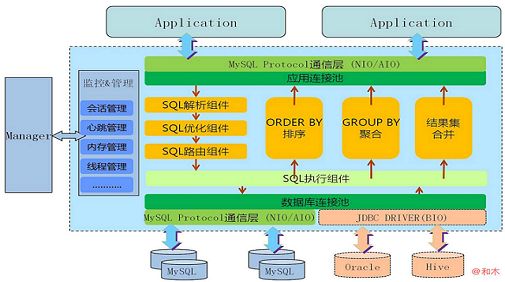
架构清晰,功能强大。
基于心跳的自动故障切换,支持读写分离,支持MySQL主从,
支持通过全局表,ER关系的分片策略,实现了高效的多表join查询。
支持MySQL、Oracle、DB2、SQL Server、PostgreSQL等DB的常见SQL语法
遵守Mysql原生协议,跨语言,跨平台,跨数据库的通用中间件代理。
支持全局序列号,解决分布式下的主键生成问题。
分片规则丰富,插件化开发,易于扩展。
关于她的琴棋书画等十八般武艺,小哥哥我就不太感兴趣了。
只对小姐姐的生儿育女,洗衣做饭,温柔孝顺,打工赚钱四大技艺感兴趣。

MYCAT 哪四大技艺呢?
1 分表分库
2 读写分离
3 自动FAIL OVER
4 性情稳定,配置简单易懂
她的性格简单介绍如下图
主要分逻辑库,逻辑表,逻辑数据节点,最后才是物理节点。
一个她可以玩多个逻辑库,每个逻辑库下面可以有多个逻辑表,
而逻辑表又可以多种方式存放在1-N个数据节点上。
最后1个数据节点只能关联1个物理节点。反之1个物理节点可以存放多个数据节点。哪怕1台物理MYSQL数据库上面可以存放100个数据节点。
逻辑表有四种类型
1 全局表,这样的表每个数据节点都冗余地存一份,而且数据是一样的。
2 分片表,该表根据某个字段和规则把数据分散存在1个或多个数据节点。
3 普通表:只保存1个数据节点上
4 组合表:比如父子表,子表要跟父表数据存放在一起,避免跨节点JOIN
配置文件有三个
1 SERVER.XML 定义用户和系统变量
2 SCHEMA.XML 定义逻辑库,逻辑表,逻辑数据节点,以及物理节点
3 RULE.XML 定义分片规则
SERVER.XML相对比较复杂些,先探讨她的SCHEMA.XML
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
定义逻辑库
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
TESTDB 定义个逻辑库,
checkSQLschema=true 时 SQL语句带有TESTDB.TABLE会被取消TESTDB
sqlMaxLimit 自动给没有使用LIMIT的SQL语句 SELETC * FROM TABLE LIMIT 100
如果 后面添加 dataNode="dn2"> 表示默认的表存放的节点。
那么下面 只要定义要分片的表就行了!只要定义分片表,全局表和组合表就行了。
定义逻辑表
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" ></table>
travelrecord 逻辑表存放在数据节点 dn1,dn2,dn3 使用自动分片规则。
其他属性
ruleRequired 该属性用于指定表是否绑定分片规则,如果配置为 true,但没有配置具体 rule 的话 ,程序会报错 |
| primaryKey 该逻辑表对应真实表的主键, |
| type:该属性定义了逻辑表的类型,目前逻辑表只有“全局表” 和” 普通表” 两种类型。全局表: global。普通表:不指定该值为 globla 的所有表 |
| autoIncrement:使用 autoIncrement=“true” 指定这个表有使用自增长主键 |
| subTables:定义分表的表明规则,使用方式添加 subTables="t_order$1-2,t_order3"。 |
| needAddLimit:指定表是否需要自动的在每个语句后面加上 limit 限制。 |
定义父子表
<table name="customer" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile">
<childTable name="orders" primaryKey="ID" joinKey="customer_id"
parentKey="id">
<childTable name="order_items" joinKey="order_id" parentKey="id" />
</childTable>
<childTable name="customer_addr" primaryKey="ID" joinKey="customer_id"
parentKey="id" />
</table>
这里定义了4张表的关系。customer 为爷爷表,下面有两个儿子,分别是orders和customer_addr,另外还有个孙子order_items。
joinKey 是关联字段 orders和父亲customer 关联字段customer_id。
parentKey 是指父表的主键字段。
primaryKey 本子表的主键。
needAddLimit 如上一样。
这里要注意嵌套层次结束标志符 parentKey="id" /> </childTable>
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
<table name="company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" />
<table name="goods" primaryKey="ID" type="global" dataNode="dn1,dn2" />
<!-- random sharding using mod sharind rule -->
<table name="hotnews" primaryKey="ID" autoIncrement="true" dataNode="dn1,dn2,dn3"
rule="mod-long" />
<table name="customer" primaryKey="ID" dataNode="dn1,dn2"
rule="sharding-by-intfile">
<childTable name="orders" primaryKey="ID" joinKey="customer_id"
parentKey="id">
<childTable name="order_items" joinKey="order_id"parentKey="id" />
</childTable>
<childTable name="customer_addr" primaryKey="ID" joinKey="customer_id"parentKey="id" />
</table>
</schema>
dataNode 标签(逻辑数据节点)
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataNode name="dn3" dataHost="localhost1" database="db3" />
name 属性:定义数据节点的名字,这个名字需要是唯一的。
dataHost 属性:该属性用于定义该分片属于哪个数据库实例的。
database 属性:该属性用于定义该分片属性哪个具体数据库实例上的具体库。
dataHost 标签(物理节点)
最底层的标签存在,直接定义了具体的数据库实例、读写分离配置和心跳语句。
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="localhost:3306" user="root"
password="123456">
<!-- can have multi read hosts -->
<readHost host="hostS2" url="192.168.1.200:3306" user="root" password="xxx" />
</writeHost>
<writeHost host="hostS1" url="localhost:3316" user="root"
password="123456" />
</dataHost>
定义个物理节点叫localhost1,最大连接数100,最小10。
balance 属性
负载均衡类型,目前的取值有 3 种:
1. balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上。
2. balance="1",全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1, M2->S2,并且 M1 与 M2 互为主备),正常情况下, M2,S1,S2 都参与 select 语句的负载均衡。
3. balance="2",所有读操作都随机的在 writeHost、 readhost 上分发。
4. balance="3",所有读请求随机的分发到 wiriterHost 对应的 readhost 执行, writerHost 不负担读压力,
注意 balance=3 只在 1.4 及其以后版本有, 1.3 没有。
在这里hostM1为主为写操作,hostS2为只读从库,hostS1为备用主库。
writeType 属性
写负载均衡类型,目前的取值有 2 种:
1. writeType="0", 所有写操作发送到配置的第一个 writeHost,第一个挂了切到还生存的第二个 writeHost,
重新启动后已切换后的为准,切换记录在配置文件中:dnindex.properties .
2. writeType="1",所有写操作都随机的发送到配置的 writeHost, 1.5 以后废弃不推荐。
switchType 属性
-1 表示不自动切换。
1 默认值,自动切换。
2 基于 MySQL 主从同步的状态决定是否切换。
3 基于 MySQL galary cluster 的切换机制(适合集群)(1.4.1)
心跳语句为 show status like ‘wsrep%
这里要看后台数据库的架构,
如果是ORACLE RAC 选择1;
如果 MYSQL MHA选择 2;
如果需要人工参与确定新主库,选择-1;
tempReadHostAvailable 属性
如果配置了这个属性 writeHost 下面的 readHost 仍旧可用,默认 0 可配置(0、 1) 。
slaveThreshold 属性
近似的主从延迟时间(秒)Seconds_Behind_Master < slaveThreshold ,读请求才会分发到该Slave,确保读到的数据相对较新。
heartbeat 标签
这个标签内指明用于和后端数据库进行心跳检查的语句。 例如,MYSQL 可以使用 select user(), Oracle 可以使用 select 1 from dual 等。
这个标签还有一个 connectionInitSql 属性,主要是当使用 Oracla 数据库时,需要执行的初始化 SQL 语句就这个放到这里面来。例如: alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss'
1.4 主从切换的语句必须是: show slave status
switchType 属性
-1 表示不自动切换
1 默认值,自动切换
2 基于 MySQL 主从同步的状态决定是否切换
心跳语句为 show slave status
3 基于 MySQL galary cluster 的切换机制(适合集群)(1.4.1)
心跳语句为 show status like ‘wsrep%
也就是说参考SWITCH TYPE属性设置。
writeHost 标签、 readHost 标签
weight 属性
权重 配置在 readhost 中作为读节点的权重(1.4 以后)。
usingDecrypt 属性
是否对密码加密默认 0 否 如需要开启配置 1,同时使用加密程序对密码加密,加密命令为:执行 mycat jar 程序(1.4.1 以后):
以上是关于MYCAT的初恋的主要内容,如果未能解决你的问题,请参考以下文章