专访MSRA周明团队,NLP铁军“超越人类”技术揭秘
Posted 新智元
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了专访MSRA周明团队,NLP铁军“超越人类”技术揭秘相关的知识,希望对你有一定的参考价值。
新智元原创
【新智元导读】2018年1月3日,微软亚洲研究院的r-net率先在SQuAD EM值达到82.650,这意味着在ExactMatch (精准匹配)指标上首次超越人类在2016年创下的82.304。新智元第一时间采访了MSRA周明团队,为读者详细解析了何为EM、F1,超越人类的具体内涵,NLP最难突破的核心问题以及我国自然语言处理技术发展现状和未来展望等众多话题。

2018年1月3日,微软亚洲研究院的r-net率先在SQuAD machine reading comprehension challenge 上达到82.650,这意味着在ExactMatch (精准匹配)指标上首次超越人类在2016年创下的82.304。
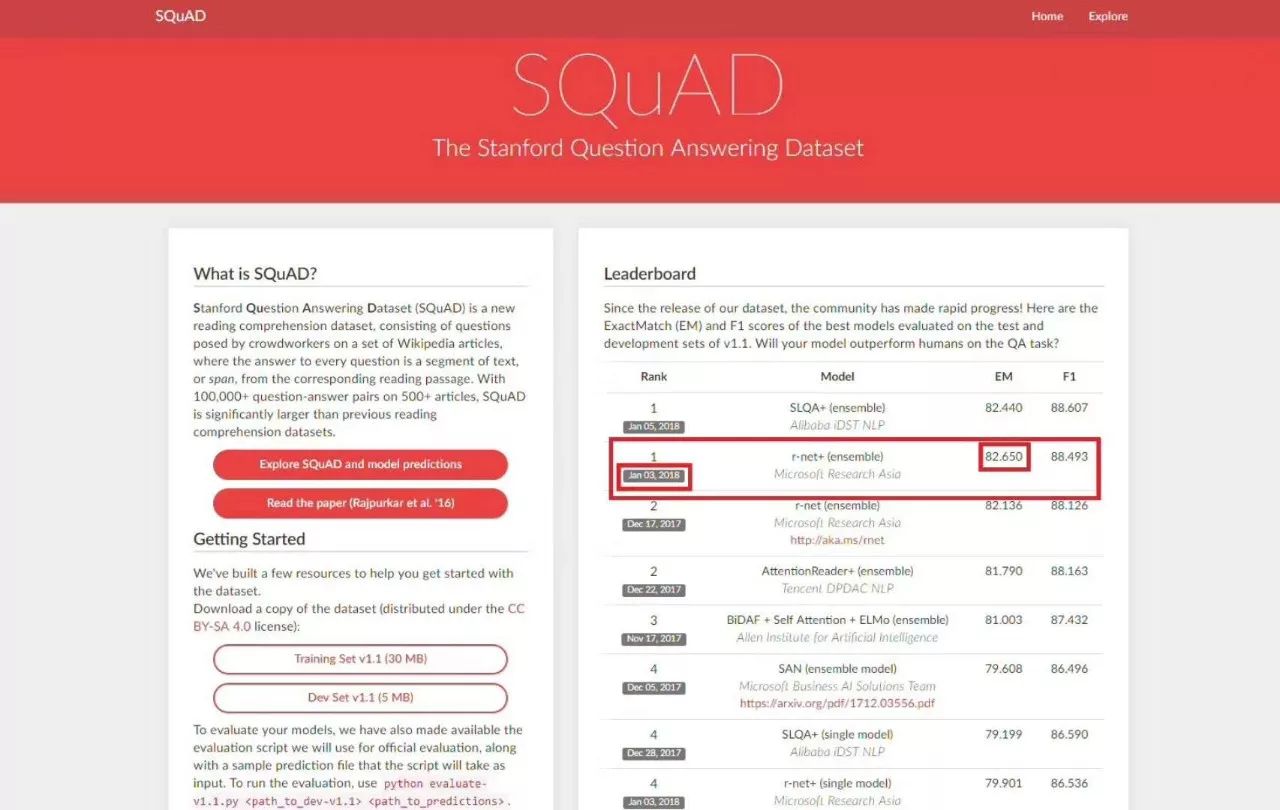
值得注意的是,其中阿里巴巴数据科学与技术研究院IDST在1月5日提交的结果EM分数为82.44,虽比微软亚洲研究院r-net略低,但也同样超越了人类分数。腾讯NLP团队之前提交的模型紧随其后,可喜可贺。
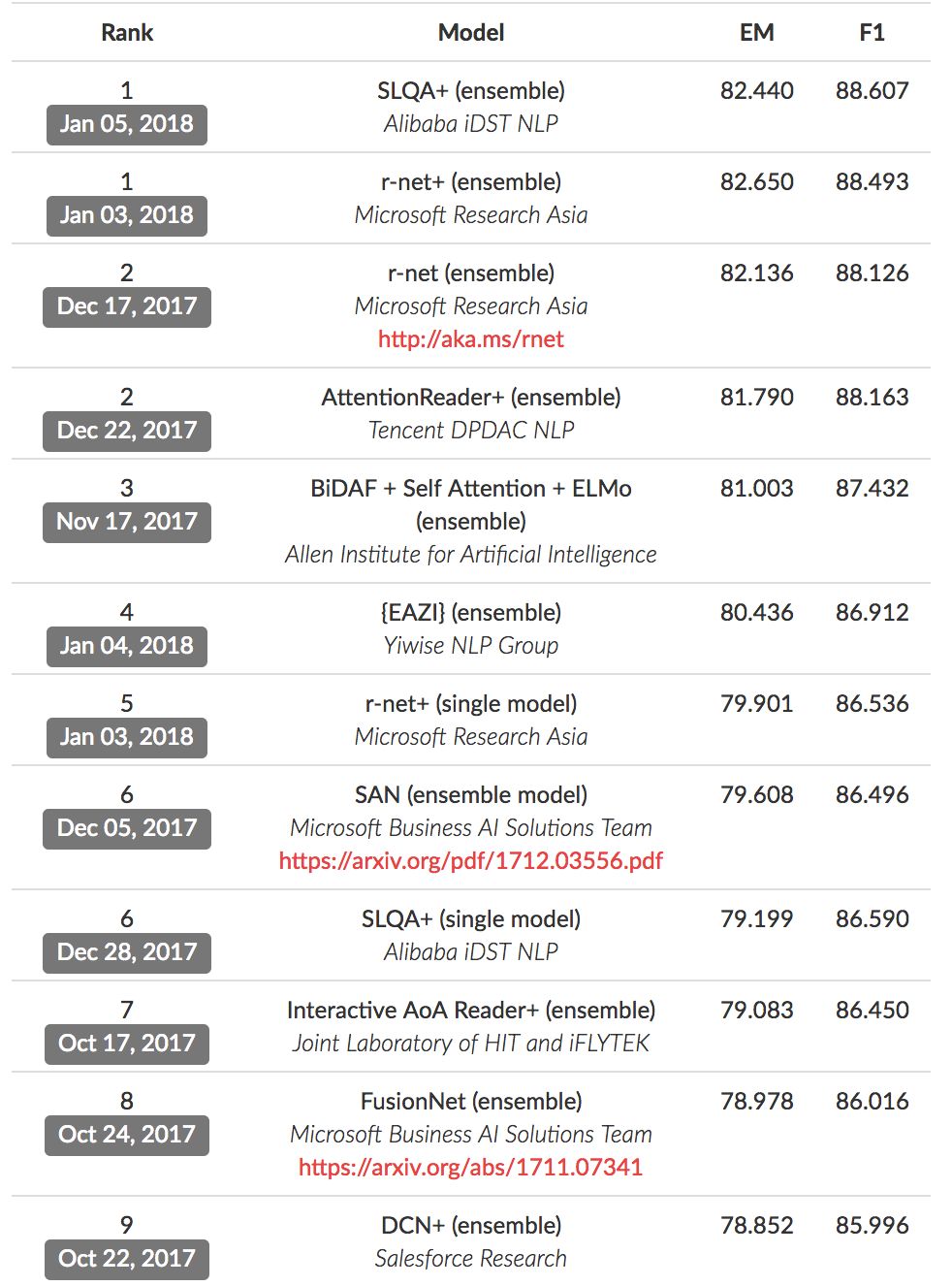
注:官网截图时间为18年1月16日
在前10名单中,我们看到了中国团队的“霸榜”:
并列第1:阿里巴巴 iDST NLP、微软亚洲研究院
并列第2:微软亚洲研究院、腾讯DPDAC NLP
第5:微软亚洲研究院
并列第6:阿里巴巴 iDST NLP
第7:科大讯飞与哈工大联合实验室
包括微软亚洲研究院、阿里巴巴、腾讯、科大讯飞、哈尔滨工业大学等在内的中国自然语言处理领域的研究机构勇攀高峰,在SQuAD 机器阅读理解比赛的前10的榜单中全面领跑。
中国AI势力崛起,积极共同推动着自然语言理解的进步。
新智元第一时间采访了周明老师团队,周老师和MSRA的资深研究员韦福如耐心解答了众多疑问,并探讨了大量技术干货,以下为精彩内容呈现。注:周为周明老师回应,韦为韦福如解析。
韦:SQuAD比赛中有两个评测指标EM和F1。
EM(Exact Match)要求系统给出的答案和人的标注答案完全匹配才能得分(会去除标点符号和冠词: a,an,the),完全匹配得1分否则不得分。
F1则根据系统给出的答案和人的标注答案之间的重合程度计算出一个0到1之间的得分,即词级别的正确率和召回率的调和平均值。
举个例子,假设某个问题的标注答案是“Denver Broncos”,系统只有给出了和标注答案完全匹配(即“Denver Broncos”)的输出,EM才会得1分,否则都不会得分。
而对于F1,即使系统输出的答案和人的标注答案不完全一样,比如系统输出的是“Broncos”,这种情况虽然EM得分为0,但是在F1这个评价指标上会得到一部分分数(0.67)。
EM是一个要求更为严格的评测指标,也是MSRA这次系统首次超过人在SQuAD上的结果的评价指标。
模型集成(ensemble)是提高系统效果的常见方法。由于神经网络模型的初始化以及训练过程有随机性,同样的算法在同样的数据上训练多次会得到不一样的模型。
模型集成就是训练多个单模型(single model),然后将这些单模型的输出进行综合得到最终结果。
集成模型一般会比单模型效果更好,但是也会以系统反应速度和计算资源为代价。实际应用中需要在模型效果和模型效率(更好和更快)上取平衡。
韦:SQuAD在测试数据集上对每个问题都至少有三个答案 (每个问题至少有3个人标注答案)。SQuAD会将第二个答案作为人的预测结果,将剩余的答案作为标准答案。
对于EM指标,预测答案同任何一个标准答案相同就算得分。对于F1指标,会选取同所有标准答案中分数最高的作为其得分。这样就得到了人的EM分数(82.304)和F1分数(91.221)。
周:16年这个比赛开始,我们微软亚洲研究院每次提交模型几乎都是第一,在2017年底,我们的成绩82.136,已经十分接近人类的标准,仅差0.17个点。这次我们模型的EM值突破达到82.650,超越了人类在精准回答的指标0.3个点。简单的说,可以这样理解这0.3个点,我们的系统比人做这套题库,多做对了30道题。
这远远不代表计算机超越了人类的阅读理解水平,因为这样的跑分结果是有一个前提条件约束的,比如在确定的题库和测试时间,并且只是成年人平均理解水平。
超越人类不能作为媒体的报道噱头,我们在看到技术进步的同时,更应该冷静思考模型的不断完善和技术应用落地。这是一个生态,需要所有玩家一起健康竞争,把现阶段面临的难题攻克,而非停留在比赛第一这样的阶段性喜悦中。
NLP最难突破的技术核心问题是什么
韦:目前SQuAD榜单上排名靠前的系统采用的都是端到端的深度神经网络。一般包含以下几个部分:
Embedding Layer:一般采用的都是在外部大规模数据上预训练的词向量(例如Glove等),以及基于循环神经网络或者卷积神经网络的从字符到单词的词向量(表示),这样就可以得到问题和文章段落里面每个单词的上下文无关的表示。有的模型也会抽取一些特征和词向量一起作为网络的输入。相当于是人的词汇级的阅读知识。
Encoding Layer:一般采用多层的循环神经网络得到问题和文章段落的每个词的上下文相关的表示。相当于人把问题和文章段落读了一遍。
Matching Layer:实际上是得到问题里面的词和文章段落词之间的对应(或者叫匹配)关系。基本是采用注意力(attention)的机制实现,常见的有基于Match-LSTM和Co-attention两种,这样就得到文章里面每个词的和问题相关的表示。相当于是带着问题把文章段落读了一遍。
Self-Matching Layer:在得到问题相关的词表示的基础上再采用self-attention的机制进一步完善文章段落中的词的表示。相当于是再把文章段落读一遍,书读百遍,其义自见。
AnswerPointerLayer:对文章段落里面的每个词预测其是答案开始以及答案结束的概率,从而计算文章段落中答案概率最大的子串输出为答案。这个一般采用Pointer Networks实现。相当于人综合所有的线索和知识定位到文章段落中的答案位置。
实际上,目前SQuAD上的排名靠前的系统在模型和算法上都有相通、相近之处。
而这也是SQuAD比赛一年多以来,整个阅读理解研究的社区和同仁(来自不同学校、公司、研究机构)共同努力、相互借鉴和提高的结果。
目前最好的模型一般综合了以下的算法或部件,包括早期基础模型。
例如Match-LSTM(新加坡管理大学)和BiDAF(Allen Institute for Artificial Intelligence)注意力机制上的创新(例如Salesforce的Coattention机制,R-NET中的Gated-Attention机制等),R-NET中的Self-Matching(或者叫Self-Attention)机制,以及最近对模型效果提升明显的预训练的上下文相关的词向量表示(Contextualized Vectors),包括基于神经机器翻译训练得到句子编码器(Salesforce)以及基于大规模外部文本数据训练得到的双向语言模型(Allen Institute for Artificial Intelligence)等。
当然也有网络模型的设计、参数调优方法等的改进和创新。可以说,目前的结果实际上是整个阅读理解社区这一年多的不断努力和合作的结果。
中文阅读理解的难度比英文大吗?
周:从现在研究阶段成果来说,我没有看到论文说中文阅读理解一定比英文的难,我倒是觉得各有各的难度,比如中文的成语典故、英文的俚语都是难点,两种语言的指代也各有不同,要具体场景具体分析,不断调整模型。
,是由中国中文信息学会(CIPS)和中国计算机学会(CCF)联合主办,百度公司、中国中文信息学会评测工作委员会和计算机学会中文信息技术专委会联合承办。竞赛将于2018年3月1日正式开启报名通道,获胜团队将分享总额10万人民币的奖金,并将在第三届“语言与智能高峰论坛”举办技术交流和颁奖。
这是一件非常好的事,竞赛数据集包含30万来自百度搜索的真实问题,每个问题对应5个候选文档文本,以及人工撰写的优质答案。
比赛中任务通常定义为:让机器阅读文本,然后回答和阅读内容相关的问题。阅读理解涉及到语言理解、知识推理、摘要生成等复杂技术,极具挑战。
这些任务的研究对于智能搜索、智能推荐、智能交互等人工智能应用具有重要意义,是自然语言处理和人工智能领域的重要前沿课题。
近半年,MSRA提升突破的关键
韦:我们这次的模型是R-NET不断发展和提升的结果。
正如前面提到的,我们在把自己的研究和经验共享给学术界的同时(例如我们ACL 2017年的论文以及后面的技术报告),也在不断吸收和借鉴学术界的研究成果来提高R-NET。
在过去的几个月里面,模型的主要提升来自于几个方面,从模型和算法上我们把模型做到更深的同时也做到了更广(宽),例如Matching Layer以及整个系统中最为关键的注意力(attention)机制部分。
另外,我们也使用了基于外部大规模数据训练的上下文相关的词向量表示(Contextualized Vectors)。我们同时也正在做一些更有意思的研究,并在实验中看到了很好的结果。
我们会在将来分享更多、更细节的信息,将我们的研究成果与学术界和工业界分享,并期待大家一起努力,共同推动机器阅读理解的研究和应用创新。
机器阅读理解技术已有的落地介绍
韦:机器阅读理解技术有着广阔的应用场景。
在搜索引擎中,机器阅读理解技术可以用来为用户的搜索(尤其是问题型的查询)提供更为智能的答案。目前R-NET的技术已经成功地在微软的必应搜索引擎中得到了很好的应用。我们通过对整个互联网的文档进行阅读理解,从而直接为用户提供精确的答案。
同时,这在移动场景的个人助理,如,微软小娜(Cortana)里也有直接的应用。
另外机器阅读理解技术在商业领域也有广泛的应用,例如智能客服中,可以使用机器阅读文本文档(如用户手册、商品描述等)来自动或辅助客服来回答用户的问题。
在办公领域,机器阅读理解技术也有很好的应用前景,比如我们可以使用机器阅读理解技术处理个人的邮件或者文档,然后用自然语言查询获取相关的信息。
此外,机器阅读理解技术在垂直领域也有非常广阔的应用前景,例如在教育领域用来辅助出题,法律领域用来理解法律条款,辅助律师或者法官判案,以及在金融领域里从非结构化的文本(比如新闻中)抽取金融相关的信息等。
我们认为阅读理解能力是人类智能中最关键的能力之一,机器阅读理解技术可以做成一个通用的能力,释放给第三方用来构建更多的应用。
机器阅读理解技术2018年以及更远的展望
韦:技术上,目前基于深度学习的算法和模型还有很大的空间,能否提出可以对复杂推理进行有效建模,以及能把常识和外部知识(比如知识库)有效利用起来的深度学习网络,是目前很有意义的研究课题。
另外,目前基于深度学习的机器阅读理解模型都是黑盒的,很难直观地表示机器进行阅读理解的过程和结果,因而可解释性的深度学习模型也将是很有趣的研究方向。
在阅读理解任务上,目前SQuAD的任务定义中答案是原文的某个子片段,而在实际中人可能读完文章之后还需要进行更复杂的推理、并组织新的文字再表达出来。对此,微软发布的MARCO数据集正在朝着这个方向努力。
此外,由于目前的SQuAD数据集中假设每个问题一定可以在对应的文档段落中找到答案,这个限制条件对于比赛和研究来说是合理有效的,所以,现有的模型就算不是很确定也会选取一个最可能的文档片段作为输出。
这个假设和模型的输出在实际应用中并不合理。人类在阅读理解回答问题上有一个很重要的能力就是可以知道如果阅读的文本里面没有答案会拒绝回答。
而这个问题不论是在研究上,还是在实际应用中,都是非常重要的研究课题。我们也已经在开展这方面的研究,并且取得了一些不错的进展。
最后,由于SQuAD数据集中的文档都是来自维基百科,虽然目前的模型都是数据驱动,但是要把目前的模型真正应用到特定的领域(尤其是垂直领域,比如金融、法律等),还需要在数据和模型上做适配和进一步的创新。
加入社群
此外,新智元AI技术+产业领域社群(智能汽车、机器学习、深度学习、神经网络等)正在面向正在从事相关领域的工程师及研究人员进行招募。
加入新智元技术社群,共享AI+开放平台
以上是关于专访MSRA周明团队,NLP铁军“超越人类”技术揭秘的主要内容,如果未能解决你的问题,请参考以下文章
[直聘]微软MSRA自然语言计算组诚聘:研究实习生 NLP研究员