NLP新里程碑!清华姚班毕业生发布KEAR:首次常识问答超越人类
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP新里程碑!清华姚班毕业生发布KEAR:首次常识问答超越人类相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :新智元
AI模型一直为人诟病的一点就是只会「死学习」,只能根据给定的训练样本来进行预测,稍微问一点「常识性」的问题它都回答不了。
比如你问GPT-3:太阳有几个眼睛?
它会毫不犹豫的告诉你:当然是一个眼睛!

虽然常识信息没有体现在输入文本中,但如果不懂常识的话,那回答只能是驴唇不对马嘴。
为了解决这类常识性错误,研究人员借助ConceptNet建立了一个专门针对常识问答的数据集CommonsenseQA,要求模型必须得了解常识才能够正确回答问题。
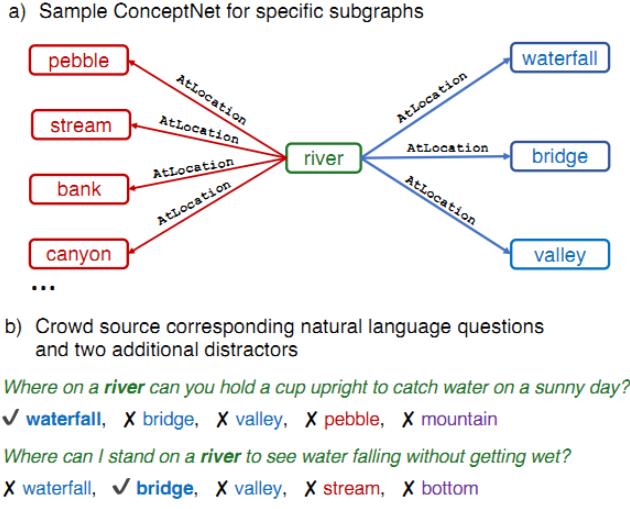
每个问题包含五个候选答案,其中有两个是干扰项,对AI模型来说属于是难上加难了。
例如给定一个问题:你的狗喜欢吃什么?(What is a treat that your dog will enjoy?)
候选答案可能是沙拉(salad)、抚摸(petted)、喜爱(affection)、骨头(bone)、关心(lots of attention)等。人在与狗交往的过程中,可以了解到大部分狗都喜欢吃骨头,从而推理出你的狗在候选答案中也更倾向于骨头,但AI模型并不懂。
所以想要正确回答这个问题,必须要懂得如何利用外部知识。
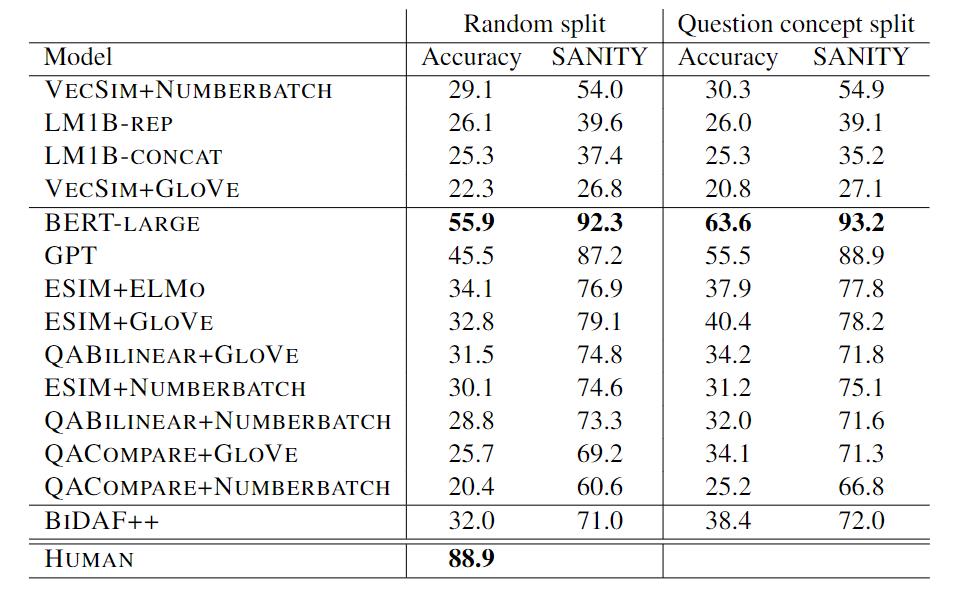
然后CommonsenseQA的作者拿了一个当时横扫各大排行榜的模型BERT-LARGE来做测试,结果惨不忍睹,准确率只有55.9%,而人类的回答准确率已经达到了88.9%了。
时间来到三年后,最近来自微软的华人团队发表了一篇论文,提出了一个KEAR(Knowledge External Attention for commonsense Reasoning)系统,将CommonsenseQA常识问答的性能抬到了新高度,准确率达到89.4%,成功超越人类,堪称AI常识领域的里程碑模型了。

相比传统AI模型需要大规模数据来训练,这篇论文提出了一种外部注意力机制(external attention mechanism)来增强Transformer架构,能够把外部知识信息集成到预测的过程中,从而减少了模型对大参数量的需求,让AI系统更加民主化(democratization),也就是说可以降低AI模型研究的门槛,不用从老黄那买特别多的显卡,也能实现SOTA性能。
大体来说,KEAR模型在回答「你的狗喜欢吃什么」这个问题的时候,它会首先从ConceptNet实体链中检索出「狗— desires — petted, affection, bone, lots of attention」,这样就排除了一个错误答案沙拉。
然后KEAR会从Wiktionary中检索出骨头的定义:构成大多数脊椎动物骨架的复合材料(a composite material making up the skeleton of most vertebrates);
从CommonsenseQA数据集中的训练数据中检索出「狗喜欢吃什么?骨头」(What do dogs like to eat? bones)。
再将检索到的知识和输入的知识进行级联后,KEAR将其作为DeBERTa模型的输入,最后可以推理出正确答案:骨头!

可以看到,对于人类来说最简单的一个问题,AI模型要完成却需要大量的外部信息才能正确回答。
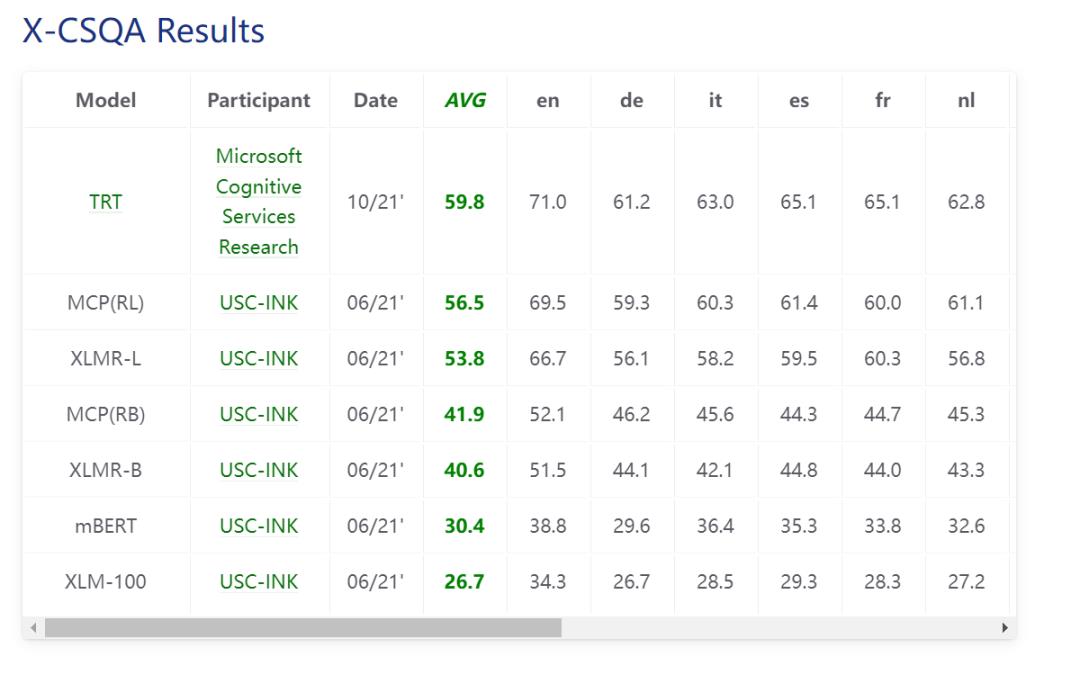
由于CommonsenseQA只是英文常识问答的数据,文中还探索了一下其他语言的常识推理是否依然有效。
研究人员首先将非英语问题翻译成英语,然后在英语的语料数据中检索知识,然后将知识文本翻译成源语言,经过外部注意力机制后再翻译获得答案,即翻译-检索-翻译(TRT)。
结果也是在X-CSR基准上的两个任务X-CODAH和X-CSQA都取得了第一名。
不止于自注意力
时至今日,大部分AI模型基本都在源文本上使用自注意力机制,通过把大量的数据喂给模型进行训练,从而使模型记住输入的文本。
虽然Transformer的效果很好,但缺点也很明显:
时间和空间复杂度太高,需要大量的显卡和显存
数据量不够的情况下,Transformer表现不够好
另一方面,Transformer本质上还是黑盒模型,没办法让他像人类一样进行文本理解和推理,知道AI为什么产生这样的预测是很重要的,KERA通过利用知识图谱、字典和公开可用的机器学习数据的常识性知识,能够一定程度地反应答案的来源及模型推理过程。
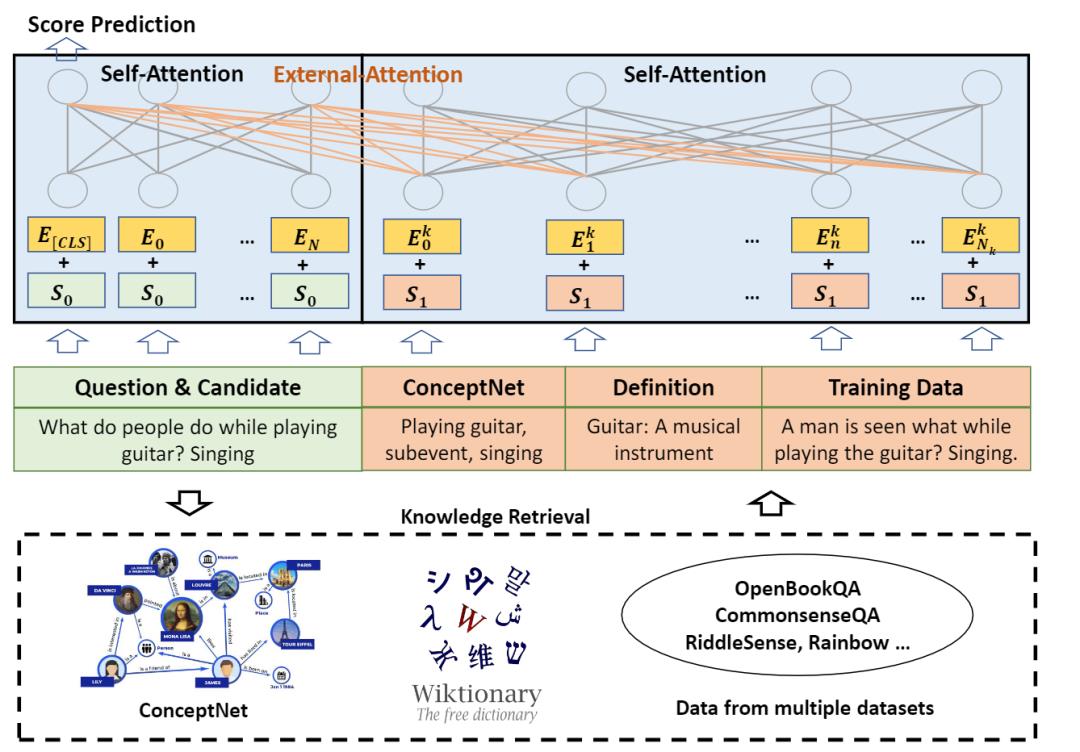
外部注意力的实现方法也很简单,将输入(input)和知识(knowledge)级联起来作为新的输入,然后将整体作为H0经过自注意力机制即可。
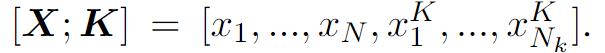
其中K(nowledge)的来源包括知识图谱ConceptNet, 字典和训练数据。
可以看到,自注意力和外部注意力的主要区别就是输入是否只来源于输入文本,即通过向外部注意力机制提供不同来源的相关背景和知识,包括知识图谱、字典、语料库和其他语言模型的输出,然后让模型同时对输入进行自注意力和对知识进行外部注意力,就能达到引入外部知识的效果。
引入的外部信息以符号(symbol)的方式存储,如纯文本或知识图谱条目,从而能够提升Transformer在语言理解方面的能力。
并且KEAR使用的输入和知识的文本级联不会对Transformer模型结构产生任何改变,使现有的系统可以很容易地使用外部注意力。
因为世界上的知识也是在动态变化的,所以外部注意力的另一个好处是,用户可以很容易地更新知识源来改变模型的预测输出。
通过引入最新的常识,例如将在线更新的知识图谱输入到模型中,可以使模型的决策过程变得更加透明和可解释。
而用多模块联合优化、加上外注意力引入知识库也是微软人工智能认知服务提质量的核心方向。
作者介绍
文章的第一作者是徐一翀,本科毕业于清华大学姚班,于卡内基梅隆大学取得博士学位,主要研究方向为交互式机器学习,自然语言处理和深度学习。目前是微软AI Cognitive Services研究组的高级研究员。

朱晨光是微软认知服务研究组的首席研究负责人。他领导知识和语言团队,从事文本总结、知识图谱和面向任务的对话方面的研发工作。他于2016年在斯坦福大学获得计算机科学博士学位和统计学硕士学位,在此之前于清华大学姚班获得计算机科学学士学位。

黄学东是微软AI认知服务工程和研究团队的领导人,IEEE/ACM院士(IEEE/ACM Fellow) ,微软首位「华人全球技术院士」、微软首席语音科学家、微软云计算与人工智能事业部认知服务团队全球技术院士/全球人工智能首席技术官。他先后获得湖南大学学士学位,清华大学硕士学位和英国爱丁堡大学博士学位。

参考资料:
https://arxiv.org/abs/2112.03254
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于NLP新里程碑!清华姚班毕业生发布KEAR:首次常识问答超越人类的主要内容,如果未能解决你的问题,请参考以下文章