NLP系列学习:CRF条件随机场
Posted 人工智能LeadAI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP系列学习:CRF条件随机场相关的知识,希望对你有一定的参考价值。
NVIDIA DLI 深度学习入门培训 | 特设三场!!
正文共1485个字,2张图,预计阅读时间5分钟。
大家好,今天让我们来看看条件随机场,条件随机场是一项大内容,在中文分词里广泛应用,因为我们在之前的文章里将概率图模型和基本的形式语言知识有所了解,当我们现在再去学习条件随机场会容易比较多(在动笔写这篇文章前我也翻阅了很多的博客,发现很多博主上来就讲一大堆核心公式,而之前的铺垫知识都很少提,我觉得这不太好,会让很多人一开始就懵)。
而我希望在我的这几篇文章尽可能的减少单纯理论知识的复述,而是通过一些实例,比如分词,一些实操,CRF+来去亲手实现算法.这样大家理解起来可能会更好.
条件随机场的文章大概有三篇:
第一篇:聊聊中文分词
第二篇:说说条件随机场的理论以及在中文分词的应用
第三篇:写写条件随机场的代码实现
而今天的这一篇将一起聊聊中文分词:
其实分词技术在国外已经是比较广泛应用了,但是在国内,因为中文的特殊性(英文由单个词语构成,而中文由单个字构成),再加上之前国内这一片研究相对落后(多为外国人),直至现在,建设一个好用的中文分词词库依旧是大家的追求.而中文分词也是自然语言处理领域的一个难点和热点,大家想想现在越来越多的人在互联网上发布信息,也在网上获取信息,海量的文本数据需要文本信息挖掘,而信息抽取,智能问答,文本倾向性分析都是由分词所作为基础而伸展开的.因此分词的效率和正确率都对以上工作有着很大的影响。
因此分词要处理的关键问题有两个:切分歧义消解和未登录词识别
而目前主要的分词方法有三种:
一种是基于词典的分词方法,这种方法又叫做机械分词方法,这种方法时间很长,他的工作思路是按照一定的策略将待分配的词和一个充分大的词典里边的词条进行匹配,就跟我们背诗句一样,自己脑子里有的会背,但是出题官出了一个没背过的,就懵了.因此这种基于词典的分词方法必须要需要一个高质量的词典来支撑,对于未登录的词语识别和歧义识别问题简直就是力不从心.但是速度快,效率高,易修改,灵活性强。
比如:”提高人民生活水平”
使用词典的方法会输出所有的可能性:
提 —提高
高 —高人
人 —人民
民 —民生
生—生活
活—活水
水 —水平
平
形成图模型后会是:
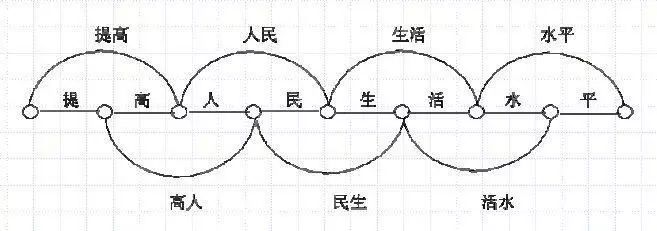
第二种是基于统计的分词方法,在使用了基于统计的方法之后,中文分词的效果得到了显著性的进步,比上一种强大了很多,并且这时候已经引入了机器学习的方法,使用已经分好的词作为一个训练语料,然后选择多种的模型去学习和解码,最后训练模型。
而这个时候,我们的文章的主角-条件随机场已经开始派上了用场,一种思路是建立条件随机场的标机模型,然后引入文字的概率特征和领域知识去分词,这样的分词准确率提高了,但是文字的概率特征太多并且多为自定义,因此这样建立的模型不仅复杂而且庞大。
并且是使用统计的方法,极大程度上依赖于你选择语料库的好坏,就跟我们学习机器学习模型一样,如果你的训练集的代表性不够明显,这样你训练出来的模型是比较容易过拟合的.如果你的训练语料要求高了,一方面你的计算量大,因此导致效率低,另外一方面高质量的语料必然离不开人工的筛选,对人力也是一个考验。
第三种是基于统计和词典相结合的方法,这也是我们现在比较常用的一种方法,比如我们现在比较流行的结巴分词,他主要就是根据HMM隐马尔可夫模型,再配合自定义词典去使用,并且你的词典可以作为一个内部的训练语料,但是这样的一个缺陷就是对于不同的领域的分词适应性并不好,需要重新训练模型,这也是我们看结巴分词在一些专门领域的效果并不好。
原文链接:https://www.jianshu.com/p/b62cb8a256f2
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
大家都在看
以上是关于NLP系列学习:CRF条件随机场的主要内容,如果未能解决你的问题,请参考以下文章
NLP --- 条件随机场CRF详解 重点 特征函数 转移矩阵