滴滴云A100 40G 性能测试 V100陪练!
Posted 托尼是塔克
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了滴滴云A100 40G 性能测试 V100陪练!相关的知识,希望对你有一定的参考价值。
眼看游戏卡RTX3080 发售在即,我终于等到了滴滴云(感谢)A100的测试机会。因为新卡比较紧张,一直在排队中,直到昨天才拿了半张A100...今天终于上手了单张40G的A100,小激动,小激动,小激动!!!基于安培架构的最新一代卡皇(NVIDIA GPU A100 Ampere)可以搞起来了。
Part 1:系统环境
A100正处于内存阶段,官网上还看不到。内测通过ssh连接,ssh连上去之后大概看了下系统环境。
操作系统,CPU,RAM数据如上。重点关注GPU:A100-SXM4-40GB (上次摸DGX A100的时候,没有把测试跑起来,好悔)
CUDA11,CudNN,TensorFlow1.5.2 等配套环境滴滴云都已经部署好了,可以省去好多时间!
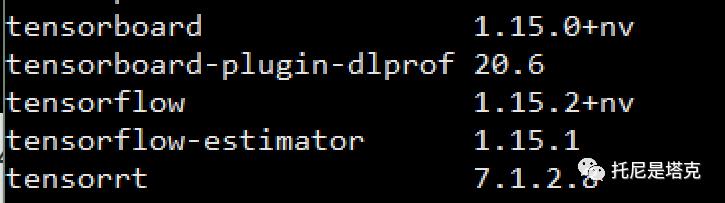
这里需要注意,新版显卡必须要用CUDA11,而且得用NV自己编译的TensorFlow1.5.2。
然后,网上捞一段Python代码:
from tensorflow.python.clientimport device_lib print(device_lib.list_local_devices())
输出:
Created TensorFlow device (/device:GPU:0 with 36672 MB memory) -> physical GPU (device: 0, name: A100-SXM4-40GB, pci bus id: 0000:cb:00.0, compute capability: 8.0): "/device:CPU:0"device_type: "CPU"memory_limit: 268435456locality {}incarnation: 3653225364972814250name: "/device:XLA_CPU:0"device_type: "XLA_CPU"memory_limit: 17179869184locality {}incarnation: 7582640257522961335physical_device_desc: "device: XLA_CPU device"name: "/device:XLA_GPU:0"device_type: "XLA_GPU"memory_limit: 17179869184locality {}incarnation: 5159602092499780099physical_device_desc: "device: XLA_GPU device"name: "/device:GPU:0"device_type: "GPU"memory_limit: 38453856175locality {bus_id: 6numa_node: 5links {}}incarnation: 3682405687960901280physical_device_desc: "device: 0, name: A100-SXM4-40GB, pci bus id: 0000:cb:00.0, compute capability: 8.0"]
可以看到有XLA_GPU和GPU,物理设备型号为A100-SXM4-40GB,算力8.0,调用应该没问题!
Part 2:掂量掂量
卡到手了,肯定是要测一测!
既然是测试,肯定需要有陪跑选手滴。这里用到的设备为谷歌Colab的V100 16G,矩池云的2080TI 11G(为啥要拉上我这个性价比之王 ╰(艹皿艹 ) ,曾经的我随风飞扬,现在的我感觉天台的风好凉)。
设备有了,怎么测试才科学呢?用娱乐大师么? 不行滴,不行滴,不行滴!
首先,操作系统都是 Ubuntu18.04,跑不了Window上的软件。
其次,这里主要是比较深度学习能力,不比吃鸡能力。
深度学习卡能干什么?炼丹咯!
刚好看到(蓄谋已久)TensorFlow官方有提供Benchmarks,可以测试一些常见模型,那我就现学现卖用这个来做个“业余”测试吧,本文提供数据仅供参考,如有谬误,不要找我!
https://github.com/tensorflow/benchmarks运行前需要先安装好CUDA,Cudnn,和TensorFlow,基本没什么多余的依赖。
三行命令就可以跑起来了
git clone https://github.com/tensorflow/benchmarks.gitcd benchmarks/scripts/tf_cnn_benchmarkspython tf_cnn_benchmarks.py --num_gpus=1 --batch_size=32 --model=resnet50
如果要测试特定的版本:
git checkout cnn_tf_v1.15_compatible这里注意区分1.15和1.5版本,别搞错哦!
Part 3:测试结果
怀着无比激动的心情,重复着无比枯燥的复制黏贴,终于把表格做出了。每次跑会有一些微小的差别,但是整体偏差不会太高。
Model /GPU |
A100 |
V100 |
2080ti |
ResNet50 |
645.26 |
386.06 |
303.65 |
AlexNet |
8282.46 |
4808.18 |
3905.13 |
Inception v3 |
440.01 |
254.19 |
198.97 |
VGG16 |
442.20 |
250.19 |
178.02 |
GoogLeNet |
1556.06 |
1029.42 |
777.65 |
ResNet152 |
228.29 |
138.39 |
115.28 |
A100 VS V100 VS 2080ti
这张表格使用Benchmarks的默认参数对比了A100,V100, 2080ti的性能。横向为GPU,列为模型名称,中间的为吞吐量images/sec,数字越大就证明越强。从结果来看,A100 Vs V100,基本保持在1.5倍上,比较好的能达到1.7倍左右。
上面为默认参数,下面使用--use_fp16比较一下A100和V100的差距。
Model /GPU |
A100 |
V100 |
ResNet50 |
1315.11 |
914.24 |
AlexNet |
10587.67 |
8810.04 |
Inception v3 |
946.03 |
579.62 |
VGG16 |
687.07 |
428.17 |
GoogLeNet |
2680.27 |
1878.02 |
ResNet152 |
395.34 |
293.98 |
A100 Vs V100 FP16
因为之前跑了20G的A100,所以也来比较一下通过MIG分割后的卡和单卡之间的差别。
MIG是multi-instance-gpu的缩写,多实例 GPU (MIG) 可提升每个 NVIDIA A100 Tensor 核心 GPU 的性能和价值。MIG 可将 A100 GPU 划分为多达七个实例,每个实例均与各自的高带宽显存、缓存和计算核心完全隔离。
模型/显卡 |
A100 40G(单张) |
A100 20G(半张) |
ResNet50 |
645.26 |
309.91 |
AlexNet |
8282.46 |
3694.83 |
Inception v3 |
440.01 |
226.36 |
VGG16 |
442.20 |
187.99 |
GoogLeNet |
1556.06 |
748.62 |
ResNet152 |
228.29 |
119.79 |
A100 40G VS MIG 20G
从结果来看,40G和20Gx2有输有赢。也就是说MIG切完后性能并没有掉很多。
因为我手上显卡资源匮乏,没有其他设备,所以网上找了一张表格,可以通过V100作为参考系,对比一下其他设备和A100的差距。
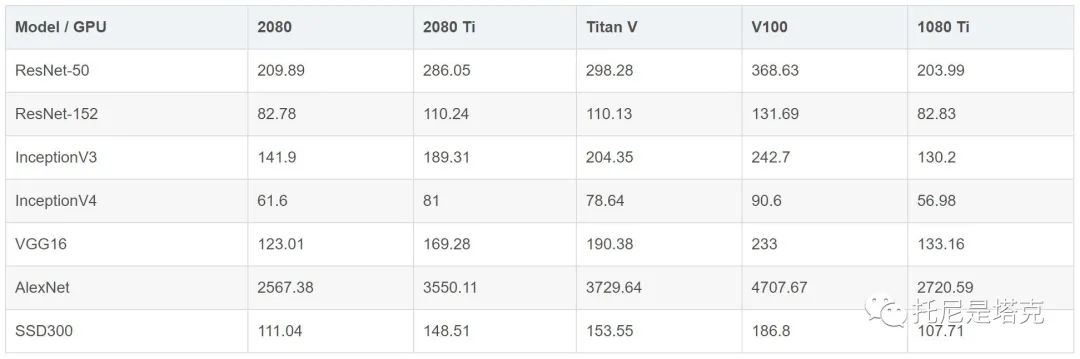
再贴两张官方的性能对比图
从官方的图来看,8张A100最好的情况下能达到8张V100的6倍多。其中跑ResNet-50 V1.5的时候大概能达到两倍,刚好TensorFlow Benchmarks提供了这个模型。那我就顺手测一测,如果有不一致,肯定是我的打开方式不对,老黄请不要拿RTX3090显卡砸我,我会空手接...!
Model /GPU |
A100 |
V100 |
ResNet-50 V1.5 |
606.23 |
349.78 |
ResNet-50 V1.5 FP16 |
1341.26 |
851.87 |
拿出计算器滴滴滴:
606.23 / 349.78 = 1.73317513865858539653496483503921341.26 / 859.04 = 1.5744890652329580804582858886919
老黄诚不我欺,四舍五入一下真的是两倍哎!
当然,严格来说,我们的测试环境还是存在不小的差异。NV官方是8卡对决(家里没矿,但是卡多啊),能保证测试过程中其他变量保持一致。我这是随手取了两个平台的单卡。
Part 4:简单总结
《性能提升20倍:英伟达GPU旗舰A100登场》这样的媒体报道,就只能当故事汇了。正常的大厂都不可能这么升级,老黄的刀法也不允许这种事情发生,一年一刀,一刀一倍不香么。从实际情况来看,A100单手怼2080ti(2倍+), 双脚踩V100是没有问题滴(1.5倍+)。
滴滴云对于A100的跟进速度相当之快,很早就开始筹备,现在已经开放测试申请了,如果有需要的可以去申请测试。要用GPU的可以去他们官网看看,质量没问题,相比之下价格非常实惠(大师码:8888)。
明天预计会发布 A100 40G跑DeepFaceLab的文章。本文中如果出现错误,我会更新在个人博客中(www.tonyisstark.com)!
完
以上是关于滴滴云A100 40G 性能测试 V100陪练!的主要内容,如果未能解决你的问题,请参考以下文章
独立云计算领导者Vultr将NVIDIA A16添加到其A40A100和GPU分片产品阵容中