数据可视化实例(十三): 发散型条形图 (matplotlib,pandas)
Posted qiu-hua
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据可视化实例(十三): 发散型条形图 (matplotlib,pandas)相关的知识,希望对你有一定的参考价值。
偏差 (Deviation)
https://datawhalechina.github.io/pms50/#/chapter11/chapter11
发散型文本 (Diverging Texts)
如果您想根据单个指标查看项目的变化情况,并可视化此差异的顺序和数量,那么散型条形图 (Diverging Bars) 是一个很好的工具。 它有助于快速区分数据中组的性能,并且非常直观,并且可以立即传达这一点。
导入所需要的库
import numpy as np # 导入numpy库 import pandas as pd # 导入pandas库 import matplotlib as mpl # 导入matplotlib库 import matplotlib.pyplot as plt import seaborn as sns # 导入seaborn库
设定图像各种属性
large = 22; med = 16; small = 12 params = {‘axes.titlesize‘: large, # 设置子图上的标题字体 ‘legend.fontsize‘: med, # 设置图例的字体 ‘figure.figsize‘: (16, 10), # 设置图像的画布 ‘axes.labelsize‘: med, # 设置标签的字体 ‘xtick.labelsize‘: med, # 设置x轴上的标尺的字体 ‘ytick.labelsize‘: med, # 设置整个画布的标题字体 ‘figure.titlesize‘: large} plt.rcParams.update(params) # 更新默认属性 plt.style.use(‘seaborn-whitegrid‘) # 设定整体风格 sns.set_style("white") # 设定整体背景风格
程序代码
# step1:导入数据
df = pd.read_csv("https://github.com/selva86/datasets/raw/master/mtcars.csv") x = df.loc[:, ‘mpg‘] # 获取mpg这一列数据 # z-score 标准化(正太标准化):将数据按期属性(按列进行)减去其均值,并处以其方差。得到的结果是,对于每个属性/每列来说所有数据都聚集在0附近,方差为1。 df[‘mpg_z‘] = (x - x.mean()) / x.std() # 列表推导式 # 小于0__红色,大于0__绿色 df[‘colors‘] = [‘red‘ if x <0 else ‘green‘ for x in df[‘mpg_z‘]] # 颜色标签 df.sort_values(‘mpg_z‘, inplace = True) # 对‘mpg_z这一列数据进行排序 df.reset_index(inplace = True) # 对排序后的数据重置索引
# step2:绘制发散条形图
# 画布 plt.figure(figsize = (14, 10), # 画布尺寸_(14, 10) dpi = 80) # 分辨率__80 # 发散型条形图 plt.hlines(df.index, # 将y下标作为绘制直线的位置 xmin = 0, # 每一行的开头 xmax = df.mpg_z) # 每一行的结尾 # 发散型文本图 for x, y, text in zip(df.mpg_z, df.index, df.mpg_z): # 使用zip() 函数用于将可迭代的对象作为参数 t = plt.text(x, # 文本位置的横坐标 y, # 文本位置的纵坐标 round(text, 2), # 对text保留2位小数(照指定的小数位数进行四舍五入运算的结果) horizontalalignment = ‘right‘ if x<0 else ‘left‘, # 水平对齐参数 verticalalignment = ‘center‘, # 垂直对齐参数 fontdict = {‘color‘:‘red‘ if x<0 else ‘green‘, ‘size‘:14} ) # 用于覆盖默认文本属性的字典(添加颜色和尺寸)
# step3:装饰图像
# y轴标签 plt.yticks(df.index, # 放置刻度的位置列表 df.cars, # 放置给定位置列表的标签列表 fontsize = 12) # 字体尺寸 # 设置图像标题 plt.title(‘Diverging Text Bars of Car Mileage‘, # 图像标题名称 fontdict={‘size‘:20}) # 字体尺寸 # 设置网格线 plt.grid(linestyle = ‘--‘, # 网格线类型 alpha = 0.5) # 网格线透明度 # 设置当前x坐标轴的范围 plt.xlim(-2.5, 2.5) plt.show() # 显示图像
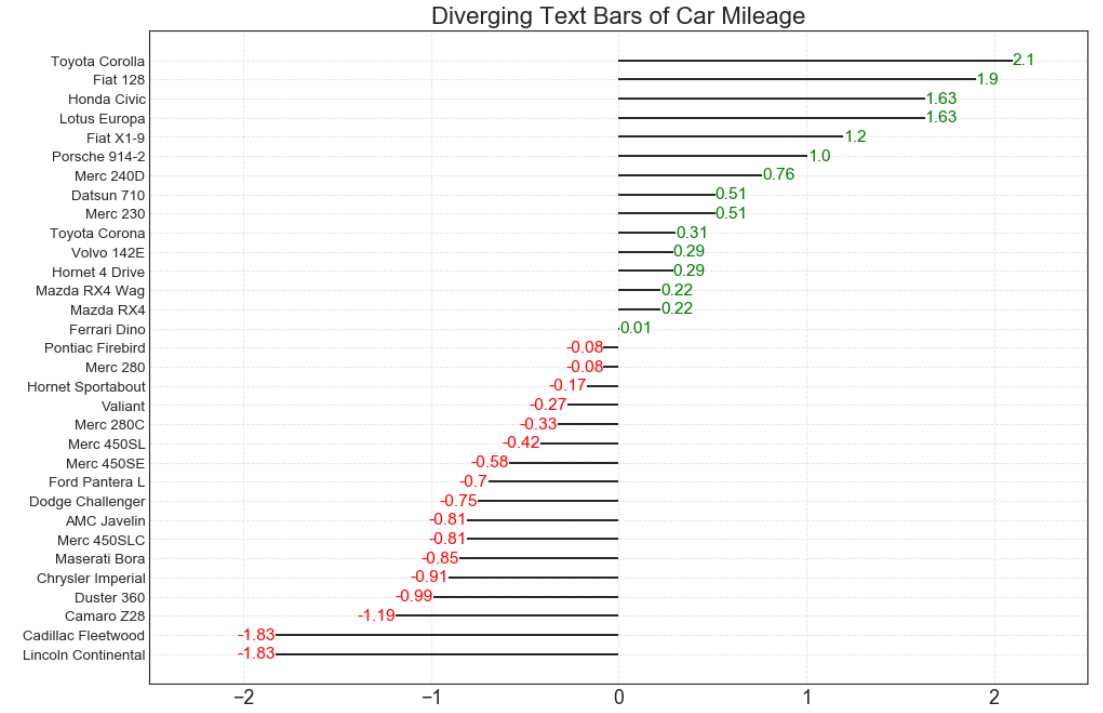
以上是关于数据可视化实例(十三): 发散型条形图 (matplotlib,pandas)的主要内容,如果未能解决你的问题,请参考以下文章
Python使用matplotlib可视化发散型条形图发散条形图(Diverging Bars)是一种可以同时处理负值和正值的条形图并按照大小排序区分数据(Diverging Bars)
R语言ggplot2可视化发散型条形图发散条形图(Diverging Bars)是一种可以同时处理负值和正值的条形图并按照大小排序区分数据(Diverging Bars)
最有用的25个 Matplotlib图(含Python代码模板)
最有用的25个 Matplotlib图(含Python代码模板)
Python使用matplotlib可视化发散型点图发散型点图可以同时处理负值和正值并按照大小排序区分数据为发散型点图添加数值标签(Diverging Dot Plot )