数据可视化代码实例(Matplotlib+Pandas)
Posted AI星课堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据可视化代码实例(Matplotlib+Pandas)相关的知识,希望对你有一定的参考价值。
Matplotlib简介
Matplotlib是python中优秀的数据可视化第三方库。可以使用在python脚本,IPython,jupyter notebook,以及网页应用服务中。matplotlib可以通过少量的代码生成柱状图,散点图,饼图,误差图等常用图形。对于简单作图,使用pyplot模块可以类似于matlab语法规则一样作图,当然也提供专业作图方法,来精确控制线条,文字坐标等。
为什么对matplotlib都是负面评价?
在我看来,新用户学习matplotlib之所以会面临一定的挑战,主要有以下几个原因。
首先,matplotlib有两种接口。第一种是基于MATLAB并使用基于状态的接口。第二种是面向对象的接口。为什么是这两种接口不在本文讨论的范围之内,但是知道有两种方法在使用matplotlib进行绘图时非常重要。
两种接口引起混淆的原因在于,在stack overflow社区和谷歌搜索可以获得大量信息的情况下,新用户对那些看起来有些相似但不一样的问题,面对多个解决方案会感到困惑。从我自己的经历说起。回顾一下我的旧代码,一堆matplotlib代码的混合——这对我来说非常混乱(即使是我写的)。
matplotlib的另一个历史性挑战是,一些默认风格选项相当没有吸引力。 在R语言世界里,可以用ggplot生成一些相当酷的绘图,相比之下,matplotlib的选项看起来有点丑。令人欣慰的是matplotlib 2.0具有更美观的样式,以及非常便捷对可视化的内容进行主题化的能力。
使用matplotlib我认为第三个挑战是,当绘制某些东西时,应该单纯使用matplotlib还是使用建立在其之上的类似pandas或者seaborn这样的工具,你会感到困惑。任何时候都可以有多种方式来做事,对于新手或不常用matplotlib的用户来讲,遵循正确的路径是具有挑战性的。将这种困惑与两种不同的API联系起来,是解决问题的秘诀。
为什么坚持要用matplotlib?
尽管有这些问题,但是庆幸有matplotlib,因为它非常强大。这个库允许创建几乎任何你可以想象的可视化。此外,围绕着它还有一个丰富的python工具生态系统,许多更先进的可视化工具用matplotlib作为基础库。如果在python数据科学栈中进行任何工作,都将需要对如何使用matplotlib有一个基本的了解。这是本文的其余部分的重点——介绍一种有效使用matplotlib的基本方法。
基本前提
如果你除了本文之外没有任何基础,建议用以下几个步骤学习如何使用matplotlib:
1、学习基本的matplotlib术语,尤其是什么是图和坐标轴
2、始终使用面向对象的接口,从一开始就养成使用它的习惯
3、用基础的pandas绘图开始你的可视化学习
4、用seaborn进行更复杂的统计可视化
5、用matplotlib来定制pandas或者seaborn可视化
这幅来自matplotlib faq的图非常经典,方便了解一幅图的不同术语。
2 基于Matlab并基于状态的接口
matplotlib内部结构复杂,但是pyplot可以快捷绘制各种可视化图形。
在使用前,记得导入模块:
1import matplotlib.pyplot as plt
先绘制一个简单图形。
1import matplotlib.pyplot as plt
2plt.plot([3,1,4,5,2])
3plt.ylabel("Grade")
4plt.show()
代码的结果如下:

plot函数介绍
1import matplotlib.pyplot as plt
2plt.plot(x ,y ,format_string, **kwargs)
参数说明
x:x轴数据,列表或者数组,可以无
y:y轴数据,列表或者数据
format_string:控制曲线风格的字符串,可以无
**kwargs :第二组曲线或者更多曲线控制参数。
2.1 散点图
散点图非常适合展现两个变量间关系,因为,图中可以直接看出数据的原始分布。还可以通过设置不同的颜色,轻松地查看不同组数据间的关系,如下图所示。那如果想要可视化三个变量之间的关系呢?没问题!只需再添加一个参数(如点的大小)来表示第三个变量就可以了,如下面第二个图所示。
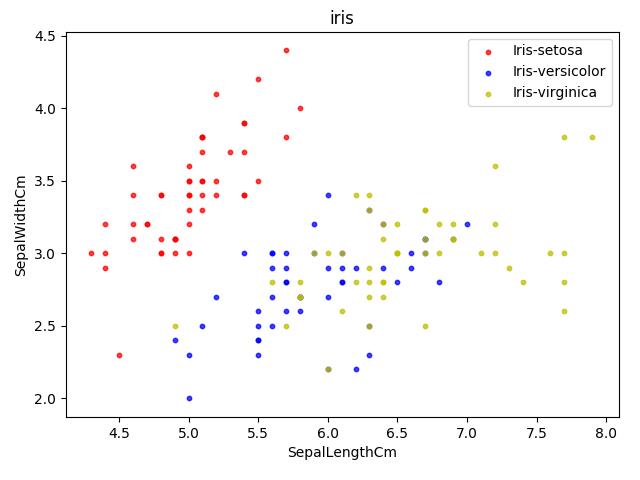
现在来写代码。首先导入Matplotlib库的pyplot子库,并命名为plt。使用 plt.subplots()命令创建一个新的图。将x轴和y轴数据传递给相应数组x_data和y_data,然后将数组和其他参数传递给ax.scatter()以绘制散点图。我们还可以设置点的大小、颜色和alpha透明度,甚至将y轴设置成对数坐标。最后再为该图设置好必要的标题和轴标签。这个函数轻松地实现了端到端的绘图!
1import matplotlib.pyplot as plt
2import numpy as np
3import pandas as pd
4def main():
5 iris=pd.read_csv('Iris.csv')
6 iris1=iris[iris['Species'].isin(['Iris-setosa'])]
7 iris2=iris[iris['Species'].isin(['Iris-versicolor'])]
8 iris3=iris[iris['Species'].isin(['Iris-virginica'])]
9 _, ax = plt.subplots()
10 ax.scatter(iris1['SepalLengthCm'], iris1['SepalWidthCm'], s = 10, color = "r", alpha = 0.75)
11 ax.scatter(iris2['SepalLengthCm'], iris2['SepalWidthCm'], s = 10, color = "b", alpha = 0.75)
12 ax.scatter(iris3['SepalLengthCm'], iris3['SepalWidthCm'], s = 10, color = "y", alpha = 0.75)
13 ax.set_title("iris")
14 ax.set_xlabel("SepalLengthCm")
15 ax.set_ylabel("SepalWidthCm")
16 plt.legend(["Iris-setosa","Iris-versicolor","Iris-virginica"])
17 plt.show()
18if __name__=='__main__':
19 main()
2.2 折线图
如果一个变量随着另一个变量的变化而大幅度变化(具有很高的协方差),为了清楚地看出变量间的关系,最好使用折线图。例如,根据下图,我们能清楚地看出,不同专业获得学士学位的人群中,女性所占的百分比随时间变化产生很大变化。
此时,若用散点图绘制,数据点容易成簇,显得非常混乱,很难看出数据本身的意义。而折线图就再合适不过了,因为它基本上反映出两个变量(女性占比和时间)协方差的大体情况。同样,也可使用不同颜色来对多组数据分组。
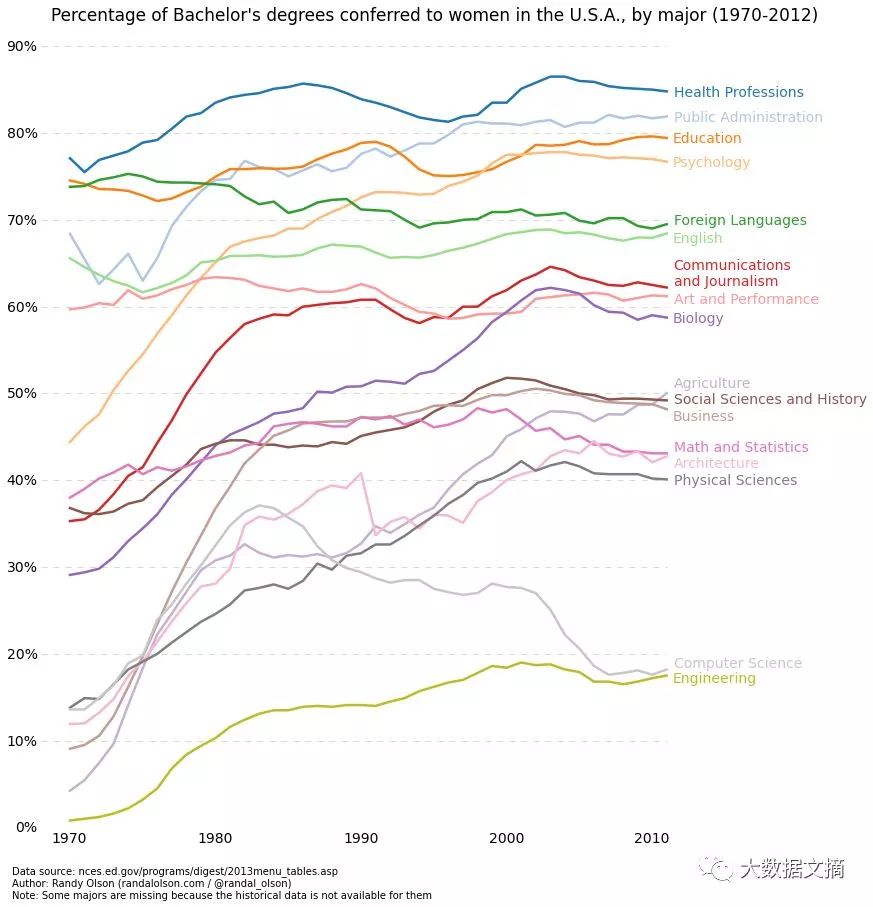
代码与散点图类似,只是一些微小的参数改动。
1def lineplot(x_data, y_data, x_label="", y_label="", title=""):
2 # Create the plot object
3 _, ax = plt.subplots()
4 # Plot the best fit line, set the linewidth (lw), color and
5 # transparency (alpha) of the line
6 ax.plot(x_data, y_data, lw = 2, color = '#539caf', alpha = 1)
7 # Label the axes and provide a title
8 ax.set_title(title)
9 ax.set_xlabel(x_label)
10 ax.set_ylabel(y_label)
2.3 直方图
直方图适合查看(或发现)数据分布。下图为不同IQ人群所占比例的直方图。从中可以清楚地看出中心期望值和中位数,看出它遵循正态分布。使用直方图(而不是散点图)可以清楚地显示出不同组数据频率之间的相对差异。而且,分组(使数据离散化)有助于看出“更宏观的分布”,若使用未被离散化的数据点,可能会产生大量数据噪声,从而很难看出数据的真实分布。
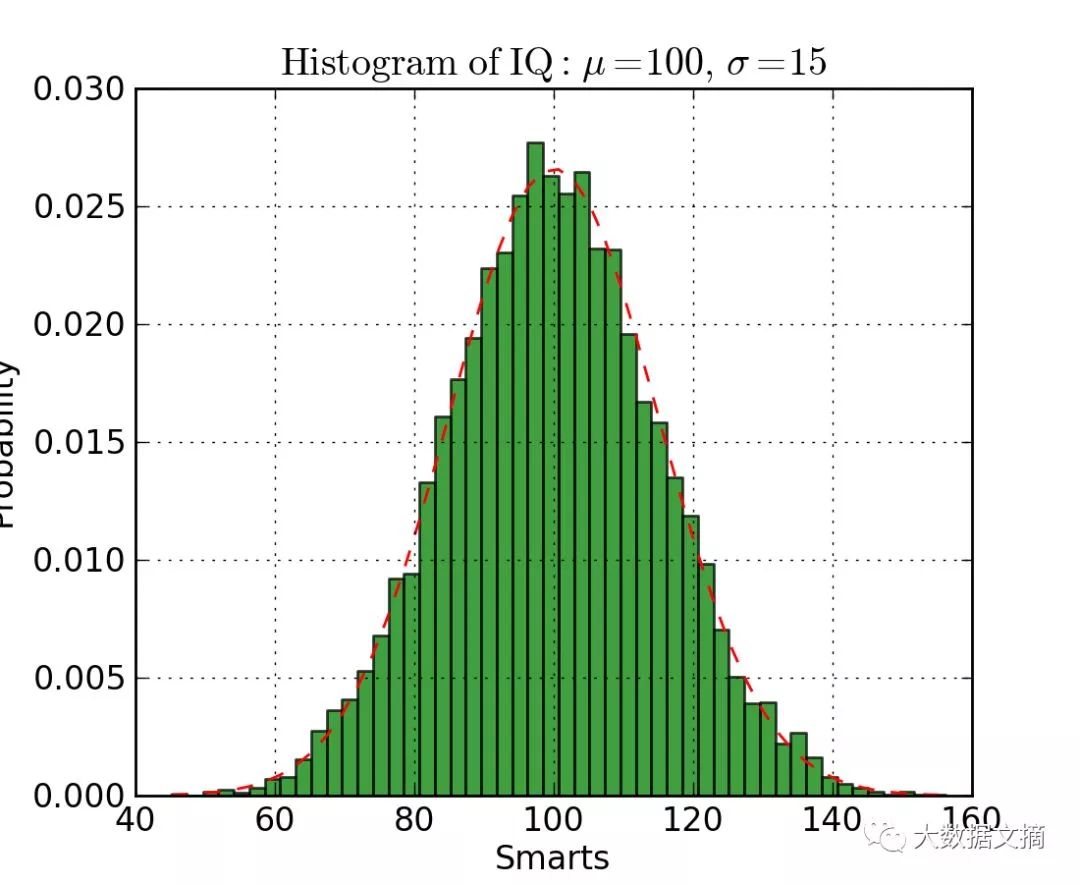
下面是用Matplotlib库创建直方图的代码。这里有两个参数需要注意。第一个参数是n_bins参数,用于控制直方图的离散度。一方面,更多的分组数能提供更详细的信息,但可能会引入数据噪声使结果偏离宏观分布;另一方面,更少的分组数能提供更宏观的数据“鸟瞰”,在不需要太多细节的情况下能更全面地了解数据整体情况。第二个参数是累积参数cumulative,是一个布尔值,通过它控制直方图是否累积,也就是选择使用概率密度函数(PDF)还是累积密度函数(CDF)。
1def histogram(data, n_bins, cumulative=False, x_label = "", y_label = "", title = ""):
2 _, ax = plt.subplots()
3 ax.hist(data, n_bins = n_bins, cumulative = cumulative, color = '#539caf')
4 ax.set_ylabel(y_label)
5 ax.set_xlabel(x_label)
6 ax.set_title(title)
2.4 柱状图
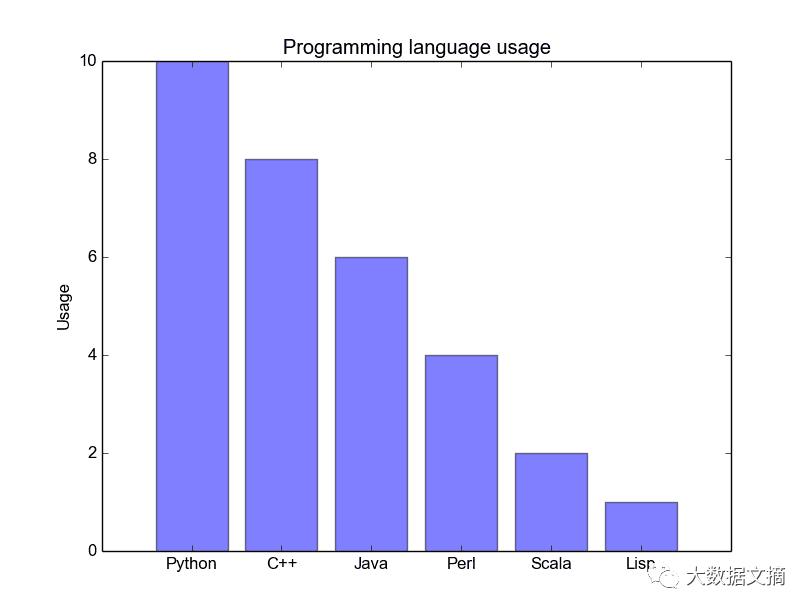
柱状图适用于对类别较少(<10个)的分类数据进行可视化。但在类别太多时,图中的柱体就会容易堆在一起,显得非常乱,对数据的理解造成困难。柱状图适合于分类数据的原因,一是能根据柱体的高度(即长短)轻松地看出类别之间的差异,二是很容易将不同类别加以区分,甚至赋予不同颜色。以下介绍三种类型的柱状图:常规柱状图,分组柱状图和堆积柱状图。参考代码来看详细的说明。
常规柱状图,如下图所示。代码中,barplot()函数的x_data参数表示x轴坐标,y_data代表y轴(柱体的高度)坐标,yerr表示在每个柱体顶部中央显示的标准偏差线。
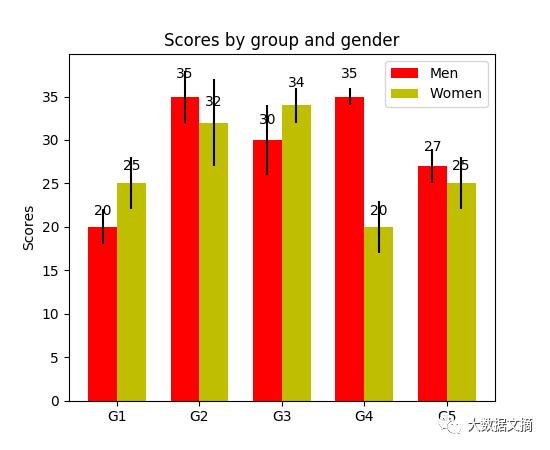
分组柱状图,如下图所示。它允许对多个分类变量进行对比。如图所示,两组关系其一是分数与组(组G1,G2,…等)的关系,其二是用颜色区分的性别之间的关系。代码中,y_data_list是一个列表,其中又包含多个子列表,每个子列表代表一个组。对每个列表赋予x坐标,循环遍历其中的每个子列表,设置成不同颜色,绘制出分组柱状图。
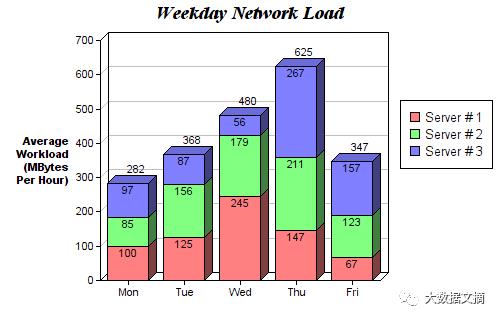
堆积柱状图,适合可视化含有子分类的分类数据。下面这张图是用堆积柱状图展示的日常服务器负载情况统计。使用不同颜色进行堆叠,对不同服务器之间进行比较,从而能查看并了解每天中哪台服务器的工作效率最高,负载具体为多少。代码与柱状图样式相同,同样为循环遍历每个组,只是这次是在旧柱体基础上堆叠,而不是在其旁边绘制新柱体。
以下是三种堆积柱状图的代码:
1def barplot(x_data, y_data, error_data, x_label="", y_label="", title=""):
2 _, ax = plt.subplots()
3 # Draw bars, position them in the center of the tick mark on the x-axis
4 ax.bar(x_data, y_data, color = '#539caf', align = 'center')
5 # Draw error bars to show standard deviation, set ls to 'none'
6 # to remove line between points
7 ax.errorbar(x_data, y_data, yerr = error_data, color = '#297083', ls = 'none', lw = 2, capthick = 2)
8 ax.set_ylabel(y_label)
9 ax.set_xlabel(x_label)
10 ax.set_title(title)
11def groupedbarplot(x_data, y_data_list, colors, y_data_names="", x_label="", y_label="", title=""):
12 _, ax = plt.subplots()
13 # Total width for all bars at one x location
14 total_width = 0.8
15 # Width of each individual bar
16 ind_width = total_width / len(y_data_list)
17 # This centers each cluster of bars about the x tick mark
18 alteration = np.arange(-(total_width/2), total_width/2, ind_width)
19 # Draw bars, one category at a time
20 for i in range(0, len(y_data_list)):
21 # Move the bar to the right on the x-axis so it doesn't
22 # overlap with previously drawn ones
23 ax.bar(x_data + alteration[i], y_data_list[i], color = colors[i], label = y_data_names[i], width = ind_width)
24 ax.set_ylabel(y_label)
25 ax.set_xlabel(x_label)
26 ax.set_title(title)
27 ax.legend(loc = 'upper right')
28def stackedbarplot(x_data, y_data_list, colors, y_data_names="", x_label="", y_label="", title=""):
29 _, ax = plt.subplots()
30 # Draw bars, one category at a time
31 for i in range(0, len(y_data_list)):
32 if i == 0:
33 ax.bar(x_data, y_data_list[i], color = colors[i], align = 'center', label = y_data_names[i])
34 else:
35 # For each category after the first, the bottom of the
36 # bar will be the top of the last category
37 ax.bar(x_data, y_data_list[i], color = colors[i], bottom = y_data_list[i - 1], align = 'center', label = y_data_names[i])
38 ax.set_ylabel(y_label)
39 ax.set_xlabel(x_label)
40 ax.set_title(title)
41 ax.legend(loc = 'upper right')
箱线图
前文介绍的直方图非常适合于对变量分布的可视化。但是,如果想要将更多的变量信息可视化呢?比如要清楚地看出标准差,或者一些情况下,中位数与平均值存在很大差异,因此是存在很多异常值呢还是数据分布本身就向一端偏移呢?
这里,箱线图就可以表示出上述的所有信息。箱体的底部和顶部分别为第一和第三四分位数(即数据的25%和75%),箱体内的横线为第二四分位数(即中位数)。箱体上下的延伸线(即T型虚线)表示数据的上下限。
由于箱形图是为每个组或变量绘制的,因此设置起来非常容易。x_data是组或变量的列表,x_data中的每个值对应于y_data中的一列值(一个列向量)。用Matplotlib库的函数boxplot()为y_data的每列值(每个列向量)生成一个箱形,然后设定箱线图中的各个参数就可以了。
1def boxplot(x_data, y_data, base_color="#539caf", median_color="#297083", x_label="", y_label="", title=""):
2 _, ax = plt.subplots()
3 # Draw boxplots, specifying desired style
4 ax.boxplot(y_data
5 # patch_artist must be True to control box fill
6 , patch_artist = True
7 # Properties of median line
8 , medianprops = {'color': median_color}
9 # Properties of box
10 , boxprops = {'color': base_color, 'facecolor': base_color}
11 # Properties of whiskers
12 , whiskerprops = {'color': base_color}
13 # Properties of whisker caps
14 , capprops = {'color': base_color})
15 # By default, the tick label starts at 1 and increments by 1 for
16 # each box drawn. This sets the labels to the ones we want
17 ax.set_xticklabels(x_data)
18 ax.set_ylabel(y_label)
19 ax.set_xlabel(x_label)
20 ax.set_title(title)
面向对象的接口
重点讲一下我遇到的最常见的绘图任务,如标记轴,调整限制,更新绘图标题,保存图片和调整图例。如果你想跟着继续学习,在链接
https://github.com/chris1610/pbpython/blob/master/notebooks/Effectively-Using-Matplotlib.ipynb
中包含附加细节的笔记,应该非常有用。
准备开始,我先引入库并读入一些数据:
1import pandas as pd
2import matplotlib.pyplot as plt
3from matplotlib.ticker import FuncFormatter
4df = pd.read_excel("https://github.com/chris1610/pbpython/blob/master/data/sample-salesv3.xlsx?raw=true")
5df.head()
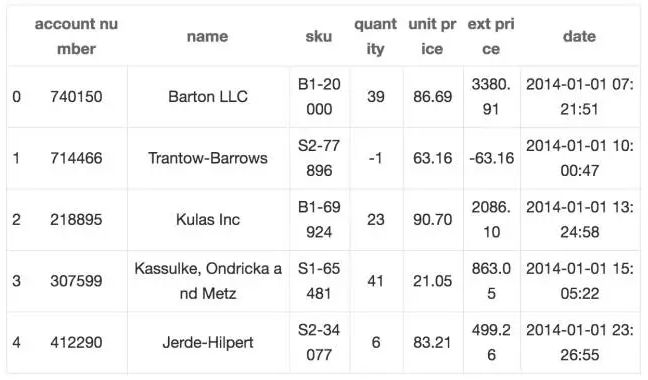
这是2014年的销售交易数据。为了使这些数据简短一些,我将对数据进行聚合,以便我们可以看到前十名客户的总购买量和总销售额。为了清楚我还会在绘图中重新命名列。
1top_10 = (df.groupby('name')['ext price', 'quantity'].agg({'ext price': 'sum', 'quantity': 'count'})
2 .sort_values(by='ext price', ascending=False))[:10].reset_index()
3top_10.rename(columns={'name': 'Name', 'ext price': 'Sales', 'quantity': 'Purchases'}, inplace=True)
下面是数据的处理结果。
现在,数据被格式化成一个简单的表格,我们来看如何将这些结果绘制成条形图。
如前所述,matplotlib有许多不同的样式可用于渲染绘图,可以用plt.style.available查看系统中有哪些可用的样式。
1['seaborn-dark',
2'seaborn-dark-palette',
3'fivethirtyeight',
4'seaborn-whitegrid',
5'seaborn-darkgrid',
6'seaborn',
7'bmh',
8'classic',
9'seaborn-colorblind',
10'seaborn-muted',
11'seaborn-white',
12'seaborn-talk',
13'grayscale',
14'dark_background',
15'seaborn-deep',
16'seaborn-bright',
17'ggplot',
18'seaborn-paper',
19'seaborn-notebook',
20'seaborn-poster',
21'seaborn-ticks',
22'seaborn-pastel']
这样简单使用一个样式:
1plt.style.use('ggplot')
使用DataFrame调用plot
1top_10.plot(kind='barh', y="Sales", x="Name")
我推荐先使用pandas绘图,是因为它是一种快速简便构建可视化的方法。 由于大多数人可能已经在pandas中进行过一些数据处理/分析,所以请先从基本的绘图开始。
参考文献:
[1]https://mp.weixin.qq.com/s/WgHXtVwVFGqqzLhtP-2olQ
[2]https://mp.weixin.qq.com/s/d5IbUFoj5xqmfD7sDJFV3g
[3]https://mp.weixin.qq.com/s/_kRDOm4R26mm4pa88XDnag
[4]https://github.com/chris1610/pbpython/blob/master/notebooks/Effectively-Using-Matplotlib.ipynb
[5]https://mp.weixin.qq.com/s/ph0-MgldDNMszHPnA38OaQ
[6]https://mp.weixin.qq.com/s/vr-pURyPkH5gGzgysRhwQQ
以上是关于数据可视化代码实例(Matplotlib+Pandas)的主要内容,如果未能解决你的问题,请参考以下文章
数据可视化实例(十七):包点图 (matplotlib,pandas)
数据可视化实例(十五):有序条形图(matplotlib,pandas)
数据可视化实例(十三): 发散型条形图 (matplotlib,pandas)
数据可视化实例(十三): 发散型条形图 (matplotlib,pandas)