追星的新姿势:使用NLP来分析巨星专辑的特别之处
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了追星的新姿势:使用NLP来分析巨星专辑的特别之处相关的知识,希望对你有一定的参考价值。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
每隔几年,就会有一位巨星风靡全世界。纵观历史,披头士乐队、Michael Jackson 等巨星就曾经这样风靡了全世界。这些巨星用他们的作品,影响了上百万人。当时光车轮驶入 21 世纪第二个十年之后,许多艺人做梦都想成为世界第一的巨星。然而出乎意料的是,一位名叫 Aubrey Graham 的多伦多人,以“Drake”为艺名,站在了世界舞台的巅峰。
Drake 最初成名的原因,是 21 世纪初他在青少年情景喜剧《Degrassi: the Next Generation》中扮演的角色。但 Drake 想成为一名说唱歌手,于是离开了剧组。Lil Wayne,当时最有影响力的说唱歌手之一,在多伦多有很多粉丝。在与 Lil Wayne 的唱片公司 Young Money Entertainment 签约后,Drake 发行了他的第一张专辑《So Far Gone》。这张专辑被认证为白金专辑,Drake 得以迅速上升到嘻哈世界的巅峰。在随后的八年里,他又发行了四张专辑、一盘录音带和一张播放列表。他最新的专辑叫《Scorpion》。
我们知道 Drake 的作品很受欢迎,但是,他为什么会如此广受欢迎呢?是音乐本身,还是因为市场营销让他如此受欢迎?我觉得也有可能是因为多种因素同时起了作用。因此,我要看看他的歌词,试图分析究竟是什么原因让 Drake 如此广受欢迎。Drake 涉猎的范围很广泛,而且都留下了很好的歌词文本,因此,获取文本数据并不是一件很困难的任务。但是如何去分析这些数据呢?得益于 NLP 技术的发展,分析文本数据比以往要容易多了。
根据维基百科说法,自然语言处理(Natural Language Processing,NLP)“是计算机科学和人工智能的一个领域,涉及计算基金和人类(自然)语言之间的相互作用,特别是如何对计算机进行编程,以处理和分析大量的自然语言数据。”在我看来,NLP 是机器学习中最有趣的领域。以许多不同形式产生的文本,为我们提供了大量的数据用于研究。
在过去的 5~10 年历,NLP 得到了快速的发展,直接与深度学习的兴起相吻合。神经网络已经成为无数 NLP 算法的通用框架。今天,有各种各样的工具可供使用,因此,从业者得以解决大量的 NLP 问题。有了这些工具,我就可以检查 Drake 的歌词了!
在开始真正的分析之前,我必须了解 Drake 的歌词。虽然网上有一些在线歌词资源,但我最终还是决定使用 Genius.com,因为 Genius 是一家注释歌词的网站,做得非常棒!而且 Genius 还有一个出色的 API,非常容易使用。
Drake 经常被批评的原因之一是缺乏创造力。以前,他就曾被指控抄袭了其他说唱歌手的作品,还让他人代为作词。因此,我打算去看看这些批评者的指控是否有根据。
这篇文章《THE LARGEST VOCABULARY》(https://pudding.cool/2017/02/vocabulary/)揭示了避免歌词雷同的想法,对说唱音乐中常用的词汇进行了可视化处理。依我看,用歌词出现频率来衡量创造力是一种较低的标准,因为你要考虑到重复的歌词。
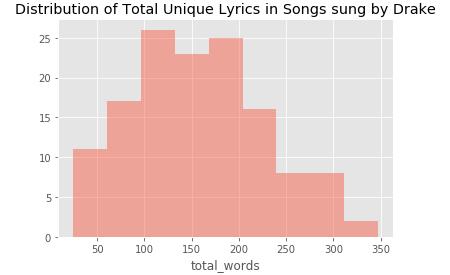
完成文本数据的清理之后,我开始分析每首歌曲中独特词的数量。如下图所示,是 Drake 所有歌曲中独特歌词分布的直方图。他的大部分歌曲似乎都有 100~200 个独特的词。由于我没有分析其他歌手歌词的情况,无从参考,因此这张直方图并没告诉我多少关于 Drake 创造力的内容。
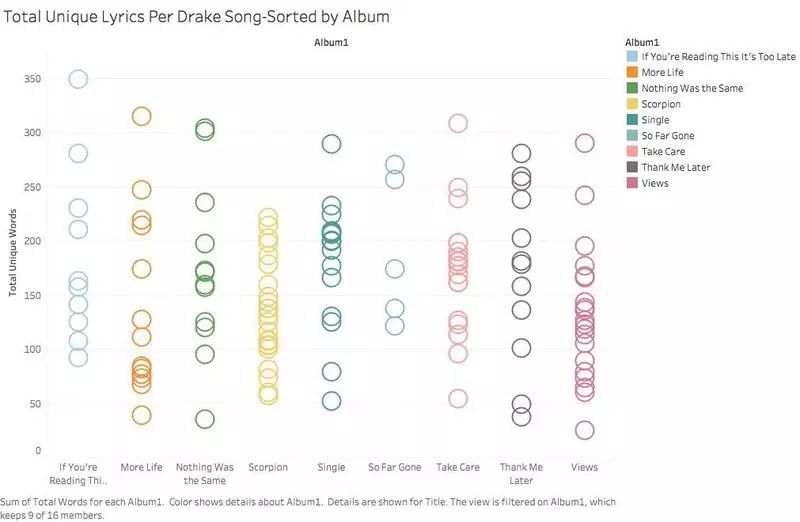
要发现 Drake 的创造力的更好方法是,通过专辑来搞清楚他的创造力。下图是我用 Tableau 中创建的。x 轴是作品的名称,y 轴是独特词的数量。每个泡泡代表一首歌。我发现,就独特的歌词而言,没有一张专辑看起来更有创意。然而,似乎每一部作品都至少有一些独特词(不包括《Scorpion》)。他最近发行的专辑《Scorpion》上的歌曲数量很多(总共 25 首),但独特词上几乎没有什么变化。
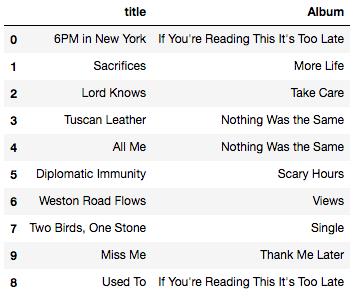
现在,回答这个问题,哪首歌的歌词最独特?答案似乎是《6PM in New York》。前 10 名的其余部分在下面,如下图所示。
命名实体识别(Named Entity Recognition ,NER)是“一项信息提取的子任务,它试图将文本中命名的实体定位和分类为预定义的类别,如人名、组织、地点、时间、数量、货币价值、百分比等”。NER 是一项特别棘手的任务。英语的复杂性使得很难创建一个对所有文本源都准确的 NER 算法。算法可能在一个文本语料库 (在我们的例子中是 Drake 歌曲集) 上表现得很好,然后在另一个语料库上表现得很差。这种不一致使得有必要尝试几种 NER 算法。正如你将看到的,算法也不是非常不准确。
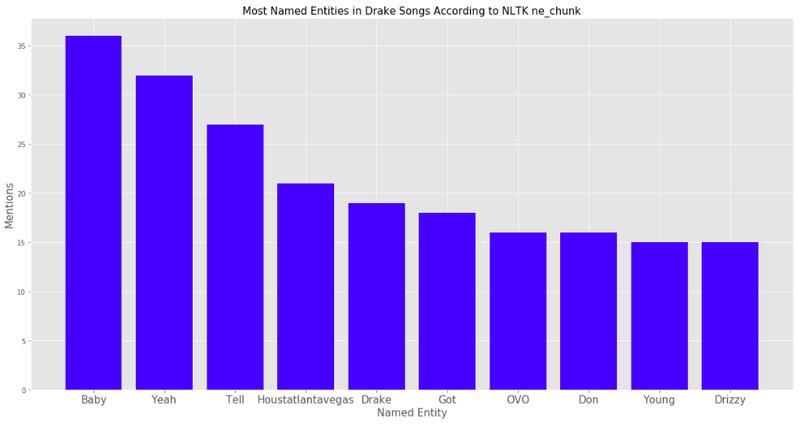
我实现的第一个是 NLTK 提供的命名实体算法。“Ne_chunk”使用带有词性标记(Part Of Speech tags,POS tagging)的单词列表来推断那些单词是实名实体。从我发现的结果中,你可以看出,NLTK 算法本身并不能很好地完成工作。
我尝试的第二种命名实体算法是 Stanford 发明的。可以说,Stanford 的计算语言学系在世界上是最负盛名的。该系开发出来的众多令人印象深刻的工具之一,就是 NER 工具。
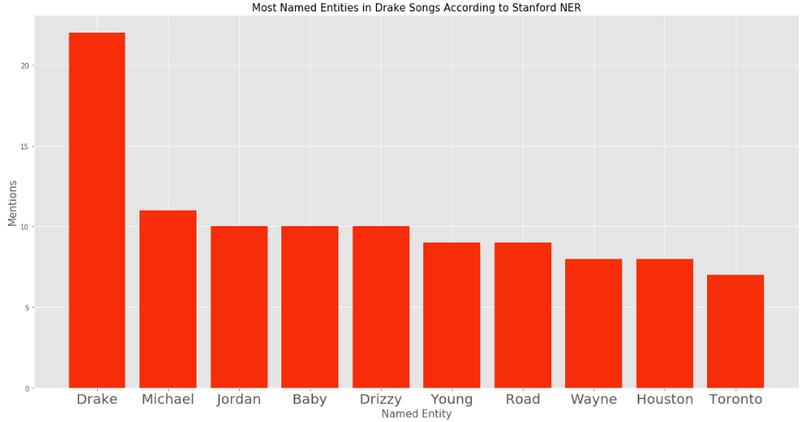
与 NLTK 的算法相比,该工具的运行时间要长得多,但它也能产生更准确的结果。虽然它并不算完美,但却是一个巨大的进步。
NLP 中最有趣的学科之一是主题建模。主题模型是一种统计模型,用于在文档集中抽取“主题”。主题建模是一种常用的文本挖掘工具,用于在文本主题中发现隐藏的语义结构。主题建模有几种算法,其中最突出的是显式语义分析(Explicit Semantic Analysis)和非负矩阵分解(Non-Negative Matrix Factorization)。然而我选择在本文用的是隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)。LDA 是由 Andrew Ng、Michael I·Jordan 和 David Blei 开发的生成统计模型。LDA 是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。
我想使用 LDA 做的的第一件事就是学习 Drake 所有歌曲中最突出的主题。为了做到这一点,我把所有的歌都列在了一个列表里。然后,利用 SciKitLearn 的 CountVectorizer,我创建了一个词袋(Bag Of Words)表示所有这些歌曲。词袋是通过矩阵表示(matrix representation)来表示单词的一种简单方法。然后使用 SciKit 学习 LDA 版本,我建立了一个模型,在给定的文本中,找到 8 个主题。
我发现有两条可行的路径来可视化 LDA 模型。第一个是通过我写的一个函数。基本上,它输出的是每个主题中最突出的词。
这里的结果很有趣,尽管得到的信息很有限。从下图中可知,主题 7 与主题 2 不同,到底怎么个不同法,结果没有提供足够的信息。

LDA 主题
辅助主题(auxiliary topics)没有提供足够的信息来区分不同的主题。出于这个原因,我用另一种方式在文本中显示主题。
在 Python 中,有一个很棒的库叫做 pyLDAvis。它是一个专门的库,使用 D3 来帮助可视化 LDA 模型创建的主题。D3 可以说是最好的可视化工具。但是,它是针对 javascript 用户的。对 JavaScript 不是特别熟练的人来说,这个插件也非常有用。为了使数据可视化,库使用降维方法。维数减缩(Dimensionality Reduction)将一个包含许多变量的数据集压缩成更小的特征量。维数减缩技术对于可视化数据非常有用,因为它可以将数据压缩为两个特征。对于我的特定的可视化,我认为,最好使用 T-SNE(t 分布的随机邻居嵌入)来进行维数减缩。
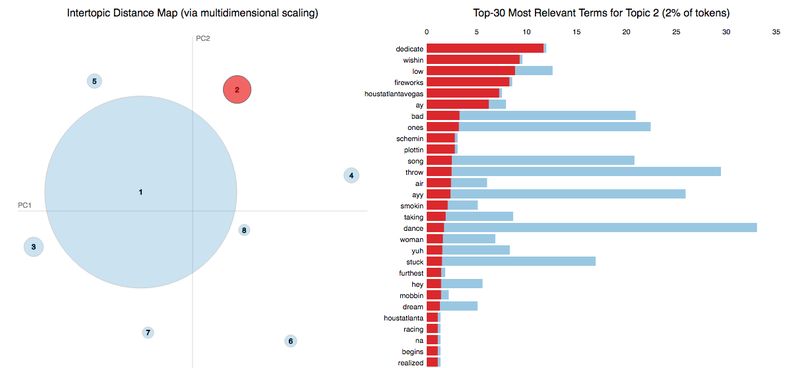
可视化主题
从我的模型的拟合来看,Drake 的大部分歌词,都可以归类为一个占据图表大部分的主题。相比之下,其他的主题都不足挂齿。
Drake 所有主要作品的主题是什么?
为了搞清楚这一问题,我按照与以前相同的步骤进行(除了为找到每个专辑的主题而运行 LDA 算法外)。然后我使用了之前定义的函数,显示他所有主要作品中最突出的词,如下图所示:
Drake 所有主要作品中最突出的词
Drake 可以说是世界上最受欢迎的歌手之一。当他决定引退时,将会成为有史以来成就最高的说唱歌手之一。因此,每当他发布新歌或专辑时,肯定会引起轰动效应。由于这些原因,他的歌词在短短几周内就迅速成为 Instagram 和 Facebook 字母的主要内容。他的歌之所以令人难以忘怀,主要因素是因为歌词。
就我的第一个 NLP 项目而言,我认为这是一个成功的项目。我觉得通过这些工作,我对 Drake 的歌词有了更具体的理解。虽然在未来的工作中,我可以使用其他一些 NLP 任务,但主题建模和命名实体识别是一个很好的起点。
原文链接:
https://towardsdatascience.com/drake-using-natural-language-processing-to-understand-his-lyrics-49e54ace3662
如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!
以上是关于追星的新姿势:使用NLP来分析巨星专辑的特别之处的主要内容,如果未能解决你的问题,请参考以下文章