腾讯云有话对你说:AI时代的大数据
Posted 永洪科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了腾讯云有话对你说:AI时代的大数据相关的知识,希望对你有一定的参考价值。
日前,以“唤醒科技·预见未来”为主题的永洪科技用户大会在北京隆重召开。来自数十个行业的影响力人物,以及近百位大数据领域的重磅大咖齐聚一堂。来自腾讯云的大数据产品首席架构师、数仓与数据湖产品负责人——堵俊平,受邀出席此次大会,并发表了题为《AI时代的大数据》的精彩演讲。
回顾精彩内容,领略大师风采
堵俊平
■ 腾讯云大数据产品首席架构师
■ 腾讯云数仓与数据湖产品负责人
■ 10余年云与大数据产品研发经验
■ 原Hortonworks美国YARN团队负责人
一
AI时代的大数据

大数据的发展阶段
温故,可以知新。在讨论AI时代大数据之前,让我们先回顾一下大数据的发展历史,在这个过程中通过总结回顾而预测一些新的变化与趋势。
大数据技术整个发展分为三个阶段:跟所有新生事物一样,它肯定是由一个起步阶段(孵化阶段),到发展阶段,最后走向成熟(再次进化)的阶段。
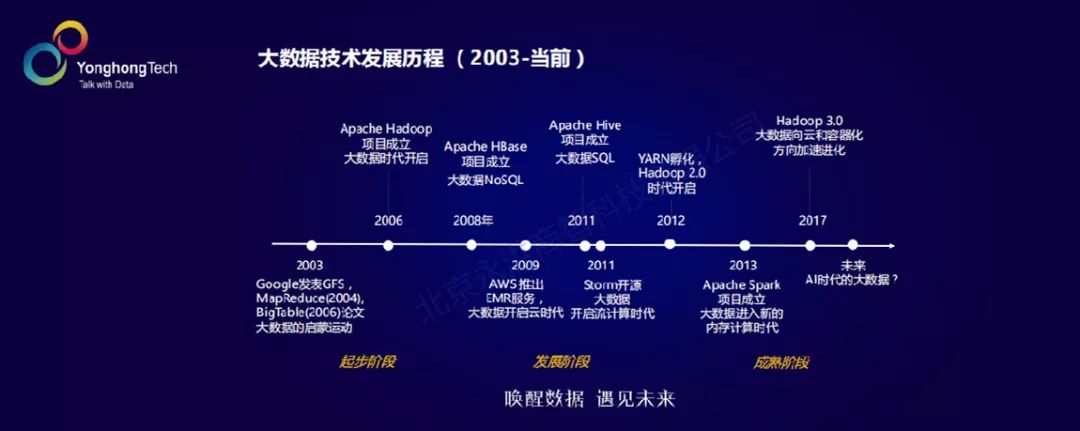
1.起步阶段
大数据的起步是在2003年左右,以Google的三篇大数据论文为标志,从号称“大数据的三驾马车”开始。一个解决分布式存储问题,一个解决分布式计算问题,还有一个解决的是分布式数据库访问的问题。在Google三篇论文之后,整个开源社区,在2006年hadoop就横空出世了,从而引领了整个大数据时代。
我们说大数据的前提,尤其是在新的互联网时代,一定要有海量的数据产生。在这个前提之下,我们对于数据处理的能力、数据分析的能力,有着与数据大规模增长相适应的需求,从而催生出新的技术。
2.发展阶段
自从有hadoop之后,以hadoop为核心构建的大数据开源生态系统也生机勃勃。后面像hbase,一个开源的NoSQL,加上后面出来的一些基于hadoop的SQL引擎,从而让整个大数据走向了数仓的时代。
再到后来,出现了storm,它是引领流计算的重要产品。包括大家知道Spark Streaming,都是一脉相承的发展。后面到Hadoop 2.0也就是YARN时代,计算执行引擎跟资源管理进行了剥离,从而诞生了统一的资源调度平台,调度不同大数据的应用,整个hadoop或者大数据的生态圈在往前继续的进化,也出现了像Spark这种大数据内存计算非常优秀的引擎,它的开源也进一步推动了大数据技术往前快速发展。
3.成熟阶段
近两年,大数据的重要发展是hadoop迈上了3.0的时代,开启了大数据拥抱容器化、与云整合的过程。关于未来,我们的看法是大数据跟AI会有更多样的融合,因为整体的技术趋势是往从数据到智能这个方向在发展的。
AI与大数据的关系
我们先来盘点一下大数据的技术生态圈和AI的技术生态圈,看看它们有哪些交集。
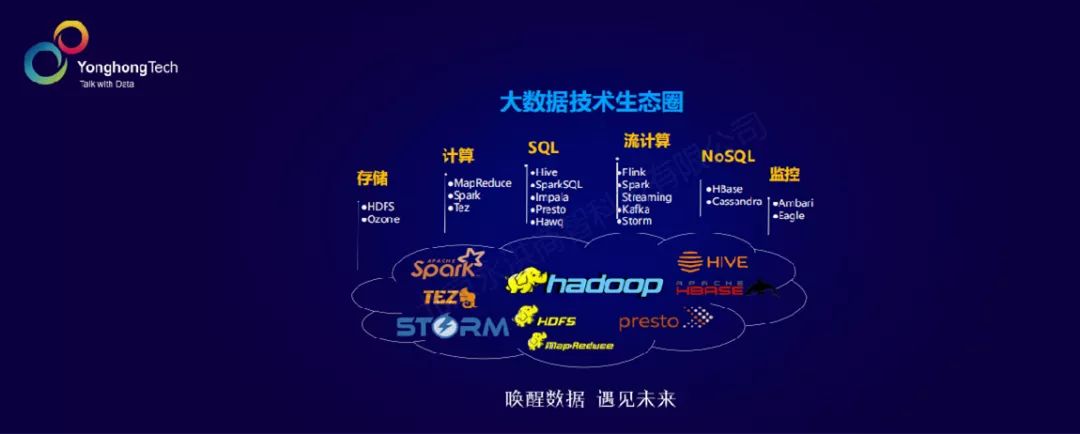

粗看下来,这还是蛮有意思的一个问题。在大数据的技术生态圈里,看不到太多AI的影子。大数据解决什么问题?数据的处理、数据分析、数据的计算等等相关的问题,在存储方面我们知道大数据里有新兴的数据湖存储,关于大数据分析,SQL引擎还是其他更多的选择,每种引擎都有自己的特点,这个是大数据的技术生态圈。在AI技术生态圈,则是另外一番景象。我们看得比较多的,不管是传统的H2O机器学习,还是TensorFlow, MxNet, PyTorch, Caffee等这些当红的深度学习的框架,看起来没有太多大数据的影子。
由此看来,大数据的生态圈和AI的技术生态圈是相互独立的,是没有太多关联依赖的两个技术生态圈。但实际上,这两个生态圈还是有融合趋势的。
那么,AI真的能够脱离大数据吗?

我觉得传统机器学习对数据处理规模的依赖相对还小一些,现在深度学习和超大规模的神经网络潮流来了之后,你会发现:
第一,不管你是受过模型的训练还是做模型的推理,都离不开大量的数据,数据是最重要的生产资料,脱离开数据,AI模型、算法都会成为无本之木、无源之水;
第二,你有强大的数据预处理平台,对AI模型本身的训练包括后面的推理都会有一个强大的促进作用,这张图展示了相对于传统的机器学习,深度学习对于预处理的要求会更高,数据预处理的能力越强,会加速整个深度学习的进度,包括模型的精准度,也会有一个提高;
第三,同时在技术层面上,两个社区也开始相互对接融合。深度学习方面有一些数据处理、数据交换的一些标准,还有工具在不断的产生,例如tf.data, tf.transform等;另外大数据这边也会更好地去支持AI框架,比如像Intel 开源的BigDL、腾讯开源的Angel、以及包括Databricks提出来的氢计划等,都是在大数据平台做深度学习,所以可以看到未来这两个社区或者两种技术在不断进行融合。
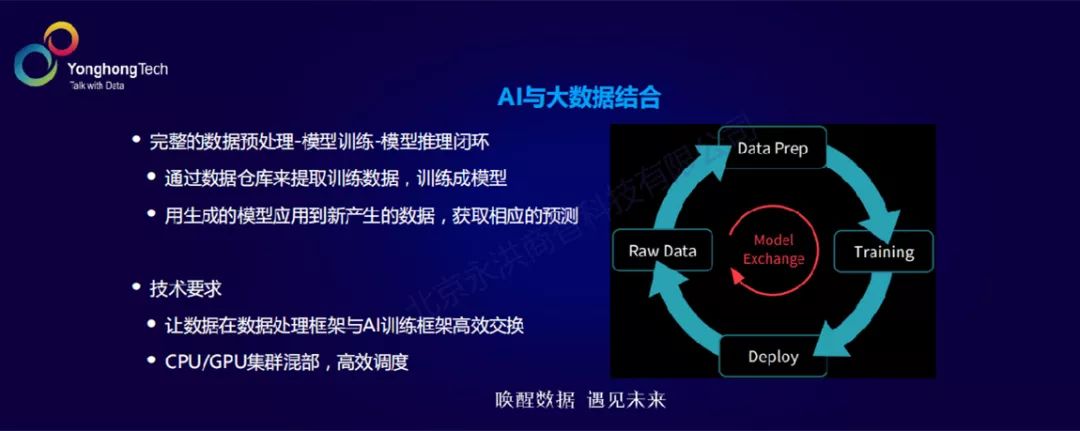
从整体来说,AI也好,大数据也好,会形成如图所示的闭环。AI机器学习的过程从一开始原始数据导入到进行数据预处理,再到模型的训练,再把训练好的模型应用到数据上做模型推导,整个过程形成一个闭环。这里面既有AI算法相应的参与,也有大数据平台能力的体现。这对现有技术提出了很多新的要求,比如当前的这些部署很多都是存在CPU计算集群,做大数据的预处理或者做后面模型的推导,而用GPU集群来做模型的训练。目前,这两个集群在很多情况下是分散处理的,在闭环里形成了一个割裂的状况。
我们认为,首先是能有一个统一的平台,在底层有调度的能力,能同时调度好AI模型训练、推理以及做数据预处理的任务。第二个是在应用层面上,大数据的这一套软件栈跟AI训练框架之间要有一个高效做数据与模型交换的机制和协议,这两块也是近期技术的热点和突破点。
总体而言,当前AI和大数据技术生态圈应该是互相共生、共同推进的状况。
二
大数据技术发展趋势
我们再回到大数据技术,看看还有哪些趋势。业界很重要的趋势,是从传统的数据仓库向数据湖的方向在演进。
数仓体系架构演进历史
1.传统的数仓体系
最早出现的是数据库一体机,是由单独的硬件软件所构成,这种数仓的问题也很明显,它需要一个专有的硬件设计,你只要用的不是通用的硬件,一般成本都会比较高。第二,它的扩展性非常差,在往前推十年、二十年是可以的,但是在这样的大数据时代,大家都不想随意地抛弃掉自己的数据和数据资产,所以一体机模式的数仓肯定要被这个时代淘汰掉。
2.分布式的数仓阶段
这个阶段也分两块,一块是从分库分表,从逻辑上把这个数据分成不同的模块,放在不同的数据库上面;另外一个方式,整个过程是通过MPP这个架构,通过一些独立的数据库组建出来MPP数据库,总体来说MPP数据库还是非常强大的。但是MPP有一个限制,它不能支持海量的数据,因为更多添加节点,尤其是当它的扩展规模超过100个节点以上的时候,会发现大的任务几乎无法执行,因为最慢的节点会拖累整个任务的执行。
3.云原生的数仓阶段
这些adhoc分析的任务在业务不断变化的情况下,包括经历波峰、波谷,对计算资源有不同的需求,这个时候云原生数仓就会越来越流行,因为它是一个多集群的,弹性可伸缩的,并且支持海量的高并发。这里说回传统的MPP数仓,还有个问题,就是SQL并发能力跟单机数据库是一样的,因为并发的所有SQL都要在每一台机器上去执行,无法突破单机数据库的并发限制。
基本上这就是数据仓库整个体系的发展过程。在技术流派方面,最早的一体机模式是共享存储的模式,后面的分库分表的模式是通过把数据库按照它的逻辑进行一些分布分表的操作,再到现在最流行的就是Share Nothing的架构。刚才也提到了,分成了MPP架构和以数据Shuffle为核心,以DAG任务为代表的SQL on Hadoop模式,现在最主流的就是MPP数据库和SQL on Hadoop这两种模式。
数据仓库虽然发展这么多年,但是也积累了一些问题,第一个问题就是……
“啊啊啊啊,然后呢?”
“被外星人劫走了吗?”
好看吗?捉急吗?想知道结尾吗?
……
未完待续
12月10日,周一见!

永洪科技
以上是关于腾讯云有话对你说:AI时代的大数据的主要内容,如果未能解决你的问题,请参考以下文章